Dit artikel is het vierde deel in een serie over tabeluitdrukkingen. In deel 1 en deel 2 heb ik de conceptuele behandeling van afgeleide tabellen behandeld. In deel 3 ben ik begonnen met het behandelen van optimalisatieoverwegingen van afgeleide tabellen. Deze maand behandel ik verdere aspecten van optimalisatie van afgeleide tabellen; in het bijzonder richt ik me op vervanging/unnesting van afgeleide tabellen.
In mijn voorbeelden gebruik ik voorbeelddatabases genaamd TSQLV5 en PerformanceV5. U vindt het script dat TSQLV5 maakt en vult hier, en het ER-diagram hier. Je kunt het script dat PerformanceV5 maakt en vult hier vinden.
Unnesting/substitutie
Unnesting/substitutie van tabelexpressies is een proces waarbij een query wordt uitgevoerd waarbij tabelexpressies worden genest, en alsof deze wordt vervangen door een query waarbij de geneste logica wordt geëlimineerd. Ik moet benadrukken dat er in de praktijk geen echt proces is waarbij SQL Server de oorspronkelijke queryreeks met de geneste logica naar een nieuwe queryreeks converteert zonder de nesting. Wat er feitelijk gebeurt, is dat het parseerproces van de query een initiële boomstructuur van logische operatoren produceert die nauw aansluiten bij de oorspronkelijke query. Vervolgens past SQL Server transformaties toe op deze querystructuur, waardoor enkele van de onnodige stappen worden geëlimineerd, meerdere stappen worden samengevouwen in minder stappen en operators worden verplaatst. In zijn transformaties kan SQL Server, zolang aan bepaalde voorwaarden wordt voldaan, dingen verschuiven over wat oorspronkelijk de grenzen van tabeluitdrukkingen waren, soms effectief alsof de geneste eenheden worden geëlimineerd. Dit alles in een poging om een optimaal plan te vinden.
In dit artikel behandel ik zowel de gevallen waarin zo'n ontnesting plaatsvindt, als de ontnestremmers. Dat wil zeggen, wanneer u bepaalde query-elementen gebruikt, wordt voorkomen dat SQL Server logische operators in de querystructuur kan verplaatsen, waardoor het wordt gedwongen de operators te verwerken op basis van de grenzen van de tabelexpressies die in de oorspronkelijke query zijn gebruikt.
Ik zal beginnen met het demonstreren van een eenvoudig voorbeeld waarbij afgeleide tabellen worden verwijderd. Ik zal ook een voorbeeld demonstreren voor een unnesting-remmer. Ik zal dan praten over ongebruikelijke gevallen waarin het verwijderen van nesten ongewenst kan zijn, resulterend in fouten of prestatievermindering, en demonstreren hoe het verwijderen van nesten in die gevallen kan worden voorkomen door het gebruik van een onthechtingsremmer.
De volgende query (we noemen het Query 1) gebruikt meerdere geneste lagen van afgeleide tabellen, waarbij elk van de tabeluitdrukkingen elementaire filterlogica toepast op basis van constanten:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Zoals u kunt zien, filtert elk van de tabeluitdrukkingen een reeks besteldatums die met een andere datum beginnen. SQL Server maakt deze meerlagige querylogica ongedaan, waardoor het vervolgens de vier filterpredikaten kan samenvoegen tot één enkele die de kruising van alle vier de predikaten vertegenwoordigt.
Bekijk het plan voor Query 1 getoond in figuur 1.
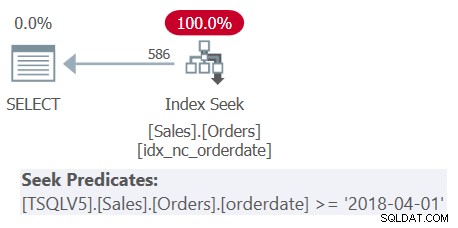 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
Merk op dat alle vier de filterpredikaten zijn samengevoegd tot een enkel predikaat dat het snijpunt van de vier vertegenwoordigt. Het plan past een zoekactie toe in de index idx_nc_orderdate op basis van het enkele samengevoegde predikaat als het zoekpredikaat. Deze index is gedefinieerd op orderdatum (expliciet), orderid (impliciet vanwege de aanwezigheid van een geclusterde index op orderid) als de indexsleutels.
