In mijn vorige post besprak ik de wachttijden van CXPACKET en manieren om parallellisme te voorkomen of te beperken. Ik heb ook uitgelegd hoe de controlethread in een parallelle operatie altijd een CXPACKET-wachttijd registreert, en dat soms niet-controlethreads ook CXPACKET-wachten registreren. Dit kan gebeuren als een van de threads is geblokkeerd in afwachting van een resource (zodat alle andere threads eerder klaar zijn en ook CXPACKET wacht), of als kardinaliteitsschattingen onjuist zijn. In deze post wil ik dat laatste onderzoeken.
Wanneer kardinaliteitsschattingen onjuist zijn, krijgen de parallelle threads die het querywerk doen, ongelijke hoeveelheden werk te doen. Het typische geval is dat één thread al het werk krijgt, of veel meer werk dan de andere threads. Dit betekent dat threads die klaar zijn met het verwerken van hun rijen (als ze die al hebben gekregen) vóór de langzaamste thread een CXPACKET registreren vanaf het moment dat ze klaar zijn tot de langzaamste thread eindigt. Dit probleem kan leiden tot een schijnbare explosie in CXPACKET-wachttijden en wordt gewoonlijk scheef parallellisme genoemd. , omdat de werkverdeling tussen de parallelle draden scheef is, niet eens.
Houd er rekening mee dat in SQL Server 2016 SP2 en SQL Server 2017 RTM CU3 consumententhreads niet langer CXPACKET-wachten registreren. Ze registreren CXCONSUMER-wachttijden, die goedaardig zijn en kunnen worden genegeerd. Dit is bedoeld om het aantal CXPACKET-wachten dat wordt gegenereerd te verminderen, en de resterende wachttijden zijn waarschijnlijker.
Voorbeeld van scheef parallellisme
Ik zal een gekunsteld voorbeeld doornemen om te laten zien hoe dergelijke gevallen kunnen worden geïdentificeerd.
Allereerst zal ik een scenario creëren waarin een tabel enorm onnauwkeurige statistieken heeft, door het aantal rijen en pagina's handmatig in te stellen in een UPDATE STATISTICS statement (doe dit niet in productie!):
USE [master];
GO
IF DB_ID (N'ExecutionMemory') IS NOT NULL
BEGIN
ALTER DATABASE [ExecutionMemory] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [ExecutionMemory];
END
GO
CREATE DATABASE [ExecutionMemory];
GO
USE [ExecutionMemory];
GO
CREATE TABLE dbo.[Test] (
[RowID] INT IDENTITY,
[ParentID] INT,
[CurrentValue] NVARCHAR (100),
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED ([RowID]));
GO
INSERT INTO dbo.[Test] ([ParentID], [CurrentValue])
SELECT
CASE WHEN ([t1].[number] % 3 = 0)
THEN [t1].[number] – [t1].[number] % 6
ELSE [t1].[number] END,
'Test' + CAST ([t1].[number] % 2 AS VARCHAR(11))
FROM [master].[dbo].[spt_values] AS [t1]
WHERE [t1].[type] = 'P';
GO
UPDATE STATISTICS dbo.[Test] ([PK_Test]) WITH ROWCOUNT = 10000000, PAGECOUNT = 1000000;
GO Dus mijn tabel heeft maar een paar duizend rijen, maar ik heb gefingeerd dat het 10 miljoen rijen heeft.
Nu zal ik een gekunstelde query maken om de bovenste 500 rijen te selecteren, die parallel zullen lopen omdat het denkt dat er miljoenen rijen zijn om te scannen.
USE [ExecutionMemory];
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentValue NVARCHAR (100);
WHILE (1=1)
SELECT TOP (500)
@CurrentValue = [CurrentValue]
FROM dbo.[Test]
ORDER BY NEWID() DESC;
GO En zet dat draaiende.
De CXPACKET-wachttijden bekijken
Nu kan ik kijken naar de CXPACKET-wachttijden die plaatsvinden met behulp van een eenvoudig script om naar de sys.dm_os_waiting_tasks te kijken DMV:
SELECT
[owt].[session_id],
[owt].[exec_context_id],
[owt].[wait_duration_ms],
[owt].[wait_type],
[owt].[blocking_session_id],
[owt].[resource_description],
[er].[database_id],
[eqp].[query_plan]
FROM sys.dm_os_waiting_tasks [owt]
INNER JOIN sys.dm_exec_sessions [es] ON
[owt].[session_id] = [es].[session_id]
INNER JOIN sys.dm_exec_requests [er] ON
[es].[session_id] = [er].[session_id]
OUTER APPLY sys.dm_exec_sql_text ([er].[sql_handle]) [est]
OUTER APPLY sys.dm_exec_query_plan ([er].[plan_handle]) [eqp]
WHERE
[es].[is_user_process] = 1
ORDER BY
[owt].[session_id],
[owt].[exec_context_id]; Als ik dit een paar keer uitvoer, zie ik uiteindelijk enkele resultaten die een scheef parallellisme vertonen (ik heb de link van het queryplan-handvat verwijderd en de resourcebeschrijving ingekort, voor de duidelijkheid, en merk op dat ik de code heb ingevoerd om de SQL-tekst te pakken als je dat wilt ook):
| session_id | exec_context_id | wait_duration_ms | wait_type | blocking_session_id | resource_description | database_id |
|---|---|---|---|---|---|---|
56 | 0 | 1 | CXPACKET | NULL | exchangeEvent | 13 |
56 | 1 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 3 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 4 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 5 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 6 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 7 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
Resultaten die scheef parallellisme in actie laten zien
De controlethread is die met exec_context_id ingesteld op 0. De andere parallelle threads zijn die met exec_context_id hoger dan 0, en ze tonen allemaal CXPACKET-wachten behalve één (merk op dat exec_context_id = 2 ontbreekt in de lijst). Je zult merken dat ze allemaal hun eigen session_id . vermelden als degene die ze blokkeert, en dat is correct omdat alle threads wachten op een andere thread van hun eigen session_id vervolledigen. De database_id is de database in wiens context de query wordt uitgevoerd, niet per se de database waar het probleem zich voordoet, maar meestal wel, tenzij de query driedelige naamgeving gebruikt om in een andere database uit te voeren.
