Dit artikel is het vijfde deel in een serie over tabeluitdrukkingen. In deel 1 heb ik de achtergrond gegeven voor tabeluitdrukkingen. In deel 2, deel 3 en deel 4 heb ik zowel de logische als de optimalisatieaspecten van afgeleide tabellen behandeld. Deze maand begin ik met het behandelen van veelvoorkomende tabeluitdrukkingen (CTE's). Net als bij afgeleide tabellen, zal ik eerst de logische behandeling van CTE's behandelen en in de toekomst zal ik ingaan op optimalisatieoverwegingen.
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. Je kunt het script dat het maakt en vult hier vinden, en het ER-diagram hier.
CTE's
Laten we beginnen met de term algemene tabeluitdrukking . Noch deze term, noch het acroniem CTE, komen voor in de ISO/IEC SQL-standaardspecificaties. Het kan dus zijn dat de term zijn oorsprong vindt in een van de databaseproducten en later is overgenomen door enkele van de andere databaseleveranciers. U vindt het in de documentatie van Microsoft SQL Server en Azure SQL Database. T-SQL ondersteunt het vanaf SQL Server 2005. De standaard gebruikt de term query-expressie om een expressie weer te geven die een of meer CTE's definieert, inclusief de buitenste query. Het gebruikt de term met lijstelement om te vertegenwoordigen wat T-SQL een CTE noemt. Ik zal binnenkort de syntaxis voor een query-expressie leveren.
Afgezien van de bron van de term, algemene tabeluitdrukking , of CTE , is de veelgebruikte term door T-SQL-beoefenaars voor de structuur waarop dit artikel zich richt. Laten we dus eerst kijken of het een geschikte term is. We hebben al geconcludeerd dat de term tabeluitdrukking is geschikt voor een expressie die conceptueel een tabel retourneert. Afgeleide tabellen, CTE's, views en inline tabelwaardefuncties zijn allemaal typen benoemde tabeluitdrukkingen die T-SQL ondersteunt. Dus de tabeluitdrukking onderdeel van algemene tabeluitdrukking lijkt me zeker passend. Wat betreft de gewone Als onderdeel van de term heeft het waarschijnlijk te maken met een van de ontwerpvoordelen van CTE's ten opzichte van afgeleide tabellen. Onthoud dat u de afgeleide tabelnaam (of beter gezegd de naam van de bereikvariabele) niet meer dan één keer in de buitenste query kunt hergebruiken. Omgekeerd kan de CTE-naam meerdere keren worden gebruikt in de buitenste query. Met andere woorden, de CTE-naam is gebruikelijk naar de buitenste vraag. Natuurlijk zal ik dit ontwerpaspect in dit artikel demonstreren.
CTE's bieden vergelijkbare voordelen als afgeleide tabellen, waaronder het mogelijk maken van de ontwikkeling van modulaire oplossingen, het hergebruiken van kolomaliassen, indirecte interactie met vensterfuncties in clausules die dit normaal niet toestaan, ondersteuning van wijzigingen die indirect afhankelijk zijn van TOP of OFFSET FETCH met orderspecificatie, en anderen. Maar er zijn bepaalde ontwerpvoordelen in vergelijking met afgeleide tabellen, die ik in detail zal bespreken nadat ik de syntaxis voor de structuur heb verstrekt.
Syntaxis
Dit is de syntaxis van de standaard voor een query-expressie:
7.17
Functie
Specificeer een tafel.
Formaat
[
[
AS
|
[
|
[
|
[
|
[
OVEREENKOMSTIG [ DOOR
FETCH { FIRST | VOLGENDE } [
7.18
Functie
Specificeer het genereren van informatie over volgorde en cyclusdetectie in het resultaat van recursieve query-expressies.
Formaat
ZOEKEN
DIEPTE EERST DOOR
CYCLE
STANDAARD
7.3
Functie
Specificeer een set
De standaardterm vraaguitdrukking staat voor een uitdrukking met een WITH-clausule, een met lijst , die is gemaakt van een of meer met lijstelementen en een buitenste query. T-SQL verwijst naar de standaard met lijstelement als CTE.
