Hier zijn we. Bijna twee decennia in de 21e eeuw en de behoefte aan meer rekenkracht is nog steeds een probleem. Technologiebedrijven beuken op de stoep om dit enorme probleem frontaal aan te pakken. Hardware-ingenieurs hebben een oplossing gevonden door de manier waarop ze de centrale verwerkingseenheid (CPU) van een computer ontwerpen en vervaardigen te veranderen. Ze bevatten nu meerdere kernen, waardoor gelijktijdigheid kan plaatsvinden. Op hun beurt hebben softwareontwikkelaars de manier waarop ze programma's schrijven aangepast aan deze verandering in hardware.
De PostgreSQL-gemeenschap heeft optimaal gebruik gemaakt van deze multi-core CPU's om de queryprestaties te verbeteren. Door alleen te updaten naar versie 9.6 of hoger, kunt u een functie genaamd query-parallellisme gebruiken om verschillende bewerkingen uit te voeren. Het verdeelt taken in kleinere delen en verspreidt elke taak over meerdere CPU-kernen. Elke kern kan de taken tegelijkertijd verwerken. Vanwege hardwarebeperkingen is dit de enige manier om de computerprestaties te verbeteren naarmate we de toekomst ingaan.
Voordat u de parallellisme-functie in de PostgreSQL-database gebruikt, is het essentieel om te herkennen hoe het een query parallel maakt. U kunt eventuele problemen opsporen en oplossen.
Hoe werkt het parallellisme van query's?
Om beter te begrijpen hoe parallellisme wordt uitgevoerd, is het een goed idee om op klantniveau te beginnen. Om toegang te krijgen tot PostgreSQL, moet een client een verbindingsverzoek verzenden naar de databaseserver, de postmaster. De postmaster voltooit de authenticatie en fork om voor elke verbinding een nieuw serverproces te creëren. Het is ook verantwoordelijk voor het creëren van een gebied van gedeeld geheugen dat een bufferpool bevat. De bufferpool houdt toezicht op de overdracht van gegevens tussen het gedeelde geheugen en de opslag. Daarom zal de bufferpool, zodra er een verbinding tot stand is gebracht, gegevens overdragen en kan parallellisme opvragen plaatsvinden.
Het is niet nodig dat alle query's parallel zijn. Er zijn gevallen waarin slechts een kleine hoeveelheid gegevens nodig is en deze snel door slechts één kern kan worden verwerkt. Deze functie wordt alleen gebruikt wanneer een zoekopdracht een aanzienlijke hoeveelheid tijd in beslag neemt. De database-optimizer bepaalt of parallellisme moet worden uitgevoerd. Als het nodig is, gebruikt de database een extra deel van het geheugen, dynamisch gedeeld geheugen (DSM). Hierdoor kunnen het leiderproces en de parallel bewuste werkprocessen de query verdelen over meerdere kernen en relevante gegevens verzamelen.
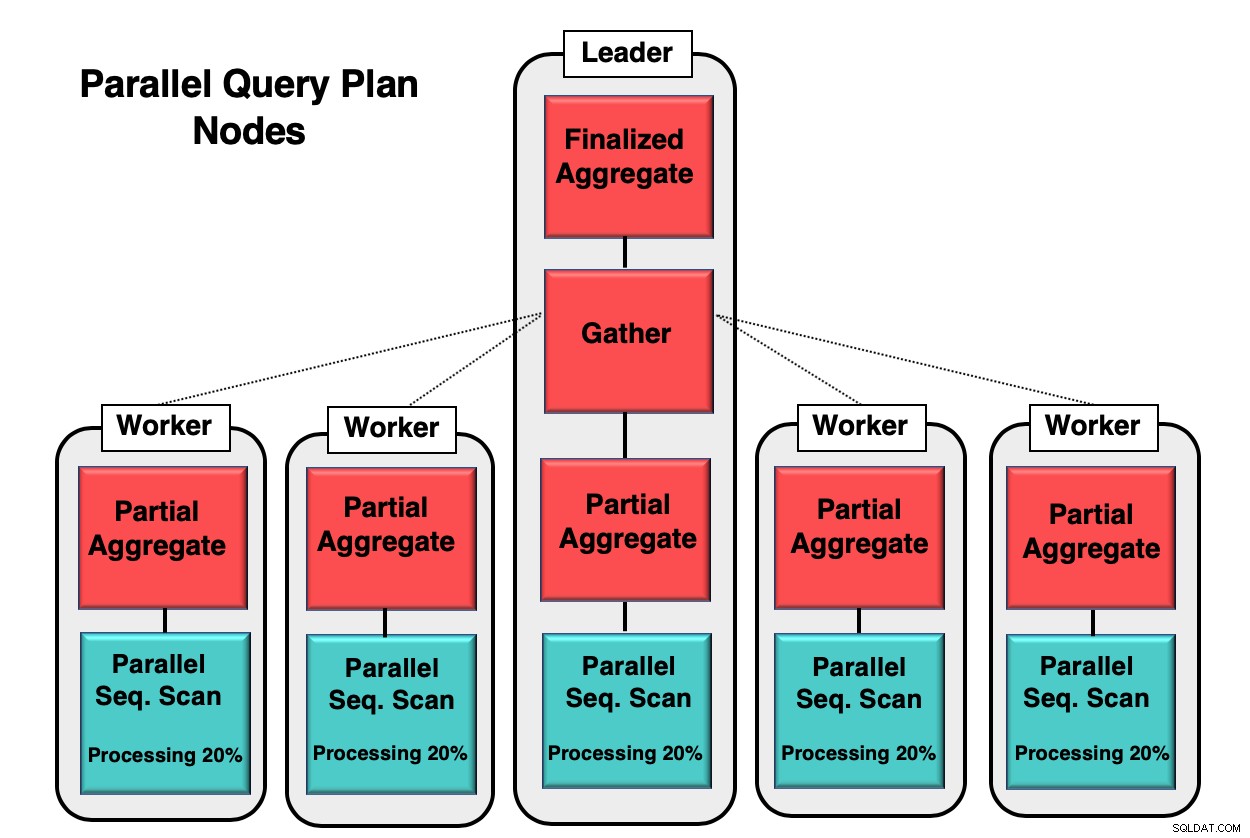