Merk ook op dat hoewel alle tabeluitdrukkingen SELECT * gebruiken en alleen de buitenste query de twee kolommen van belang projecteert:orderdate en orderid, de bovengenoemde index als dekkend wordt beschouwd. Zoals ik in deel 3 heb uitgelegd, negeert SQL Server voor optimalisatiedoeleinden, zoals indexselectie, de kolommen uit de tabelexpressies die uiteindelijk niet relevant zijn. Onthoud echter dat u wel rechten moet hebben om die kolommen te doorzoeken.
Zoals vermeld, zal SQL Server proberen tabelexpressies te unnesten, maar zal het unnesting vermijden als het in een unnesting-remmer struikelt. Met een bepaalde uitzondering die ik later zal beschrijven, zal het gebruik van TOP of OFFSET FETCH unnesting verhinderen. De reden hiervoor is dat een poging om een tabelexpressie te verwijderen met TOP of OFFSET FETCH kan resulteren in een wijziging in de betekenis van de oorspronkelijke query.
Beschouw als voorbeeld de volgende query (we noemen het Query 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Het invoeraantal rijen voor het TOP-filter is een BIGINT-getypte waarde. In dit voorbeeld gebruik ik de maximale BIGINT-waarde (2 ^ 63 - 1, bereken in T-SQL met SELECT POWER (2., 63) - 1). Ook al weten jij en ik dat onze Orders-tabel nooit zoveel rijen zal hebben en daarom het TOP-filter echt zinloos is, moet SQL Server rekening houden met de theoretische mogelijkheid dat het filter zinvol is. Daarom verwijdert SQL Server de tabelexpressies in deze query niet. Het plan voor Query 2 wordt getoond in figuur 2.
 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
De unnesting-remmers verhinderden dat SQL Server de filterpredikaten kon samenvoegen, waardoor de vorm van het plan meer leek op de conceptuele query. Het is echter interessant om te zien dat SQL Server nog steeds de kolommen negeerde die uiteindelijk niet relevant waren voor de buitenste query, en daarom de dekkingsindex kon gebruiken op orderdatum, orderid.
Laten we, om te illustreren waarom TOP en OFFSET-FETCH remmers van het nesten zijn, een eenvoudige predikaat-pushdown-optimalisatietechniek nemen. Predikaat pushdown betekent dat de optimizer een filterpredikaat naar een eerder punt duwt in vergelijking met het oorspronkelijke punt dat het verschijnt in de logische queryverwerking. Stel dat u een query hebt met zowel een inner join als een WHERE-filter op basis van een kolom vanaf een van de zijden van de join. In termen van logische queryverwerking, wordt verondersteld dat het WHERE-filter wordt geëvalueerd na de join. Maar vaak duwt de optimizer het filterpredikaat naar een stap voorafgaand aan de join, omdat de join hierdoor minder rijen heeft om mee te werken, wat doorgaans resulteert in een meer optimaal plan. Onthoud echter dat dergelijke transformaties alleen zijn toegestaan in gevallen waarin de betekenis van de oorspronkelijke zoekopdracht behouden blijft, in die zin dat u gegarandeerd de juiste resultatenset krijgt.