Het kardinaliteitsschattingsprobleem bekijken
Met het query_plan kolom in de query-uitvoer (die ik voor de duidelijkheid heb verwijderd), kunt u erop klikken om het grafische plan te openen en vervolgens met de rechtermuisknop klikken en Weergeven met SQL Sentry Plan Explorer selecteren. Dit wordt als volgt weergegeven:
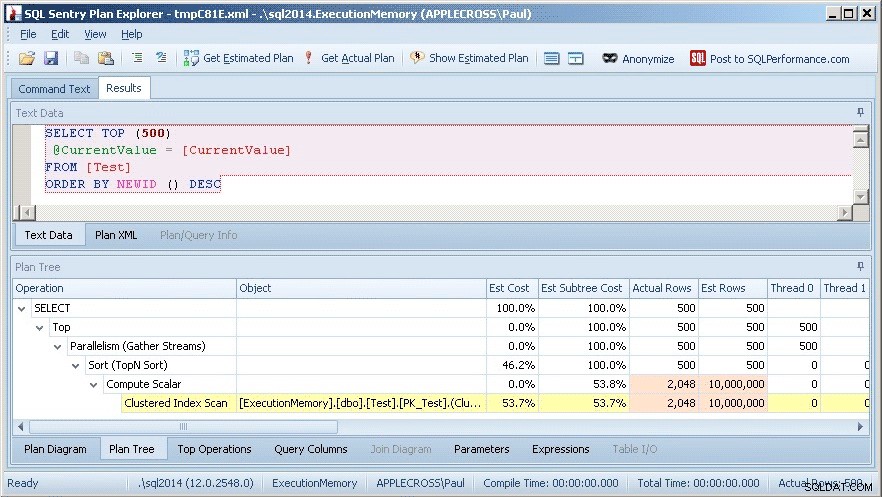
Ik kan meteen zien dat er een kardinaliteitsschattingsprobleem is, aangezien de werkelijke rijen voor de geclusterde indexscan slechts 2.048 zijn, vergeleken met 10.000.000 est (geschatte) rijen.
Als ik naar voren scrol, zie ik de verdeling van rijen over de parallelle threads die werden gebruikt:
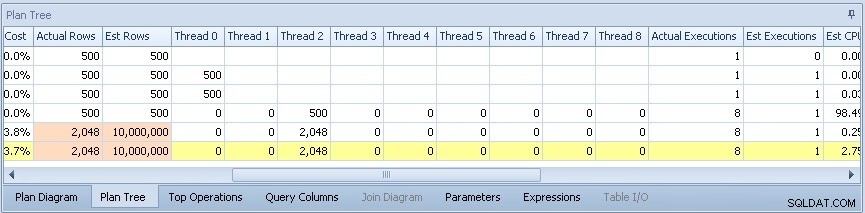
Kijk, slechts één enkele thread deed enig werk tijdens het parallelle gedeelte van het plan - degene die niet verscheen in de sys.dm_os_waiting_tasks uitvoer hierboven.
In dit geval is de oplossing om de statistieken voor de tabel bij te werken.
In mijn verzonnen voorbeeld zal dat niet werken, omdat er geen wijzigingen in de tabel zijn aangebracht, dus ik zal het installatiescript opnieuw uitvoeren, waarbij ik de UPDATE STATISTICS weglaat uitspraak.
Het zoekplan wordt dan:
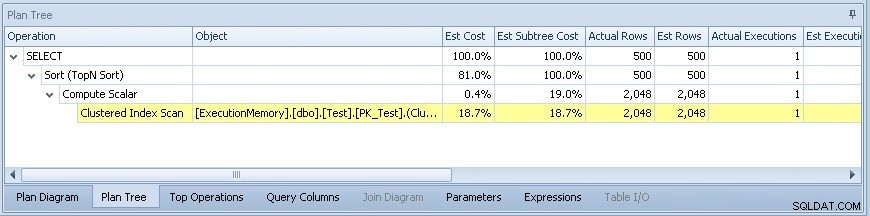
Waar er geen kardinaliteitsprobleem is en ook geen parallellisme - probleem opgelost!
Samenvatting
Als u CXPACKET-wachttijden ziet optreden, kunt u eenvoudig controleren op scheef parallellisme met behulp van de hierboven beschreven methode. Alle gevallen die ik heb gezien, waren te wijten aan problemen met kardinaliteitsschattingen van een of andere soort, en vaak is het gewoon een kwestie van statistieken bijwerken.
Wat algemene wachtstatistieken betreft, kunt u meer informatie vinden over het gebruik ervan voor het oplossen van problemen met de prestaties in:
- Mijn serie SQLskills-blogposts, te beginnen met Wachtstatistieken, of vertel me alsjeblieft waar het pijn doet
- Mijn bibliotheek met wachttypes en vergrendelingsklassen hier
- Mijn online Pluralsight-trainingscursus SQL Server:prestatieproblemen oplossen met behulp van wachtstatistieken
- SQL Sentry
Tot de volgende keer, veel plezier met het oplossen van problemen!