Ik schreef eerder over de eigenschap Actual Rows Read. Het vertelt u hoeveel rijen daadwerkelijk door een Index Seek worden gelezen, zodat u kunt zien hoe selectief het Seek-predikaat is, vergeleken met de selectiviteit van het Seek-predicaat plus het resterende predikaat samen.
Maar laten we eens kijken naar wat er werkelijk aan de hand is in de Seek-operator. Omdat ik er niet van overtuigd ben dat "Actual Rows Read" noodzakelijkerwijs een nauwkeurige beschrijving is van wat er aan de hand is.
Ik wil kijken naar een voorbeeld dat adressen van bepaalde adrestypes opvraagt voor een klant, maar het principe hier zou gemakkelijk van toepassing zijn op veel andere situaties als de vorm van uw zoekopdracht past, zoals het opzoeken van attributen in een Key-Value Pair-tabel, bijvoorbeeld.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Ik weet dat ik je niets over de metadata heb laten zien - ik kom daar zo op terug. Laten we eens nadenken over deze zoekopdracht en wat voor soort index we ervoor willen hebben.
Ten eerste kennen we de CustomerID precies. Een gelijkheidsmatch als deze maakt het over het algemeen een uitstekende kandidaat voor de eerste kolom in een index. Als we een index op deze kolom hadden, zouden we direct in de adressen van die klant kunnen duiken - dus ik zou zeggen dat dat een veilige veronderstelling is.
Het volgende dat u moet overwegen, is dat filter op AddressTypeID. Het toevoegen van een tweede kolom aan de sleutels van onze index is volkomen redelijk, dus laten we dat doen. Onze index staat nu aan (CustomerID, AddressTypeID). En laten we ook FullAddress OPNEMEN, zodat we geen zoekopdrachten hoeven uit te voeren om het plaatje compleet te maken.
En ik denk dat we klaar zijn. We zouden veilig moeten kunnen aannemen dat de ideale index voor deze zoekopdracht is:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
We zouden het mogelijk als een unieke index kunnen bestempelen - we zullen later kijken naar de impact daarvan.
Dus laten we een tabel maken (ik gebruik tempdb, omdat ik het niet nodig heb om verder te gaan dan deze blogpost) en dit uit te testen.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Ik ben niet geïnteresseerd in externe sleutelbeperkingen, of welke andere kolommen er zijn. Ik ben alleen geïnteresseerd in mijn Ideale Index. Dus creëer dat ook, als je dat nog niet hebt gedaan.
Mijn plan lijkt redelijk perfect.
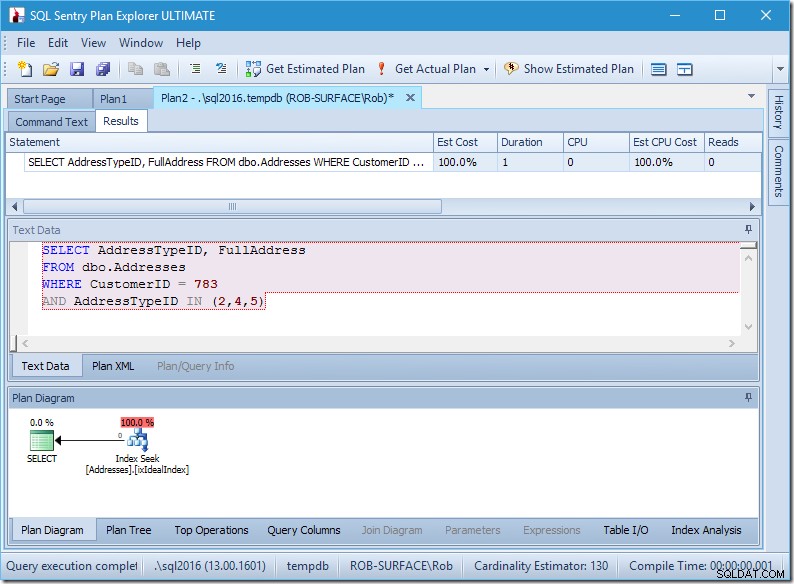
Ik heb een indexzoekopdracht, en dat is het.
Toegegeven, er zijn geen gegevens, dus er zijn geen leesbewerkingen, geen CPU, en het werkt ook vrij snel. Konden alle zoekopdrachten maar zo goed worden afgestemd.
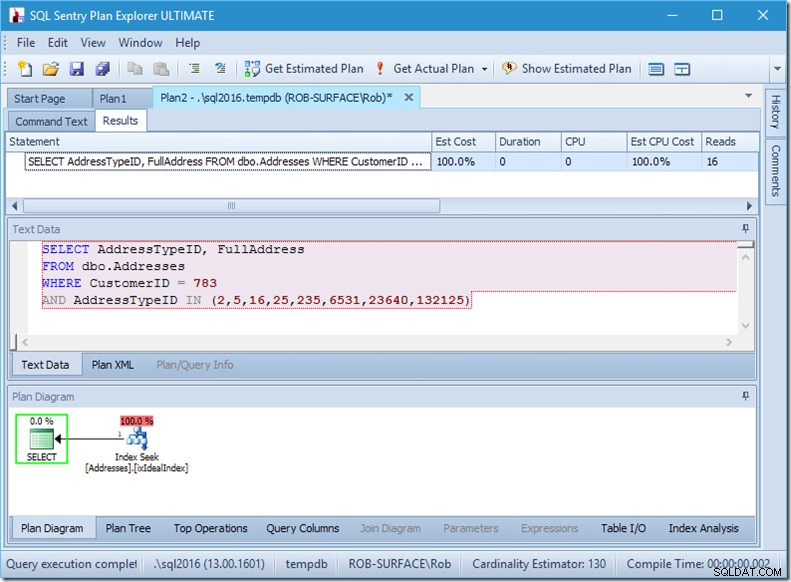
Laten we eens wat dichterbij kijken, door naar de eigenschappen van de Seek te kijken.
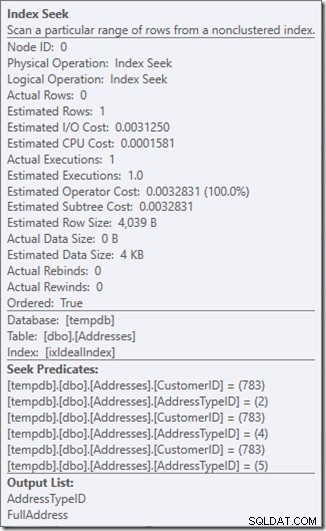
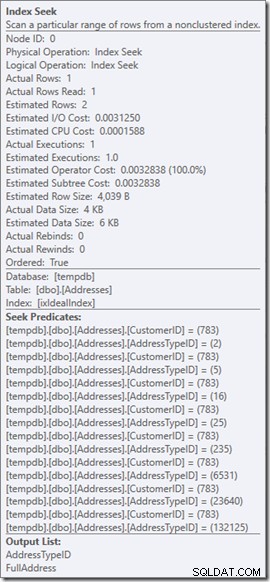
We kunnen de zoekpredikaten zien. Er zijn zes. Drie over de CustomerID en drie over de AddressTypeID. Wat we hier eigenlijk hebben, zijn drie sets zoekpredikaten, die drie zoekbewerkingen aangeven binnen de enkele zoekoperator. De eerste zoekactie is op zoek naar Klant 783 en Adrestype 2. De tweede zoekt naar 783 en 4, en de laatste 783 en 5. Onze zoekoperator verscheen één keer, maar er waren drie zoekacties binnenin.
We hebben niet eens gegevens, maar we kunnen zien hoe onze index zal worden gebruikt.
Laten we wat dummy-gegevens invoeren, zodat we een deel van de impact hiervan kunnen bekijken. Ik ga adressen invoeren voor typen 1 tot 6. Elke klant (meer dan 2000, gebaseerd op de grootte van master..spt_values ) zal een adres van type 1 hebben. Misschien is dat het primaire adres. Ik laat 80% een type 2-adres hebben, 60% een type 3, enzovoort, tot 20% voor type 5. Rij 783 krijgt adressen van type 1, 2, 3 en 4, maar niet 5. Ik zou liever met willekeurige waarden zijn gegaan, maar ik wil er zeker van zijn dat we op dezelfde pagina zitten voor de voorbeelden.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Laten we nu eens kijken naar onze zoekopdracht met gegevens. Er komen twee rijen uit. Het is zoals voorheen, maar we zien nu de twee rijen uit de Seek-operator komen en we zien zes lezingen (rechtsboven).
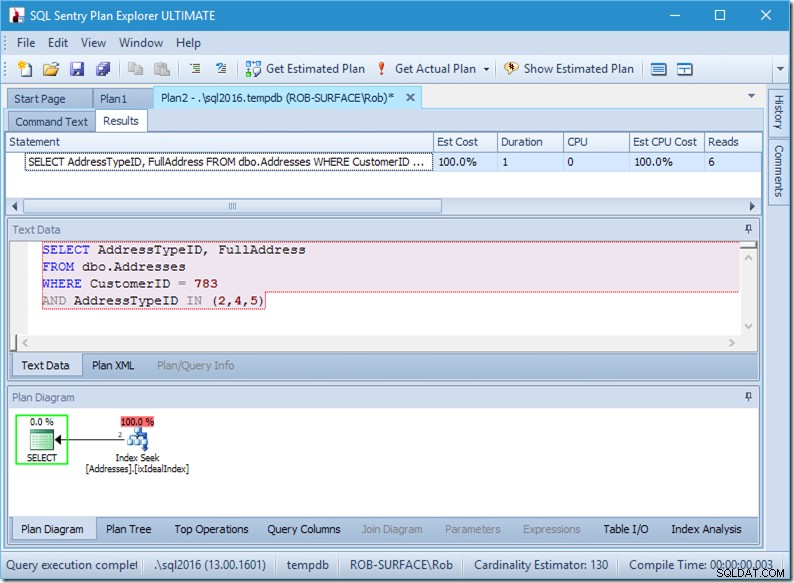
Six reads lijkt me logisch. We hebben een kleine tabel en de index past op slechts twee niveaus. We doen drie zoekopdrachten (binnen onze ene operator), dus de engine leest de hoofdpagina, zoekt uit naar welke pagina hij moet gaan en leest die, en doet dat drie keer.
Als we alleen naar twee AddressTypeID's zouden zoeken, zouden we slechts 4 reads zien (en in dit geval wordt een enkele rij uitgevoerd). Uitstekend.
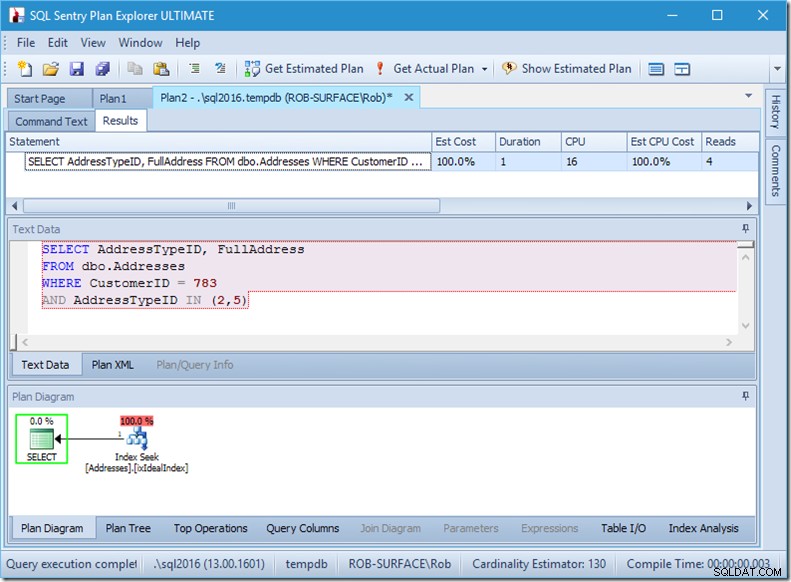
En als we naar 8 adrestypes zouden zoeken, dan zouden we er 16 zien.
Maar elk van deze laat zien dat de werkelijke rijen die worden gelezen exact overeenkomen met de werkelijke rijen. Helemaal geen inefficiëntie!
Laten we teruggaan naar onze oorspronkelijke zoekopdracht, op zoek naar adrestypes 2, 4 en 5 (die 2 rijen retourneert) en nadenken over wat er binnen de zoekopdracht gebeurt.
Ik ga ervan uit dat de Query Engine al het werk heeft gedaan om erachter te komen dat de Index Seek de juiste operatie is en dat het paginanummer van de indexroot bij de hand is.
Op dit punt laadt het die pagina in het geheugen, als het er nog niet is. Dat is de eerste lezing die wordt geteld bij de uitvoering van de zoekopdracht. Vervolgens zoekt het het paginanummer voor de rij waarnaar het zoekt en leest het die pagina in. Dat is de tweede keer dat het wordt gelezen.
Maar we verdoezelen vaak dat stukje 'vindt het paginanummer'.
Door gebruik te maken van DBCC IND(2, N'dbo.Address', 2); (de eerste 2 is de database-ID omdat ik tempdb gebruik; de tweede 2 is de index-id van ixIdealIndex ), kan ik ontdekken dat de 712 in bestand 1 de pagina is met het hoogste IndexLevel. In de onderstaande schermafbeelding kan ik zien dat pagina 668 IndexLevel 0 is, wat de hoofdpagina is.

Dus nu kan ik DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); om de inhoud van pagina 712 te zien. Op mijn computer krijg ik 84 rijen die terugkomen, en ik kan zien dat CustomerID 783 op pagina 1004 van bestand 5 zal staan.
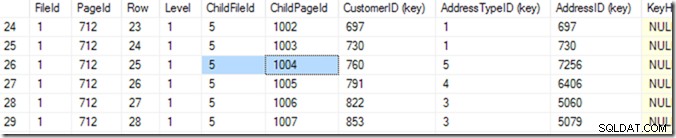
Maar ik weet dit door door mijn lijst te scrollen totdat ik degene zie die ik wil. Ik begon een beetje naar beneden te scrollen en kwam toen weer omhoog, totdat ik de rij vond die ik wilde. Een computer noemt dit een binaire zoekopdracht, en het is een beetje nauwkeuriger dan ik. Het zoekt naar de rij waar de combinatie (CustomerID, AddressTypeID) kleiner is dan degene die ik zoek, waarbij de volgende pagina groter of hetzelfde is. Ik zeg "hetzelfde" omdat er twee kunnen zijn die overeenkomen, verspreid over twee pagina's. Het weet dat er 84 rijen (0 tot 83) met gegevens op die pagina staan (het leest dat in de paginakoptekst), dus het begint met het controleren van rij 41. Van daaruit weet het in welke helft hij moet zoeken, en (in dit voorbeeld), zal het rij 20 lezen. Nog een paar keer gelezen (in totaal 6 of 7)* en het weet die rij 25 (kijk naar de kolom met de naam 'Rij' voor deze waarde, niet het rijnummer dat door SSMS is opgegeven ) is te klein, maar rij 26 is te groot – dus 25 is het antwoord!
*Bij een binaire zoekopdracht kan het zoeken iets sneller zijn als het geluk heeft wanneer het blok in tweeën wordt gesplitst als er geen middelste slot is, en afhankelijk van of het middelste slot kan worden geëlimineerd of niet.
Nu kan het naar pagina 1004 in bestand 5 gaan. Laten we daar DBCC PAGE op gebruiken.
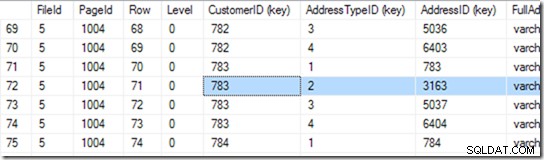
Deze geeft me 94 rijen. Het doet nog een binaire zoekopdracht om het begin van het bereik te vinden waarnaar het op zoek is. Het moet door 6 of 7 rijen kijken om dat te vinden.
“Begin van het assortiment?” Ik hoor je vragen. Maar we zoeken adrestype 2 van klant 783.
Klopt, maar we hebben deze index niet als uniek verklaard. Het kunnen er dus twee zijn. Als het uniek is, kan de seeker een singleton-zoekopdracht uitvoeren en kan hij deze tegenkomen tijdens de binaire zoekopdracht, maar in dit geval moet hij de binaire zoekopdracht voltooien om de eerste rij in het bereik te vinden. In dit geval is dat rij 71.
Maar we stoppen hier niet. Nu moeten we kijken of er echt een tweede is! Dus het leest ook rij 72 en vindt dat het CustomerID+AddressTypeiD-paar inderdaad te groot is, en het zoeken is voltooid.
En dit gebeurt drie keer. De derde keer vindt hij geen rij voor klant 783 en adrestype 5, maar hij weet dit niet van tevoren en moet het zoeken nog voltooien.
Dus de rijen die daadwerkelijk over deze drie zoekopdrachten worden gelezen (om twee rijen te vinden om uit te voeren) zijn veel meer dan het aantal dat wordt geretourneerd. Er zijn er ongeveer 7 op indexniveau 1 en nog ongeveer 7 op bladniveau om het begin van het bereik te vinden. Dan leest het de rij waar we om geven, en dan de rij daarna. Dat klinkt meer als 16 voor mij, en het doet dit drie keer, ongeveer 48 rijen makend.
Maar Actual Rows Read gaat niet over het aantal rijen dat daadwerkelijk wordt gelezen, maar over het aantal rijen dat wordt geretourneerd door het Seek-predicaat, dat wordt getest met het Residual-predicaat. En daarin worden alleen de 2 rijen gevonden door de 3 zoekacties.
Je zou op dit moment kunnen denken dat hier een zekere mate van ineffectiviteit is. De tweede zoekactie zou ook pagina 712 hebben gelezen, dezelfde 6 of 7 rijen daar hebben gecontroleerd, en dan pagina 1004 hebben gelezen, en er doorheen gejaagd... net als de derde zoekactie.
Dus misschien was het beter geweest om dit in één keer te krijgen, door pagina 712 en pagina 1004 elk maar één keer te lezen. Per slot van rekening zou ik, als ik dit met een op papier gebaseerd systeem zou doen, hebben geprobeerd klant 783 te vinden en vervolgens al hun adrestypen hebben gescand. Omdat ik weet dat een klant niet veel adressen heeft. Dat is een voordeel dat ik heb ten opzichte van de database-engine. De database-engine weet door middel van zijn statistieken dat zoeken het beste is, maar hij weet niet dat het zoeken maar één niveau moet dalen, wanneer het kan zien dat het de ideale index heeft.
Als ik mijn zoekopdracht verander om een reeks adrestypes te pakken, van 2 tot 5, dan krijg ik bijna het gewenste gedrag:
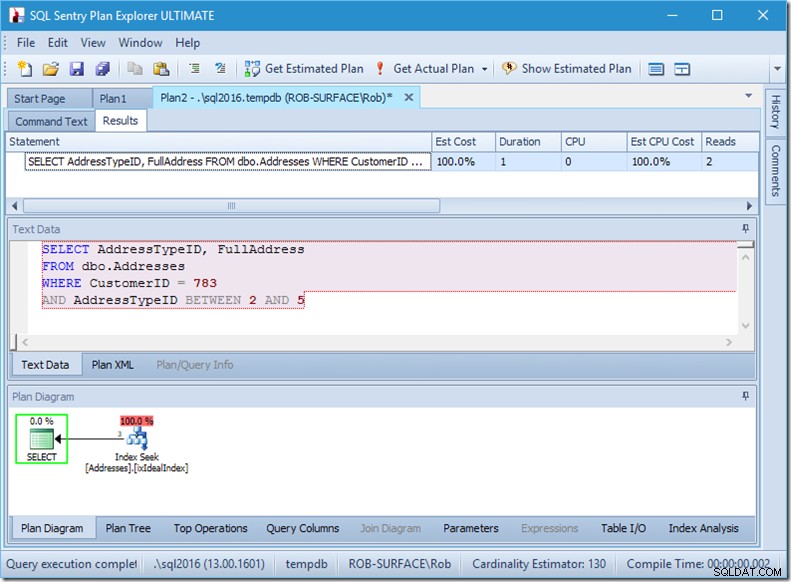
Kijk - het aantal leesbeurten is gedaald tot 2, en ik weet welke pagina's het zijn...
... maar mijn resultaten zijn verkeerd. Omdat ik alleen adrestypes 2, 4 en 5 wil, niet 3. Ik moet zeggen dat het er geen 3 moet hebben, maar ik moet voorzichtig zijn hoe ik dit doe. Bekijk de volgende twee voorbeelden.
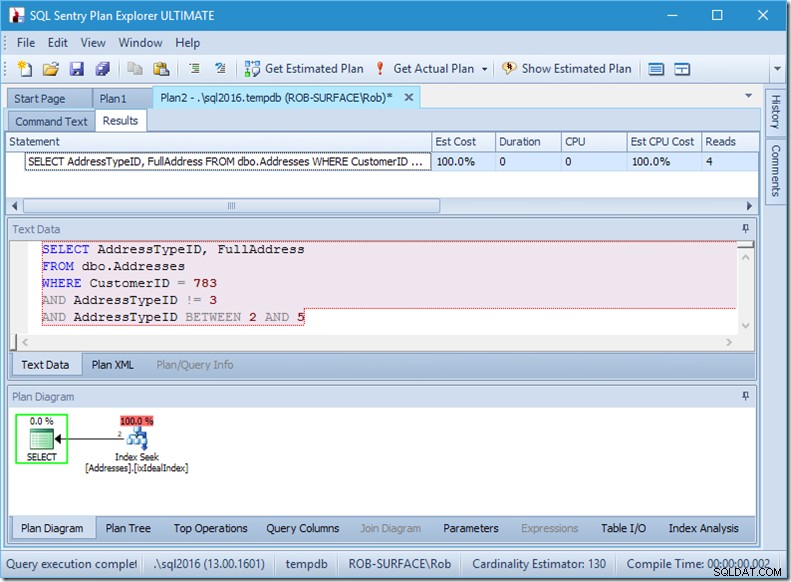
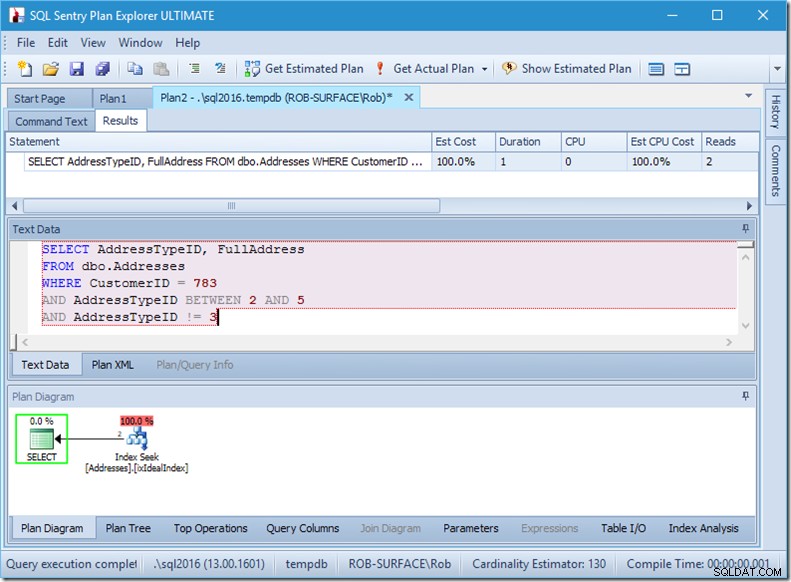
Ik kan je verzekeren dat de predikaatvolgorde er niet toe doet, maar hier duidelijk wel. Als we de "niet 3" eerst plaatsen, doet het twee zoekopdrachten (4 keer gelezen), maar als we de "niet 3" als tweede plaatsen, doet het een enkele zoekopdracht (2 keer gelezen).
Het probleem is dat AddressTypeID !=3 wordt geconverteerd naar (AddressTypeID> 3 OR AddressTypeID <3), wat dan wordt gezien als twee zeer nuttige zoekpredikaten.
Dus mijn voorkeur gaat uit naar het gebruik van een niet-sargable predikaat om aan te geven dat ik alleen adrestypes 2, 4 en 5 wil. En ik kan dat doen door AddressTypeID op de een of andere manier aan te passen, zoals er nul aan toevoegen.
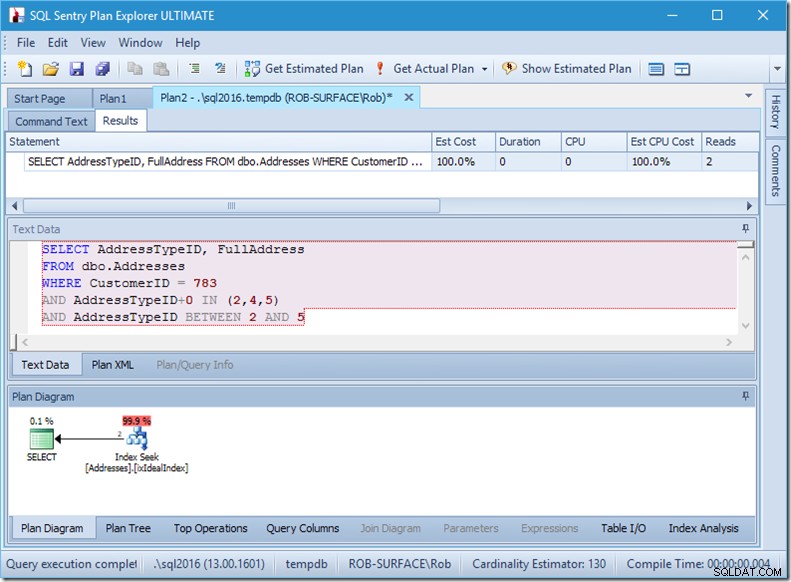
Nu heb ik een mooie en strakke scan van het bereik binnen een enkele zoekopdracht, en ik zorg er nog steeds voor dat mijn zoekopdracht alleen de rijen retourneert die ik wil.
Oh, maar dat eigendom van Actual Rows Read? Dat is nu hoger dan de eigenschap Actual Rows, omdat het Seek-predicaat adrestype 3 vindt, dat het Residual-predicaat verwerpt.
Ik heb drie perfecte zoekopdrachten geruild voor een enkele imperfecte zoekopdracht, die ik oplos met een resterend predikaat.
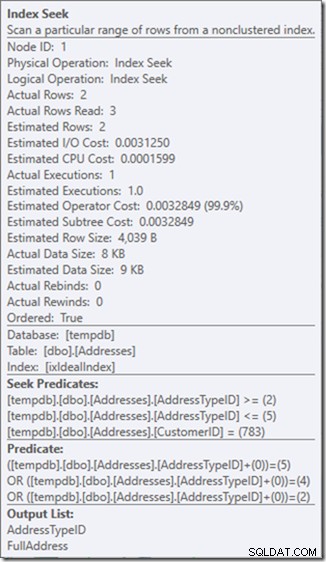
En voor mij is dat soms een prijs die het waard is om te betalen, waardoor ik een queryplan krijg waar ik veel gelukkiger mee ben. Het is niet aanzienlijk goedkoper, ook al heeft het slechts een derde van de reads (omdat er maar twee fysieke reads zouden zijn), maar als ik denk aan het werk dat het doet, voel ik me veel meer op mijn gemak met wat ik het vraag om op deze manier te doen.