Overweeg de volgende code, die een buitenste query heeft met een WHERE-filter tegen een afgeleide tabel, die op zijn beurt is gebaseerd op een tabelexpressie met een TOP-filter:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Deze query is natuurlijk niet-deterministisch vanwege het ontbreken van een ORDER BY-clausule in de tabelexpressie. Toen ik het uitvoerde, had SQL Server toegang tot de eerste drie rijen met besteldatums eerder dan 2018, dus ik kreeg een lege set als uitvoer:
orderid orderdate ----------- ---------- (0 rows affected)
Zoals vermeld, verhinderde het gebruik van TOP in de tabeluitdrukking het ongedaan maken/vervangen van de tabeluitdrukking hier. Als SQL Server de tabelexpressie had verwijderd, zou het vervangingsproces hebben geresulteerd in het equivalent van de volgende query:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Deze zoekopdracht is ook niet-deterministisch vanwege het ontbreken van de ORDER BY-clausule, maar heeft duidelijk een andere betekenis dan de oorspronkelijke zoekopdracht. Als de tabel Sales.Orders ten minste drie bestellingen heeft die in 2018 of later zijn geplaatst - en dat is het geval - levert deze query noodzakelijkerwijs drie rijen op, in tegenstelling tot de oorspronkelijke query. Dit is het resultaat dat ik kreeg toen ik deze zoekopdracht uitvoerde:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
Als de niet-deterministische aard van de bovenstaande twee zoekopdrachten u in de war brengt, volgt hier een voorbeeld met een deterministische zoekopdracht:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; De tabelexpressie filtert de drie orders met de laagste order-ID's. De buitenste zoekopdracht filtert vervolgens van die drie bestellingen alleen de bestellingen die op of na 8 juli 2017 zijn geplaatst. Het blijkt dat er maar één in aanmerking komende bestelling is. Deze query genereert de volgende uitvoer:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Stel dat SQL Server de tabelexpressie in de oorspronkelijke query heeft verwijderd, waarbij het vervangingsproces resulteert in het volgende query-equivalent:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
De betekenis van deze zoekopdracht is anders dan de oorspronkelijke zoekopdracht. Deze zoekopdracht filtert eerst de bestellingen die op of na 8 juli 2017 zijn geplaatst en filtert vervolgens de top drie van de bestellingen met de laagste bestellings-ID's. Deze query genereert de volgende uitvoer:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
Om te voorkomen dat de betekenis van de oorspronkelijke query wordt gewijzigd, past SQL Server hier geen unnesting/substitutie toe.
De laatste twee voorbeelden hadden betrekking op een eenvoudige mix van WHERE- en TOP-filtering, maar er kunnen aanvullende conflicterende elementen zijn als gevolg van het ongedaan maken van nesten. Wat als u bijvoorbeeld verschillende bestelspecificaties heeft in de tabelexpressie en de buitenste query, zoals in het volgende voorbeeld:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; U realiseert zich dat als SQL Server de tabelexpressie zou verwijderen en de twee verschillende bestelspecificaties in één zou samenvouwen, de resulterende query een andere betekenis zou hebben gehad dan de oorspronkelijke query. Het zou ofwel de verkeerde rijen hebben gefilterd of de resultaatrijen in de verkeerde presentatievolgorde hebben gepresenteerd. Kortom, u realiseert zich waarom het veilig is voor SQL Server om te voorkomen dat tabeluitdrukkingen worden verwijderd/vervangen die zijn gebaseerd op TOP- en OFFSET-FETCH-query's.
Ik noemde eerder dat er een uitzondering is op de regel dat het gebruik van TOP en OFFSET-FETCH unnesting voorkomt. Dat is wanneer u TOP (100) PERCENT gebruikt in een geneste tabelexpressie, met of zonder een ORDER BY-component. SQL Server realiseert zich dat er niet echt wordt gefilterd en optimaliseert de optie uit. Hier is een voorbeeld om dit aan te tonen:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Het TOP-filter wordt genegeerd, het nest wordt ongedaan gemaakt en u krijgt hetzelfde plan als eerder getoond voor Query 1 in Afbeelding 1.
Bij gebruik van OFFSET 0 ROWS zonder FETCH-clausule in een geneste tabelexpressie, vindt er ook geen echte filtering plaats. Dus theoretisch had SQL Server deze optie ook kunnen optimaliseren en unnesting mogelijk hebben gemaakt, maar op de datum van schrijven is dit niet het geval. Hier is een voorbeeld om dit aan te tonen:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; U krijgt hetzelfde plan als het eerder getoonde plan voor Query 2 in Afbeelding 2, waaruit blijkt dat er geen unnesting heeft plaatsgevonden.