T-SQL ondersteunt niet alle standaard syntaxiselementen. Het ondersteunt bijvoorbeeld niet enkele van de meer geavanceerde recursieve query-elementen waarmee u de zoekrichting kunt bepalen en cycli in een grafiekstructuur kunt afhandelen. Recursieve zoekopdrachten staan centraal in het artikel van volgende maand.
Hier is de T-SQL-syntaxis voor een vereenvoudigde zoekopdracht tegen een CTE:
Hier is een voorbeeld van een eenvoudige zoekopdracht tegen een CTE die Amerikaanse klanten vertegenwoordigt:
U vindt dezelfde drie delen in een statement tegen een CTE als bij een statement tegen een afgeleide tabel:
Wat anders is aan het ontwerp van CTE's in vergelijking met afgeleide tabellen, is waar in de code deze drie elementen zich bevinden. Bij afgeleide tabellen wordt de inner query genest in de FROM-component van de outer query en wordt de naam van de tabelexpressie toegewezen na de tabelexpressie zelf. De elementen zijn als het ware met elkaar verweven. Omgekeerd, bij CTE's, scheidt de code de drie elementen:eerst wijst u de naam van de tabeluitdrukking toe; ten tweede specificeert u de tabeluitdrukking - van begin tot eind zonder onderbrekingen; ten derde specificeert u de buitenste query - van begin tot eind zonder onderbrekingen. Later, onder 'Ontwerpoverwegingen', zal ik de implicaties van deze ontwerpverschillen uitleggen.
Een woord over CTE's en het gebruik van een puntkomma als verklaring terminator. Helaas, in tegenstelling tot standaard SQL, dwingt T-SQL je niet om alle instructies met een puntkomma te beëindigen. Er zijn echter maar heel weinig gevallen in T-SQL waar de code zonder een terminator dubbelzinnig is. In die gevallen is de opzegging verplicht. Een voorbeeld van zo'n geval betreft het feit dat de WITH-clausule voor meerdere doeleinden wordt gebruikt. Een daarvan is het definiëren van een CTE, een andere is het definiëren van een tabelhint voor een query, en er zijn een paar aanvullende gebruiksscenario's. In de volgende instructie wordt bijvoorbeeld de clausule WITH gebruikt om het serialiseerbare isolatieniveau te forceren met een tabelhint:
De kans op dubbelzinnigheid is wanneer u een niet-beëindigde instructie hebt die voorafgaat aan een CTE-definitie, in welk geval de parser mogelijk niet kan bepalen of de WITH-component bij de eerste of tweede instructie hoort. Hier is een voorbeeld om dit aan te tonen:
Hier kan de parser niet zeggen of de WITH-component moet worden gebruikt om een tabelhint te definiëren voor de tabel Klanten in de eerste instructie, of om een CTE-definitie te starten. U krijgt de volgende foutmelding:
De oplossing is natuurlijk om de instructie voorafgaand aan de CTE-definitie te beëindigen, maar als best practice zou u eigenlijk al uw verklaringen moeten beëindigen:
Het is je misschien opgevallen dat sommige mensen hun CTE-definities als oefening met een puntkomma beginnen, zoals:
Het punt in deze praktijk is om de kans op toekomstige fouten te verkleinen. Wat als iemand op een later moment een niet-beëindigde verklaring vlak voor uw CTE-definitie in het script toevoegt en niet de moeite neemt om het volledige script te controleren, maar alleen hun verklaring? Uw puntkomma vlak voor de WITH-clausule wordt in feite hun verklaring terminator. Je kunt zeker de bruikbaarheid van deze praktijk zien, maar het is een beetje onnatuurlijk. Wat wordt aanbevolen, hoewel moeilijker te bereiken, is om goede programmeerpraktijken in de organisatie in te voeren, inclusief het beëindigen van alle uitspraken.
Wat betreft de syntaxisregels die van toepassing zijn op de tabelexpressie die wordt gebruikt als de innerlijke query in de CTE-definitie, zijn ze dezelfde als die van toepassing zijn op de tabelexpressie die wordt gebruikt als de innerlijke query in een afgeleide tabeldefinitie. Dat zijn:
Zie de sectie "Een tabeluitdrukking is een tabel" in deel 2 van de serie voor details.
