Inleiding
Gegevens opslaan is één ding; betekenisvolle, nuttige, correcte opslaan gegevens is iets heel anders. Hoewel betekenis en bruikbaarheid zelf subjectieve eigenschappen zijn, kan correctheid op zijn minst logisch worden gedefinieerd en afgedwongen. Typen zorgen er al voor dat getallen getallen zijn en datums datums, maar kunnen niet garanderen dat gewicht of afstand positieve getallen zijn of voorkomen dat datumbereiken elkaar overlappen. Tuple-, tabel- en databasebeperkingen passen regels toe op gegevens die worden opgeslagen en verwerpen waarden of combinaties van waarden die niet door de beugel kunnen.
Beperkingen maken andere invoervalidatietechnieken op geen enkele manier onbruikbaar, zelfs niet als ze dezelfde beweringen testen. Tijd die wordt besteed aan het proberen en falen om ongeldige gegevens op te slaan, is verspilde tijd. Overtredingsberichten, zoals assert in systeem- en applicatieprogrammeertalen, onthult alleen het eerste probleem met het eerste kandidaatrecord veel gedetailleerder dan iemand die niet direct betrokken is bij de databasebehoeften. Maar wat de juistheid van gegevens betreft, zijn beperkingen wet, ten goede of ten kwade; al het andere is advies.
Op Tuples:niet null, standaard en vinkje
Niet-null-beperkingen zijn de eenvoudigste categorie. Een tuple moet een waarde hebben voor het beperkte attribuut, of anders gezegd, de set toegestane waarden voor de kolom bevat niet langer de lege set. Geen waarde betekent geen tuple:de invoeging of update wordt afgewezen.
Bescherming tegen null-waarden is net zo eenvoudig als het declareren van column_name COLUMN_TYPE NOT NULL in CREATE TABLE of ADD COLUMN . Null-waarden veroorzaken hele categorieën problemen tussen de database en eindgebruikers, dus het is een goede gewoonte om reflexmatig niet-null-beperkingen op een kolom te definiëren zonder een goede reden om nulls toe te staan.
Het verstrekken van een standaardwaarde als er niets is opgegeven (door weglating of een expliciete NULL ) in een insert of update wordt niet altijd als een beperking beschouwd, aangezien kandidaatrecords worden gewijzigd en opgeslagen in plaats van afgewezen. In veel DBMS'en kunnen standaardwaarden worden gegenereerd door een functie, hoewel MySQL voor dit doel geen door de gebruiker gedefinieerde functies toestaat.
Elke andere validatieregel die alleen afhangt van de waarden binnen een enkele tuple kan worden geïmplementeerd als een CHECK beperking. In zekere zin, NOT NULL zelf is een afkorting voor CHECK (column_name IS NOT NULL); de foutmelding die bij overtreding wordt ontvangen, maakt het grootste verschil. CHECK , kan echter de waarheid van elk Booleaans predikaat toepassen en afdwingen over een enkele tuple. Een tabel met geografische locaties moet bijvoorbeeld CHECK (latitude >= -90 AND latitude < 90) , en evenzo voor een lengtegraad tussen -180 en 180 -- of, indien beschikbaar, gebruik en valideer een GEOGRAPHY gegevenstype.
Op tafels:uniek en uitgesloten
Beperkingen op tabelniveau testen tuples tegen elkaar. In een unieke beperking kan slechts één record een bepaalde set waarden voor de beperkte kolommen hebben. Nullabiliteit kan hier problemen veroorzaken, aangezien NULL is nooit gelijk aan iets anders, tot en met NULL zelf. Een unieke beperking voor (batman, robin) maakt daarom oneindige kopieën van elke Robinless Batman mogelijk.
Uitsluitingsbeperkingen worden alleen ondersteund in PostgreSQL en DB2, maar vullen een zeer nuttige niche:ze kunnen overlappingen voorkomen. Specificeer de beperkte velden en de bewerkingen waarmee elk zal worden geëvalueerd, en een nieuwe record wordt alleen geaccepteerd als geen bestaande record met succes kan worden vergeleken met elk veld en elke bewerking. Bijvoorbeeld een schedules tabel kan worden geconfigureerd om conflicten te weigeren:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upsert-bewerkingen zoals PostgreSQL's ON CONFLICT clausule of MySQL's ON DUPLICATE KEY UPDATE gebruik een beperking op tabelniveau om conflicten te detecteren. En zoals niet-null-beperkingen kunnen worden uitgedrukt als CHECK beperkingen, kan een unieke beperking worden uitgedrukt als een uitsluitingsbeperking op gelijkheid.