Eerder heb ik uitgelegd dat het proces voor het verwijderen van nesten/substitutie niet echt een nieuwe queryreeks genereert die vervolgens wordt geoptimaliseerd, maar eerder te maken heeft met transformaties die SQL Server toepast op de boom van logische operators. Er is een verschil tussen de manier waarop SQL Server een query optimaliseert met geneste tabelexpressies en een daadwerkelijke logisch equivalente query zonder de nesting. Het gebruik van tabelexpressies zoals afgeleide tabellen, evenals subquery's verhindert eenvoudige parametrering. Recall Query 1 eerder in het artikel getoond:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Omdat de query gebruikmaakt van afgeleide tabellen, vindt er geen eenvoudige parametrering plaats. Dat wil zeggen, SQL Server vervangt de constanten niet door parameters en optimaliseert vervolgens de query, maar optimaliseert eerder de query met de constanten. Met predikaten op basis van constanten kan SQL Server de kruisende perioden samenvoegen, wat in ons geval resulteerde in één predikaat in het plan, zoals eerder getoond in figuur 1.
Overweeg vervolgens de volgende query (we noemen het Query 3), die een logisch equivalent is van Query 1, maar waarbij u zelf de unnesting toepast:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
Het plan voor deze zoekopdracht wordt getoond in figuur 3.
 Figuur 3:Plan voor Query 3
Figuur 3:Plan voor Query 3
Dit plan wordt als veilig beschouwd voor eenvoudige parametrering, dus de constanten worden vervangen door parameters en bijgevolg worden de predikaten niet samengevoegd. De motivatie voor parametrering is natuurlijk het vergroten van de kans op hergebruik van plannen bij het uitvoeren van vergelijkbare query's die alleen verschillen in de constanten die ze gebruiken.
Zoals vermeld, verhinderde het gebruik van afgeleide tabellen in Query 1 eenvoudige parametrering. Evenzo zou het gebruik van subquery's eenvoudige parametrering voorkomen. Hier is bijvoorbeeld onze vorige Query 3 met een betekenisloos predikaat op basis van een subquery die is toegevoegd aan de WHERE-component:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Deze keer vindt er geen eenvoudige parametrering plaats, waardoor SQL Server de door de predikaten weergegeven kruisende perioden kan samenvoegen met de constanten, wat resulteert in hetzelfde plan als eerder in figuur 1.
Als u query's hebt met tabeluitdrukkingen die constanten gebruiken, en het is belangrijk voor u dat SQL Server de code parametriseert en om welke reden dan ook niet zelf parametriseert, onthoud dan dat u de mogelijkheid heeft om geforceerde parametrering te gebruiken met een planhandleiding. Als voorbeeld maakt de volgende code zo'n plangids voor Query 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Voer Query 3 opnieuw uit nadat u de plangids hebt gemaakt:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; U krijgt hetzelfde plan als eerder getoond in figuur 3 met de geparametriseerde predikaten.
Als je klaar bent, voer je de volgende code uit om de plangids te laten vallen:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Ontstekken voorkomen
Houd er rekening mee dat SQL Server tabelexpressies geneest om optimalisatieredenen. Het doel is om de kans op het vinden van een plan met lagere kosten te vergroten in vergelijking met zonder unnesting. Dat geldt voor de meeste transformatieregels die door de optimizer worden toegepast. Er kunnen zich echter enkele ongebruikelijke gevallen voordoen waarin u onthechting wilt voorkomen. Dit kan zijn om fouten te voorkomen (ja in sommige ongebruikelijke gevallen kan het verwijderen van nesten tot fouten leiden) of om prestatieredenen om een bepaalde planvorm te forceren, vergelijkbaar met het gebruik van andere prestatiehints. Onthoud dat je een eenvoudige manier hebt om het verwijderen van nesten te voorkomen door TOP te gebruiken met een zeer groot aantal.
