Inleiding
Er zijn twee stromingen over het uitvoeren van berekeningen in uw database:mensen die denken dat het geweldig is, en mensen die het bij het verkeerde eind hebben. Dit wil niet zeggen dat de wereld van functies, opgeslagen procedures, gegenereerde of berekende kolommen en triggers allemaal zonneschijn en rozen is! Deze tools zijn verre van onfeilbaar, en ondoordachte implementaties kunnen slecht presteren, hun beheerders traumatiseren en meer, wat het bestaan van controverse enigszins verklaart.
Maar databases zijn per definitie erg goed in het verwerken en manipuleren van informatie, en de meeste stellen diezelfde controle en kracht ter beschikking aan hun gebruikers (SQLite en MS Access in mindere mate). Externe gegevensverwerkingsprogramma's beginnen op de achterste voet door informatie uit de database te halen, vaak via een netwerk, voordat ze iets kunnen doen. En waar databaseprogramma's ten volle kunnen profiteren van native set-operaties, indexering, tijdelijke tabellen en andere vruchten van een halve eeuw database-evolutie, hebben externe programma's van elke complexiteit de neiging om een bepaald niveau van opnieuw uitvinden van het wiel met zich mee te brengen. Dus waarom zou u de database niet aan het werk zetten?
Dit is waarom je misschien niet wil je database programmeren!
- Databasefunctionaliteit heeft de neiging onzichtbaar te worden, vooral triggers. Deze zwakte schaalt ongeveer met de grootte van teams en/of applicaties die interactie hebben met de database, aangezien minder mensen zich de programmering in de database herinneren of zich bewust zijn van de programmering. Documentatie helpt, maar slechts in beperkte mate.
- SQL is een taal die speciaal is ontwikkeld voor het manipuleren van datasets. Het is niet bijzonder goed in dingen die geen datasets manipuleren, en het is minder goed hoe ingewikkelder die andere dingen worden.
- RDBMS-mogelijkheden en SQL-dialecten verschillen. Eenvoudig gegenereerde kolommen worden breed ondersteund, maar het overzetten van complexere databaselogica naar andere winkels kost minimaal tijd en moeite.
- Upgrades voor databaseschema's zijn meestal ingewikkelder dan applicatie-upgrades. Snel veranderende logica kan het beste ergens anders worden gehandhaafd, hoewel het de moeite waard kan zijn om nog een keer te kijken als de zaken eenmaal stabiel zijn.
- Het beheren van databaseprogramma's is niet zo eenvoudig als men zou hopen. Veel hulpprogramma's voor schemamigratie doen weinig of niets voor de organisatie, wat leidt tot uitgebreide diffs en lastige codebeoordelingen (de afhankelijkheidsgrafieken van sqitch en het herwerken van individuele objecten maken het een opmerkelijke uitzondering, en migra probeert het probleem volledig te omzeilen). Bij het testen verbeteren frameworks zoals pgTAP en utPLSQL de black-box-integratietests, maar vertegenwoordigen ze ook een extra ondersteunings- en onderhoudsverplichting.
- Met een gevestigde externe codebase is elke structurele verandering vaak zowel inspanningsintensief als riskant.
Aan de andere kant, voor de taken waarvoor het geschikt is, biedt SQL snelheid, beknoptheid, duurzaamheid en de mogelijkheid om geautomatiseerde workflows te "canoniseren". Datamodellering is meer dan entiteiten als insecten op karton vastpinnen, en het onderscheid tussen data in beweging en data in rust is een lastige. Rust is echt een langzamere beweging in een fijnere graad; informatie stroomt altijd van hier naar daar, en de programmeerbaarheid van databases is een krachtig hulpmiddel om die stromen te beheren en te sturen.