Als je ervaren T-SQL-ontwikkelaars vraagt of ze liever afgeleide tabellen of CTE's gebruiken, zal niet iedereen het erover eens zijn wat beter is. Natuurlijk hebben verschillende mensen verschillende stijlvoorkeuren. Ik gebruik soms afgeleide tabellen en soms CTE's. Het is goed om bewust de specifieke verschillen in taalontwerp tussen de twee tools te identificeren en te kiezen op basis van uw prioriteiten in een bepaalde oplossing. Met de tijd en ervaring maak je je keuzes intuïtiever.
Verder is het belangrijk om het gebruik van tabeluitdrukkingen en tijdelijke tabellen niet te verwarren, maar dat is een prestatiegerelateerde discussie die ik in een toekomstig artikel zal behandelen.
CTE's hebben recursieve querymogelijkheden en afgeleide tabellen niet. Dus als u daarop moet vertrouwen, gaat u natuurlijk voor CTE's. Recursieve zoekopdrachten staan centraal in het artikel van volgende maand.
In deel 2 heb ik uitgelegd dat ik het nesten van afgeleide tabellen zie als een toevoeging van complexiteit aan de code, omdat het moeilijk is om de logica te volgen. Ik gaf het volgende voorbeeld, waarin ik de besteljaren identificeerde waarin meer dan 70 klanten bestellingen plaatsten:
CTE's bieden geen ondersteuning voor nesten. Dus wanneer u een oplossing beoordeelt of problemen oplost op basis van CTE's, raakt u niet verdwaald in de geneste logica. In plaats van te nesten, bouwt u meer modulaire oplossingen door meerdere CTE's te definiëren onder dezelfde WITH-instructie, gescheiden door komma's. Elk van de CTE's is gebaseerd op een query die van begin tot eind wordt geschreven zonder onderbrekingen. Ik zie het als een goede zaak vanuit het oogpunt van duidelijkheid en onderhoudbaarheid van de code.
Hier is een oplossing voor de bovengenoemde taak met behulp van CTE's:
Ik vind de op CTE gebaseerde oplossing beter. Maar nogmaals, vraag ervaren ontwikkelaars welke van de twee bovenstaande oplossingen hun voorkeur hebben, en ze zullen het er niet allemaal mee eens zijn. Sommigen geven de voorkeur aan de geneste logica en alles op één plek kunnen zien.
Een heel duidelijk voordeel van CTE's ten opzichte van afgeleide tabellen is wanneer u moet communiceren met meerdere instanties van dezelfde tabelexpressie in uw oplossing. Onthoud het volgende voorbeeld, gebaseerd op afgeleide tabellen uit deel 2 van de serie:
Deze oplossing retourneert orderjaren, ordertellingen per jaar en het verschil tussen de tellingen van het huidige jaar en het voorgaande jaar. Ja, je zou het gemakkelijker kunnen doen met de LAG-functie, maar mijn focus ligt hier niet op het vinden van de beste manier om deze zeer specifieke taak uit te voeren. Ik gebruik dit voorbeeld om bepaalde taalontwerpaspecten van benoemde tabeluitdrukkingen te illustreren.
Het probleem met deze oplossing is dat u geen naam kunt toewijzen aan een tabeluitdrukking en deze opnieuw kunt gebruiken in dezelfde stap voor het verwerken van logische query's. U noemt een afgeleide tabel naar de tabelexpressie zelf in de FROM-component. Als u een afgeleide tabel definieert en een naam geeft als de eerste invoer van een join, kunt u die afgeleide tabelnaam niet ook opnieuw gebruiken als de tweede invoer van dezelfde join. Als u zelf twee instanties van dezelfde tabeluitdrukking wilt koppelen, heeft u bij afgeleide tabellen geen andere keuze dan de code te dupliceren. Dat is wat je deed in het bovenstaande voorbeeld. Omgekeerd wordt de CTE-naam toegewezen als het eerste element van de code tussen de bovengenoemde drie (CTE-naam, inner query, outer query). In termen van logische queryverwerking:tegen de tijd dat u bij de buitenste query komt, is de CTE-naam al gedefinieerd en beschikbaar. Dit betekent dat u kunt communiceren met meerdere instanties van de CTE-naam in de buitenste query, zoals:
Deze oplossing heeft een duidelijk programmeervoordeel ten opzichte van de oplossing die is gebaseerd op afgeleide tabellen, omdat u niet twee exemplaren van dezelfde tabelexpressie hoeft te onderhouden. Er valt meer over te zeggen vanuit het oogpunt van fysieke verwerking, en vergelijk het met het gebruik van tijdelijke tabellen, maar ik zal dit doen in een toekomstig artikel dat zich richt op prestaties.
