In deel 2 van deze serie heb je de mogelijkheid toegevoegd om via de REST API aangebrachte wijzigingen op te slaan in een database met behulp van SQLAlchemy en heb je geleerd hoe je die gegevens kunt serialiseren voor de REST API met behulp van Marshmallow. Het verbinden van de REST API met een database zodat de applicatie wijzigingen kan aanbrengen in bestaande data en nieuwe data kan creëren is geweldig en maakt de applicatie veel bruikbaarder en robuuster.
Dat is echter slechts een deel van de kracht die een database biedt. Een nog krachtigere functie is de R onderdeel van RDBMS systemen:relaties . In een database is een relatie de mogelijkheid om twee of meer tabellen op een zinvolle manier met elkaar te verbinden. In dit artikel leert u hoe u relaties implementeert en uw Person . verandert database in een mini-blog-webtoepassing.
In dit artikel leer je:
- Waarom meer dan één tabel in een database nuttig en belangrijk is
- Hoe tabellen aan elkaar gerelateerd zijn
- Hoe SQLAlchemy u kan helpen relaties te beheren
- Hoe relaties u helpen een mini-blogtoepassing te bouwen
Voor wie is dit artikel bedoeld
Deel 1 van deze serie heeft je begeleid bij het bouwen van een REST API, en deel 2 liet je zien hoe je die REST API aan een database kunt koppelen.
Dit artikel breidt uw programmeergereedschapsriem verder uit. U leert hoe u hiërarchische gegevensstructuren kunt maken die door SQLAlchemy worden weergegeven als een-op-veel-relaties. Bovendien breid je de REST API die je al hebt gebouwd uit om CRUD-ondersteuning (Create, Read, Update en Delete) te bieden voor de elementen in deze hiërarchische structuur.
De webtoepassing die in deel 2 wordt gepresenteerd, zal zijn HTML- en JavaScript-bestanden op belangrijke manieren wijzigen om een meer volledig functionele mini-blogtoepassing te creëren. Je kunt de definitieve versie van de code uit deel 2 bekijken in de GitHub-repository voor dat artikel.
Wacht even terwijl je aan de slag gaat met het maken van relaties en je mini-blogtoepassing!
Aanvullende afhankelijkheden
Er zijn geen nieuwe Python-afhankelijkheden die verder gaan dan wat nodig was voor het artikel in deel 2. U gaat echter twee nieuwe JavaScript-modules in de webtoepassing gebruiken om de zaken eenvoudiger en consistenter te maken. De twee modules zijn de volgende:
- Stuur.js is een template-engine voor JavaScript, net als Jinja2 voor Flask.
- Moment.js is een datetime-parseer- en opmaakmodule die het weergeven van UTC-tijdstempels eenvoudiger maakt.
U hoeft geen van beide te downloaden, omdat de webtoepassing ze rechtstreeks van het Cloudflare CDN (Content Delivery Network) haalt, zoals u al doet voor de jQuery-module.
Persoonsgegevens uitgebreid voor bloggen
In deel 2, de People gegevens bestonden als een woordenboek in de build_database.py Python-code. Dit is wat u gebruikte om de database te vullen met enkele initiële gegevens. Je gaat de People . aanpassen gegevensstructuur om elke persoon een lijst met aan hem gekoppelde notities te geven. De nieuwe People datastructuur ziet er als volgt uit:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Elke persoon in de People woordenboek bevat nu een sleutel genaamd notes , die is gekoppeld aan een lijst met tupels met gegevens. Elke tuple in de notes lijst staat voor een enkele noot met de inhoud en een tijdstempel. De tijdstempels worden geïnitialiseerd (in plaats van dynamisch gemaakt) om de volgorde later in de REST API te demonstreren.
Elke persoon is gekoppeld aan meerdere notities en elke enkele notitie is gekoppeld aan slechts één persoon. Deze hiërarchie van gegevens staat bekend als een een-op-veel-relatie, waarbij een enkel bovenliggend object is gerelateerd aan veel onderliggende objecten. U zult zien hoe deze een-op-veel-relatie wordt beheerd in de database met SQLAlchemy.
