Een paar dagen geleden was de release van een nieuwe versie van ClusterControl, de 1.7.2, waar we verschillende nieuwe functies kunnen zien, een van de belangrijkste is de ondersteuning voor TimescaleDB.
TimescaleDB is een open-source tijdreeksdatabase die is geoptimaliseerd voor snelle opname en complexe query's die volledige SQL ondersteunt. Het is gebaseerd op PostgreSQL en biedt het beste van NoSQL en relationele werelden voor tijdreeksgegevens. TimescaleDB ondersteunt streaming-replicatie als de primaire replicatiemethode, die kan worden gebruikt in een setup met hoge beschikbaarheid. PostgreSQL wordt echter niet geleverd met automatische failover en dit is een probleem in een productieomgeving met hoge beschikbaarheid. Handmatige failover houdt meestal in dat een mens wordt opgeroepen en een computer moet vinden, moet inloggen op de systemen, moet begrijpen wat er aan de hand is, voordat de failover-procedures worden gestart. Dit vertaalt zich in een lange downtime. Gelukkig is er een manier om failovers te automatiseren met ClusterControl, dat nu TimescaleDB ondersteunt.
In deze blog zullen we zien hoe u een gerepliceerde TimescaleDB-installatie met automatische failover in slechts een paar klikken implementeert met behulp van ClusterControl. We zullen ook zien hoe je een enkel database-eindpunt voor applicaties kunt toevoegen via HAProxy. Als eerste vereiste moet u versie 1.7.2 van ClusterControl op een speciale host of VM installeren.
TimescaleDB implementeren
Om een nieuwe installatie van TimescaleDB vanuit ClusterControl uit te voeren, selecteert u eenvoudig de optie "Deploy" en volgt u de instructies die verschijnen. Houd er rekening mee dat als u al een TimescaleDB-instantie heeft, u in plaats daarvan 'Bestaande server/database importeren' moet selecteren.
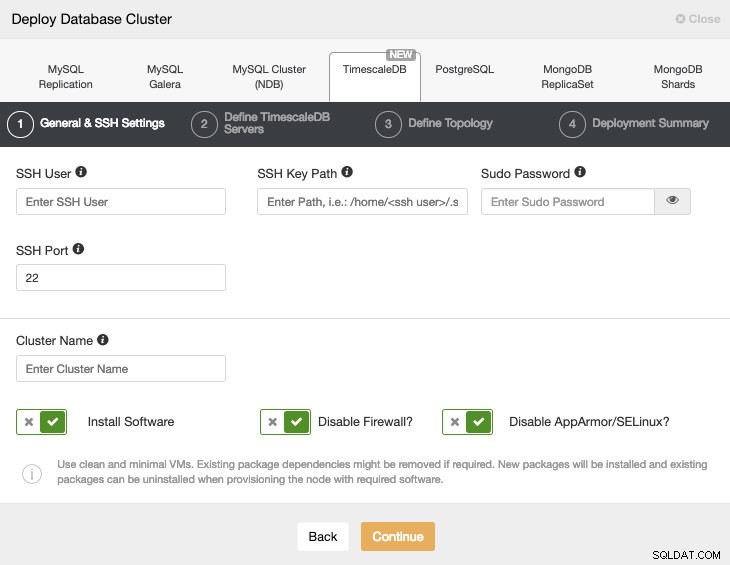
Bij het selecteren van TimescaleDB moeten we Gebruiker, Sleutel of Wachtwoord en poort specificeren om via SSH verbinding te maken met onze TimescaleDB-hosts. We hebben ook een naam nodig voor ons nieuwe cluster en als we willen dat ClusterControl de bijbehorende software en configuraties voor ons installeert.
Controleer hier de gebruikersvereiste van ClusterControl voor deze taak.
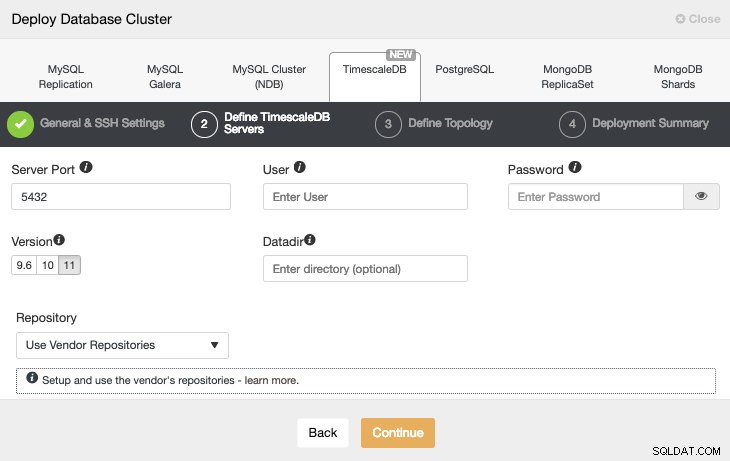
Na het instellen van de SSH-toegangsinformatie, moeten we de databasegebruiker, -versie en datadir (optioneel) definiëren. We kunnen ook specificeren welke repository we moeten gebruiken.