Sommige database-engines splitsen het verschil tussen SQL en andere programmeertalen door ook die andere programmeertalen aan te passen. SQL Server ondersteunt functies die zijn geschreven in elke .NET Framework-taal; Oracle heeft in Java opgeslagen procedures; PostgreSQL staat extensies met C toe en is door de gebruiker programmeerbaar in Python, Perl en Tcl, met plug-ins die shellscripts, R, JavaScript en meer toevoegen. Afronding van de gebruikelijke verdachten, het is SQL of niets voor MySQL en MariaDB, MS Access is alleen programmeerbaar in VBA en SQLite is helemaal niet programmeerbaar door de gebruiker.
Het gebruik van niet-SQL-talen is een optie als SQL ontoereikend is voor een bepaalde taak of als u andere code wilt hergebruiken, maar het zal u niet helpen om de andere problemen te omzeilen die databaseprogrammering tot een veelsnijdend zwaard maken. Het gebruik hiervan bemoeilijkt in ieder geval de implementatie en interoperabiliteit verder. Voorbehoud scriptor:laat de schrijver oppassen.
Functies vs Procedures
Net als bij andere aspecten van het implementeren van de SQL-standaard, variëren de exacte details een beetje van RDBMS tot RDBMS. In het algemeen:
- Functies hebben geen controle over transacties.
- Functies retourneren waarden; procedures kunnen parameters wijzigen die zijn aangeduid als
OUTofINOUTdie dan kan worden gelezen in de aanroepende context, maar nooit een resultaat retourneert (uitgezonderd SQL Server). - Functies worden aangeroepen vanuit SQL-instructies om wat werk uit te voeren aan records die worden opgehaald of opgeslagen, terwijl procedures op zichzelf staan.
Meer specifiek staat MySQL ook recursie en enkele aanvullende SQL-instructies in functies niet toe. SQL Server verbiedt functies om gegevens te wijzigen, dynamische SQL uit te voeren en fouten af te handelen. PostgreSQL scheidde tot 2017 met versie 11 helemaal geen opgeslagen procedures van functies, dus Postgres-functies kunnen bijna alles doen wat procedures kunnen, behalve transactiecontrole.
Dus, welke te gebruiken wanneer? Functies zijn het meest geschikt voor logica die record voor record toepast terwijl gegevens worden opgeslagen en opgehaald. Complexere workflows die door zichzelf worden aangeroepen en intern gegevens verplaatsen, zijn beter als procedures.
Standaardwaarden en generatie
Zelfs eenvoudige berekeningen kunnen problemen opleveren als ze vaak genoeg worden uitgevoerd of als er meerdere concurrerende implementaties zijn. Bewerkingen op waarden in een enkele rij -- denk aan het converteren tussen metrische en Engelse eenheden, het vermenigvuldigen van een tarief met gewerkte uren voor factuursubtotalen, het berekenen van de oppervlakte van een geografische polygoon -- kunnen in een tabeldefinitie worden gedeclareerd om het ene of het andere probleem aan te pakken :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
De meeste RDBMS'en bieden een keuze tussen "opgeslagen" en "virtueel" gegenereerde kolommen. In het eerste geval wordt de waarde berekend en opgeslagen wanneer de rij wordt ingevoegd of bijgewerkt. Dit is de enige optie met PostgreSQL, vanaf versie 12, en MS Access. Virtueel gegenereerde kolommen worden berekend wanneer ze worden opgevraagd zoals in weergaven, zodat ze geen ruimte innemen, maar vaker opnieuw worden berekend. Beide soorten zijn strikt beperkt:waarden kunnen niet afhankelijk zijn van informatie buiten de rij waartoe ze behoren, ze kunnen niet worden bijgewerkt en individuele RDBMS'en kunnen nog specifiekere beperkingen hebben. PostgreSQL verbiedt bijvoorbeeld het partitioneren van een tabel op een gegenereerde kolom.
Gegenereerde kolommen zijn een gespecialiseerd hulpmiddel. Vaker is alles wat nodig is een standaardwaarde voor het geval er geen waarde wordt opgegeven bij het invoegen. Functies zoals now() worden vaak weergegeven als standaardkolommen, maar de meeste databases staan zowel aangepaste als ingebouwde functies toe (behalve MySQL, waar alleen current_timestamp kan een standaardwaarde zijn).