Voorbeeld om fouten te vermijden
Ik zal beginnen met een geval waarin het verwijderen van tabeluitdrukkingen tot fouten kan leiden.
Beschouw de volgende vraag (we noemen het vraag 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Dit voorbeeld is een beetje gekunsteld in die zin dat het gemakkelijk is om het tweede filterpredikaat te herschrijven, zodat het nooit in een fout resulteert (korting <0,1), maar het is een handig voorbeeld voor mij om mijn punt te illustreren. Kortingen zijn niet-negatief. Dus zelfs als er orderregels zijn met een korting van nul, moet de query die eruit filteren (het eerste filterpredikaat zegt dat de korting groter moet zijn dan de minimumkorting in de tabel). Er is echter geen garantie dat SQL Server de predikaten in schriftelijke volgorde zal evalueren, dus u kunt niet rekenen op kortsluiting.
Bekijk het plan voor Query 4 zoals weergegeven in figuur 4.
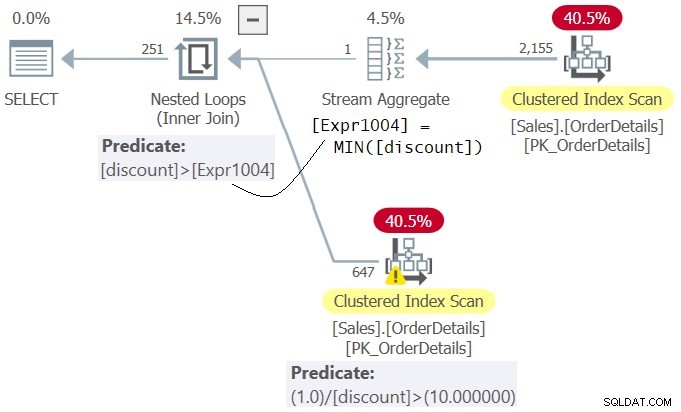 Figuur 4:Plan voor Query 4
Figuur 4:Plan voor Query 4
Merk op dat in het plan het predikaat 1.0 / korting> 10.0 (tweede in WHERE-clausule) wordt geëvalueerd vóór het predikaat korting>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Misschien denkt u dat u de fout kunt vermijden door een afgeleide tabel te gebruiken, waarbij u de filtertaken scheidt in een binnenste en een buitenste, zoals:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; SQL Server past echter het nesten van de afgeleide tabel toe, wat resulteert in hetzelfde plan dat eerder in figuur 4 is getoond, en bijgevolg mislukt deze code ook met een fout door delen door nul:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Een eenvoudige oplossing hier is om een ontnestingsremmer te introduceren, zoals (we noemen deze oplossing Query 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Het plan voor Query 5 wordt getoond in figuur 5.
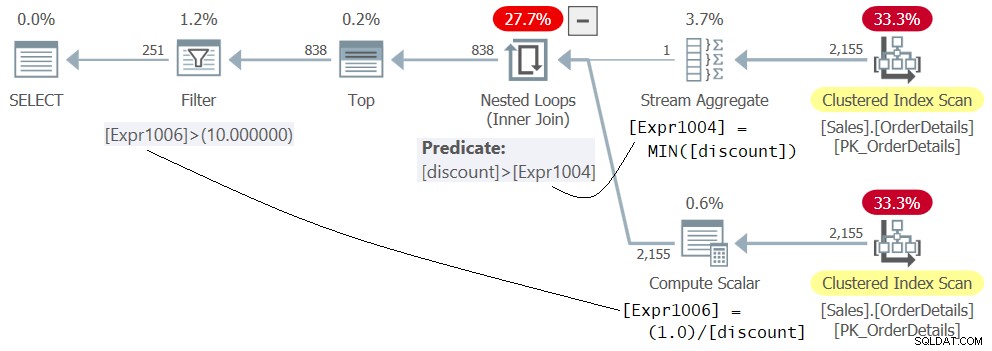 Figuur 5:Plan voor Query 5
Figuur 5:Plan voor Query 5
Wees niet in de war door het feit dat de uitdrukking 1.0 / korting in het binnenste deel van de operator Nested Loops verschijnt, alsof deze eerst wordt geëvalueerd. Dit is slechts de definitie van het lid Expr1006. De feitelijke evaluatie van het predikaat Expr1006> 10.0 wordt door de filteroperator toegepast als de laatste stap in het plan nadat de rijen met de minimale korting eerder waren uitgefilterd door de geneste lussen-operator. Deze oplossing werkt zonder fouten.