In de volgende stap moeten we onze servers toevoegen aan het cluster dat we gaan maken.
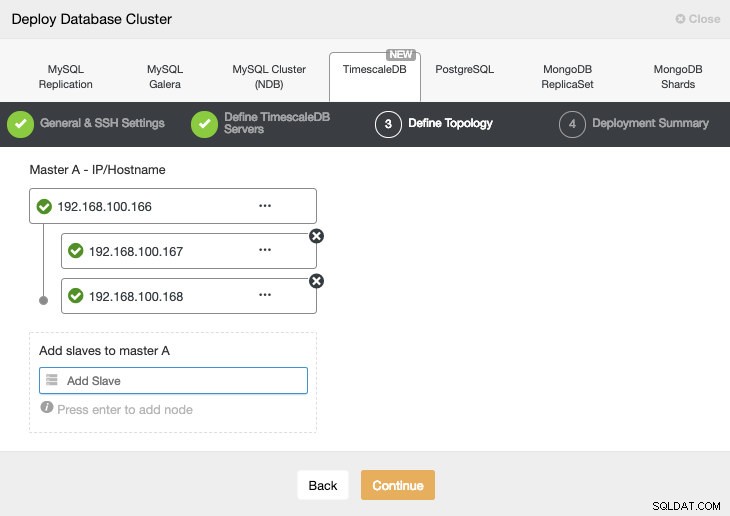
Bij het toevoegen van onze servers kunnen we IP of hostnaam invoeren.
In de laatste stap kunnen we kiezen of onze replicatie synchroon of asynchroon zal zijn.
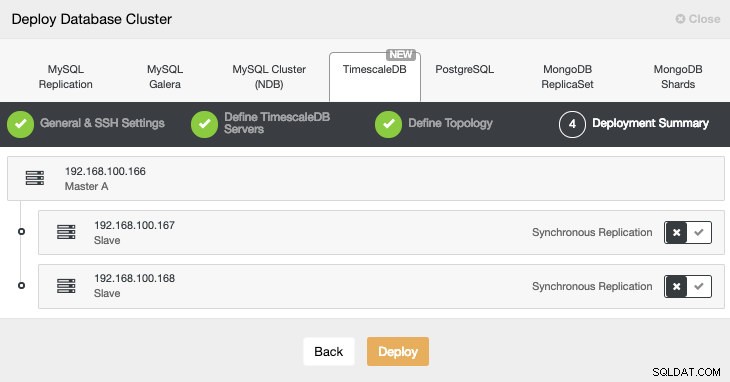
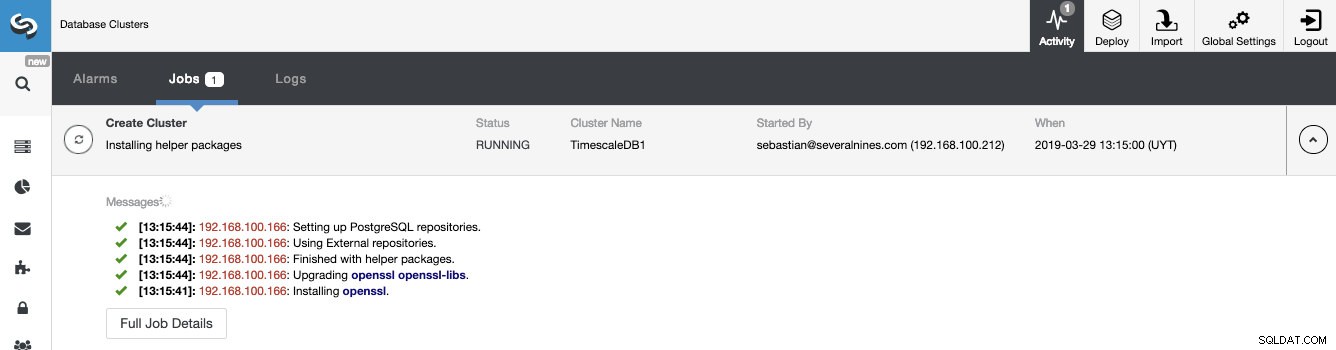
We kunnen de status van het maken van ons nieuwe cluster volgen via de ClusterControl-activiteitenmonitor.