Een voordeel van code op basis van afgeleide tabellen in vergelijking met code op basis van CTE's heeft te maken met de sluitingseigenschap die een tabeluitdrukking zou moeten hebben. Onthoud dat de sluitingseigenschap van een relationele uitdrukking zegt dat zowel de invoer als de uitvoer relaties zijn, en dat een relationele uitdrukking daarom kan worden gebruikt waar een relatie wordt verwacht, als invoer voor weer een andere relationele uitdrukking. Op dezelfde manier retourneert een tabelexpressie een tabel en wordt verondersteld beschikbaar te zijn als invoertabel voor een andere tabelexpressie. Dit geldt voor een query die is gebaseerd op afgeleide tabellen - u kunt deze gebruiken waar een tabel wordt verwacht. U kunt bijvoorbeeld een query gebruiken die is gebaseerd op afgeleide tabellen als de innerlijke query van een CTE-definitie, zoals in het volgende voorbeeld:
Hetzelfde geldt echter niet voor een zoekopdracht die is gebaseerd op CTE's. Hoewel het conceptueel wordt verondersteld te worden beschouwd als een tabeluitdrukking, kunt u deze niet gebruiken als de innerlijke query in afgeleide tabeldefinities, subquery's en CTE's zelf. De volgende code is bijvoorbeeld niet geldig in T-SQL:
Het goede nieuws is dat je een query kunt gebruiken die is gebaseerd op CTE's als de innerlijke query in views en inline tabelwaardefuncties, die ik in toekomstige artikelen behandel.
Onthoud ook dat u altijd een andere CTE kunt definiëren op basis van de laatste zoekopdracht, en vervolgens de buitenste zoekopdracht kunt laten interageren met die CTE:
Zoals gezegd, vind ik het vanuit het oogpunt van probleemoplossing meestal gemakkelijker om de logica van code te volgen die is gebaseerd op CTE's, in vergelijking met code die is gebaseerd op afgeleide tabellen. Oplossingen op basis van afgeleide tabellen hebben echter het voordeel dat u elk nestingniveau kunt markeren en onafhankelijk kunt uitvoeren, zoals weergegeven in afbeelding 1.
Met CTE's is het lastiger. Om ervoor te zorgen dat code met CTE's kan worden uitgevoerd, moet deze beginnen met een WITH-component, gevolgd door een of meer benoemde tabeluitdrukkingen tussen haakjes, gescheiden door komma's, gevolgd door een query zonder tussen haakjes geplaatste komma's. Je bent in staat om alle innerlijke vragen die echt op zichzelf staan te markeren en uit te voeren, evenals de code van de volledige oplossing; u kunt echter geen ander tussenliggend deel van de oplossing markeren en met succes uitvoeren. Afbeelding 2 toont bijvoorbeeld een mislukte poging om de code die C2 voorstelt uit te voeren.
Dus bij CTE's moet je wat onhandige middelen gebruiken om een tussenstap van de oplossing te kunnen oplossen. Een veelgebruikte oplossing is bijvoorbeeld om tijdelijk een SELECT * FROM your_cte-query direct onder de relevante CTE te injecteren. U markeert en voert vervolgens de code uit, inclusief de geïnjecteerde query, en wanneer u klaar bent, verwijdert u de geïnjecteerde query. Afbeelding 3 demonstreert deze techniek.
Het probleem is dat wanneer u wijzigingen aanbrengt in de code, zelfs tijdelijke kleine wijzigingen zoals hierboven, de kans bestaat dat wanneer u probeert terug te keren naar de oorspronkelijke code, u uiteindelijk een nieuwe bug introduceert.
Een andere optie is om uw code een beetje anders op te maken, zodat elke niet-eerste CTE-definitie begint met een aparte regel code die er als volgt uitziet:
Wanneer u vervolgens een tussenliggend deel van de code naar een bepaalde CTE wilt uitvoeren, kunt u dit doen met minimale wijzigingen in uw code. Met behulp van een regelcommentaar becommentarieert u alleen die ene regel code die overeenkomt met die CTE. Vervolgens markeert u de code en voert u deze uit tot en met de inner query van die CTE, die nu als de buitenste query wordt beschouwd, zoals geïllustreerd in figuur 4.
Als je niet tevreden bent met deze stijl, heb je nog een andere optie. U kunt een blokopmerking gebruiken die begint net voor de komma die voorafgaat aan de CTE van belang en eindigt na de open haakjes, zoals geïllustreerd in afbeelding 5.
Het komt neer op persoonlijke voorkeuren. Ik gebruik meestal de tijdelijk geïnjecteerde SELECT * query-techniek.
Er is een zekere beperking in de ondersteuning van T-SQL voor tabelwaardeconstructors in vergelijking met de standaard. Als je niet bekend bent met de constructie, bekijk dan eerst deel 2 in de serie, waar ik het in detail beschrijf. Terwijl u met T-SQL een afgeleide tabel kunt definiëren op basis van een tabelwaardeconstructor, kunt u geen CTE definiëren op basis van een tabelwaardeconstructor.
Hier is een ondersteund voorbeeld dat een afgeleide tabel gebruikt:
Helaas wordt vergelijkbare code die een CTE gebruikt niet ondersteund:
Deze code genereert de volgende fout:
Er zijn echter een paar oplossingen. Een daarvan is om een query te gebruiken tegen een afgeleide tabel, die op zijn beurt is gebaseerd op een tabelwaardeconstructor, als de innerlijke query van de CTE, zoals:
Een andere manier is om de techniek te gebruiken die mensen gebruikten voordat constructors met tabelwaarde in T-SQL werden geïntroduceerd - met behulp van een reeks FROMless-query's gescheiden door UNION ALL-operators, zoals:
Merk op dat de kolomaliassen direct na de CTE-naam worden toegewezen.
De twee methoden worden op dezelfde manier gealgebreerd en geoptimaliseerd, dus gebruik de methode waarmee u zich het prettigst voelt.
Een hulpmiddel dat ik vrij vaak in mijn oplossingen gebruik, is een hulptabel met getallen. Een optie is om een echte getallentabel in uw database te maken en deze te vullen met een reeks van redelijk formaat. Een andere is het ontwikkelen van een oplossing die een reeks getallen on-the-fly produceert. Voor de laatste optie wil je dat de invoer de begrenzers zijn van het gewenste bereik (we noemen ze
Deze code genereert de volgende uitvoer:
De eerste CTE genaamd L0 is gebaseerd op een tabelwaardeconstructor met twee rijen. De werkelijke waarden zijn daar onbeduidend; wat belangrijk is, is dat het twee rijen heeft. Vervolgens is er een reeks van vijf extra CTE's genaamd L1 tot en met L5, die elk een kruisverbinding toepassen tussen twee instanties van de voorgaande CTE. De volgende code berekent het aantal rijen dat mogelijk wordt gegenereerd door elk van de CTE's, waarbij @L het CTE-niveaunummer is:
Dit zijn de cijfers die u voor elke CTE krijgt:
Als je naar niveau 5 gaat, krijg je meer dan vier miljard rijen. Dit zou voldoende moeten zijn voor elk praktisch gebruik dat ik kan bedenken. De volgende stap vindt plaats in de CTE genaamd Nums. U gebruikt een ROW_NUMBER-functie om een reeks gehele getallen te genereren die begint met 1 op basis van geen gedefinieerde volgorde (ORDER BY (SELECT NULL)) en geeft de resultaatkolom een naam rownum. Ten slotte gebruikt de buitenste query een TOP-filter op basis van rijnummervolgorde om zoveel getallen te filteren als de gewenste reekskardinaliteit (@high – @low + 1), en berekent het resultaatgetal n als @low + rownum – 1.
Hier kunt u echt de schoonheid van het CTE-ontwerp waarderen en de besparingen die het mogelijk maakt wanneer u oplossingen modulair bouwt. Uiteindelijk pakt het unnesting-proces 32 tabellen uit, elk bestaande uit twee rijen op basis van constanten. Dit is duidelijk te zien in het uitvoeringsplan voor deze code, zoals weergegeven in afbeelding 6 met SentryOne Plan Explorer.