Brute Force-aanpak
De database die u hebt gebouwd, heeft de gegevens in een tabel opgeslagen en een tabel is een tweedimensionale reeks rijen en kolommen. Kunnen de People woordenboek hierboven worden weergegeven in een enkele tabel met rijen en kolommen? Het kan op de volgende manier in uw person . zijn database tabel. Helaas wordt er door het opnemen van alle feitelijke gegevens in het voorbeeld een schuifbalk voor de tabel gemaakt, zoals u hieronder zult zien:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Cool, een mini-blogtoepassing! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Dit kan handig zijn | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Nou, best wel handig | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Ik ga echt diepgaande observaties maken | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Misschien zijn ze duidelijker dan ik dacht | 2019-02-06 22:17:54 |
| 6 | Pasen | Konijn | 2018-08-08 21:16:01 | Heeft iemand mijn paaseieren gezien? | 2019-01-07 22:47:54 |
| 7 | Pasen | Konijn | 2018-08-08 21:16:01 | Ik ben erg laat met het afleveren van deze! | 2019-04-06 22:17:54 |
De bovenstaande tabel zou echt werken. Alle gegevens worden weergegeven en een enkele persoon is gekoppeld aan een verzameling verschillende notities.
Voordelen
Conceptueel heeft de bovenstaande tabelstructuur het voordeel dat deze relatief eenvoudig te begrijpen is. Je zou zelfs kunnen stellen dat de gegevens bewaard kunnen worden in een plat bestand in plaats van in een database.
Vanwege de tweedimensionale tabelstructuur zou u deze gegevens in een spreadsheet kunnen opslaan en gebruiken. Spreadsheets zijn behoorlijk in gebruik genomen als gegevensopslag.
Nadelen
Hoewel de bovenstaande tabelstructuur zou werken, heeft deze enkele echte nadelen.
Om de verzameling aantekeningen weer te geven worden alle gegevens van elke persoon herhaald voor elke unieke aantekening, de persoonsgegevens zijn dus overbodig. Dit is niet zo'n groot probleem voor uw persoonsgegevens, omdat er niet zoveel kolommen zijn. Maar stel je voor dat een persoon veel meer kolommen had. Zelfs met grote schijven kan dit een opslagprobleem worden als je te maken hebt met miljoenen rijen gegevens.
Het hebben van redundante gegevens zoals deze kan na verloop van tijd tot onderhoudsproblemen leiden. Wat als de paashaas bijvoorbeeld besloot dat een naamsverandering een goed idee was. Om dit te doen, zou elk record met de naam van de paashaas moeten worden bijgewerkt om de gegevens consistent te houden. Dit soort werk tegen de database kan leiden tot inconsistentie van gegevens, vooral als het werk wordt gedaan door een persoon die handmatig een SQL-query uitvoert.
Het benoemen van kolommen wordt lastig. In de bovenstaande tabel staat een timestamp kolom die wordt gebruikt om de aanmaak- en updatetijd van een persoon in de tabel bij te houden. U wilt ook vergelijkbare functionaliteit hebben voor het maken en bijwerken van een notitie, maar omdat timestamp is al gebruikt, een verzonnen naam van note_timestamp wordt gebruikt.
Wat als u extra een-op-veel-relaties wilt toevoegen aan de person tafel? Bijvoorbeeld om de kinderen of telefoonnummers van een persoon op te nemen. Elke persoon kan meerdere kinderen en meerdere telefoonnummers hebben. Dit kan relatief eenvoudig gedaan worden met de Python People woordenboek hierboven door children toe te voegen en phone_numbers sleutels met nieuwe lijsten met de gegevens.
Maar die nieuwe een-op-veel-relaties vertegenwoordigen in uw person bovenstaande databasetabel wordt aanzienlijk moeilijker. Elke nieuwe een-op-veel-relatie verhoogt het aantal rijen dat nodig is om deze voor elke afzonderlijke invoer in de onderliggende gegevens aanzienlijk te vertegenwoordigen. Bovendien worden de problemen in verband met gegevensredundantie groter en moeilijker op te lossen.
Ten slotte zouden de gegevens die u terugkrijgt uit de bovenstaande tabelstructuur niet erg Pythonisch zijn:het zou gewoon een grote lijst met lijsten zijn. SQLAlchemy zou je niet veel kunnen helpen omdat de relatie er niet is.
