Inleiding
Een Eager Index Spool leest alle rijen van de onderliggende operator in een geïndexeerde werktabel, voordat het rijen terugstuurt naar de bovenliggende operator. In sommige opzichten is een enthousiaste indexspoel de ultieme ontbrekende indexsuggestie , maar het wordt niet als zodanig gerapporteerd.
Kostenbeoordeling
Het invoegen van rijen in een geïndexeerde werktabel is relatief goedkoop, maar niet gratis. De optimizer moet er rekening mee houden dat het werk meer bespaart dan het kost. Om dat in het voordeel van de spoel uit te werken, moet het plan worden geschat om meer dan eens rijen van de spoel te verbruiken. Anders kan het net zo goed de spoel overslaan en de onderliggende bewerking die ene keer uitvoeren.
- Om meer dan één keer toegang te krijgen, moet de spool zich aan de binnenkant van een geneste lus-join-operator bevinden.
- Elke iteratie van de lus moet zoeken naar een bepaalde index-spoolsleutelwaarde die wordt geleverd door de buitenkant van de lus.
Dat betekent dat de join een apply . moet zijn , geen geneste loops join . Voor het verschil tussen de twee, zie mijn artikel Apply versus Nested Loops Join.
Opmerkelijke kenmerken
Terwijl een enthousiaste indexspoel alleen aan de binnenkant van een geneste lus verschijnt, pas toe , het is geen "prestatiespoel". Een enthousiaste indexspoel kan niet worden uitgeschakeld met traceringsvlag 8690 of de NO_PERFORMANCE_SPOOL vraaghint.
Rijen die in de indexspoel worden ingevoegd, worden normaal gesproken niet vooraf gesorteerd in de volgorde van de indexsleutels, wat kan leiden tot splitsingen van indexpagina's. Ongedocumenteerde traceervlag 9260 kan worden gebruikt om een Sorteren . te genereren operator vóór de indexspoel om dit te voorkomen. Het nadeel is dat de extra sorteerkosten de optimizer ervan kunnen weerhouden de spoeloptie te kiezen.
SQL Server ondersteunt geen parallelle invoegingen in een b-tree-index. Dit betekent dat alles onder een parallelle gretige indexspoel op een enkele thread draait. De operators onder de spoel zijn nog steeds (misleidend) gemarkeerd met het parallellisme-pictogram. Er is één thread gekozen om te schrijven naar de spoel. De andere threads wachten op EXECSYNC terwijl dat voltooid is. Zodra de spoel is gevuld, kan deze worden gelezen uit door parallelle draden.
Indexspoelen vertellen de optimizer niet dat ze uitvoer ondersteunen die is gerangschikt op basis van de indexsleutels van de spoel. Als gesorteerde uitvoer van de spool vereist is, ziet u mogelijk een onnodige Sorteren exploitant. Enthousiaste indexspoelen moeten hoe dan ook vaak worden vervangen door een permanente index, dus dit is meestal een kleine zorg.
Er zijn vijf optimalisatieregels die een Eager Index Spool kunnen genereren optie (intern bekend als een index on-the-fly ). We zullen er drie in detail bekijken om te begrijpen waar enthousiaste indexspoelen vandaan komen.
SelToIndexOnTheFly
Dit is de meest voorkomende. Het komt overeen met een of meer relationele selecties (ook wel filters of predikaten genoemd) net boven een operator voor gegevenstoegang. De SelToIndexOnTheFly regel vervangt de predikaten door een seek-predikaat op een enthousiaste indexspoel.
Demo
Een AdventureWorks voorbeeld database voorbeeld wordt hieronder getoond:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
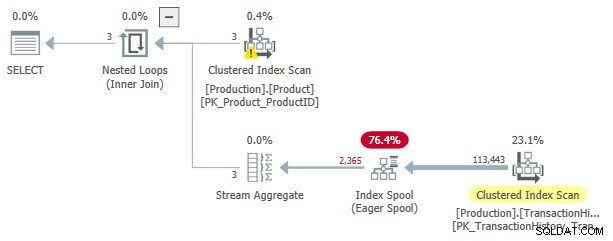
Dit uitvoeringsplan kost naar schatting 3.0881 eenheden. Enkele aandachtspunten:
- De Nested Loops Inner Join operator is een solliciteer , met
ProductIDenSafetyStockLevelvan hetProducttabel als buitenste referenties . - Bij de eerste iteratie van de toepassing, de Eager Index Spool is volledig ingevuld vanuit de geclusterde indexscan van de
TransactionHistorytafel. - De werktabel van de spoel heeft een geclusterde index die is ingetoetst op
(ProductID, Quantity). - Rijen die overeenkomen met de predikaten
TH.ProductID = P.ProductIDenTH.Quantity < P.SafetyStockLevelworden beantwoord door de spoel met behulp van zijn index. Dit geldt voor elke iteratie van de toepassing, inclusief de eerste. - De
TransactionHistorytabel wordt maar één keer gescand.
Gesorteerde invoer op de spoel
Het is mogelijk om gesorteerde invoer af te dwingen naar de enthousiaste indexspoel, maar dit heeft wel invloed op de geschatte kosten, zoals opgemerkt in de inleiding. Voor het bovenstaande voorbeeld levert het inschakelen van de ongedocumenteerde traceringsvlag een plan op zonder een spoel:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
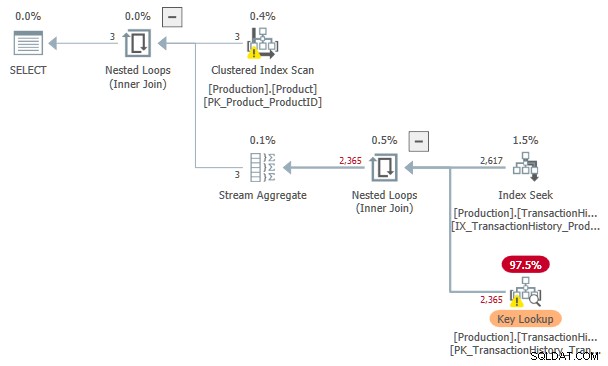
De geschatte kosten van deze Index Seek en Key Lookup plan is 3.11631 eenheden. Dit is meer dan de kosten van het abonnement met alleen een indexspoel, maar minder dan het abonnement met een indexspoel en gesorteerde invoer.
Om een plan met gesorteerde invoer naar de spool te zien, moeten we het verwachte aantal lus-iteraties verhogen. Dit geeft de spoel de kans om de extra kosten van de Sorteren . terug te betalen . Een manier om het aantal verwachte rijen van het Product uit te breiden tabel is om de Name predikaat minder beperkend:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
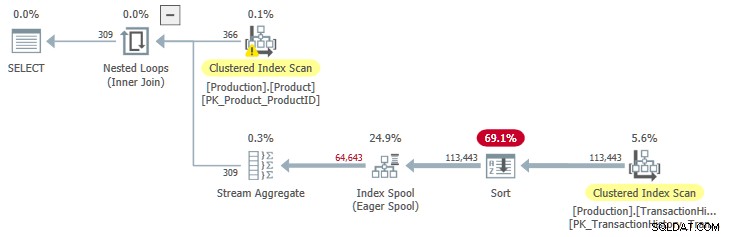
OPTION (QUERYTRACEON 9260); Dit geeft ons een uitvoeringsplan met gesorteerde invoer naar de spoel:
JoinToIndexOnTheFly
Deze regel transformeert een inner join op een solliciteer , met een gretige indexspoel aan de binnenkant. Ten minste één van de join-predikaten moet een ongelijkheid zijn om aan deze regel te voldoen.
Dit is een veel meer gespecialiseerde regel dan SelToIndexOnTheFly , maar het idee is ongeveer hetzelfde. In dit geval wordt de selectie (predikaat) die wordt getransformeerd naar een index-spool-zoekopdracht, gekoppeld aan de join. De transformatie van join naar apply staat toe dat het join-predikaat van de join zelf naar de binnenkant van de toepassing wordt verplaatst.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
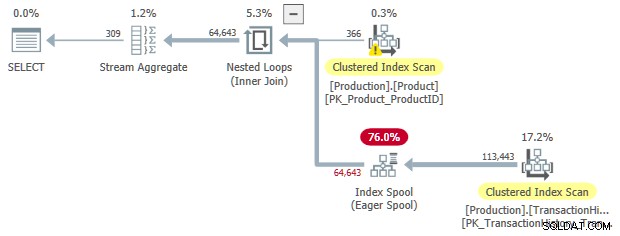
Net als voorheen kunnen we gesorteerde invoer op de spoel vragen:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
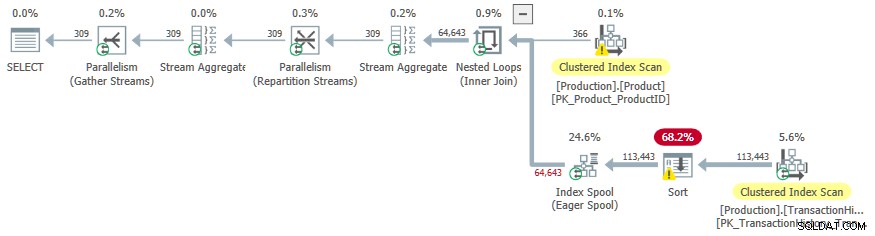
Deze keer hebben de extra sorteerkosten de optimizer ertoe aangezet om een parallel plan te kiezen.
Een ongewenst neveneffect is het Sorteren operator morst naar tempdb . De totale geheugentoekenning die beschikbaar is voor het sorteren is voldoende, maar wordt gelijkelijk verdeeld over parallelle threads (zoals gebruikelijk). Zoals opgemerkt in de inleiding, ondersteunt SQL Server geen parallelle invoegingen in een b-tree-index, dus de operators onder de enthousiaste index-spool draaien op een enkele thread. Deze enkele thread krijgt maar een fractie van de geheugentoelage, dus de Sorteren morst naar tempdb .
Deze bijwerking is misschien een van de redenen waarom de traceervlag niet is gedocumenteerd en niet wordt ondersteund.
SelSTVFToIdxOnFly
Deze regel doet hetzelfde als SelToIndexOnTheFly , maar voor een functie met streamingtabelwaarde (sTVF) rijbron. Deze sTVF's worden intern veel gebruikt om onder andere DMV's en DMF's te implementeren. Ze verschijnen in moderne uitvoeringsplannen als Tabel gewaardeerde functie operators (oorspronkelijk als externe tabelscans ).
In het verleden konden veel van deze sTVF's geen gecorreleerde parameters van een apply accepteren. Ze kunnen letterlijke waarden, variabelen en moduleparameters accepteren, maar niet toepassen uiterlijke referenties. Er zijn nog steeds waarschuwingen hierover in de documentatie, maar die zijn nu enigszins verouderd.
Hoe dan ook, het punt is dat het soms niet mogelijk is voor SQL Server om een apply door te geven buitenste referentie als parameter naar een sTVF. In die situatie kan het zinvol zijn om een deel van het sTVF-resultaat te materialiseren in een enthousiaste indexspoel. De huidige regel biedt die mogelijkheid.
Demo
Het volgende codevoorbeeld toont een DMV-query die met succes is geconverteerd van een join naar een apply . Buitenste referenties worden als parameters doorgegeven aan de tweede DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
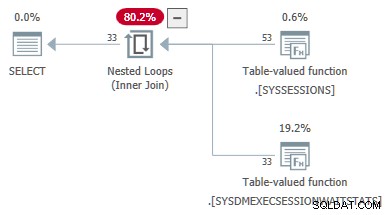
De planeigenschappen van de wachtstatistieken TVF tonen de invoerparameters. De tweede parameterwaarde wordt geleverd als een buitenste referentie van de sessies DMV:
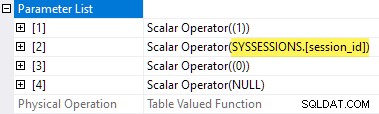
Het is jammer dat sys.dm_exec_session_wait_stats is een weergave, geen functie, want dat verhindert ons om een apply . te schrijven rechtstreeks.
Het herschrijven hieronder is voldoende om de interne conversie teniet te doen:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Met de session_id predikaten die nu niet als parameters worden gebruikt, de SelSTVFToIdxOnFly regel is vrij om ze te converteren naar een enthousiaste indexspoel:
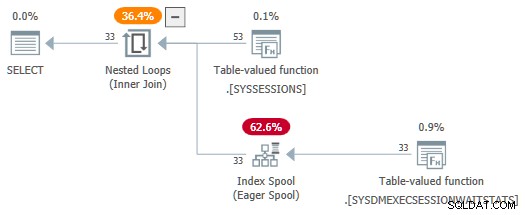
Ik wil je niet de indruk geven dat lastige herschrijvingen nodig zijn om een enthousiaste indexspoel over een DMV-bron te krijgen - het zorgt alleen maar voor een eenvoudigere demo. Als je toevallig een zoekopdracht tegenkomt met DMV-joins die een plan met een enthousiaste spoel oplevert, weet je tenminste hoe het daar is gekomen.
U kunt geen indexen maken op DMV's, dus u moet mogelijk een hash- of merge-join gebruiken als het uitvoeringsplan niet goed genoeg presteert.
Recursieve CTE's
De overige twee regels zijn SelIterToIdxOnFly en JoinIterToIdxOnFly . Ze zijn directe tegenhangers van SelToIndexOnTheFly en JoinToIndexOnTheFly voor recursieve CTE-gegevensbronnen. Deze zijn uiterst zeldzaam in mijn ervaring, dus ik ga er geen demo's voor geven. (Zo maar de Iter een deel van de regelnaam is logisch:het komt voort uit het feit dat SQL Server staartrecursie implementeert als geneste iteratie.)
Wanneer meerdere keren naar een recursieve CTE wordt verwezen aan de binnenkant van een toepassing, wordt een andere regel (SpoolOnIterator ) kan het resultaat van de CTE cachen:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Het uitvoeringsplan bevat een zeldzame Eager Row Count Spool :
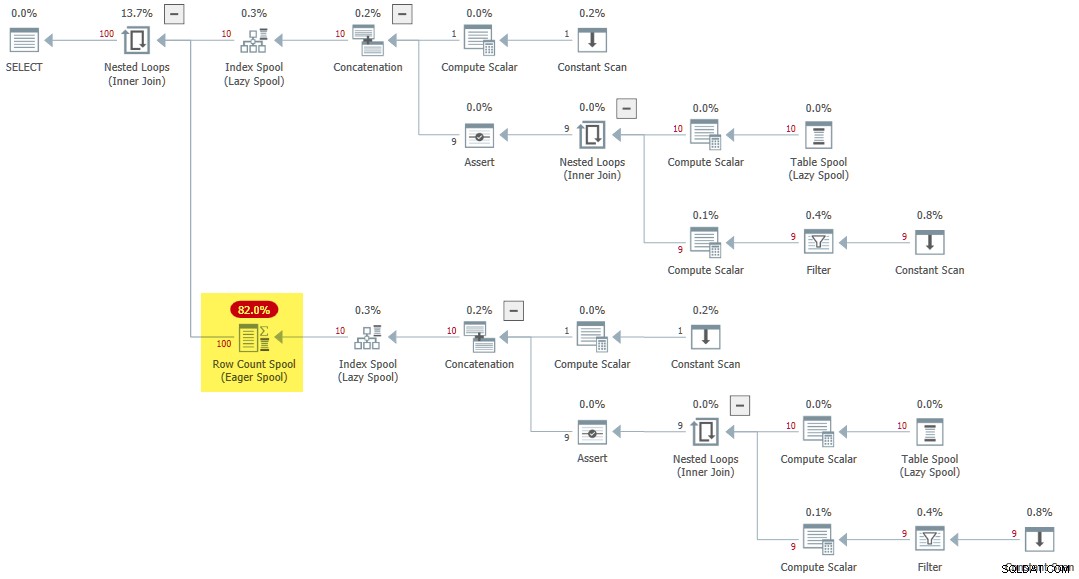
Laatste gedachten
Enthousiaste indexspoelen zijn vaak een teken dat er een bruikbare permanente index ontbreekt in het databaseschema. Dit is niet altijd het geval, zoals blijkt uit de voorbeelden van functies met streamingtabelwaarde.