Figuur 1 geeft u een voorbeeld van hoe parallellisme plaatsvindt binnen de database. Het leiderproces voert de eerste query uit, terwijl de afzonderlijke werkprocessen een kopie van hetzelfde proces initiëren. Het gedeeltelijk geaggregeerde knooppunt, of CPU-kern, is verantwoordelijk voor het implementeren van de parallelle sequentiële scan van de databasetabel.
In dit geval verwerkt elk sequentiële scanknooppunt 20% van de gegevens in blokken van 8 kb. Deze zelfde knooppunten kunnen hun activiteit coördineren met behulp van een techniek die parallel bewustzijn wordt genoemd. Elk knooppunt heeft volledige kennis van welke gegevens al zijn verwerkt en welke gegevens in de tabel moeten worden gescand om de query te voltooien. Zodra de tuples volledig zijn verzameld, wordt deze naar het verzamelknooppunt gestuurd om te worden gecompileerd en afgerond.
Parallelle bewerkingen
Er kunnen verschillende soorten query's worden gebruikt om gegevens uit een database op te halen om resultatensets te produceren. Hier zijn specifieke bewerkingen waarmee u het gebruik van meerdere kernen effectief kunt benutten.
Sequentiële scan
Deze bewerking leest gegevens in een tabel van het begin tot het einde om gegevens te verzamelen. Het verdeelt de werklast gelijkmatig over meerdere kernen om de verwerkingssnelheid van query's te verhogen. Het is op de hoogte van elke kernactiviteit, waardoor het gemakkelijker wordt om te bepalen of de volledige query is voltooid. Het verzamelknooppunt ontvangt vervolgens de gegevens die zijn geëxtraheerd op basis van de zoekopdracht.
Aggregatie
Een standaardbewerking, die een grote hoeveelheid gegevens nodig heeft en deze in een kleiner aantal rijen condenseert. Dit gebeurt tijdens de parallelle verwerking door alleen uit een tabel of indexen de juiste informatie te extraheren op basis van de query. Het uitvoeren van een gemiddelde van specifieke gegevens is een uitstekend voorbeeld van aggregatie.
Hash-deelname
Een techniek die wordt gebruikt om de gegevens tussen twee tabellen samen te voegen. Het is het snelste join-algoritme, dat meestal wordt uitgevoerd met een kleine en een grote tabel. U maakt eerst een hashtabel en laadt alle gegevens uit één tabel daarin. Vervolgens kunt u alle gegevens uit de hash en de tweede tabel scannen met behulp van parallelle sequentiële scan. Elke tuple die uit de scan wordt gehaald, wordt vergeleken met de hashtabel om te zien of er een overeenkomst is. Als er een match wordt gevonden, worden de gegevens samengevoegd. Met de release van PostgreSQL 11 kost het gebruik van parallellisme om een hash-join te voltooien ongeveer een derde van de eerdere verwerkingstijd.