Voorbeeld om prestatieredenen
Ik ga verder met een geval waarin het verwijderen van tabeluitdrukkingen de prestaties kan schaden.
Begin met het uitvoeren van de volgende code om de context naar de PerformanceV5-database te schakelen en STATISTICS IO en TIME in te schakelen:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Beschouw de volgende vraag (we noemen het vraag 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
De optimizer identificeert een ondersteunende dekkingsindex met verzendperiode en besteldatum als leidende sleutels. Het maakt dus een plan met een geordende scan van de index gevolgd door een op volgorde gebaseerde Stream Aggregate-operator, zoals weergegeven in het plan voor Query 6 in Afbeelding 6.
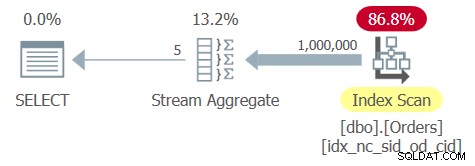 Figuur 6:Plan voor Query 6
Figuur 6:Plan voor Query 6
De tabel Orders heeft 1.000.000 rijen en de verzendperiode van de groeperingskolom is erg compact:er zijn slechts 5 verschillende verzender-ID's, wat resulteert in een dichtheid van 20% (gemiddeld percentage per afzonderlijke waarde). Het toepassen van een volledige scan van het indexblad omvat het lezen van een paar duizend pagina's, wat resulteert in een looptijd van ongeveer een derde van een seconde op mijn systeem. Dit zijn de prestatiestatistieken die ik heb gekregen voor het uitvoeren van deze query:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
De indexboom is momenteel drie niveaus diep.
Laten we het aantal bestellingen schalen met een factor 1.000 tot 1.000.000.000, maar nog steeds met slechts 5 verschillende verzenders. Het aantal pagina's in het indexblad zou groeien met een factor 1.000, en de indexboom zou waarschijnlijk resulteren in een extra niveau (vier niveaus diep). Dit plan heeft een lineaire schaal. Je zou eindigen met bijna 4.000.000 logische uitlezingen en een looptijd van een paar minuten.
Wanneer u een MIN- of MAX-aggregaat moet berekenen tegen een grote tabel, met een zeer hoge dichtheid in de groeperingskolom (belangrijk!), en een ondersteunende B-tree-index die is ingetoetst op de groeperingskolom en de aggregatiekolom, is er een veel optimalere planvorm dan die in Afbeelding 6. Stelt u zich een planvorm voor die de kleine set verzender-ID's scant van een index op de Verzenders-tabel, en in een lus voor elke verzender een zoekopdracht toepast tegen de ondersteunende index op Orders om het totaal te verkrijgen. Met 1.000.000 rijen in de tabel zouden 5 zoekopdrachten 15 reads inhouden. Met 1.000.000.000 rijen zouden 5 zoekopdrachten 20 reads omvatten. Met een biljoen rijen, 25 leest in totaal. Duidelijk een veel optimaler plan. U kunt een dergelijk plan daadwerkelijk bereiken door de tabel Verzenders op te vragen en het aggregaat te verkrijgen met behulp van een scalaire geaggregeerde subquery tegen Orders, zoals (we noemen deze oplossing Query 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
Het plan voor deze query wordt getoond in figuur 7.