De primaire sleutel
Unieke beperkingen hebben een bijzonder handig speciaal geval. Met een extra niet-null-beperking op de unieke kolom of kolommen, kan elk record in de tabel afzonderlijk worden geïdentificeerd door zijn waarden voor de beperkte kolommen, die gezamenlijk een sleutel worden genoemd . Meerdere kandidaatsleutels kunnen naast elkaar bestaan in een tabel, zoals users soms nog steeds een duidelijk uniek en niet-null email s en username s; maar het declareren van een primaire sleutel stelt één enkel criterium vast waarmee records openbaar en exclusief bekend zijn. Sommige RDBMS'en organiseren zelfs rijen op pagina's op de primaire sleutel, voor dit doel een geclusterde index genoemd , om het zoeken op primaire sleutelwaarden zo snel mogelijk te maken.
Er zijn twee soorten primaire sleutels. Een natuurlijke sleutel wordt gedefinieerd op een kolom of kolommen die "van nature" in de gegevens van de tabel zijn opgenomen, terwijl een surrogaatsleutel of synthetische sleutel uitsluitend wordt uitgevonden om de sleutel te worden. Natuurlijke sleutels vereisen zorg -- er kunnen meer dingen veranderen dan databaseontwerpers vaak toeschrijven, van namen tot nummeringsschema's. Een opzoektabel met land- en regionamen kunnen hun respectievelijke ISO 3166-codes gebruiken als een veilige natuurlijke primaire sleutel, maar een users tabel met een natuurlijke sleutel op basis van veranderlijke waarden zoals namen of e-mailadressen nodigt uit tot problemen. Maak bij twijfel een surrogaatsleutel.
Als een natuurlijke sleutel meerdere kolommen omvat, moet altijd een surrogaatsleutel worden overwogen, omdat sleutels met meerdere kolommen meer moeite kosten om te beheren. Als de natuurlijke sleutel echter past, moeten kolommen worden gerangschikt in toenemende specificiteit, net zoals ze zijn in indexen:landcode dan regiocode, in plaats van omgekeerd.
De surrogaatsleutel was van oudsher een enkele integerkolom, of BIGINT waar miljarden uiteindelijk zullen worden toegewezen. Relationele databases kunnen automatisch surrogaatsleutels vullen met het volgende gehele getal in een reeks, een functie die gewoonlijk SERIAL wordt genoemd. of IDENTITY .
Een automatisch oplopende numerieke teller is niet zonder nadelen:het toevoegen van records met vooraf gegenereerde sleutels kan conflicten veroorzaken, en als sequentiële waarden worden blootgesteld aan gebruikers, is het gemakkelijk voor hen om te raden wat andere geldige sleutels zouden kunnen zijn. Universally Unique Identifiers, of UUID's, vermijden deze zwakke punten en zijn een veelvoorkomende keuze geworden voor surrogaatsleutels, hoewel ze ook veel groter in-page zijn dan een eenvoudig nummer. De v1 (MAC-adresgebaseerd) en v4 (pseudowillekeurig) UUID-typen worden het meest gebruikt.
In de database:buitenlandse sleutels
Relationele databases implementeren slechts één klasse van beperkingen voor meerdere tabellen, de
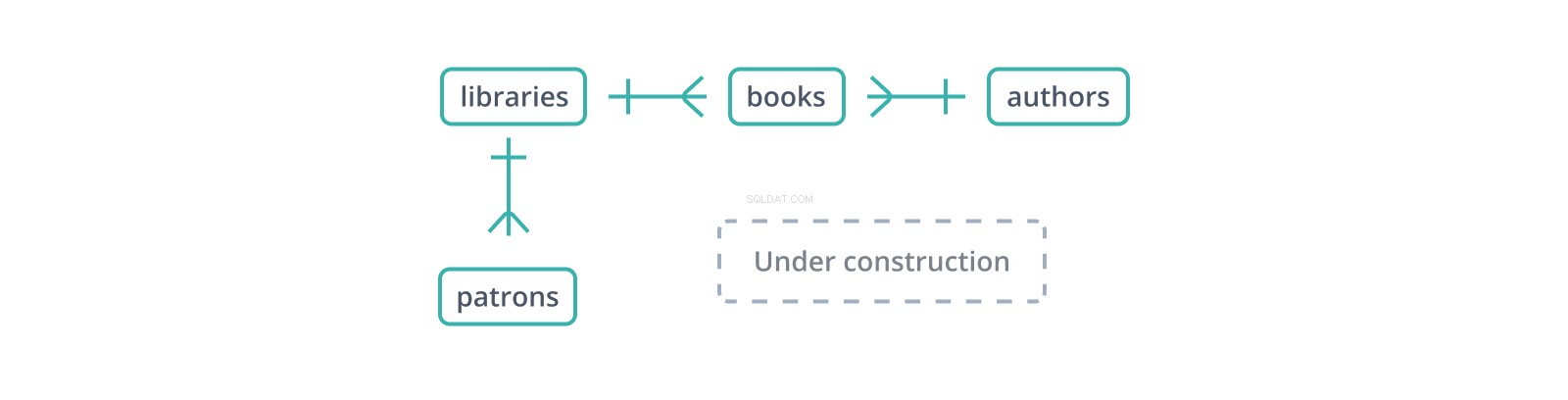
Dit informele "entity-relationship diagram" of ERD toont het begin van een schema voor een database van bibliotheken en hun collecties en mecenassen. Elke rand vertegenwoordigt een relatie tussen de tabellen die het verbindt. de | glyph geeft één record op zijn kant aan, terwijl de "kraaienpoot" glyph meerdere vertegenwoordigt:een bibliotheek heeft veel boeken en heeft veel klanten.
Een refererende sleutel is een kopie van de primaire sleutel van een andere tabel, kolom voor kolom (een punt ten gunste van surrogaatsleutels:slechts één kolom om te kopiëren en te verwijzen), met waarden die records in deze tabel koppelen aan "bovenliggende" records daarin. In het bovenstaande schema zijn de books tabel onderhoudt een library_id externe sleutel naar libraries , die boeken bevatten, en een author_id aan authors , die ze schrijven. Maar wat gebeurt er als een boek wordt ingevoegd met een author_id die niet bestaat in authors ?
Als de refererende sleutel niet beperkt is - d.w.z. het is gewoon een andere kolom of kolommen - kan een boek een auteur hebben die niet bestaat. Dit is een probleem:als iemand de link tussen books probeert te volgen en authors , ze komen nergens terecht. Als authors.author_id een serieel geheel getal is, is er ook de mogelijkheid dat niemand het merkt totdat de valse author_id uiteindelijk wordt toegewezen, en je krijgt een bepaald exemplaar van Don Quichot eerst toegeschreven aan niemand die bekend is en vervolgens aan Pierre Menard, met Miguel Cervantes nergens te vinden.
Het beperken van de externe sleutel kan niet voorkomen dat een boek verkeerd wordt toegeschreven als de foutieve author_id verwijzen naar een bestaand record in authors , dus andere controles en tests blijven belangrijk. De set bestaande externe sleutelwaarden is echter bijna altijd een kleine subset van de mogelijke buitenlandse sleutelwaarden, dus beperkingen van buitenlandse sleutels zullen de meeste verkeerde waarden opvangen en voorkomen. Met een externe sleutelbeperking, de Quixote met een niet-bestaande auteur worden afgewezen in plaats van opgenomen.
Is dit waar het "relationele" in "Relationele database" vandaan komt?
Vreemde sleutels creëren relaties tussen tabellen, maar tabellen zoals we ze kennen zijn wiskundig relaties tussen de sets van mogelijke waarden voor elk attribuut. Een enkele tupel relateert een waarde voor kolom A aan een waarde voor kolom B en verder. Het originele artikel van E.F. Codd gebruikt 'relationeel' in deze zin.
Dit heeft eindeloos veel verwarring veroorzaakt en zal dit waarschijnlijk voor altijd blijven doen.
Voor bepaalde waarden van correct
Er zijn veel meer manieren waarop gegevens onjuist kunnen zijn dan hier besproken. Beperkingen helpen, maar zelfs zij zijn maar zo flexibel; veel algemene specificaties binnen tabellen, zoals een limiet van twee of hoger voor het aantal keren dat een waarde in een kolom mag voorkomen, kunnen alleen worden afgedwongen met triggers.
Maar er zijn ook manieren waarop de structuur van een tabel tot inconsistenties kan leiden. Om dit te voorkomen, moeten we zowel primaire als externe sleutels rangschikken, niet alleen om te definiëren en te valideren, maar om te normaliseren de relaties tussen tabellen. Ten eerste hebben we echter nog maar net de oppervlakte ontdekt van hoe de relaties tussen tabellen de structuur van de database zelf bepalen.