Vorige week heb ik een bericht gepubliceerd met de naam #BackToBasics:DATEFROMPARTS() , waar ik liet zien hoe je deze 2012+-functie kunt gebruiken voor schonere, sargable query's over het datumbereik. Ik heb het gebruikt om aan te tonen dat als je een datumpredikaat met een open einde gebruikt, en je hebt een index op de relevante datum/tijd-kolom, je een veel beter indexgebruik en een lagere I/O kunt krijgen (of, in het ergste geval , hetzelfde, als een zoekopdracht om de een of andere reden niet kan worden gebruikt, of als er geen geschikte index bestaat):
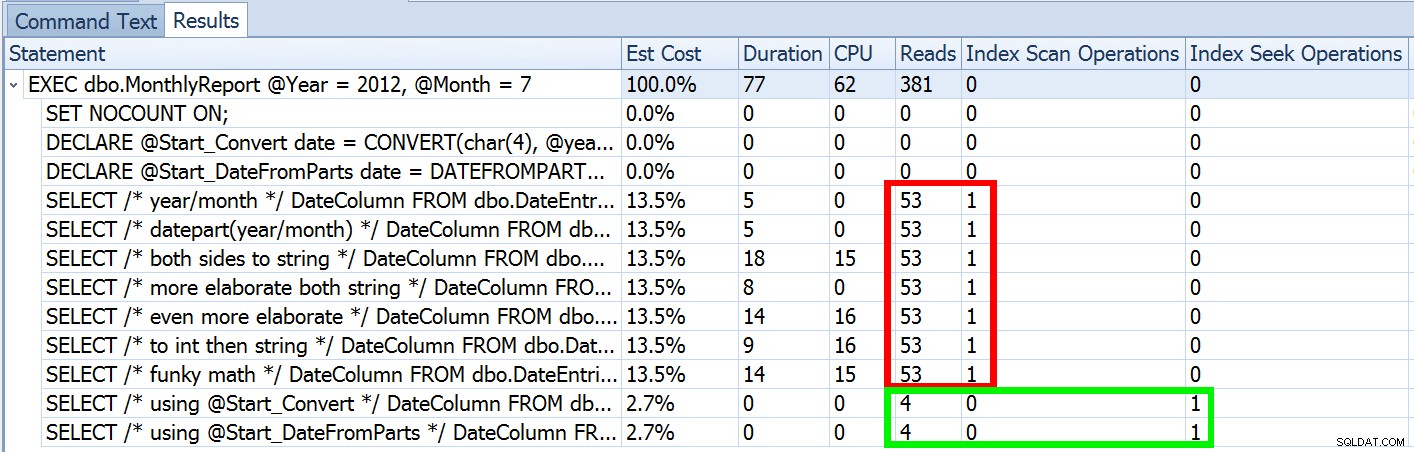
Maar dat is slechts een deel van het verhaal (en voor de duidelijkheid:DATEFROMPARTS() is technisch niet vereist om een zoekopdracht te krijgen, het is in dat geval gewoon schoner). Als we een beetje uitzoomen, merken we dat onze schattingen verre van nauwkeurig zijn, een complexiteit die ik niet wilde introduceren in de vorige post:
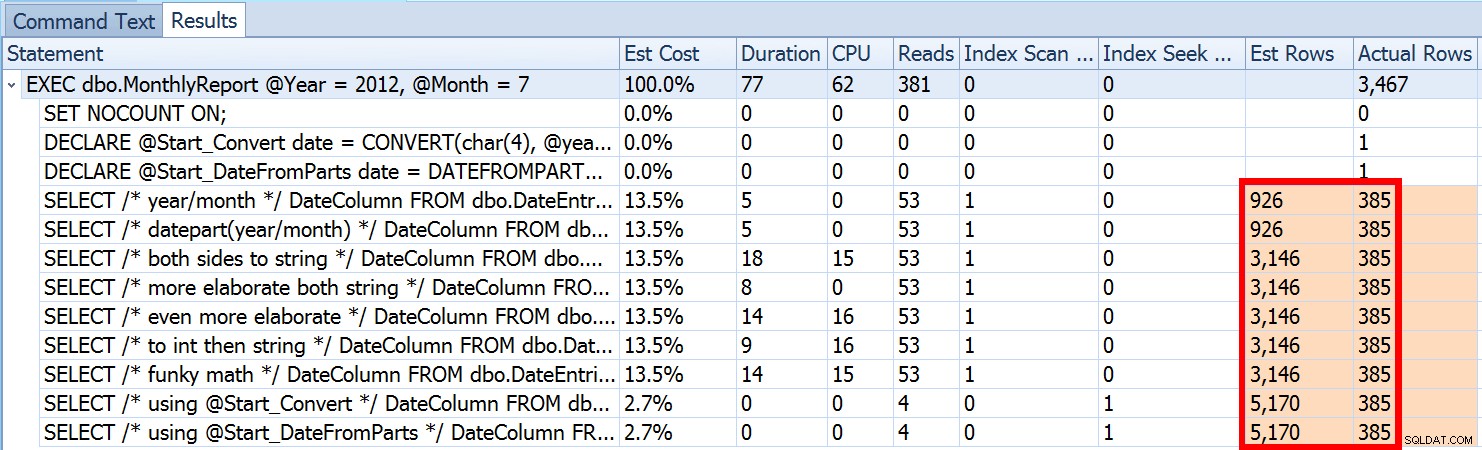
Dit is niet ongebruikelijk voor zowel ongelijkheidspredikaten als bij geforceerde scans. En natuurlijk, zou de methode die ik voorstelde niet de meest onnauwkeurige statistieken opleveren? Hier is de basisaanpak (u kunt het tabelschema, de indexen en voorbeeldgegevens uit mijn vorige bericht halen):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Nu zullen onnauwkeurige schattingen niet altijd een probleem zijn, maar het kan problemen veroorzaken met inefficiënte plankeuzes aan de twee uitersten. Een enkel plan is mogelijk niet optimaal wanneer het gekozen bereik een zeer klein of zeer groot percentage van de tabel of index zal opleveren, en dit kan voor SQL Server erg moeilijk worden om te voorspellen wanneer de gegevensdistributie ongelijkmatig is. Joseph Sack schetste de meer typische dingen die slechte schattingen kunnen beïnvloeden in zijn post, "Ten Common Threats to Execution Plan Quality:"
"[...] slechte rij-schattingen kunnen van invloed zijn op een verscheidenheid aan beslissingen, waaronder indexselectie, zoek- versus scanbewerkingen, parallelle versus seriële uitvoering, selectie van join-algoritmen, interne versus externe fysieke join-selectie (bijv. build versus sonde), spoolgeneratie, bladwijzerzoekopdrachten versus volledige geclusterde of heap-tabeltoegang, stream- of hash-aggregatieselectie, en of een gegevenswijziging al dan niet een breed of smal plan gebruikt."
Er zijn ook andere, zoals geheugenbeurzen die te groot of te klein zijn. Hij gaat verder met het beschrijven van enkele van de meest voorkomende oorzaken van slechte schattingen, maar de primaire oorzaak ontbreekt in dit geval in zijn lijst:schattingen. Omdat we een lokale variabele gebruiken om de inkomende int . te wijzigen parameters naar een enkele lokale date variabele, weet SQL Server niet wat de waarde zal zijn, dus maakt het gestandaardiseerde schattingen van kardinaliteit op basis van de hele tabel.
We zagen hierboven dat de schatting voor mijn voorgestelde aanpak 5.170 rijen was. Nu weten we dat met een ongelijkheidspredikaat, en met SQL Server die de parameterwaarden niet kent, het 30% van de tabel zal raden. 31,645 * 0.3 is niet 5.170. Evenmin is 31,465 * 0.3 * 0.3 , als we ons herinneren dat er eigenlijk twee predikaten zijn die tegen dezelfde kolom werken. Dus waar komt deze 5.170 waarde vandaan?
Zoals Paul White beschrijft in zijn bericht "Kardinaliteitsschatting voor meerdere predikaten", gebruikt de nieuwe kardinaliteitsschatter in SQL Server 2014 exponentiële uitstel, dus het vermenigvuldigt het aantal rijen van de tabel (31.465) met de selectiviteit van het eerste predikaat (0,3) , en vermenigvuldigt dat vervolgens met de vierkantswortel van de selectiviteit van het tweede predikaat (~0.547723).
31.645 * (0,3) * SQRT (0,3) ~=5.170,227Dus nu kunnen we zien waar SQL Server met zijn schatting kwam; wat zijn enkele van de methoden die we kunnen gebruiken om er iets aan te doen?
- Geef datumparameters door. Indien mogelijk kunt u de toepassing wijzigen zodat deze de juiste datumparameters doorgeeft in plaats van afzonderlijke integer-parameters.
- Gebruik een wrapper-procedure. Een variatie op methode #1 - bijvoorbeeld als u de toepassing niet kunt wijzigen - zou zijn om een tweede opgeslagen procedure te maken die geconstrueerde datumparameters van de eerste accepteert.
- Gebruik
OPTION (RECOMPILE). Tegen de geringe kosten van compilatie elke keer dat de query wordt uitgevoerd, dwingt dit SQL Server om te optimaliseren op basis van de waarden die elke keer worden weergegeven, in plaats van een enkel plan te optimaliseren voor onbekende, eerste of gemiddelde parameterwaarden. (Voor een grondige behandeling van dit onderwerp, zie Paul White's "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Gebruik dynamische SQL. Dynamische SQL hebben om de geconstrueerde
datete accepteren variabele dwingt juiste parametrering af (net alsof je een opgeslagen procedure hebt aangeroepen met eendateparameter), maar het is een beetje lelijk en moeilijker te onderhouden.
- Knoei met hints en traceervlaggen. Paul White heeft het over enkele van deze in de bovengenoemde post.
Ik ga niet suggereren dat dit een uitputtende lijst is, en ik ga het advies van Paul over hints of traceervlaggen niet herhalen, dus ik zal me alleen concentreren op het laten zien hoe de eerste vier benaderingen het probleem met slechte schattingen kunnen verminderen .
1. Datumparameters
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Wikkelprocedure
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPTIE (HERCOMPILEREN)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamische SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
De testen
Met de vier sets procedures was het gemakkelijk om tests te maken die me de plannen en de schattingen die SQL Server had afgeleid, zouden laten zien. Omdat sommige maanden drukker zijn dan andere, heb ik drie verschillende maanden gekozen en ze allemaal meerdere keren uitgevoerd.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Het resultaat? Elk afzonderlijk plan levert dezelfde Index Seek op, maar de schattingen zijn alleen correct voor alle drie de periodes in de OPTION (RECOMPILE) versie. De rest blijft de schattingen gebruiken die zijn afgeleid van de eerste set parameters (juli 2012), en terwijl ze betere schattingen krijgen voor de eerste uitvoering, zal die schatting niet per se beter zijn voor vervolgens uitvoeringen met verschillende parameters (een klassiek schoolvoorbeeld van het snuiven van parameters):
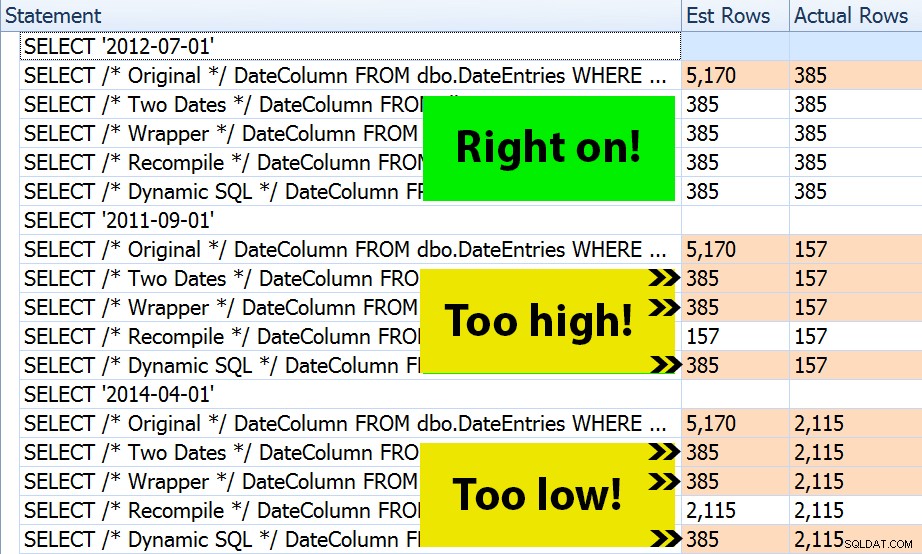
Merk op dat het bovenstaande geen *exacte* uitvoer is van SQL Sentry Plan Explorer - ik heb bijvoorbeeld de instructieboomrijen verwijderd die de buitenste opgeslagen procedureaanroepen en parameterdeclaraties lieten zien.
Het is aan jou om te bepalen of de tactiek van elke keer compileren het beste voor je is, of dat je in de eerste plaats iets moet "repareren". Hier eindigden we met dezelfde plannen en geen merkbare verschillen in runtime-prestatiestatistieken. Maar in grotere tabellen, met meer scheve gegevensverdeling en grotere varianties in predikaatwaarden (denk bijvoorbeeld aan een rapport dat een week, een jaar en alles daartussenin kan beslaan), kan het de moeite waard zijn om wat onderzoek te doen. En merk op dat u hier methoden kunt combineren - u kunt bijvoorbeeld overschakelen naar de juiste datumparameters *en* OPTION (RECOMPILE) toevoegen , als je wilde.
Conclusie
In dit specifieke geval, wat een opzettelijke vereenvoudiging is, heeft de inspanning om de juiste schattingen te krijgen niet echt vruchten afgeworpen - we kregen geen ander plan en de runtime-prestaties waren gelijkwaardig. Er zijn echter zeker andere gevallen waarin dit een verschil zal maken, en het is belangrijk om schattingsongelijkheid te herkennen en te bepalen of dit een probleem kan worden naarmate uw gegevens groeien en/of uw distributie scheef loopt. Helaas is er geen zwart-wit antwoord, omdat veel variabelen van invloed zijn op de vraag of compilatie-overhead gerechtvaardigd is - zoals bij veel scenario's, IT DEPENDS™ …