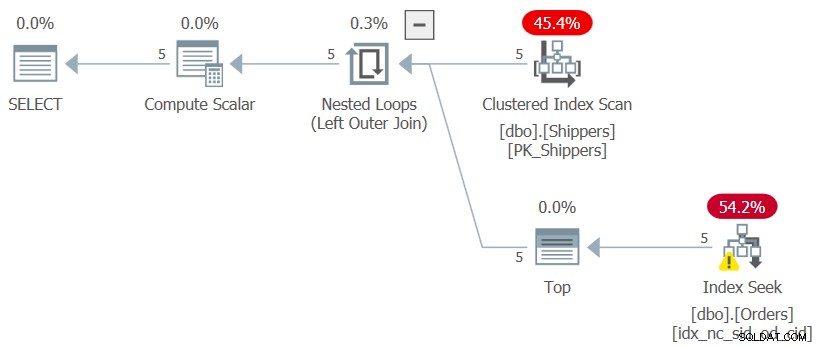 Figuur 7:Plan voor Query 7
Figuur 7:Plan voor Query 7
De gewenste planvorm is bereikt en de prestatiecijfers voor het uitvoeren van deze query zijn zoals verwacht te verwaarlozen:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Zolang de groeperingskolom erg compact is, wordt de grootte van de tabel Orders vrijwel onbeduidend.
Maar wacht even voordat je gaat vieren. Er is een vereiste om alleen de verzenders te behouden waarvan de maximale gerelateerde orderdatum in de Orders-tabel op of na 2018 is. Klinkt als een eenvoudige toevoeging. Definieer een afgeleide tabel op basis van Query 7 en pas het filter toe in de buitenste query, zoals zo (we noemen deze oplossing Query 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Helaas verwijdert SQL Server de afgeleide tabelquery, evenals de subquery, en converteert de aggregatielogica naar het equivalent van de gegroepeerde querylogica, met shipperid als de groeperingskolom. En de manier waarop SQL Server een gegroepeerde query weet te optimaliseren, is gebaseerd op een enkele doorgang over de invoergegevens, wat resulteert in een plan dat erg lijkt op het plan dat eerder in figuur 6 is getoond, alleen met het extra filter. Het plan voor Query 8 wordt getoond in figuur 8.
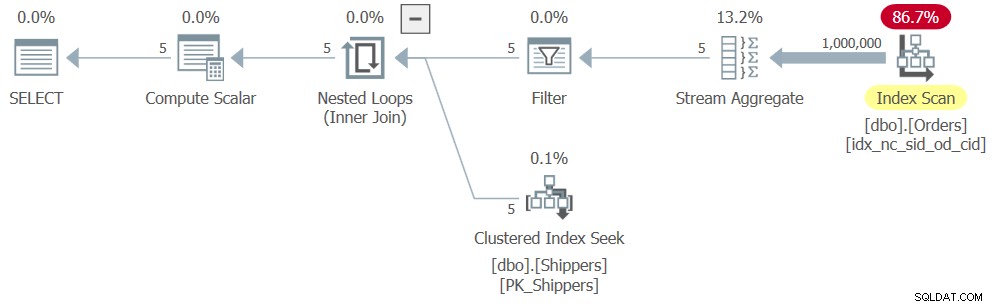 Figuur 8:Plan voor Query 8
Figuur 8:Plan voor Query 8
Bijgevolg is de schaalverdeling lineair en zijn de prestatiecijfers vergelijkbaar met die voor Query 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
De oplossing is het introduceren van een ontnestingsremmer. Dit kan worden gedaan door een TOP-filter toe te voegen aan de tabeluitdrukking waarop de afgeleide tabel is gebaseerd, zoals (we noemen deze oplossing Query 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Het plan voor deze zoekopdracht wordt getoond in figuur 9 en heeft de gewenste planvorm met de zoekopdrachten:
