In mijn vorige artikel zijn we begonnen met het beschrijven van de basisprincipes van het EXPLAIN-commando en hebben we geanalyseerd wat er in PostgreSQL gebeurt bij het uitvoeren van een query.
Ik ga verder met schrijven over de basisprincipes van EXPLAIN in PostgreSQL. De informatie is een korte recensie van Understanding EXPLAIN door Guillaume Lelarge. Ik raad ten zeerste aan om het origineel te lezen, omdat er wat informatie over het hoofd wordt gezien.
Cache
Wat gebeurt er op fysiek niveau bij het uitvoeren van onze query? Laten we het uitzoeken. Ik heb mijn server op Ubuntu 13.10 geïmplementeerd en schijfcaches van het besturingssysteemniveau gebruikt.
Ik stop PostgreSQL, voer wijzigingen door in het bestandssysteem, wis de cache en voer PostgreSQL uit:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Wanneer de cache is gewist, voert u de query uit met de optie BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

We lezen de tabel met blokjes. De cache is leeg. We moesten toegang krijgen tot 8334 blokken om de hele tabel van de schijf te lezen.
Buffers:gedeeld lezen is het aantal blokken dat PostgreSQL van de schijf leest.
Voer de vorige zoekopdracht uit
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffers:gedeelde hit is het aantal blokken dat is opgehaald uit de PostgreSQL-cache.
Bij elke zoekopdracht haalt PostgreSQL steeds meer gegevens uit de cache, waardoor de eigen cache wordt gevuld.
Cache-leesbewerkingen zijn sneller dan schijfleesbewerkingen. U kunt deze trend zien door de Totale runtime-waarde bij te houden.
De grootte van de cacheopslag wordt bepaald door de constante shared_buffers in het bestand postgresql.conf.
WAAR
Voeg de voorwaarde toe aan de zoekopdracht
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Er zijn geen indexen op de tafel. Bij het uitvoeren van de query wordt elk record van de tabel opeenvolgend gescand (Seq Scan) en vergeleken met de c1> 500-voorwaarde. Als aan de voorwaarde is voldaan, wordt het record toegevoegd aan het resultaat. Anders wordt het weggegooid. Filter geeft dit gedrag aan, evenals de kostenwaarde stijgt.
Het geschatte aantal rijen neemt af.
In het originele artikel wordt uitgelegd waarom de kosten deze waarde aannemen en hoe het geschatte aantal rijen wordt berekend.
Het is tijd om indexen te maken.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Het geschatte aantal rijen is gewijzigd. Hoe zit het met de index?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Slechts 510 rijen van meer dan 1 miljoen worden gefilterd. PostgreSQL moest meer dan 99,9% van de tabel lezen.
We dwingen de index te gebruiken door Seq Scan uit te schakelen:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

In Index Scan en Index Cond wordt de foo_c1_idx index gebruikt in plaats van Filter.
Wanneer u de hele tabel selecteert, verhoogt het gebruik van de index de kosten en tijd om de query uit te voeren.
Seq Scan inschakelen:
SET enable_seqscan TO on;
Pas de zoekopdracht aan:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
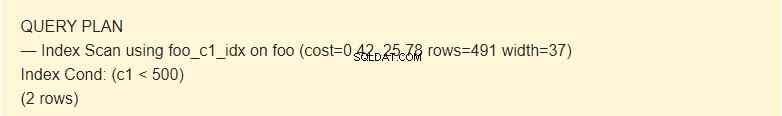
Hier gebruikt de planner de index.
Laten we de waarde nu ingewikkelder maken door het tekstveld toe te voegen.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Zoals u kunt zien, wordt de foo_c1_idx-index gebruikt voor c1 <500. Om c2 ~~ 'abcd%'::text uit te voeren, gebruikt u het filter.
Opgemerkt moet worden dat het POSIX-formaat van de LIKE-operator wordt gebruikt in de uitvoer van de resultaten. Als er alleen het tekstveld in de voorwaarde staat:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan wordt toegepast.
Bouw de index op met c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

De index wordt niet toegepast omdat mijn database voor testvelden de UTF-8-codering gebruikt.
Bij het bouwen van de index is het nodig om de klasse van de operator text_pattern_ops te specificeren:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Super goed! Het werkte!
Bitmap Index Scan gebruikt de foo_c2_idx1 index om te bepalen welke records we nodig hebben. Vervolgens gaat PostgreSQL naar de tabel (Bitmap Heap Scan) om te controleren of deze records daadwerkelijk bestaan. Dit gedrag verwijst naar het versiebeheer van PostgreSQL.
Als u alleen het veld selecteert waarop de index is gebouwd, in plaats van de hele rij:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan wordt sneller uitgevoerd dan Index Scan omdat het niet nodig is om de rij van de tabel te lezen:width=4.
Conclusie
- Seq Scan leest de hele tabel
- Index Scan gebruikt de index voor de WHERE-instructies en leest de tabel bij het selecteren van rijen
- Bitmap Index Scan maakt gebruik van Index Scan en selectiecontrole via de tabel. Effectief voor een groot aantal rijen.
- Alleen index scannen is het snelste blok, dat alleen de index leest.
Verder lezen:
Query-optimalisatie in PostgreSQL. UITLEG Basisprincipes – Deel 3