Relationele databasebenadering
Op basis van wat je hierboven hebt gezien, wordt het duidelijk dat het vrij snel onhandelbaar wordt om zelfs een redelijk complexe dataset in een enkele tabel weer te geven. Welk alternatief biedt een database dan? Dit is waar de R onderdeel van RDBMS databases spelen een rol. Het vertegenwoordigen van relaties neemt de hierboven geschetste nadelen weg.
In plaats van te proberen hiërarchische gegevens in een enkele tabel weer te geven, worden de gegevens opgedeeld in meerdere tabellen, met een mechanisme om ze aan elkaar te relateren. De tabellen zijn opgedeeld langs verzamellijnen, dus voor uw People woordenboek hierboven, betekent dit dat er een tabel zal zijn die mensen vertegenwoordigt en een andere die noten vertegenwoordigt. Dit brengt je oorspronkelijke person terug tabel, die er als volgt uitziet:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pasen | Konijn | 2018-08-08 21:16:01.886834 |
Om de nieuwe notitie-informatie weer te geven, maakt u een nieuwe tabel met de naam note . (Denk aan onze enkelvoudige tabelnaamgevingsconventie.) De tabel ziet er als volgt uit:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Cool, een mini-blogtoepassing! | 2019-01-06 22:17:54 |
| 2 | 1 | Dit kan handig zijn | 2019-01-08 22:17:54 |
| 3 | 1 | Nou, best wel handig | 2019-03-06 22:17:54 |
| 4 | 2 | Ik ga echt diepgaande observaties maken | 2019-01-07 22:17:54 |
| 5 | 2 | Misschien zijn ze duidelijker dan ik dacht | 2019-02-06 22:17:54 |
| 6 | 3 | Heeft iemand mijn paaseieren gezien? | 2019-01-07 22:47:54 |
| 7 | 3 | Ik ben erg laat met het afleveren van deze! | 2019-04-06 22:17:54 |
Merk op dat, net als de person tabel, de note tabel heeft een unieke identificatie genaamd note_id , wat de primaire sleutel is voor de note tafel. Een ding dat niet duidelijk is, is de toevoeging van de person_id waarde in de tabel. Waar wordt dat voor gebruikt? Dit is wat de relatie met de person creëert tafel. Terwijl note_id is de primaire sleutel voor de tabel, person_id is wat bekend staat als een externe sleutel.
De externe sleutel geeft elke invoer in de note tabel de primaire sleutel van de person opnemen waarmee het is geassocieerd. Hiermee kan SQLAlchemy alle notities verzamelen die bij elke persoon horen door de person.person_id te verbinden primaire sleutel tot de note.person_id externe sleutel, een relatie creëren.
Voordelen
Door de gegevensset in twee tabellen te splitsen en het concept van een externe sleutel te introduceren, hebt u de gegevens een beetje ingewikkelder gemaakt om over na te denken, en hebt u de nadelen van een enkele tabelweergave opgelost. SQLAlchemy zal je helpen om de toegenomen complexiteit vrij gemakkelijk te coderen.
De gegevens zijn niet langer redundant in de database. Er is slechts één persoonsvermelding voor elke persoon die u in de database wilt opslaan. Dit lost het opslagprobleem onmiddellijk op en vereenvoudigt het onderhoudsprobleem aanzienlijk.
Als de paashaas toch van naam wil veranderen, dan hoef je maar één rij in de person te veranderen tabel, en al het andere dat met die rij te maken heeft (zoals de note tabel) zou onmiddellijk profiteren van de verandering.
Kolomnaamgeving is consistenter en zinvoller. Omdat persoons- en notitiegegevens in afzonderlijke tabellen voorkomen, kan het tijdstempel voor het maken en bijwerken consistent worden genoemd in beide tabellen, omdat er geen conflict is voor namen tussen tabellen.
Bovendien hoeft u niet langer permutaties van elke rij te maken voor nieuwe een-op-veel-relaties die u mogelijk wilt vertegenwoordigen. Neem onze children en phone_numbers voorbeeld van vroeger. Om dit te implementeren zou child . nodig zijn en phone_number tafels. Elke tabel zou een externe sleutel van person_id . bevatten relateren aan de person tafel.
