Ik vervolg een reeks artikelen over de basisprincipes van EXPLAIN in PostgreSQL, wat een korte recensie is van Understanding EXPLAIN door Guillaume Lelarge.
Om het probleem beter te begrijpen, raad ik ten zeerste aan om de originele "Understanding EXPLAIN" door Guillaume Lelarge en lees mijn eerste en tweede artikel.
BESTEL DOOR
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Eerst voert u een sequentiële scan (Seq Scan) van de foo-tabel uit en vervolgens sorteert u (Sorteren). Het -> teken van het EXPLAIN commando geeft de hiërarchie van stappen (knooppunt) aan. Hoe eerder de stap wordt uitgevoerd, hoe groter de inspringing.
Sorteersleutel is een voorwaarde voor sorteren.
Sorteermethode:externe samenvoegschijf een tijdelijk bestand op de schijf met een capaciteit van 4592 kB wordt gebruikt bij het sorteren.
Controleer met de BUFFERS-optie:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
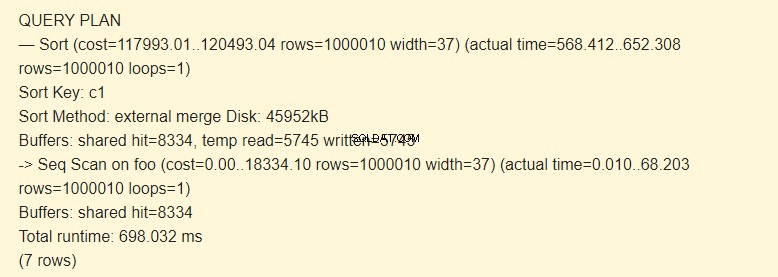
Inderdaad, de regel tijdelijk lezen=5745 geschreven=5745 betekent dat 45960Kb (5745 blokken van elk 8 Kb) werden opgeslagen en gelezen in het tijdelijke bestand. De bewerkingen met 8334 blokken zijn uitgevoerd in de cache.
De bewerkingen met het bestandssysteem zijn langzamer dan bewerkingen in RAM.
Laten we proberen de geheugencapaciteit van work_mem te vergroten:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Sorteermethode:quicksort Geheugen:102702kB – de gehele sortering is uitgevoerd in RAM.
De index is als volgt:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

We hebben alleen nog Index Scan over, wat de snelheid van de zoekopdracht aanzienlijk beïnvloedde.
LIMIET
Verwijder de eerder gemaakte index:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Zoals verwacht worden Seq Scan en Filter gebruikt.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan leest rijen van de tabel en vergelijkt ze (Filter) met de voorwaarde. Zodra er 10 records zijn die aan de voorwaarde voldoen, wordt de scan beëindigd. In ons geval moesten we, om 10 resultaatrijen te krijgen, slechts 3063 records lezen in plaats van de hele tabel. 3053 rijen van dit aantal zijn afgewezen (rijen verwijderd door filter).
Hetzelfde gebeurt met Index Scan.
DOE MEE
Maak een nieuwe tabel en genereer er statistieken voor:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
De query voor twee tabellen is als volgt:
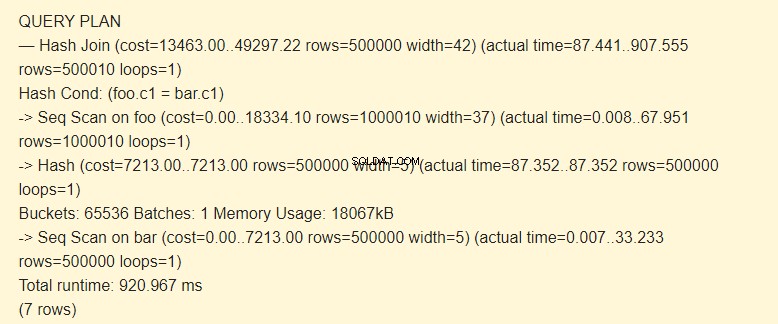
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Eerst leest de sequentiële scan (Seq Scan) de staaftabel. Voor elke rij wordt een hash (Hash) berekend.
Vervolgens scant het de foo-tabel en voor elke rij wordt een hash berekend die wordt vergeleken (Hash Join) met de hash van de bartabel door de Hash Cond-voorwaarde. Als ze overeenkomen, wordt een resulterende tekenreeks uitgevoerd.
18067 kB geheugen wordt gebruikt om hashes voor de balk op te slaan.
Voeg de index toe:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hasj wordt niet meer gebruikt. Samenvoegen Join en Index Scan op de indices van beide tabellen verbeteren de prestaties aanzienlijk.
LEFT JOIN:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
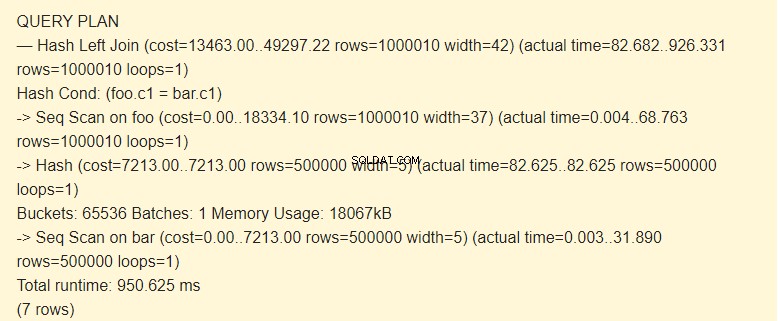
Volg Scan?
Laten we eens kijken welk resultaat we zullen hebben als we Seq Scan uitschakelen.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Volgens de planner is het gebruik van indexen duurder dan het gebruik van hashes. Dit is mogelijk met een voldoende grote hoeveelheid toegewezen geheugen. Weet je nog dat we work_mem hebben verhoogd?
Als u echter niet genoeg geheugen heeft, zal de planner zich anders gedragen:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Als we Index Scan uitschakelen, welk resultaat wordt dan EXPLAIN weergegeven?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
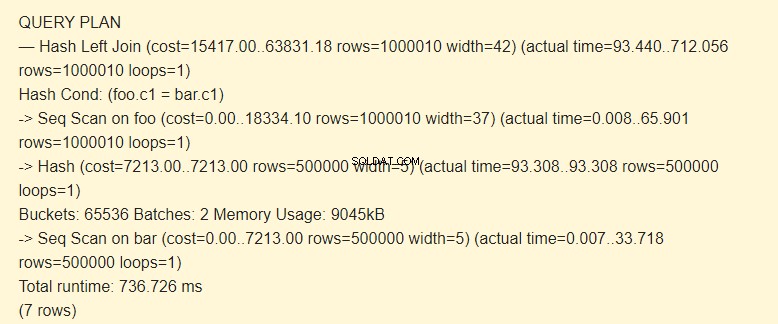
Partijen:2 heeft hogere kosten. De hele hash paste niet in het geheugen; we moesten het opsplitsen in twee pakketten van 9045kB.
Bedankt voor het lezen van mijn artikelen! Ik hoop dat ze nuttig waren. Als je opmerkingen of feedback hebt, laat het me dan gerust weten.