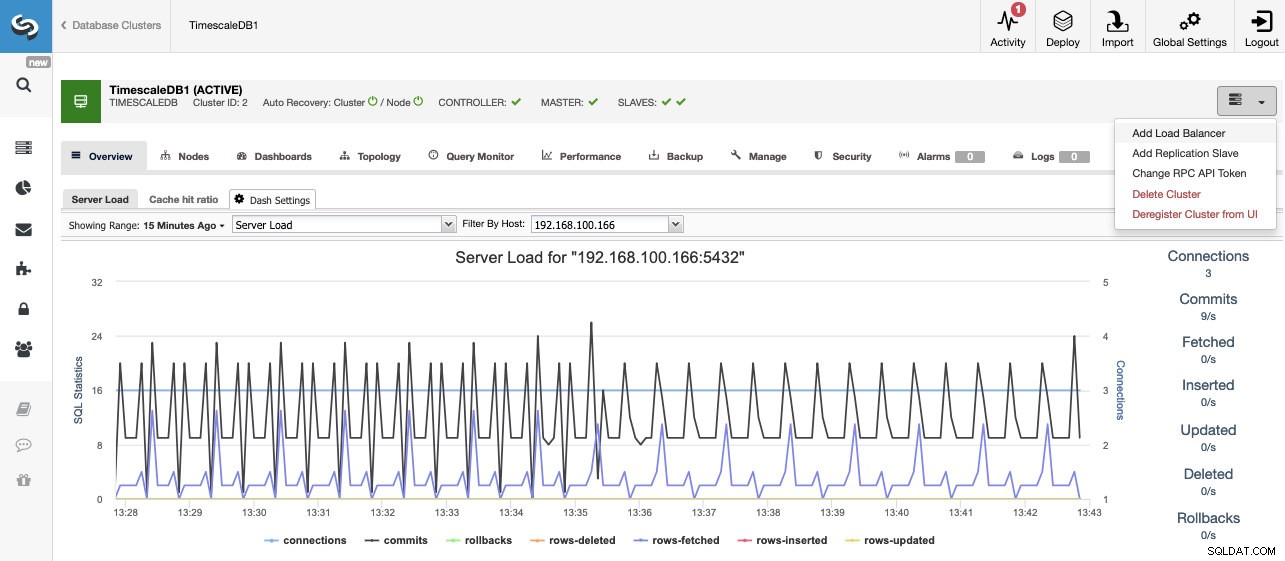
Zodra de taak is voltooid, kunnen we ons nieuwe TimescaleDB-cluster zien in het hoofdscherm van ClusterControl.

Zodra we ons cluster hebben gemaakt, kunnen we er verschillende taken op uitvoeren, zoals het toevoegen van een load balancer (HAProxy) of een nieuwe replica.
TijdschaalDB schalen
Als we naar clusteracties gaan en "Replicatieslave toevoegen" selecteren, kunnen we een nieuwe replica maken of een bestaande TimescaleDB-database als replica toevoegen.
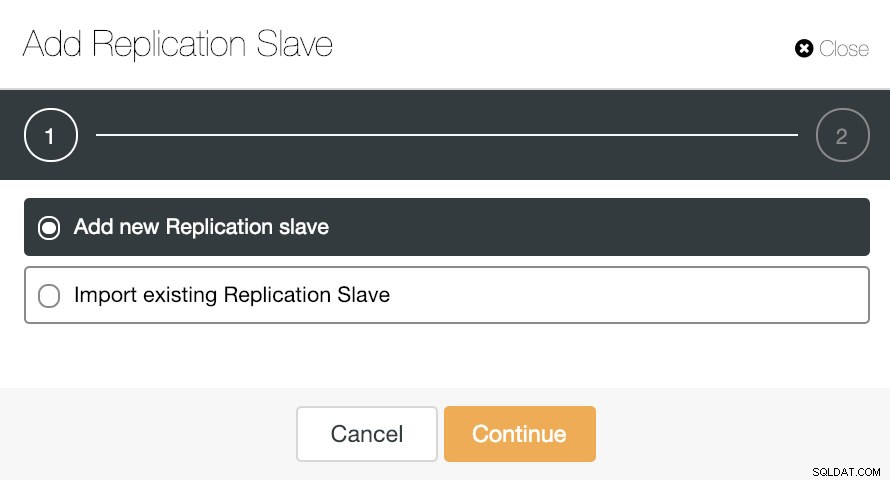
Laten we eens kijken hoe het toevoegen van een nieuwe replicatieslave een heel gemakkelijke taak kan zijn.