Als u SQLAlchemy gebruikt, zouden de gegevens die u terugkrijgt uit de bovenstaande tabellen direct nuttiger zijn, omdat u een object voor elke personenrij krijgt. Dat object heeft attributen genoemd die overeenkomen met de kolommen in de tabel. Een van die attributen is een Python-lijst met de gerelateerde notitie-objecten.
Nadelen
Waar de brute force-benadering eenvoudiger te begrijpen was, maakt het concept van externe sleutels en relaties het denken over de gegevens wat abstracter. Over deze abstractie moet worden nagedacht voor elke relatie die u tussen tabellen tot stand brengt.
Gebruik maken van relaties betekent zich committeren aan het gebruik van een databasesysteem. Dit is een ander hulpmiddel om te installeren, te leren en te onderhouden dat verder gaat dan de applicatie die de gegevens daadwerkelijk gebruikt.
SQLAalchemy-modellen
Om de twee bovenstaande tabellen en de relatie daartussen te gebruiken, moet u SQLAlchemy-modellen maken die op de hoogte zijn van beide tabellen en de relatie ertussen. Hier is de SQLAlchemy Person model uit deel 2, bijgewerkt met een relatie met een verzameling notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Regels 1 tot 8 van de bovenstaande Python-klasse zien er precies hetzelfde uit als wat u eerder in deel 2 hebt gemaakt. Regels 9 tot 16 creëren een nieuw attribuut in de Person klasse genaamd notes . Deze nieuwe notes attributen wordt gedefinieerd in de volgende regels code:
-
Lijn 9: Net als de andere attributen van de klasse, creëert deze regel een nieuw attribuut genaamd
notesen stelt het gelijk aan een instantie van een object genaamddb.relationship. Dit object creëert de relatie die u toevoegt aan dePersonclass en wordt gemaakt met alle parameters die in de volgende regels zijn gedefinieerd. -
Lijn 10: De stringparameter
'Note'definieert de SQLAlchemy-klasse die dePersonklasse zal te maken hebben met. DeNoteclass is nog niet gedefinieerd, daarom is het hier een string. Dit is een voorwaartse verwijzing en helpt bij het omgaan met problemen die de volgorde van definities kan veroorzaken wanneer iets nodig is dat pas later in de code wordt gedefinieerd. De'Note'string staat dePerson. toe class om deNote. te vinden class tijdens runtime, wat na beidePersonenNotezijn gedefinieerd. -
Lijn 11: De
backref='person'parameter is lastiger. Het creëert een zogenaamde achterwaartse referentie inNotevoorwerpen. Elke instantie van eenNoteobject zal een attribuut bevatten genaamdperson. Depersonattribuut verwijst naar het bovenliggende object dat een bepaaldeNoteinstantie wordt geassocieerd met. Een verwijzing hebben naar het bovenliggende object (personin dit geval) in het kind kan erg handig zijn als uw code herhalingen van notities maakt en informatie over de ouder moet bevatten. Dit gebeurt verrassend vaak in code voor weergaveweergave. -
Lijn 12: De
cascade='all, delete, delete-orphan'parameter bepaalt hoe instanties van notitieobjecten moeten worden behandeld wanneer wijzigingen worden aangebracht in de bovenliggendePersonvoorbeeld. Bijvoorbeeld, wanneer eenPersonobject is verwijderd, zal SQLAlchemy de SQL maken die nodig is om dePerson. te verwijderen uit de databank. Bovendien vertelt deze parameter het om ook alleNote. te verwijderen instanties die ermee verband houden. U kunt meer lezen over deze opties in de SQLAlchemy-documentatie. -
Lijn 13: De
single_parent=Trueparameter is vereist alsdelete-orphanmaakt deel uit van de vorigecascadeparameter. Dit vertelt SQLAlchemy om verweesdeNote. niet toe te staan instanties (eenNotezonder ouderPersonobject) bestaan omdat elkeNoteheeft een alleenstaande ouder. -
Lijn 14: De
order_by='desc(Note.timestamp)'parameter vertelt SQLAlchemy hoe deNote. moet worden gesorteerd instanties die zijn gekoppeld aan eenPerson. Wanneer eenPersonobject wordt opgehaald, standaard denotesattributenlijst bevatNoteobjecten in een onbekende volgorde. De SQLAlchemydesc(...)functie sorteert de notities in aflopende volgorde van nieuw naar oud. Als deze regel in plaats daarvanorder_by='Note.timestamp'. was , zou SQLAlchemy standaard deasc(...). gebruiken functie, en sorteer de noten in oplopende volgorde, van oud naar nieuw.
