[ Deel 1 | Deel 2 | Deel 3 ]
In de geest van Grant Fritchey's recente tirades, en Erin Stellato's inspanningen sinds ik denk voordat we elkaar ontmoetten, wil ik op de kar springen om te bazuinen en het idee te promoten om sporen te schrappen ten gunste van Extended Events. Wanneer iemand traceer . zegt , denken de meeste mensen meteen Profiler . Hoewel Profiler zijn eigen speciale nachtmerrie is, wilde ik het vandaag hebben over de standaardtracering van SQL Server.
In onze omgeving is het ingeschakeld op alle 200+ productieservers, en het verzamelt een heleboel rommel die we nooit gaan onderzoeken. Zoveel rommel dat belangrijke gebeurtenissen die we misschien nuttig vinden voor het oplossen van problemen, de traceringsbestanden uitrollen voordat we ooit de kans krijgen. Dus begon ik het vooruitzicht te overwegen om het uit te zetten, omdat:
- het is niet gratis (de overhead van de waarnemer van de traceeractiviteit zelf, de I/O die betrokken is bij het schrijven naar de traceerbestanden en de ruimte die ze innemen);
- op de meeste servers wordt er nooit naar gekeken; op anderen, zelden; en,
- het is gemakkelijk weer aan te zetten voor specifieke, geïsoleerde probleemoplossing.
Een aantal andere dingen zijn van invloed op de waarde van de standaardtracering. Het is op geen enkele manier configureerbaar - je kunt niet wijzigen welke gebeurtenissen het verzamelt, je kunt geen filters toevoegen en je kunt niet bepalen hoeveel bestanden het bewaart (5), hoe groot ze kunnen worden (20 MB elk) , of waar ze zijn opgeslagen (SERVERPROPERTY('ErrorLogFileName') ). We zijn dus volledig overgeleverd aan de werklast — op een bepaalde server kunnen we niet voorspellen hoe ver de gegevens teruggaan (gebeurtenissen met grotere TextData waarden kunnen bijvoorbeeld veel meer ruimte innemen en oudere gebeurtenissen sneller naar buiten duwen). Soms kan het een week teruggaan, andere keren kan het slechts enkele minuten teruggaan.
De huidige staat analyseren
Ik heb de volgende code uitgevoerd tegen 224 productie-instanties, gewoon om te begrijpen wat voor soort ruis het standaardspoor in onze omgeving opvult. Dit is waarschijnlijk ingewikkelder dan het zou moeten zijn, en het is zelfs niet zo ingewikkeld als de laatste vraag die ik heb gebruikt, maar het is een goed startpunt om de uitsplitsing te analyseren van gebeurtenistypen op hoog niveau die momenteel worden vastgelegd:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Het predikaat EventSubClass is er om dubbeltelling van DDL-gebeurtenissen te voorkomen.Voor een kaart met EventClass-waarden heb ik ze in dit antwoord op Stack Exchange vermeld.)