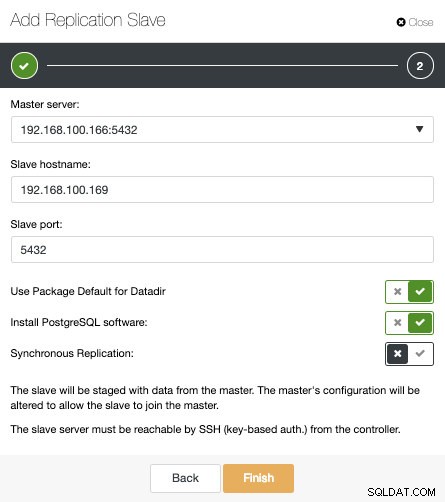
Zoals je in de afbeelding kunt zien, hoeven we alleen onze Master-server te kiezen, het IP-adres voor onze nieuwe slave-server en de databasepoort in te voeren. Vervolgens kunnen we kiezen of we willen dat ClusterControl de software voor ons installeert en of de replicatieslave synchroon of asynchroon moet zijn.
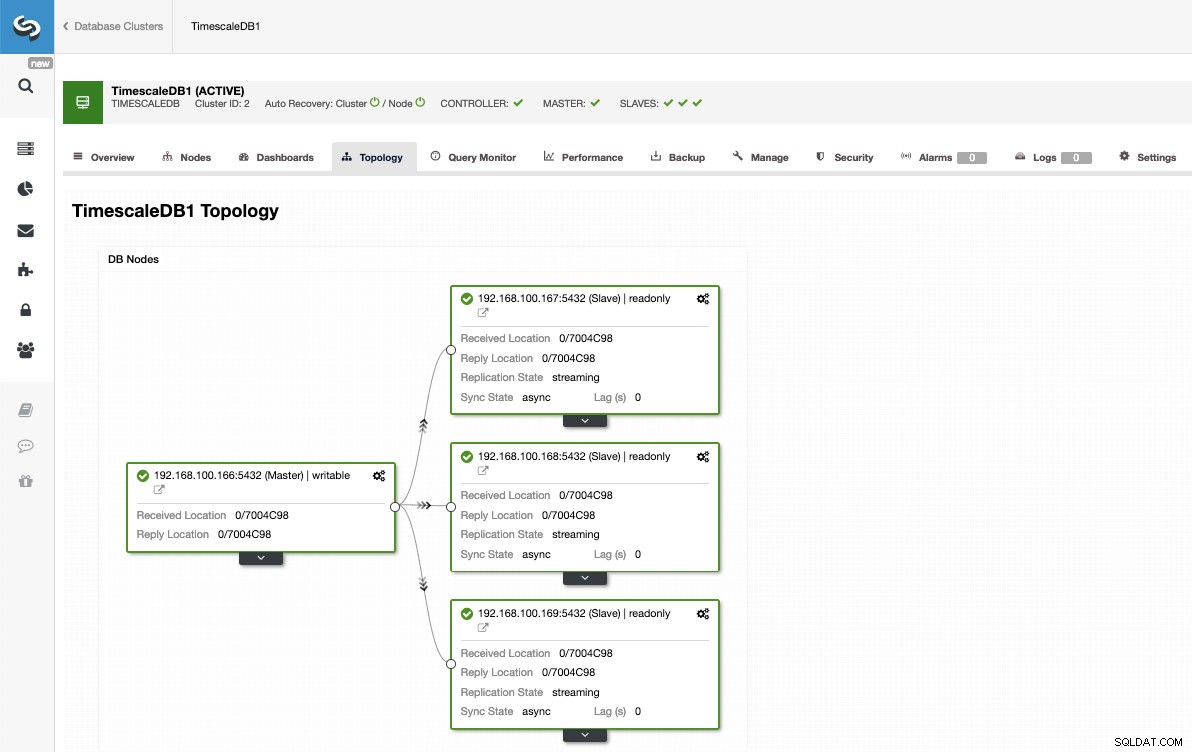
Op deze manier kunnen we zoveel replica's toevoegen als we willen en het leesverkeer ertussen spreiden met behulp van een load balancer, die we ook kunnen implementeren met ClusterControl.
Vanuit ClusterControl kunt u met één klik ook verschillende beheertaken uitvoeren, zoals Reboot Host, Rebuild Replication Slave of Promote Slave.
Conclusie
Zoals we hierboven hebben gezien, kunt u TimescaleDB nu implementeren met ClusterControl. Eenmaal geïmplementeerd, biedt ClusterControl een hele reeks functies, van bewaking, waarschuwingen, automatische failover, back-up, herstel op een bepaald tijdstip, back-upverificatie tot het schalen van leesreplica's. Dit kan u helpen om TimescaleDB op een vriendelijke en intuïtieve manier te beheren.