Laten we het nogal droge maar eenvoudige voorbeeld nemen van een lotnummer in het formaat YYYYXXX, waarbij de eerste vier cijfers het huidige jaar vertegenwoordigen en de laatste drie een oplopende teller:de eerste geproduceerde partij dit jaar is 2020001, de tweede 2020002, enzovoort . Er is geen standaardtype of ingebouwde functie die een waarde als deze genereert, maar een door de gebruiker gedefinieerde functie kan elke partij nummeren
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Verwijzen naar gegevens in functies
De volgorde-aanpak hierboven heeft één belangrijke zwakte (en lot_counter zal nog steeds dezelfde waarde hebben als op 31 december. Er is echter meer dan één manier om bij te houden hoeveel kavels er in een jaar zijn gemaakt, en door lots op te vragen zelf het next_lot_number functie kan een correcte waarde garanderen nadat het jaar voorbij is.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Workflows
Zelfs een functie met één instructie heeft een cruciaal voordeel ten opzichte van externe code:uitvoering verlaat nooit de veiligheid van de ACID-garanties van de database. Vergelijk next_lot_number hierboven naar de mogelijkheden van een clienttoepassing of zelfs een handmatig proces, het uitvoeren van
Opgeslagen programma's met meerdere statements openen een immense ruimte aan mogelijkheden, aangezien SQL alle tools bevat die je nodig hebt om procedurele code te schrijven, van het afhandelen van uitzonderingen tot savepoints (het is zelfs Turing compleet met vensterfuncties en algemene tabeluitdrukkingen!). Volledige workflows voor gegevensverwerking kunnen in de database worden uitgevoerd, waardoor de blootstelling aan andere delen van het systeem wordt geminimaliseerd en tijdrovende omwegen tussen de database en andere domeinen worden geëlimineerd.
Veel software-architectuur in het algemeen gaat over het beheren en isoleren van complexiteit, om te voorkomen dat het over de grenzen tussen subsystemen gaat. Als een min of meer gecompliceerde workflow bestaat uit het trekken van gegevens naar een backend, script of cron-job van een toepassing, het verteren en toevoegen ervan en het opslaan van het resultaat, dan is het tijd om je af te vragen wat er echt nodig is om je buiten de database te wagen.
Zoals hierboven vermeld, is dit een gebied waar verschillen tussen RDBMS-smaken en SQL-dialecten naar voren komen. Een functie of procedure die voor de ene database is ontwikkeld, zal waarschijnlijk niet op een andere worden uitgevoerd zonder wijzigingen, of dat nu de TOP van SQL Server is. voor een standaard LIMIT clausule of volledig herwerken hoe de tijdelijke status wordt opgeslagen in een enterprise Oracle naar PostgreSQL-migratie. Het canoniseren van uw workflows in SQL verplicht u ook grondiger naar uw huidige platform en dialect dan bijna elke andere keuze die u kunt maken.
Berekeningen in query's
Tot nu toe hebben we gekeken naar het gebruik van functies om gegevens op te slaan en te wijzigen, ongeacht of deze zijn gebonden aan tabeldefinities of het beheren van workflows met meerdere tabellen. In zekere zin is dat het krachtiger gebruik waarvoor ze kunnen worden ingezet, maar functies hebben ook een plaats bij het ophalen van gegevens. Veel tools die u mogelijk al in uw zoekopdrachten gebruikt, zijn geïmplementeerd als functies, van standaard ingebouwde functies zoals count naar extensies zoals Postgres' jsonb_build_object , PostGIS' ST_SnapToGrid , en meer. Omdat deze nauwer zijn geïntegreerd met de database zelf, zijn ze natuurlijk meestal geschreven in andere talen dan SQL (bijvoorbeeld C in het geval van PostgreSQL en PostGIS).