En de resultaten zijn niet mooi (typische resultaten van een willekeurige server). Het volgende geeft niet de exacte uitvoer van die zoekopdracht weer, maar ik heb wat tijd besteed aan het samenvoegen van de resultaten in een beter verteerbaar formaat, om te zien hoeveel van de gegevens nuttig waren en hoeveel ruis (klik om te vergroten):
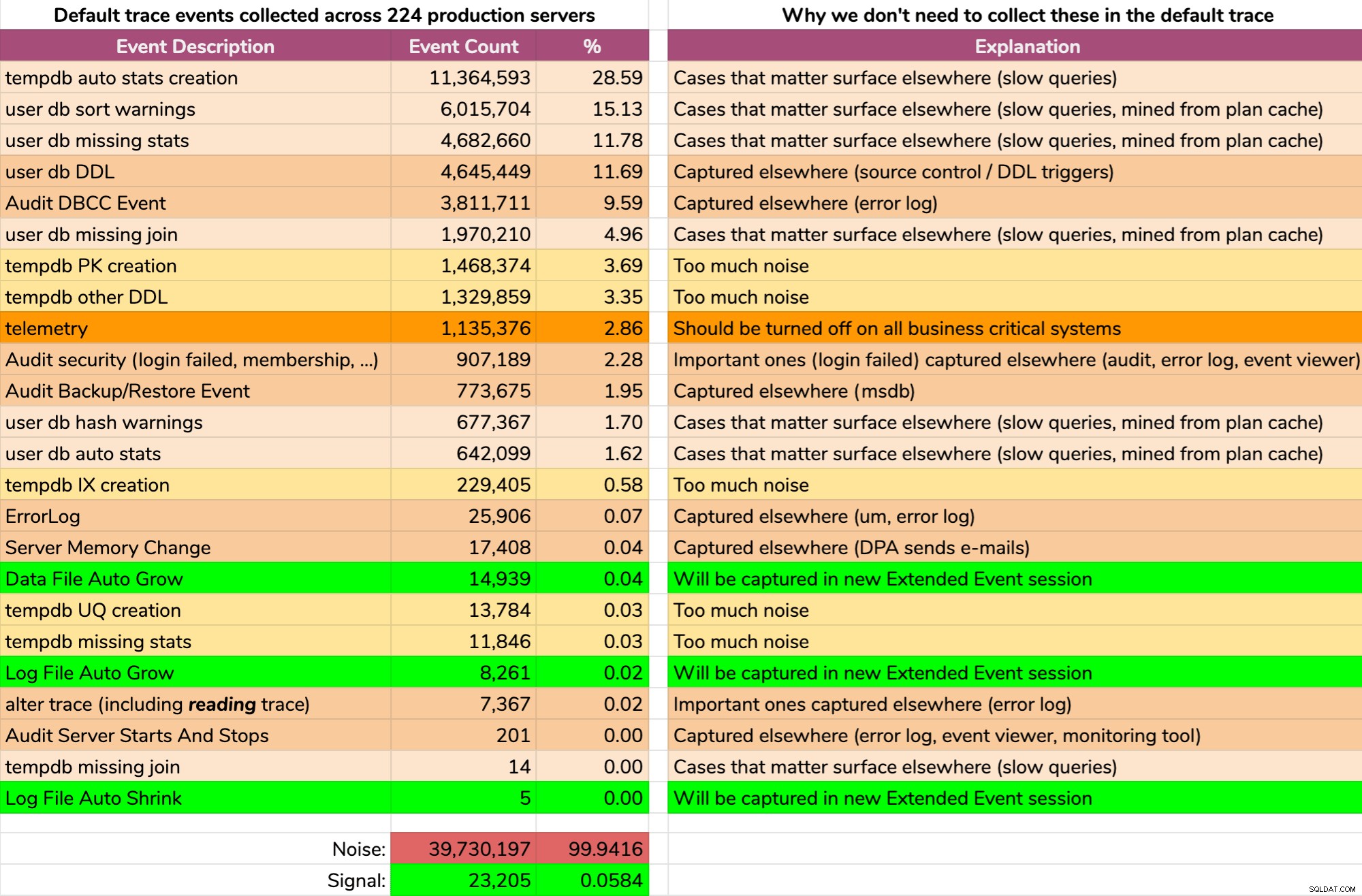
Bijna alle ruis (99,94%). Het enige nuttige dat we ooit nodig hadden van de standaardtracering waren bestandsgroei- en krimpgebeurtenissen, aangezien dit het enige was dat we op de een of andere manier nergens anders konden vastleggen. Maar zelfs daar kunnen we niet altijd op vertrouwen, omdat de data zo snel wegrolt.