Nu uw Person model heeft de nieuwe notes attribuut, en dit vertegenwoordigt de een-op-veel-relatie met Note objecten, moet u een SQLAlchemy-model definiëren voor een Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
De Note class definieert de attributen waaruit een notitie bestaat, zoals te zien is in ons voorbeeld note databasetabel van bovenaf. De attributen worden hier gedefinieerd:
-
Lijn 1 maakt de
Noteklasse, overervend vandb.Model, precies zoals je eerder deed bij het maken van dePersonklasse. -
Lijn 2 vertelt de klas welke databasetabel moet worden gebruikt om
Note. op te slaan objecten. -
Lijn 3 maakt de
note_idattribuut, definiëren als een geheel getal en als de primaire sleutel voor deNotevoorwerp. -
Lijn 4 maakt de
person_idattribuut, en definieert het als de refererende sleutel, met betrekking tot deNoteklasse aan dePersonklas met behulp van deperson.person_idhoofdsleutel. Dit, en dePerson.notesattribuut, zo weet SQLAlchemy wat te doen bij interactie metPersonenNoteobjecten. -
Lijn 5 maakt de
contentattribuut, dat de eigenlijke tekst van de notitie bevat. Denullable=Falseparameter geeft aan dat het goed is om nieuwe notities te maken die geen inhoud hebben. -
Lijn 6 maakt de
timestampattribuut, en precies zoals dePersonklasse, dit bevat de aanmaak- of updatetijd voor een bepaaldeNoteinstantie.
De database initialiseren
Nu u de Person . heeft bijgewerkt en maakte de Note modellen, gebruikt u ze om de testdatabase people.db opnieuw op te bouwen . U doet dit door de build_database.py . bij te werken code uit deel 2. Zo ziet de code eruit:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
De bovenstaande code komt uit deel 2, met een paar wijzigingen om de een-op-veel-relatie tussen Person te creëren en Note . Hier zijn de bijgewerkte of nieuwe regels die aan de code zijn toegevoegd:
-
Lijn 4 is bijgewerkt om de
Note. te importeren klasse eerder gedefinieerd. -
Regels 7 t/m 39 bevatten de bijgewerkte
PEOPLEwoordenboek met onze persoonsgegevens, samen met de lijst met notities die aan elke persoon zijn gekoppeld. Deze gegevens worden in de database ingevoegd. -
Lijnen 49 tot 61 herhaal de
PEOPLEwoordenboek, waarbij elkeperson. wordt opgehaald op zijn beurt en gebruiken om een Person. te maken voorwerp. -
Lijn 53 herhaalt de
person.noteslijst, waarbij elkenote. wordt opgehaald op zijn beurt. -
Lijn 54 pakt de
contentuit entimestampvan elkenotetupel. -
Lijn 55 tot 60 maakt een
Noteobject en voegt het toe aan de verzameling persoonsnotities met behulp vanp.notes.append(). -
Lijn 61 voegt de
Persontoe objectpnaar de databasesessie. -
Lijn 63 voert alle activiteiten in de sessie door naar de database. Op dit punt worden alle gegevens weggeschreven naar de
personennotetabellen in depeople.dbdatabasebestand.
Dat zie je bij het werken met de notes verzameling in de Person objectinstantie p is net als werken met elke andere lijst in Python. SQLAlchemy zorgt voor de onderliggende een-op-veel relatie-informatie wanneer de db.session.commit() er wordt gebeld.
Bijvoorbeeld, net als een Person instantie heeft zijn primaire sleutelveld person_id geïnitialiseerd door SQLAlchemy wanneer het is vastgelegd in de database, instanties van Note zullen hun primaire sleutelvelden worden geïnitialiseerd. Bovendien is de Note buitenlandse sleutel person_id wordt ook geïnitialiseerd met de primaire sleutelwaarde van de Person instantie waaraan het is gekoppeld.