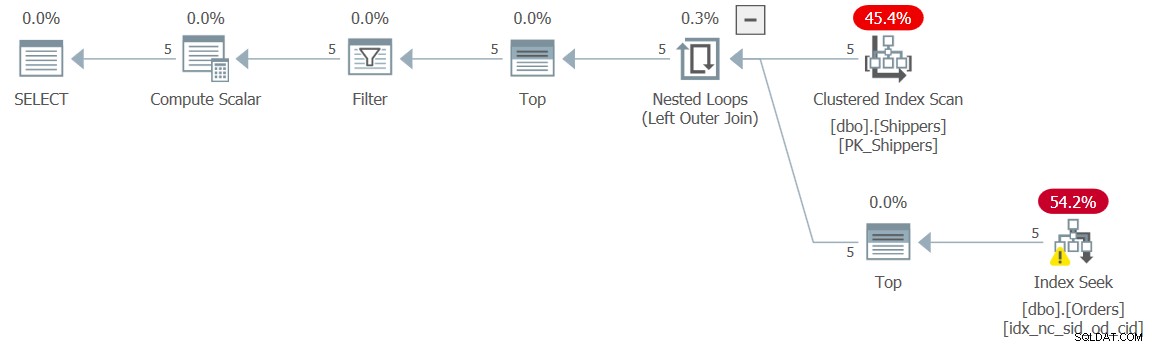 Figuur 9:Plan voor Query 9
Figuur 9:Plan voor Query 9
De prestatiecijfers voor deze uitvoering zijn dan natuurlijk te verwaarlozen:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Nog een andere optie is om te voorkomen dat de subquery ongedaan wordt gemaakt, door het MAX-aggregaat te vervangen door een equivalent TOP (1)-filter, zoals (we noemen deze oplossing Query 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Het plan voor deze zoekopdracht wordt weergegeven in figuur 10 en heeft opnieuw de gewenste vorm met de zoekopdrachten.
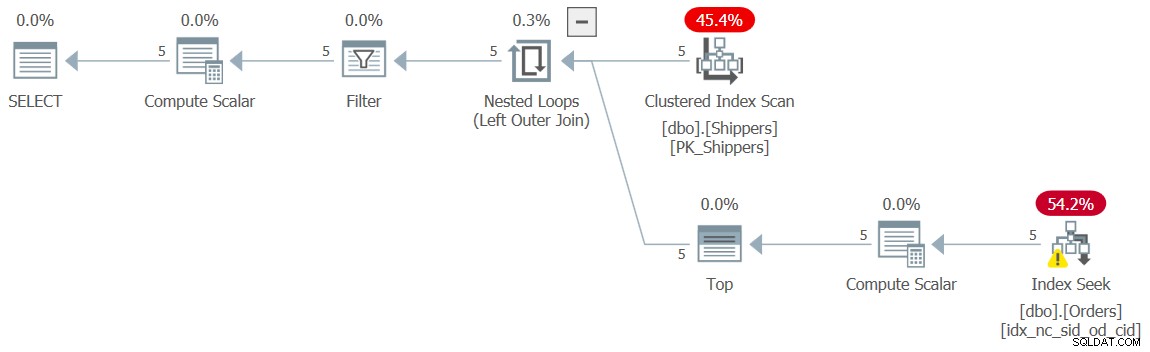 Figuur 10:Plan voor Query 10
Figuur 10:Plan voor Query 10
Ik heb de bekende verwaarloosbare prestatiecijfers voor deze uitvoering:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Als u klaar bent, voert u de volgende code uit om te stoppen met het rapporteren van prestatiestatistieken:
SET STATISTICS IO, TIME OFF;
Samenvatting
In dit artikel vervolg ik de discussie die ik vorige maand begon over optimalisatie van afgeleide tabellen. Deze maand heb ik me gefocust op het unnesten van afgeleide tabellen. Ik legde uit dat het verwijderen van nesten doorgaans resulteert in een meer optimaal plan dan zonder het verwijderen van nesten, maar behandelde ook voorbeelden waar het ongewenst is. Ik liet een voorbeeld zien waarbij het verwijderen van de nesten tot een fout leidde, evenals een voorbeeld dat tot prestatievermindering leidde. Ik heb laten zien hoe je onthechting kunt voorkomen door een ontknopingsremmer zoals TOP toe te passen.
Volgende maand ga ik verder met het verkennen van benoemde tabeluitdrukkingen, waarbij de focus verschuift naar CTE's.