Met de introductie van Azure SQL Database en de toevoeging van meer functionaliteit in v12, beginnen databasebeheerders te merken dat hun organisaties meer geïnteresseerd zijn in het verplaatsen van databases naar dit platform.
Ik ben onlangs meer in Azure SQL Database gaan duiken om te zien wat er drastisch verschilt van het ondersteunen van de box-versie in datacenters over de hele wereld en Azure SQL Database. In mijn vorige artikel, "Tuning:een goede plek om te beginnen", heb ik mijn aanpak behandeld om aan de slag te gaan met het afstemmen van SQL Server. Ik besloot dit te vergelijken met Azure SQL Database om de belangrijkste verschillen te ontdekken.
In mijn oorspronkelijke artikel ben ik begonnen met algemene instellingen op instantieniveau die ik zie genegeerd of als standaard gelaten, evenals onderhoudsitems. Deze omvatten geheugen, maxdop, kostendrempel voor parallellisme, optimaliseren voor ad-hocworkloads en het configureren van tempdb. Met Azure SQL Database bent u niet verantwoordelijk voor het exemplaar en kunt u deze instellingen niet wijzigen. Azure SQL Database is een Platform as a Service (PaaS), wat betekent dat Microsoft de instantie voor u beheert; je bent gewoon een huurder met je database of databases.
U bent echter verantwoordelijk voor het onderhoud, dus u moet statistieken bijwerken en indexfragmentatie afhandelen zoals u doet voor het boxproduct. Voor die taken heb ik geconstateerd dat de meeste klanten die processen beheren met een speciale Azure-VM met SQL Server en SQL Server Agent met geplande taken.
Als ik de stappen van mijn artikel volg, zijn de volgende gebieden waar ik naar ga kijken, bestands- en wachtstatistieken en dure zoekopdrachten. Als u zich afvraagt of dit aspect van uw werk als productie-dba met on-premises databases zal veranderen wanneer u met Azure SQL Database werkt, is het antwoord niet echt . Bestands- en wachtstatistieken zijn er nog steeds, maar we moeten ze op een iets andere manier bereiken. Als je gewend bent de scripts van Paul Randal te gebruiken voor bestandsstatistieken en wachtstatistieken (of de zoekopdrachten voor bestandsstatistieken voor een bepaalde periode en wachtstatistieken voor een bepaalde periode), dan moet je enkele wijzigingen aanbrengen om die scripts om te werken met Azure SQL Database.
Toen ik Paul's script voor bestandsstatistieken voor het eerst probeerde, mislukte het omdat Azure SQL Database geen ondersteuning bood voor sys.master_files :
Ongeldige objectnaam 'sys.master_files'.
Ik heb het script kunnen aanpassen om sys.databases te gebruiken in de join om de databasenaam te krijgen en verwijder het gedeelte van het script om de individuele bestandsnamen te krijgen, aangezien we slechts met een enkel gegevens- en logbestand te maken hebben. Je kunt de wijzigingen zien die ik moest maken in de volgende afbeelding:
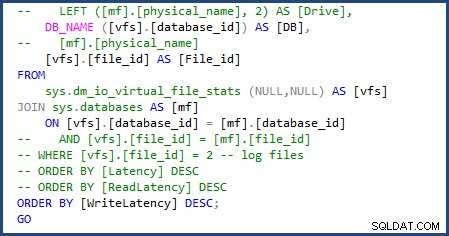
Toen ik daarna het script file-stats-over-a-period-of-time uitvoerde en dezelfde wijziging aanbracht in sys.databases en het verwijderen van de verwijzingen naar file_id in de join is het mislukt omdat Azure SQL Database v12 geen globale ##temp-tabellen ondersteunt.
Nadat ik alle globale ##temp-tabellen in lokaal had veranderd, had ik een ander probleem met het script dat bestaande tijdelijke tabellen die werden gebruikt niet kon verwijderen, omdat er niet rechtstreeks naar lokale #temp-tabellen kan worden verwezen zoals globale ##temp-tabellen dat kunnen, maar dit was gemakkelijk te verhelpen door dergelijke controles te wijzigen in OBJECT_ID('tempdb..#SQLskillsStats1') . Ik heb dezelfde wijziging aangebracht voor de tweede tijdelijke tabel en het codeblok aan het begin en einde van het script bijgewerkt.
Ik moest nog een wijziging aanbrengen en [mf].[type_desc] verwijderen en LEFT ([mf].[physical_name], 2) AS [Drive] aangezien die afhankelijk zijn van sys.master_files . Het script was toen compleet en klaar voor gebruik met Azure SQL Database.
Ik gebruik de file-stats-over-a-period-of-time regelmatig bij het oplossen van prestatieproblemen. De cumulatieve gegevens hebben hun doel, maar ik ben meer geïnteresseerd in specifieke tijdssegmenten waarin gebruikersworkloads worden uitgevoerd.
Met bestandsstatistieken houden we ons bezig met onze latentie per databasebestand en hoe we kunnen afstemmen om de algehele I/O te helpen verminderen. De aanpak is hetzelfde als die van SQL Server, waarbij je je queries goed moet afstemmen en de juiste indexen moet hebben. Als de werklast gewoon te groot is, moet u naar een sneller presterende DTU-databaselaag gaan. Voor mij is dit geweldig:je gooit er gewoon hardware tegenaan; maar het is niet echt hardware in de traditionele zin. Met Azure SQL Database kunt u beginnen met een goedkopere laag en kunt u opschalen naarmate uw bedrijf en I/O-eisen groeien - in wezen door gewoon een schakelaar om te zetten.
Het was gemakkelijker om de beste methode te vinden om wachtstatistieken te verkrijgen. Het standaardscript dat velen van ons gebruiken, werkt nog steeds, maar het trekt wachtstatistieken op voor de container waarin uw database wordt uitgevoerd. Die wachttijden zijn nog steeds van toepassing op uw systeem, maar kunnen wachttijden omvatten die zijn gemaakt door andere databases in dezelfde container. Azure SQL Database bevat een nieuwe DMV, sys.dm_db_wait_stats , die naar de huidige database filtert. Als je net als ik bent en voornamelijk Paul's wachtstatistieken-script gebruikt dat alle goedaardige wachttijden weglaat, verander dan gewoon sys.dm_os_wait_stats naar sys.dm_db_wait_stats . Dezelfde wijziging werkt ook voor het script waits-over-a-period-of-time, maar u moet ook de wijziging doorvoeren van globale variabelen naar lokaal.
Als het gaat om het vinden van dure zoekopdrachten, vindt een van mijn favoriete scripts om uit te voeren de meest gebruikte uitvoeringsplannen. In mijn ervaring is het afstemmen van een query die 100.000 keer per dag wordt aangeroepen meestal een grotere winst dan het afstemmen van een query met de hoogste IO, maar die maar één keer per week wordt uitgevoerd. De volgende vraag gebruik ik om de meest gebruikte abonnementen te vinden:
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'Prepared use )OPSTELLING pre>Wanneer ik deze query in demo's gebruik, spoel ik altijd mijn plancache om de waarden opnieuw in te stellen. Toen ik probeerde
DBCC FREEPROCCACHE. uit te voeren in Azure SQL Database kreeg ik de volgende foutmelding:Het blijkt dat
SQL Azure biedt momenteel geen ondersteuning voor DBCC FREEPROCCACHE (Transact-SQL), dus u kunt een uitvoeringsplan niet handmatig uit de cache verwijderen. Als u echter wijzigingen aanbrengt in de tabel of weergave waarnaar wordt verwezen door de query (ALTER TABLE en ALTER VIEW), wordt het plan uit de cache verwijderd.DBCC FREEPROCCACHEwordt niet ondersteund in Azure SQL Database. Dit was verontrustend voor mij, wat als ik in productie ben en een aantal slechte plannen heb en de procedurecache wil wissen zoals ik kan met de doosversie. Een beetje Google/Bing-onderzoek leidde ertoe dat ik het Microsoft-artikel "Understanding the Procedure Cache on SQL Azure" vond, waarin staat:Door dit met Kimberly Tripp te bespreken, nadat het beschreven gedrag niet is gezien, wordt het plan niet uit de cache gewist, maar het maakt het plan ongeldig (en dan zal het plan uiteindelijk uit de cache worden verwijderd). Hoewel dit in bepaalde situaties nuttig is, was dit niet wat ik nodig had. Voor mijn demo wilde ik de tellers in sys.dm_exec_cached_plans resetten. Het genereren van een nieuw plan zou mij niet de gewenste resultaten opleveren. Ik nam contact op met mijn team en Glenn Berry zei dat ik het volgende script moest proberen:
WIJZIG DATABASE-SCOPED CONFIGURATIE PROCEDURE_CACHE WISSEN;Dit commando werkte; Ik kon de procedurecache voor de specifieke database wissen. Database Scoped Configurations is een nieuwe functie die is toegevoegd in SQL Server 2016 RC0; Glenn blogde er hier over:ALTER DATABASE SCOPED CONFIGURATION gebruiken in SQL Server 2016.
Ik ben verheugd om verschillende van mijn eigen databases naar Azure SQL Database te verplaatsen en om te blijven leren over de nieuwe functies en schaalbaarheidsopties. Ik kijk er ook naar uit om samen te werken met SentryOne DB Sentry, een recente toevoeging aan het SentryOne Platform. Ik ben het meest geïnteresseerd in het experimenteren met het DTU-gebruiksdashboard, dat Mike Wood in zijn recente bericht beschreef.