Als je vaak merkt dat je (of denkt dat je jezelf zou kunnen vinden) gegevens moet ophalen en vervolgens een bewerking op elk record moet uitvoeren voordat het echt is klaar, overweeg om ze in plaats daarvan te transformeren op de weg uit de database! Projecteert u een aantal werkdagen vanaf een datum? Een diff genereren tussen twee JSONB velden? Vrijwel elke berekening die alleen afhangt van de informatie die u opvraagt, kan in SQL worden uitgevoerd. En wat er in de database wordt gedaan -- zolang het maar consequent wordt gebruikt -- is canoniek voor wat betreft alles wat bovenop de database is gebouwd.
Het moet gezegd:als u met een applicatie-backend werkt, kan de toolkit voor gegevenstoegang beperken hoeveel kilometers u haalt uit het uitbreiden van queryresultaten met functies. De meeste van dergelijke bibliotheken kunnen willekeurige SQL uitvoeren, maar die welke algemene SQL-instructies genereren op basis van modelklassen, kunnen het aanpassen van de query SELECT mogelijk niet toestaan. lijsten. Gegenereerde kolommen of weergaven kunnen hier een antwoord zijn.
Triggers en gevolgen
Functies en procedures zijn controversieel genoeg tussen databaseontwerpers en gebruikers, maar dingen echt opstijgen met triggers. Een trigger definieert een automatische actie, meestal een procedure (SQLite staat slechts één instructie toe), die vóór, na of in plaats van een andere actie moet worden uitgevoerd.
De initiërende actie is over het algemeen het invoegen, bijwerken of verwijderen van een tabel, en de triggerprocedure kan meestal worden ingesteld om ofwel voor elke record of voor de instructie als geheel uit te voeren. SQL Server staat ook triggers toe op bij te werken views, meestal als een manier om meer gedetailleerde beveiligingsmaatregelen af te dwingen; en het, PostgreSQL en Oracle bieden allemaal een of andere vorm van evenement of
Een veelvoorkomend gebruik met een laag risico voor triggers is als een extra krachtige beperking die voorkomt dat ongeldige gegevens worden opgeslagen. In alle belangrijke relationele databases, alleen primaire en externe sleutels en UNIQUE beperkingen kunnen informatie buiten het kandidaat-record evalueren. Het is niet mogelijk om in een tabeldefinitie te verklaren dat er bijvoorbeeld slechts twee lots in een maand mogen worden gemaakt -- en de eenvoudigste database-en-code-oplossing is kwetsbaar voor een vergelijkbare race-conditie als de 'count-then-set'-benadering van lot_number boven. Om een andere beperking af te dwingen die betrekking heeft op de hele tabel of andere tabellen, hebt u een
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Zodra u begint met het uitvoeren van lots zelf kan de laatste bewerking zijn van een trigger die wordt geïnitieerd door een invoeging in orders , zonder menselijke gebruiker of applicatie-backend die gemachtigd is om te schrijven naar lots direct. Of als items aan een kavel worden toegevoegd, kan een trigger daar het bijwerken van current_quantity . afhandelen , en start een ander proces wanneer het de target_quantity . bereikt .
Triggers en functies kunnen worden uitgevoerd op het toegangsniveau van hun definitie (in PostgreSQL, een SECURITY DEFINER declaratie naast de LANGUAGE van een functie ), die anders beperkte gebruikers de macht geeft om bredere processen te initiëren -- en het valideren en testen van die processen des te belangrijker maakt.