Aanmelden samenvoegen
Als de optimizer bepaalt dat een hash-join de geheugencapaciteit gaat overschrijden, zal hij in plaats daarvan een merge-join uitvoeren. Het proces omvat het scannen door twee gesorteerde lijsten tegelijk en voegt dezelfde elementen samen. Als de items niet gelijk zijn, worden de gegevens niet samengevoegd.
Aangesloten lus toevoegen
Deze bewerking wordt gebruikt wanneer u twee tabellen met verschillende programmeertalen moet samenvoegen, zoals Quick Basic, Python, enz. Elke tabel wordt gescand en verwerkt met behulp van meerdere kernen. Als de gegevens overeenkomen, wordt deze naar het verzamelknooppunt gestuurd om te worden samengevoegd. De indexen worden ook gescand, daarom bevat dit proces meerdere lussen om de gegevens op te halen. Door het parallelle proces te gebruiken, duurt het gemiddeld slechts een derde van de tijd om de join te voltooien.
B-tree Index Scan
Deze bewerking scant door een boom met gesorteerde gegevens om specifieke informatie te vinden. Dit proces duurt langer dan de typische sequentiële scan omdat er veel wordt gewacht bij het zoeken naar records. Het scannen naar de juiste gegevens is echter verdeeld over meerdere processors.
Bitmap Heap-scan
U kunt meerdere indexen samenvoegen door deze bewerking te gebruiken. U wilt eerst het equivalente aantal bitmaps maken, aangezien u indexen hebt. Als u bijvoorbeeld drie indexen heeft, moet u eerst drie bitmaps maken. Elke bitmap zal tupels ophalen en compileren op basis van de zoekopdracht.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperPartitie-parallellisme
Er is een andere vorm van parallellisme die kan plaatsvinden binnen de PostgreSQL-database. Het komt echter niet van het scannen van tabellen en het opsplitsen van de taken. U kunt de gegevens partitioneren of verdelen op specifieke waarden. U kunt bijvoorbeeld de waardekopers nemen en één enkele kern de gegevens alleen binnen die waarde laten verwerken. Op die manier weet u precies wat elke kern op elk moment verwerkt.
Hash-partitionering
Deze bewerking wordt gebruikt door tabelrijen in subtabellen te spreiden. Nogmaals, de verdeling wordt over het algemeen bepaald door een duidelijke waarde of lijst met waarden uit een tabel. Dit is een uitstekende methode om te gebruiken als u niet over een efficiënte opslagbeheertechniek beschikt op al uw apparaten. U zou partitionering willen gebruiken om de gegevens willekeurig te verdelen om I/O-knelpunten te voorkomen.
Partitiegewijs deelnemen
Een techniek die wordt gebruikt om tabellen op te splitsen op partities en ze samen te voegen door vergelijkbare partities aan elkaar te koppelen. U heeft bijvoorbeeld een grote tabel met kopers uit de hele Verenigde Staten. U kunt de tabel eerst opsplitsen in verschillende steden en vervolgens enkele steden samenvoegen op basis van de regio in elke staat. Partition-wise join vereenvoudigt uw gegevens en zorgt ervoor dat tabellen kunnen worden gemanipuleerd.
Parallel onveilig
PostgreSQL 11 voert automatisch query-parallellisme uit als de optimizer bepaalt dat dit de snelste manier is om de query te voltooien. Hoe hoger de PostgreSQL-versie die u gebruikt, hoe meer parallelle mogelijkheden uw database zal hebben. Helaas moeten niet alle query's op een parallelle manier worden uitgevoerd, zelfs als dit mogelijk is. Het type query dat u uitvoert, heeft mogelijk specifieke beperkingen en vereist dat slechts één kern alle verwerking voltooit. Dit vertraagt de prestaties van uw systeem, maar het garandeert dat de ontvangen gegevens volledig zijn.
Om ervoor te zorgen dat uw zoekopdrachten nooit in gevaar komen, hebben ontwikkelaars een functie gemaakt met de naam parallel onveilig. U kunt de database-optimizer handmatig overschrijven en verzoeken om de query nooit parallel te laten lopen. Het proces van parallellisme wordt niet uitgevoerd.
Parallellisme binnen de PostgreSQL-database is een functie die alleen maar beter wordt met elke databaseversie. Ook al is de toekomst van technologie onzeker, het lijkt erop dat het gebruik van deze functie niet lang meer zal duren.
Voor meer informatie kunt u het volgende bekijken...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table