Een andere manier waarop ik de gegevens heb gesegmenteerd:oudste gebeurtenis per instantie. Sommige instanties hadden zoveel ruis dat ze de standaard traceergegevens niet langer dan een paar minuten konden vasthouden! Ik heb de servernamen vervaagd, maar dit zijn echte gegevens (dit zijn de 20 servers met de kortste geschiedenis - klik om te vergroten):
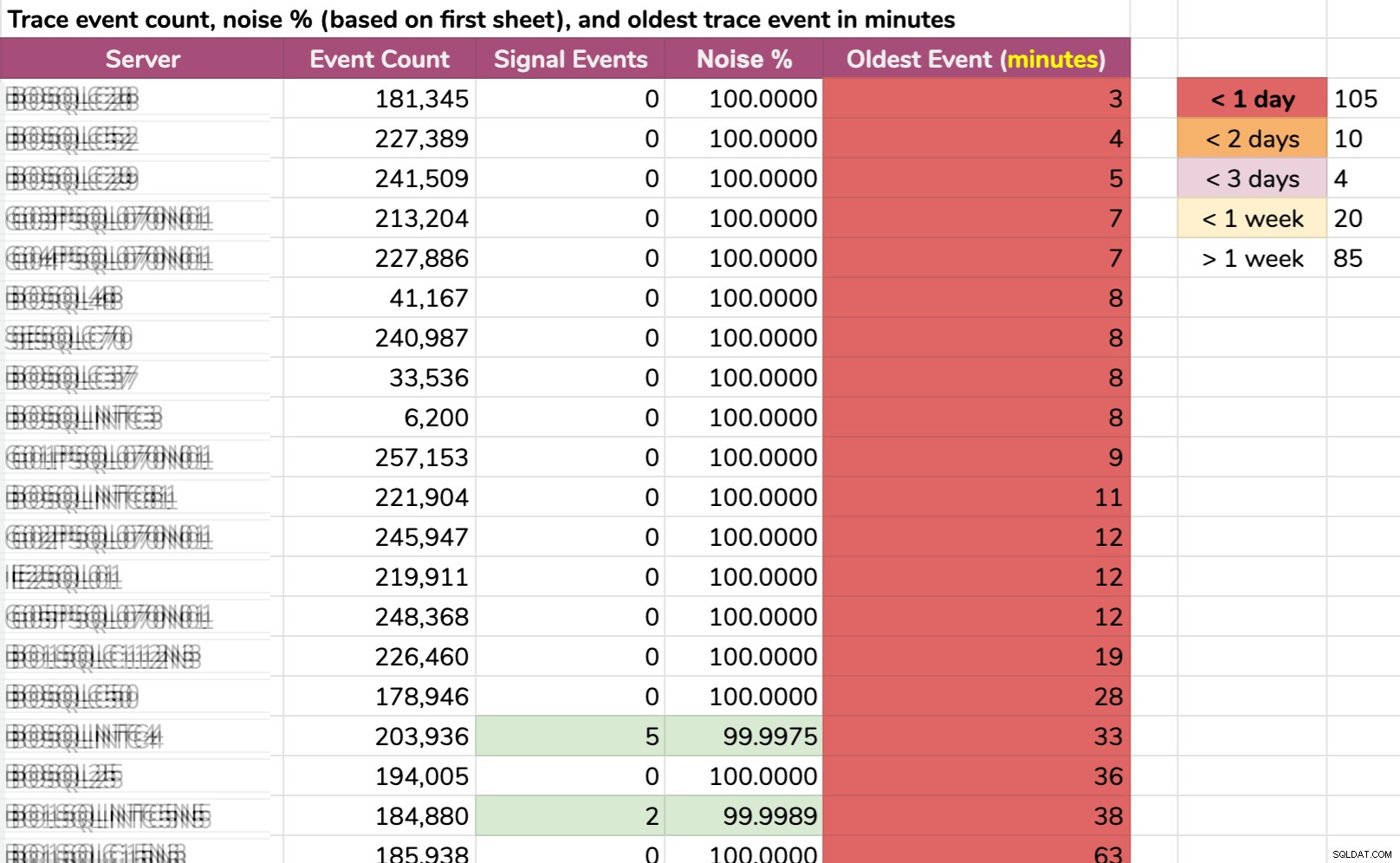
Zelfs als het spoor alleen zou verzamelen relevante informatie, en er is iets interessants gebeurd, we zouden snel moeten handelen om het op te vangen, afhankelijk van de server. Als het is gebeurd:
- 20 minuten geleden , dan zou het al verdwenen zijn op 15 keer .
- gisteren deze keer , het zou verdwenen zijn in 105 gevallen .
- twee dagen geleden , het zou verdwenen zijn op 115 keer .
- meer dan een week geleden , het zou verdwenen zijn in 139 gevallen .
We hadden ook een handvol servers aan de andere kant, maar die zijn in deze context niet interessant; die servers zijn zo, simpelweg omdat daar niets interessants gebeurt (ze zijn bijvoorbeeld niet bezet of maken geen deel uit van een kritieke werkbelasting).
Aan de positieve kant...
Bij het onderzoeken van de standaardtracering kwamen enkele verkeerde configuraties op een paar van onze servers aan het licht:
- Verschillende servers hadden nog telemetrie ingeschakeld . Ik ben er helemaal voor om Microsoft in bepaalde omgevingen te helpen, maar niet tegen de overheadkosten op bedrijfskritische systemen.
- Sommige synchronisatietaken op de achtergrond waren het blindelings toevoegen van leden aan rollen , keer op keer, zonder te controleren of ze al in die rollen zaten. Dit is op zich niet schadelijk, vooral omdat deze gebeurtenissen niet langer de standaardtracering vullen, maar ze waarschijnlijk ook audits met ruis vullen, en er zijn waarschijnlijk andere blinde hertoepassingsbewerkingen die in hetzelfde patroon plaatsvinden.
- Iemand had autoshrink ingeschakeld ergens (sorry!), dus dit was iets dat ik wilde opsporen en voorkomen dat het opnieuw zou gebeuren (de nieuwe XE zal deze gebeurtenissen ook vastleggen).
Dit leidde tot vervolgtaken om deze problemen op te lossen en/of voorwaarden toe te voegen aan bestaande automatisering. We kunnen dus herhaling voorkomen zonder erop te vertrouwen dat we het geluk hebben om ze te overkomen in een toekomstige standaard traceringsbeoordeling, voordat ze worden uitgerold.
...maar het probleem blijft
Anders is alles ofwel informatie waar we onmogelijk iets aan kunnen doen of, zoals beschreven in de bovenstaande afbeelding, gebeurtenissen die we al ergens anders vastleggen. En nogmaals, de enige gegevens waarin ik geïnteresseerd ben van de standaardtracering die we niet al op een andere manier vastleggen, zijn gebeurtenissen met betrekking tot bestandsgroei en -krimp (hoewel de standaardtrace alleen de automatische variëteit vastlegt).
Maar het grotere probleem is niet echt het geluidsvolume. Ik kan grote massieve trace-bestanden met veel rommel aan, aangezien WHERE-clausules voor precies dit doel zijn uitgevonden. Het echte probleem is dat belangrijke gebeurtenissen te snel verdwenen.
Het antwoord
Het antwoord, althans in ons scenario, was eenvoudig:schakel de standaardtracering uit, aangezien het niet de moeite waard is om het uit te voeren als er niet op kan worden vertrouwd.
Maar wat zou het moeten vervangen, gezien de hoeveelheid ruis hierboven? Iets?
Misschien wil je een Extended Events-sessie die alles vastlegt het standaardspoor vastgelegd. Als dat zo is, heeft Jonathan Kehayias je gedekt. Dit zou u dezelfde informatie geven, maar met controle over zaken als retentie, waar de gegevens worden opgeslagen en, naarmate u zich meer op uw gemak voelt, de mogelijkheid om enkele van de luidruchtigere of minder nuttige gebeurtenissen geleidelijk en in de loop van de tijd te verwijderen.
Mijn plan was wat agressiever en werd al snel een "eenvoudig" proces om het volgende uit te voeren op alle servers in de omgeving (via CMS):
- ontwikkel een Extended Events-sessie die alleen bestandswijzigingsgebeurtenissen vastlegt (zowel handmatig als automatisch)
- de standaard tracering uitschakelen
- een weergave maken om het voor onze teams eenvoudig te maken om doelgegevens te gebruiken
Houd er rekening mee dat Ik stel niet voor dat u de standaardtracering blindelings uitschakelt , ik leg alleen uit waarom ik ervoor koos om dit in onze omgeving te doen. In komende berichten in deze serie zal ik de nieuwe Extended Events-sessie laten zien, de weergave die de onderliggende gegevens blootlegt, de code die ik heb gebruikt om deze wijzigingen op alle servers te implementeren, en mogelijke bijwerkingen die u in gedachten moet houden.
[ Deel 1 | Deel 2 | Deel 3 ]