Elke Constant Scan-operator vertegenwoordigt een tabel met constanten met twee rijen. Het punt is dat de Top-operator degene is die om die rijen vraagt, en hij maakt kortsluiting nadat hij het gewenste aantal heeft gekregen. Let op de 10 rijen die zijn aangegeven boven de pijl die naar de Top-operator stromen.
Ik weet dat de focus van dit artikel ligt op de conceptuele behandeling van CTE's en niet op fysieke/prestatieoverwegingen, maar door naar het plan te kijken, kun je de beknoptheid van de code echt waarderen in vergelijking met de langdradige van wat het achter de schermen betekent.
Met behulp van afgeleide tabellen kunt u een oplossing schrijven die elke CTE-verwijzing vervangt door de onderliggende query die deze vertegenwoordigt. Wat je krijgt is best eng:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formaat
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Onjuiste syntaxis bij 'UC'. Als dit bedoeld is als een algemene tabelexpressie, moet u de vorige instructie expliciet beëindigen met een puntkomma. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Ontwerpoverwegingen
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figuur 1:Kan een deel van de code markeren en uitvoeren met afgeleide tabellen
Figuur 1:Kan een deel van de code markeren en uitvoeren met afgeleide tabellen  Figuur 2:Kan een deel van de code niet markeren en uitvoeren met CTE's
Figuur 2:Kan een deel van de code niet markeren en uitvoeren met CTE's  Figuur 3:Injecteer SELECT * onder relevante CTE
Figuur 3:Injecteer SELECT * onder relevante CTE , cte_name AS (
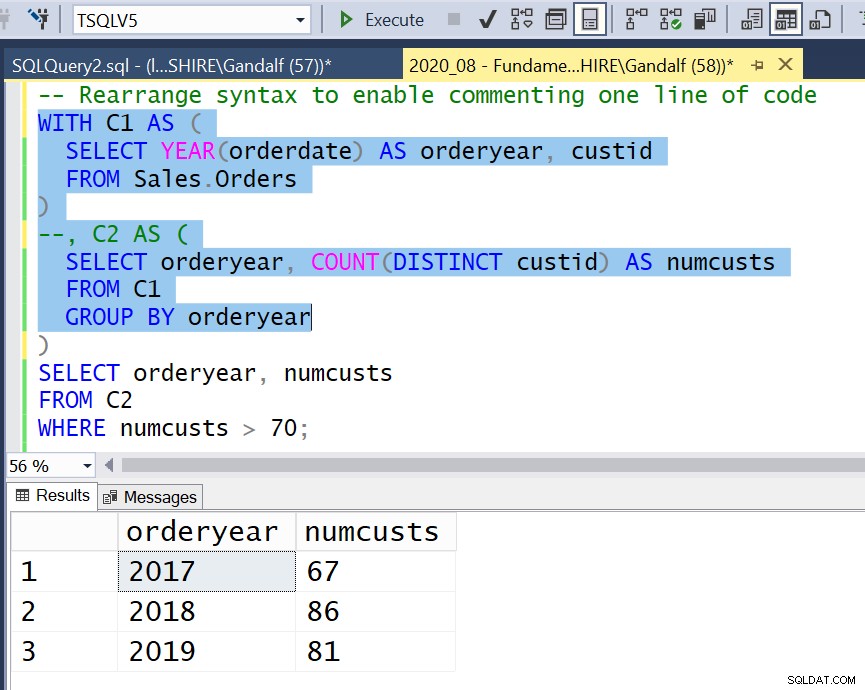 Figuur 4:Herschik de syntaxis om commentaar op één regel code mogelijk te maken
Figuur 4:Herschik de syntaxis om commentaar op één regel code mogelijk te maken  Figuur 5:Blokcommentaar gebruiken
Figuur 5:Blokcommentaar gebruiken Tabelwaardeconstructor
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Onjuiste syntaxis bij het trefwoord 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Een reeks getallen produceren
@low en @high ). U wilt dat uw oplossing potentieel grote bereiken ondersteunt. Hier is mijn oplossing voor dit doel, met behulp van CTE's, met een verzoek voor het bereik 1001 tot 1010 in dit specifieke voorbeeld:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardinaliteit L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4.294.967.296  Figuur 6:plan voor het genereren van een reeks getallen
Figuur 6:plan voor het genereren van een reeks getallen DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Summary
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes