In deel 1 en deel 2 van deze serie heb ik de logische of conceptuele aspecten van benoemde tabeluitdrukkingen in het algemeen en afgeleide tabellen in het bijzonder behandeld. Deze maand en de volgende ga ik de fysieke verwerkingsaspecten van afgeleide tabellen behandelen. Herinner uit deel 1 de onafhankelijkheid van fysieke gegevens principe van de relationele theorie. Het relationele model en de standaard opvraagtaal die erop gebaseerd is, wordt verondersteld alleen de conceptuele aspecten van de gegevens te behandelen en de fysieke implementatiedetails zoals opslag, optimalisatie, toegang en verwerking van de gegevens over te laten aan het databaseplatform (de implementatie ). In tegenstelling tot de conceptuele behandeling van de gegevens, die gebaseerd is op een wiskundig model en een standaardtaal, en daarom erg op elkaar lijkt in de verschillende relationele databasebeheersystemen die er zijn, is de fysieke behandeling van de gegevens niet gebaseerd op enige standaard, en heeft daarom de neiging zeer platformspecifiek zijn. In mijn verslag van de fysieke behandeling van benoemde tabeluitdrukkingen in de serie richt ik me op de behandeling in Microsoft SQL Server en Azure SQL Database. De fysieke behandeling in andere databaseplatforms kan heel anders zijn.
Bedenk dat de aanleiding voor deze reeks enige verwarring is die in de SQL Server-gemeenschap bestaat rond benoemde tabelexpressies. Zowel qua terminologie als qua optimalisatie. Ik heb enkele terminologische overwegingen behandeld in de eerste twee delen van de serie, en zal in toekomstige artikelen meer behandelen bij het bespreken van CTE's, standpunten en inline TVF's. Wat betreft de optimalisatie van benoemde tabeluitdrukkingen, bestaat er verwarring rond de volgende items (ik noem hier afgeleide tabellen omdat dat de focus van dit artikel is):
- Persistentie: Staat er ergens een afgeleide tabel? Blijft het op schijf staan en hoe verwerkt SQL Server het geheugen ervoor?
- Kolomprojectie: Hoe werkt indexovereenkomsten met afgeleide tabellen? Als een afgeleide tabel bijvoorbeeld een bepaalde subset van kolommen uit een onderliggende tabel projecteert en de buitenste query een subset van de kolommen uit de afgeleide tabel projecteert, is SQL Server dan slim genoeg om optimale indexering te berekenen op basis van de uiteindelijke subset van kolommen dat is echt nodig? En hoe zit het met machtigingen; heeft de gebruiker machtigingen nodig voor alle kolommen waarnaar wordt verwezen in de inner queries, of alleen voor de laatste die echt nodig zijn?
- Meerdere verwijzingen naar kolomaliassen: Als de afgeleide tabel een resultaatkolom heeft die is gebaseerd op een niet-deterministische berekening, bijvoorbeeld een aanroep van de functie SYSDATETIME, en de buitenste query heeft meerdere verwijzingen naar die kolom, wordt de berekening dan slechts één keer uitgevoerd, of afzonderlijk voor elke buitenste verwijzing ?
- Unnesting/substitutie/inlining: Verwijdert SQL Server, of inline, de afgeleide tabelquery? Dat wil zeggen, voert SQL Server een vervangingsproces uit waarbij de oorspronkelijke geneste code wordt omgezet in één query die rechtstreeks ingaat tegen de basistabellen? En als dat zo is, is er dan een manier om SQL Server te instrueren om dit proces voor het verwijderen van nesten te voorkomen?
Dit zijn allemaal belangrijke vragen en de antwoorden op deze vragen hebben aanzienlijke gevolgen voor de prestaties, dus het is een goed idee om een duidelijk begrip te hebben van hoe deze items worden afgehandeld in SQL Server. Deze maand ga ik de eerste drie items behandelen. Er is nogal wat te zeggen over het vierde item, dus ik zal er volgende maand een apart artikel aan wijden (deel 4).
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat TSQLV5 maakt en vult hier, en het ER-diagram hier.
Persistentie
Sommige mensen gaan er intuïtief van uit dat SQL Server het resultaat van het tabelexpressiegedeelte van de afgeleide tabel (het resultaat van de innerlijke query) in een werktabel bewaart. Op de datum van dit schrijven is dat niet het geval; Aangezien persistentieoverwegingen echter de keuze van een leverancier zijn, zou Microsoft kunnen besluiten dit in de toekomst te veranderen. SQL Server is inderdaad in staat om tussentijdse queryresultaten in werktabellen (meestal in tempdb) te bewaren als onderdeel van de queryverwerking. Als het ervoor kiest om dit te doen, ziet u een vorm van een spool-operator in het plan (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). De keuze van SQL Server om al dan niet iets in een werktabel te spoolen, heeft momenteel echter niets te maken met uw gebruik van benoemde tabelexpressies in de query. SQL Server spoolt soms tussentijdse resultaten om prestatieredenen, zoals het vermijden van herhaald werk (hoewel momenteel niet gerelateerd aan het gebruik van benoemde tabeluitdrukkingen), en soms om andere redenen, zoals Halloween-beveiliging.
Zoals gezegd, ga ik volgende maand in op de details van het verwijderen van afgeleide tabellen. Voor nu volstaat het om te zeggen dat SQL Server normaal gesproken een unnesting/inlining-proces toepast op afgeleide tabellen, waarbij het de geneste queries vervangt door een query tegen de onderliggende basistabellen. Nou, ik oversimplificeer een beetje. Het is niet zo dat SQL Server de oorspronkelijke T-SQL-querystring met de afgeleide tabellen letterlijk converteert naar een nieuwe querystring zonder deze; in plaats daarvan past SQL Server transformaties toe op een interne logische boomstructuur van operators, en het resultaat is dat de afgeleide tabellen in feite meestal niet worden genest. Wanneer u naar een uitvoeringsplan kijkt voor een query met afgeleide tabellen, ziet u daar geen melding van omdat ze voor de meeste optimalisatiedoeleinden niet bestaan. U ziet toegang tot de fysieke structuren die de gegevens bevatten voor de onderliggende basistabellen (heap, B-tree rowstore-indexen en columnstore-indexen voor schijfgebaseerde tabellen en tree- en hash-indexen voor geheugengeoptimaliseerde tabellen).
Er zijn gevallen die voorkomen dat SQL Server een afgeleide tabel ongedaan maakt, maar zelfs in die gevallen zet SQL Server het resultaat van de tabelexpressie niet voort in een werktabel. Ik zal de details samen met voorbeelden volgende maand verstrekken.
Aangezien SQL Server afgeleide tabellen niet aanhoudt, maar rechtstreeks samenwerkt met de fysieke structuren die de gegevens voor de onderliggende basistabellen bevatten, is de vraag over hoe geheugen wordt verwerkt voor afgeleide tabellen onbespreekbaar. Als de onderliggende basistabellen schijfgebaseerde tabellen zijn, moeten hun relevante pagina's in de bufferpool worden verwerkt. Als de onderliggende tabellen voor het geheugen zijn geoptimaliseerd, moeten hun relevante rijen in het geheugen worden verwerkt. Maar dat is niet anders dan wanneer je zelf de onderliggende tabellen opvraagt zonder afgeleide tabellen te gebruiken. Er is hier dus niets bijzonders. Wanneer u afgeleide tabellen gebruikt, hoeft SQL Server daarvoor geen speciale geheugenoverwegingen toe te passen. Voor de meeste doeleinden voor zoekopdrachtoptimalisatie bestaan ze niet.
Als u het resultaat van een tussenliggende stap in een werktabel moet behouden, moet u tijdelijke tabellen of tabelvariabelen gebruiken, geen benoemde tabeluitdrukkingen.
Kolomprojectie en een woord op SELECT *
Projectie is een van de oorspronkelijke operatoren van relationele algebra. Stel je hebt een relatie R1 met attributen x, y en z. De projectie van R1 op een deelverzameling van zijn attributen, bijv. x en z, is een nieuwe relatie R2, waarvan de kop de deelverzameling is van geprojecteerde attributen van R1 (x en z in ons geval), en waarvan het lichaam de set van tupels is gevormd uit de originele combinatie van geprojecteerde attribuutwaarden van de tupels van R1.
Bedenk dat het lichaam van een relatie - een verzameling tupels - per definitie geen duplicaten heeft. Het spreekt dus voor zich dat de tupels van de resultaatrelatie de onderscheiden combinatie zijn van attribuutwaarden die worden geprojecteerd vanuit de oorspronkelijke relatie. Onthoud echter dat de hoofdtekst van een tabel in SQL een multiset van rijen is en geen set, en normaal gesproken verwijdert SQL geen dubbele rijen, tenzij u het opdracht geeft. Gegeven een tabel R1 met kolommen x, y en z, kan de volgende query mogelijk dubbele rijen retourneren, en volgt daarom niet de semantiek van de projectie-operator van relationele algebra voor het retourneren van een set:
SELECT x, z FROM R1;
Door een DISTINCT-clausule toe te voegen, elimineert u dubbele rijen en volgt u de semantiek van relationele projectie nauwkeuriger:
SELECT DISTINCT x, z FROM R1;
Natuurlijk zijn er gevallen waarin u weet dat het resultaat van uw zoekopdracht verschillende rijen heeft zonder dat er een DISTINCT-clausule nodig is, bijvoorbeeld wanneer een subset van de kolommen die u retourneert, een sleutel uit de opgevraagde tabel bevat. Als x bijvoorbeeld een sleutel is in R1, zijn de bovenstaande twee zoekopdrachten logisch equivalent.
Denk in ieder geval aan de vragen die ik eerder noemde over de optimalisatie van query's met afgeleide tabellen en kolomprojectie. Hoe werkt indexmatching? Als een afgeleide tabel een bepaalde subset van kolommen uit een onderliggende tabel projecteert, en de buitenste query een subset van de kolommen uit de afgeleide tabel projecteert, is SQL Server dan slim genoeg om optimale indexering te berekenen op basis van de uiteindelijke subset van kolommen die eigenlijk nodig zijn? En hoe zit het met machtigingen; heeft de gebruiker machtigingen nodig voor alle kolommen waarnaar wordt verwezen in de inner queries, of alleen voor de laatste die echt nodig zijn? Stel ook dat de tabelexpressiequery een resultaatkolom definieert die is gebaseerd op een berekening, maar dat de buitenste query die kolom niet projecteert. Is de berekening überhaupt geëvalueerd?
Laten we beginnen met de laatste vraag, laten we het proberen. Overweeg de volgende vraag:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Zoals je zou verwachten, mislukt deze query met een fout door delen door nul:
Msg 8134, Level 16, State 1Delen door nul opgetreden fout.
Definieer vervolgens een afgeleide tabel met de naam D op basis van de bovenstaande query, en in het buitenste queryproject D alleen op custid en stad, zoals zo:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Zoals vermeld, past SQL Server normaal gesproken unnesting/substitutie toe, en aangezien er niets in deze query is dat unnesting verhindert (meer hierover volgende maand), komt de bovenstaande query overeen met de volgende query:
SELECT custid, city FROM Sales.Customers;
Nogmaals, ik oversimplificeer hier een beetje. De realiteit is een beetje ingewikkelder dan dat deze twee vragen als echt identiek worden beschouwd, maar ik kom volgende maand op die complexiteiten. Het punt is dat de uitdrukking 1/0 niet eens voorkomt in het uitvoeringsplan van de query en helemaal niet wordt geëvalueerd, dus de bovenstaande query wordt zonder fouten uitgevoerd.
De tabelexpressie moet echter wel geldig zijn. Beschouw bijvoorbeeld de volgende vraag:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Hoewel de buitenste query alleen een kolom uit de groeperingsset van de binnenste query projecteert, is de binnenquery niet geldig omdat deze kolommen probeert te retourneren die geen deel uitmaken van de groeperingsset en ook niet zijn opgenomen in een aggregatiefunctie. Deze query mislukt met de volgende fout:
Msg 8120, niveau 16, staat 1Kolom 'Sales.Customers.custid' is ongeldig in de selectielijst omdat deze niet is opgenomen in een aggregatiefunctie of de GROUP BY-clausule.
Laten we vervolgens de vraag over het matchen van indexen aanpakken. Als de buitenste query alleen een subset van de kolommen uit de afgeleide tabel projecteert, is SQL Server dan slim genoeg om indexovereenkomsten uit te voeren op basis van alleen de geretourneerde kolommen (en natuurlijk alle andere kolommen die anders een betekenisvolle rol spelen, zoals filteren, groeperen enzovoort)? Maar voordat we deze vraag aanpakken, kun je je afvragen waarom we ons er zelfs maar mee bezig houden. Waarom zou je de innerlijke query-retourkolommen hebben die de buitenste query niet nodig heeft?
Het antwoord is eenvoudig, om de code in te korten door de innerlijke query de beruchte SELECT * te laten gebruiken. We weten allemaal dat het gebruik van SELECT * een slechte gewoonte is, maar dat is vooral het geval wanneer het wordt gebruikt in de buitenste query. Wat als u een tabel met een bepaalde kop opvraagt en die kop later wordt gewijzigd? De applicatie kan bugs bevatten. Zelfs als je geen bugs krijgt, zou je uiteindelijk onnodig netwerkverkeer kunnen genereren door kolommen te retourneren die de applicatie niet echt nodig heeft. Bovendien maak je in zo'n geval minder optimaal gebruik van indexering, omdat je de kans verkleint dat dekkingsindexen worden gevonden die zijn gebaseerd op de echt benodigde kolommen.
Dat gezegd hebbende, voel ik me eigenlijk best op mijn gemak bij het gebruik van SELECT * in een tabeluitdrukking, wetende dat ik sowieso alleen de echt benodigde kolommen in de buitenste query ga projecteren. Vanuit een logisch oogpunt is dat redelijk veilig met enkele kleine kanttekeningen die ik binnenkort zal bespreken. Dat is zolang indexmatching in zo'n geval optimaal wordt gedaan, en het goede nieuws is dat dit ook zo is.
Om dit aan te tonen, veronderstel dat u de tabel Sales.Orders moet doorzoeken en de drie meest recente bestellingen voor elke klant moet retourneren. U bent van plan een afgeleide tabel met de naam D te definiëren op basis van een query die rijnummers berekent (resultaat kolom rownum) die zijn gepartitioneerd op custid en geordend op orderdatum DESC, orderid DESC. De buitenste zoekopdracht filtert van D (relationele beperking ) alleen de rijen waar rownum kleiner is dan of gelijk is aan 3, en project D op custid, orderdate, orderid en rownum. Nu heeft Sales.Orders meer kolommen dan degene die u moet projecteren, maar voor de beknoptheid wilt u dat de binnenquery SELECT * gebruikt, plus de berekening van het rijnummer. Dat is veilig en wordt optimaal afgehandeld in termen van indexmatching.
Gebruik de volgende code om de optimale dekkingsindex te maken om uw vraag te ondersteunen:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Dit is de query die de betreffende taak archiveert (we noemen het Query 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Let op de SELECT * van de inner query en de lijst met expliciete kolommen van de outer query.
Het plan voor deze query, zoals weergegeven door SentryOne Plan Explorer, wordt weergegeven in Afbeelding 1.
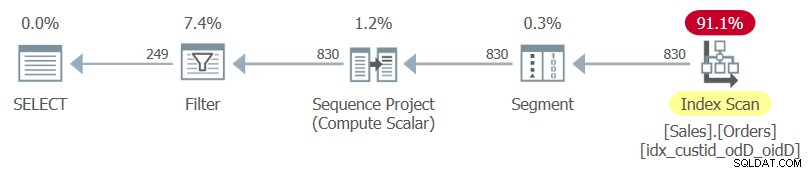 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
Merk op dat de enige index die in dit plan wordt gebruikt, de optimale dekkingsindex is die u zojuist hebt gemaakt.
Als u alleen de innerlijke query markeert en het uitvoeringsplan bekijkt, ziet u dat de geclusterde index van de tabel wordt gebruikt, gevolgd door een sorteerbewerking.
Dus dat is goed nieuws.
Wat betreft machtigingen, dat is een ander verhaal. In tegenstelling tot indexvergelijking, waarbij u de index niet nodig hebt om kolommen op te nemen waarnaar wordt verwezen door de innerlijke query's, zolang ze uiteindelijk niet nodig zijn, moet u machtigingen hebben voor alle kolommen waarnaar wordt verwezen.
Om dit te demonstreren, gebruikt u de volgende code om een gebruiker met de naam user1 aan te maken en enkele machtigingen toe te wijzen (SELECTEER machtigingen voor alle kolommen van Sales.Customers en alleen voor de drie kolommen van Sales.Orders die uiteindelijk relevant zijn in de bovenstaande query):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Voer de volgende code uit om gebruiker1 te imiteren:
EXECUTE AS USER = 'user1';
Probeer alle kolommen uit Sales.Orders te selecteren:
SELECT * FROM Sales.Orders;
Zoals verwacht krijg je de volgende fouten vanwege het ontbreken van rechten op sommige kolommen:
Msg 230, Level 14, State 1De SELECT-machtiging is geweigerd op de kolom 'empid' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230 , Level 14, State 1
De SELECT-machtiging is geweigerd op de kolom 'requireddate' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, staat 1
De SELECT-machtiging is geweigerd in de kolom 'verzenddatum' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Status 1
De SELECT-machtiging is geweigerd op de kolom 'shipperid' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-toestemming is geweigerd voor de kolom 'vracht' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Bericht 230, Level 14, State 1
De SELECT-machtiging is geweigerd voor de kolom 'shipname' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-machtiging is geweigerd voor de kolom 'shipaddress' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-machtiging is geweigerd op de kolom 'shipcity' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT toestemming is geweigerd voor de kolom 'shipregion' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-permissie was geweigerd op de kolom 'shippostalcode' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-toestemming is geweigerd op de kolom 'shipcountry' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Probeer de volgende query, projecteer en interactief met alleen kolommen waarvoor gebruiker1 rechten heeft:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Toch krijg je kolomtoestemmingsfouten vanwege het ontbreken van toestemmingen voor sommige van de kolommen waarnaar wordt verwezen door de innerlijke query via de SELECT *:
Msg 230, Level 14, State 1De SELECT-machtiging is geweigerd op de kolom 'empid' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230 , Level 14, State 1
De SELECT-machtiging is geweigerd op de kolom 'requireddate' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, staat 1
De SELECT-machtiging is geweigerd in de kolom 'verzenddatum' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Status 1
De SELECT-machtiging is geweigerd op de kolom 'shipperid' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-toestemming is geweigerd voor de kolom 'vracht' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Bericht 230, Level 14, State 1
De SELECT-machtiging is geweigerd voor de kolom 'shipname' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-machtiging is geweigerd voor de kolom 'shipaddress' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-machtiging is geweigerd op de kolom 'shipcity' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT toestemming is geweigerd voor de kolom 'shipregion' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-permissie was geweigerd op de kolom 'shippostalcode' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
De SELECT-toestemming is geweigerd op de kolom 'shipcountry' van het object 'Orders', database 'TSQLV5', schema 'Sales'.
Als het inderdaad een gewoonte is om in uw bedrijf gebruikersrechten toe te kennen aan alleen relevante kolommen waarmee ze moeten communiceren, zou het logisch zijn om een iets langere code te gebruiken en expliciet te zijn over de kolomlijst in zowel de innerlijke als de buitenste query's. zoals zo:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Deze keer wordt de query uitgevoerd zonder fouten.
Een andere variant die vereist dat de gebruiker alleen machtigingen heeft voor de relevante kolommen, is om expliciet te zijn over de kolomnamen in de SELECT-lijst van de inner query en SELECT * te gebruiken in de outer query, zoals:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Deze query wordt ook zonder fouten uitgevoerd. Ik zie deze versie echter als een versie die gevoelig is voor bugs voor het geval er later wijzigingen worden aangebracht in een innerlijk niveau van nesten. Zoals eerder vermeld, is het voor mij de beste praktijk om expliciet te zijn over de kolomlijst in de buitenste query. Dus zolang je je geen zorgen maakt over een gebrek aan toestemming voor sommige kolommen, voel ik me comfortabel met SELECT * in innerlijke query's, maar een expliciete kolomlijst in de buitenste query. Als het toepassen van specifieke kolommachtigingen gebruikelijk is in het bedrijf, is het het beste om gewoon expliciet te zijn over kolomnamen op alle nestniveaus. Let op, expliciet zijn over kolomnamen in alle nestingniveaus is eigenlijk verplicht als uw query wordt gebruikt in een schemagebonden object, aangezien schemabinding het gebruik van SELECT * overal in de query verbiedt.
Voer nu de volgende code uit om de index te verwijderen die u eerder op Sales.Orders hebt gemaakt:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Er is nog een geval met een soortgelijk dilemma met betrekking tot de legitimiteit van het gebruik van SELECT *; in de innerlijke query van het predikaat EXISTS.
Beschouw de volgende vraag (we noemen het vraag 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Het plan voor deze zoekopdracht wordt getoond in figuur 2.
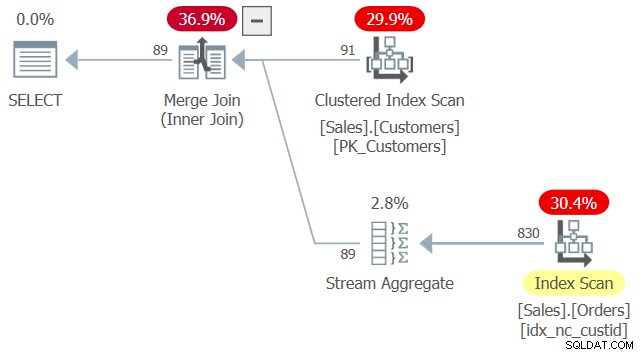 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
Bij het toepassen van indexmatching kwam de optimizer tot de conclusie dat de index idx_nc_custid een dekkende index op Sales.Orders is, aangezien deze de custid-kolom bevat - de enige echte relevante kolom in deze zoekopdracht. Dat is ondanks het feit dat deze index geen andere kolom bevat dan custid, en dat de inner query in het EXISTS predikaat SELECT * zegt. Tot dusver lijkt het gedrag op het gebruik van SELECT * in afgeleide tabellen.
Het verschil met deze query is dat deze zonder fouten wordt uitgevoerd, ondanks het feit dat gebruiker1 geen rechten heeft voor sommige kolommen van Sales.Orders. Er is een argument om te rechtvaardigen dat hier geen machtigingen voor alle kolommen nodig zijn. Het predikaat EXISTS hoeft immers alleen te controleren op het bestaan van overeenkomende rijen, dus de SELECT-lijst van de innerlijke query is echt zinloos. Het zou waarschijnlijk het beste zijn geweest als SQL in zo'n geval helemaal geen SELECT-lijst nodig had, maar dat schip is al gevaren. Het goede nieuws is dat de SELECT-lijst effectief wordt genegeerd, zowel in termen van indexovereenkomst als in termen van vereiste machtigingen.
Het lijkt er ook op dat er een ander verschil is tussen afgeleide tabellen en EXISTS bij gebruik van SELECT * in de inner query. Onthoud deze vraag van eerder in het artikel:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Als je het je herinnert, heeft deze code een fout gegenereerd omdat de innerlijke query ongeldig is.
Probeer dezelfde innerlijke vraag, alleen deze keer in het predikaat EXISTS (we noemen dit Statement 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Vreemd genoeg beschouwt SQL Server deze code als geldig en wordt deze met succes uitgevoerd. Het plan voor deze code wordt getoond in figuur 3.
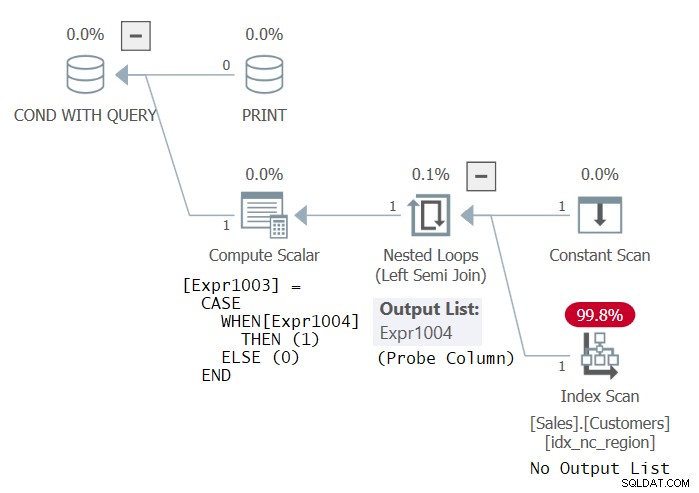 Figuur 3:Plan voor stelling 3
Figuur 3:Plan voor stelling 3
Dit plan is identiek aan het plan dat u zou krijgen als de innerlijke vraag gewoon SELECT * FROM Sales.Customers was (zonder de GROUP BY). Je controleert tenslotte op het bestaan van groepen, en als er rijen zijn, zijn er natuurlijk ook groepen. Hoe dan ook, ik denk dat het feit dat SQL Server deze query als geldig beschouwt, een fout is. De SQL-code moet zeker geldig zijn! Maar ik begrijp waarom sommigen zouden kunnen beweren dat de SELECT-lijst in de EXISTS-query zou moeten worden genegeerd. In ieder geval gebruikt het plan een gesondeerde linker semi-join, die geen kolommen hoeft te retourneren, maar gewoon een tabel doorzoekt om te controleren op het bestaan van rijen. De index op Klanten kan elke willekeurige index zijn.
Op dit punt kunt u de volgende code uitvoeren om te stoppen met het imiteren van gebruiker1 en om het te laten vallen:
REVERT; DROP USER IF EXISTS user1;
Terug naar het feit dat ik het een handige oefening vind om SELECT * te gebruiken in innerlijke niveaus van nesten, hoe meer niveaus je hebt, hoe meer deze oefening je code verkort en vereenvoudigt. Hier is een voorbeeld met twee nestingniveaus:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Er zijn gevallen waarin deze praktijk niet kan worden gebruikt. Als de binnenquery bijvoorbeeld tabellen met gemeenschappelijke kolomnamen samenvoegt, zoals in het volgende voorbeeld:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Zowel Sales.Customers als Sales.Orders hebben een kolom met de naam custid. U gebruikt een tabelexpressie die is gebaseerd op een join tussen de twee tabellen om de afgeleide tabel D te definiëren. Onthoud dat de kop van een tabel een set kolommen is en dat u als set geen dubbele kolomnamen kunt hebben. Daarom mislukt deze query met de volgende fout:
Msg 8156, Level 16, State 1De kolom 'custid' is meerdere keren opgegeven voor 'D'.
Hier moet u expliciet zijn over kolomnamen in de innerlijke query en ervoor zorgen dat u ofwel de custid retourneert van slechts één van de tabellen, of unieke kolomnamen toewijst aan de resultaatkolommen voor het geval u beide wilt retourneren. Vaker zou je de vorige benadering gebruiken, zoals:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Nogmaals, je zou expliciet kunnen zijn met de kolomnamen in de inner query en SELECT * gebruiken in outer query, zoals:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Maar zoals ik eerder al zei, beschouw ik het als een slechte gewoonte om niet expliciet te zijn over kolomnamen in de buitenste zoekopdracht.
Meerdere verwijzingen naar kolomaliassen
Laten we doorgaan naar het volgende item:meerdere verwijzingen naar afgeleide tabelkolommen. Als de afgeleide tabel een resultaatkolom heeft die is gebaseerd op een niet-deterministische berekening, en de buitenste query heeft meerdere verwijzingen naar die kolom, wordt de berekening dan slechts één keer of afzonderlijk voor elke verwijzing geëvalueerd?
Laten we beginnen met het feit dat meerdere verwijzingen naar dezelfde niet-deterministische functie in een query onafhankelijk moeten worden geëvalueerd. Beschouw de volgende vraag als voorbeeld:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Deze code genereert de volgende uitvoer met twee verschillende GUID's:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Omgekeerd, als u een afgeleide tabel hebt met een kolom die is gebaseerd op een niet-deterministische berekening, en de buitenste query heeft meerdere verwijzingen naar die kolom, wordt verondersteld dat de berekening slechts één keer wordt geëvalueerd. Beschouw de volgende vraag (we noemen deze vraag 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Het plan voor deze zoekopdracht wordt getoond in figuur 4.
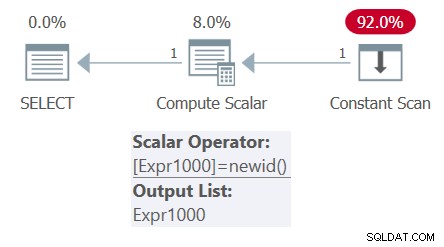 Figuur 4:Plan voor Query 4
Figuur 4:Plan voor Query 4
Merk op dat er slechts één aanroep van de NEWID-functie in het plan is. Dienovereenkomstig toont de uitvoer twee keer dezelfde GUID:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
De bovenstaande twee zoekopdrachten zijn dus niet logisch equivalent, en er zijn gevallen waarin inlining/substitutie niet plaatsvindt.
Bij sommige niet-deterministische functies is het wat lastiger om aan te tonen dat meerdere aanroepen in een query afzonderlijk worden afgehandeld. Neem als voorbeeld de functie SYSDATETIME. Het heeft een precisie van 100 nanoseconden. Wat is de kans dat een zoekopdracht zoals de volgende twee verschillende waarden laat zien?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Als je je verveelt, kun je herhaaldelijk op F5 drukken totdat het gebeurt. Als je belangrijkere dingen met je tijd te doen hebt, kun je er de voorkeur aan geven een lus te lopen, zoals:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Toen ik bijvoorbeeld deze code uitvoerde, kreeg ik 1971.
Als u er zeker van wilt zijn dat de niet-deterministische functie slechts één keer wordt aangeroepen en op dezelfde waarde vertrouwt in meerdere queryverwijzingen, zorg er dan voor dat u een tabelexpressie definieert met een kolom op basis van de functieaanroep en dat u meerdere verwijzingen naar die kolom hebt van de buitenste vraag, zoals zo (we noemen deze vraag 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
Het plan voor deze zoekopdracht wordt getoond in figuur 5.
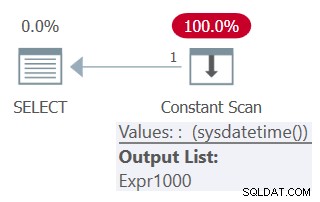 Figure 5:Plan for Query 5
Figure 5:Plan for Query 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Samenvatting
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.