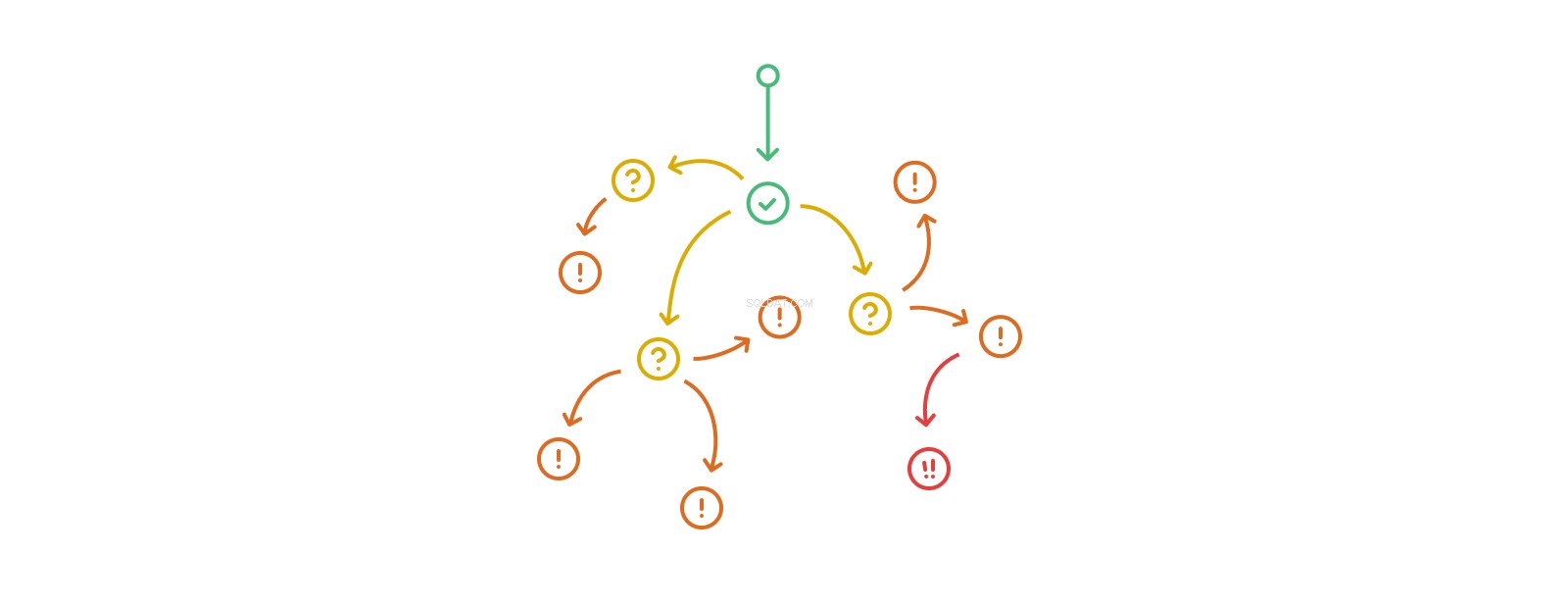
De trigger-action-trigger-action call-stack kan willekeurig lang worden, hoewel echte recursie in de vorm van het meerdere keren wijzigen van dezelfde tabellen of records in een dergelijke stroom illegaal is op sommige platforms en meer in het algemeen in bijna alle omstandigheden een slecht idee. Trigger nesting overtreft snel ons vermogen om de omvang en effecten ervan te begrijpen. Databases die intensief gebruik maken van geneste triggers beginnen af te drijven van het rijk van het gecompliceerde naar dat van het complexe, en worden moeilijk of onmogelijk te analyseren, debuggen en voorspellen.
Praktische programmeerbaarheid
Berekeningen in de database worden niet alleen sneller en beknopter uitgedrukt:ze elimineren dubbelzinnigheid en stellen normen. De bovenstaande voorbeelden zorgen ervoor dat databasegebruikers geen lotnummers hoeven te berekenen of dat ze zich zorgen hoeven te maken dat ze per ongeluk meer kavels aanmaken dan ze aankunnen. Met name applicatieontwikkelaars zijn vaak getraind om databases te zien als "domme opslag", die alleen structuur en persistentie bieden, en kunnen dus merken dat ze - of erger nog, zich niet realiseren dat ze - onhandig buiten de database articuleren wat ze zouden kunnen doen effectiever in SQL.
Programmeerbaarheid is een onterecht over het hoofd gezien kenmerk van relationele databases. Er zijn redenen om het te vermijden en meer om het gebruik ervan te beperken, maar functies, procedures en triggers zijn allemaal krachtige hulpmiddelen om de complexiteit te beperken die uw datamodel oplegt aan de systemen waarin het is ingebed.