Hier is een voorbeeld van een Person object vóór de db.session.commit() in een soort pseudocode:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Hier is het voorbeeld Person object na de db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Het belangrijke verschil tussen de twee is dat de primaire sleutel van de Person en Note objecten is geïnitialiseerd. De database-engine zorgde hiervoor omdat de objecten werden gemaakt vanwege de functie voor automatisch verhogen van primaire sleutels die in deel 2 is besproken.
Bovendien is de person_id buitenlandse sleutel in alle Note instances is geïnitialiseerd om te verwijzen naar het bovenliggende item. Dit gebeurt vanwege de volgorde waarin de Person en Note objecten worden gemaakt in de database.
SQLAlchemy is op de hoogte van de relatie tussen Person en Note voorwerpen. Wanneer een Person object is toegewijd aan de person databasetabel, krijgt SQLAlchemy de person_id primaire sleutelwaarde. Die waarde wordt gebruikt om de externe sleutelwaarde van person_id . te initialiseren in een Note object voordat het wordt vastgelegd in de database.
SQLAlchemy zorgt voor dit database-huishoudelijk werk vanwege de informatie die u hebt doorgegeven toen de Person.notes attribuut is geïnitialiseerd met de db.relationship(...) voorwerp.
Bovendien is de Person.timestamp attribuut is geïnitialiseerd met het huidige tijdstempel.
Het uitvoeren van de build_database.py programma vanaf de opdrachtregel (in de virtuele omgeving wordt de database opnieuw gemaakt met de nieuwe toevoegingen, zodat deze klaar is voor gebruik met de webtoepassing. Deze opdrachtregel zal de database opnieuw opbouwen:
$ python build_database.py
De build_database.py hulpprogramma voert geen berichten uit als het succesvol wordt uitgevoerd. Als er een uitzondering wordt gegenereerd, wordt er een fout op het scherm afgedrukt.
REST API bijwerken
U heeft de SQLAlchemy-modellen bijgewerkt en gebruikt om de people.db . bij te werken databank. Nu is het tijd om de REST API bij te werken om toegang te bieden tot de nieuwe notitiegegevens. Dit is de REST API die je in deel 2 hebt gebouwd:
| Actie | HTTP-werkwoord | URL-pad | Beschrijving |
|---|---|---|---|
| Maken | POST | /api/people | URL om een nieuwe persoon aan te maken |
| Lees | GET | /api/people | URL om een verzameling mensen te lezen |
| Lees | GET | /api/people/{person_id} | URL om één persoon te lezen op person_id |
| Bijwerken | PUT | /api/people/{person_id} | URL om een bestaande persoon bij te werken via person_id |
| Verwijderen | DELETE | /api/people/{person_id} | URL om een bestaande persoon te verwijderen via person_id |
De bovenstaande REST-API biedt HTTP-URL-paden naar verzamelingen van dingen en naar de dingen zelf. U kunt een lijst met mensen krijgen of met één persoon communiceren uit die lijst met mensen. Deze padstijl verfijnt wat van links naar rechts wordt geretourneerd, en wordt gaandeweg gedetailleerder.
Je gaat door met dit patroon van links naar rechts om gedetailleerder te worden en toegang te krijgen tot de notitieverzamelingen. Dit is de uitgebreide REST-API die u maakt om notities te maken voor de miniblog-webtoepassing:
| Actie | HTTP-werkwoord | URL-pad | Beschrijving |
|---|---|---|---|
| Maken | POST | /api/people/{person_id}/notes | URL om een nieuwe notitie te maken |
| Lees | GET | /api/people/{person_id}/notes/{note_id} | URL om de enkele notitie van een enkele persoon te lezen |
| Bijwerken | PUT | api/people/{person_id}/notes/{note_id} | URL om de enkele notitie van een enkele persoon bij te werken |
| Verwijderen | DELETE | api/people/{person_id}/notes/{note_id} | URL om de enkele notitie van een enkele persoon te verwijderen |
| Lees | GET | /api/notes | URL om alle notities voor alle mensen te sorteren op note.timestamp |
Er zijn twee variaties in de notes onderdeel van de REST API vergeleken met de conventie die wordt gebruikt in de people sectie:
-
Er is geen URL gedefinieerd om alle
notes. te krijgen gekoppeld aan een persoon, alleen een URL om een enkele notitie te krijgen. Dit zou de REST API in zekere zin compleet hebben gemaakt, maar de webtoepassing die u later gaat maken, heeft deze functionaliteit niet nodig. Daarom is het weggelaten. -
Er is de opname van de laatste URL
/api/notes. This is a convenience method created for the web application. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml file.
Opmerking:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relatie. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes lijst. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person verbonden.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Opmerking:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or operatie. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Lijn 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
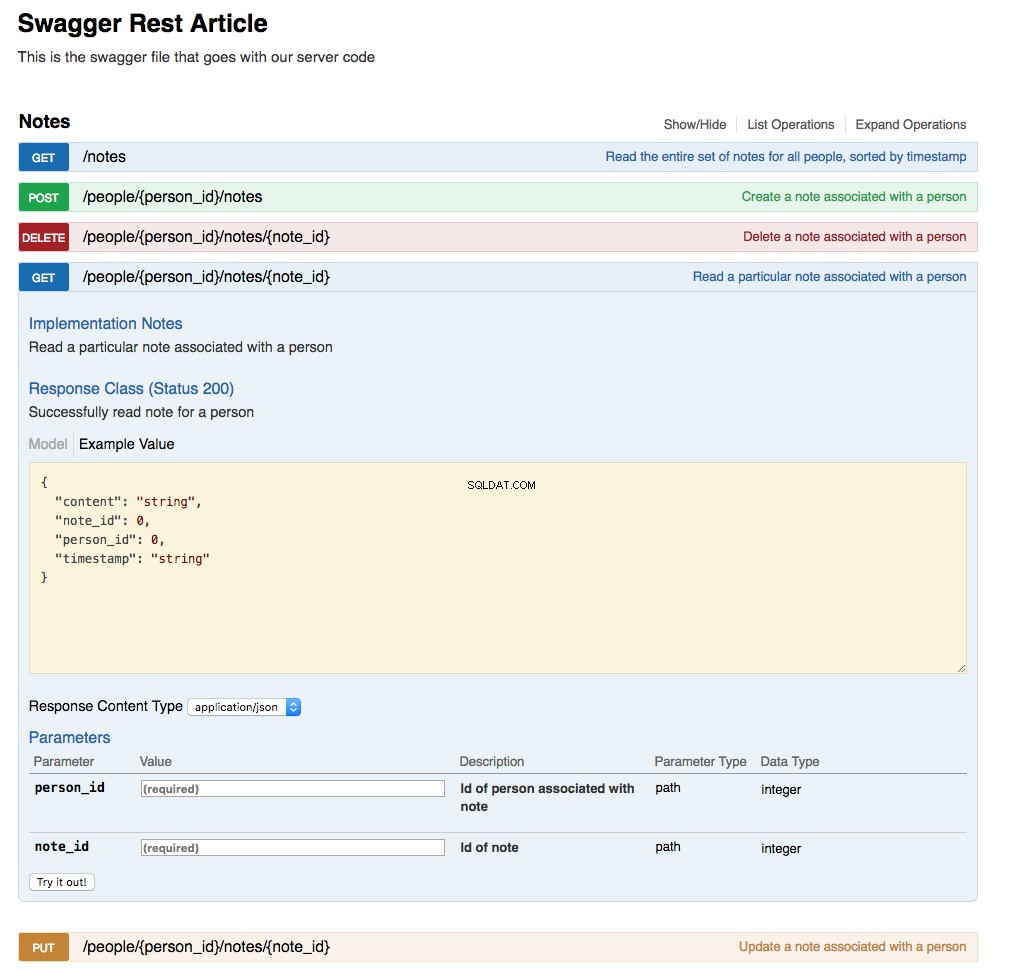
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
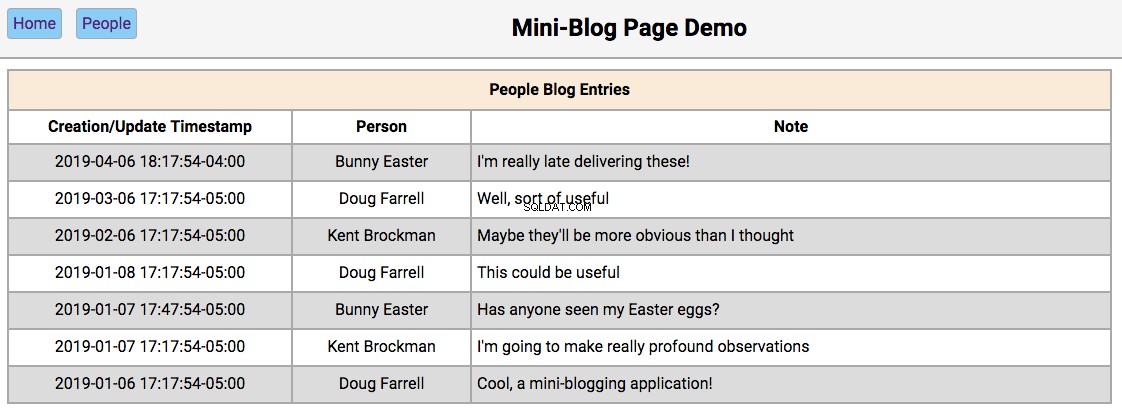
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
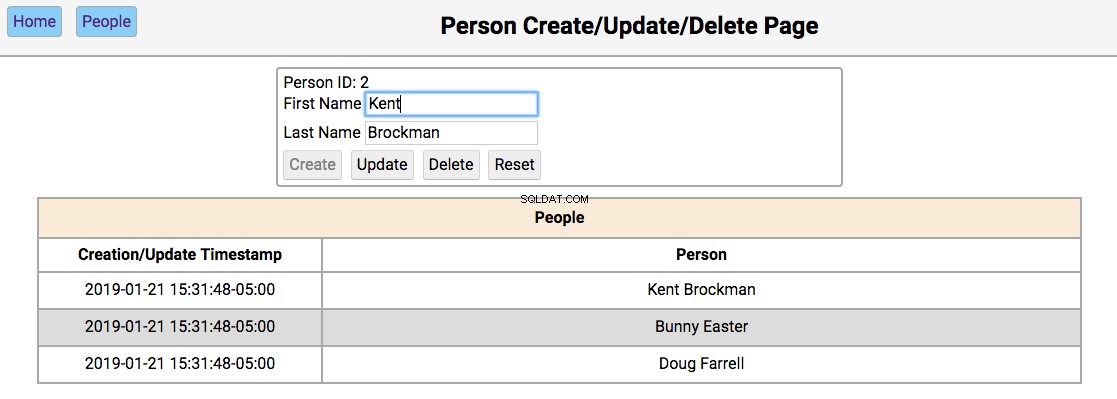
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete toetsen.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Verwijderen , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
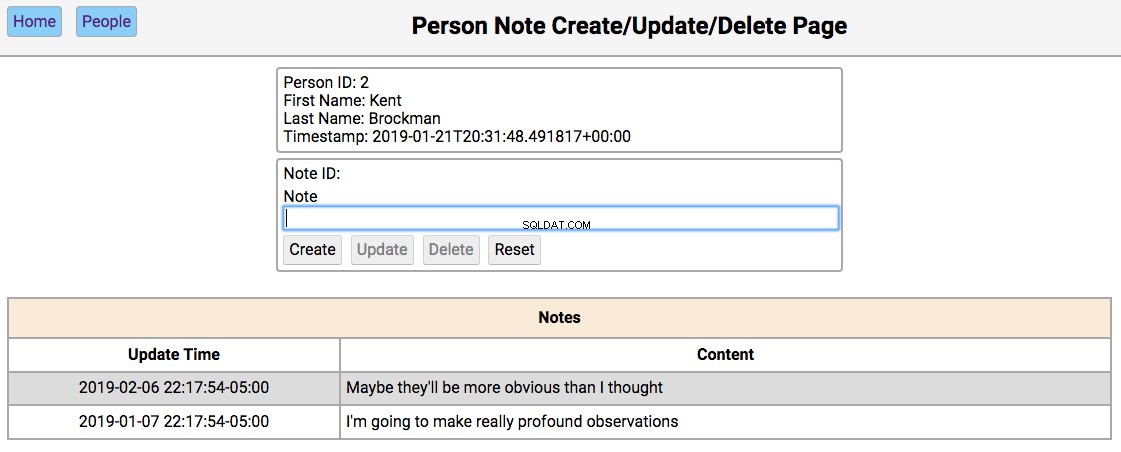
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete toetsen.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Verwijderen , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusie
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »