Opmerking:dit bericht is oorspronkelijk alleen gepubliceerd in ons eBook, High Performance Techniques for SQL Server, Volume 3. U kunt hier meer te weten komen over onze eBooks.
Een vereiste die ik af en toe zie, is dat er een zoekopdracht wordt geretourneerd met bestellingen die zijn gegroepeerd op klant, met het maximale totaalbedrag dat tot nu toe voor elke bestelling is gezien (een "lopende max"). Dus stel je deze voorbeeldrijen eens voor:
| SalesOrderID | Klant-ID | Besteldatum | TotalDue |
|---|---|---|---|
| 12 | 2 | 01-01-2014 | 37.55 |
| 23 | 1 | 02-01-2014 | 45.29 |
| 31 | 2 | 03-01-2014 | 24.56 |
| 32 | 2 | 04-01-2014 | 89.84 |
| 37 | 1 | 05-01-2014 | 32.56 |
| 44 | 2 | 2014-01-06 | 45.54 |
| 55 | 1 | 07-01-2014 | 99.24 |
| 62 | 2 | 08-01-2014 | 12.55 |
Een paar rijen voorbeeldgegevens
De gewenste resultaten van de genoemde vereisten zijn als volgt:sorteer in duidelijke bewoordingen de bestellingen van elke klant op datum en vermeld elke bestelling. Als dat de hoogste TotalDue-waarde is voor alle bestellingen die tot die datum zijn gezien, drukt u het totaal van die bestelling af, of drukt u de hoogste TotalDue-waarde van alle eerdere bestellingen af:
| SalesOrderID | Klant-ID | Besteldatum | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 02-01-2014 | 45.29 | 45.29 |
| 23 | 1 | 05-01-2014 | 32.56 | 45.29 |
| 31 | 1 | 07-01-2014 | 99.24 | 99.24 |
| 32 | 2 | 01-01-2014 | 37.55 | 37.55 |
| 37 | 2 | 03-01-2014 | 24.56 | 37.55 |
| 44 | 2 | 04-01-2014 | 89.84 | 89.84 |
| 55 | 2 | 2014-01-06 | 45.54 | 89.84 |
| 62 | 2 | 08-01-2014 | 12.55 | 89.84 |
Voorbeeld van gewenste resultaten
Veel mensen zouden instinctief een cursor of while-lus willen gebruiken om dit te bereiken, maar er zijn verschillende benaderingen waarbij deze constructies niet worden gebruikt.
Gecorreleerde subquery
Deze benadering lijkt de eenvoudigste en meest rechttoe rechtaan benadering van het probleem, maar het is keer op keer bewezen om niet te schalen, aangezien de uitlezingen exponentieel groeien naarmate de tabel groter wordt:
SELECT /* Gecorreleerde subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader WHERE CustomerID =h.CustomerID EN SalesOrderID <=h.SalesOrderID) FROM Sales.SalesOrderHeader AS h BESTELLEN OP CustomerID, SalesOrderID;
Hier is het plan tegen AdventureWorks2014, met behulp van SQL Sentry Plan Explorer:
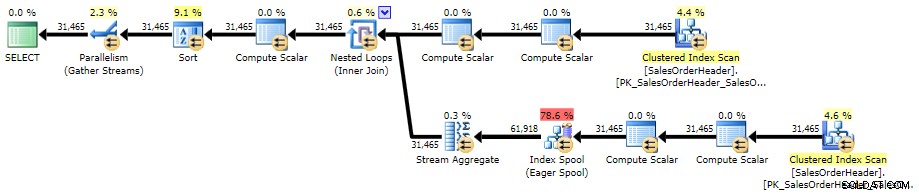 Uitvoeringsplan voor gecorreleerde subquery (klik om te vergroten)
Uitvoeringsplan voor gecorreleerde subquery (klik om te vergroten)
Zelfverwijzende CROSS APPLY
Deze benadering is bijna identiek aan de gecorreleerde subquery-aanpak, in termen van syntaxis, planvorm en prestaties op schaal.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader AS hCROSS APPLY( SELECT MaxTotalDue =MAX(TotalDue) FROM Sales.SalesOrderWHEREHeader AS i i.CustomerID =h.CustomerID EN i.SalesOrderID <=h.SalesOrderID) ALS xORDER DOOR h.CustomerID, h.SalesOrderID;
Het plan lijkt veel op het gecorreleerde subqueryplan, het enige verschil is de locatie van een soort:
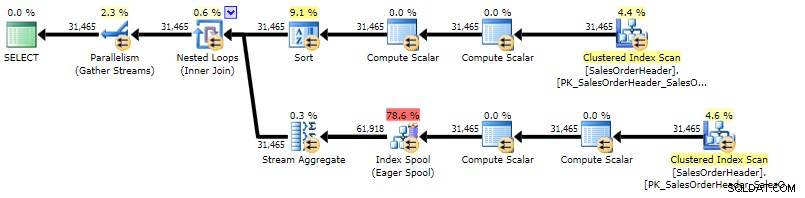 Uitvoeringsplan voor CROSS APPLY (klik om te vergroten)
Uitvoeringsplan voor CROSS APPLY (klik om te vergroten)
Recursieve CTE
Achter de schermen gebruikt dit lussen, maar totdat we het daadwerkelijk uitvoeren, kunnen we doen alsof dit niet het geval is (hoewel het gemakkelijk het meest gecompliceerde stuk code is dat ik ooit zou willen schrijven om dit specifieke probleem op te lossen):
;MET /* Recursieve CTE */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) VAN Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALLES SELECTEER r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =GEVAL WANNEER r.TotalDue> cte.MaxTotal.SEDue THEN r. .MaxTotalDue EINDE VAN cte CROSS APPLY (SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() OVER (VERDELING OP CustomerID ORDER DOOR SalesOrderID) VAN Sales.SalesOrderHeader AS h WHERE h.CustomerID =cte..SaCustomerID AND h..SaCustomerID AND h.. cte.SalesOrderID ) AS r WHERE r.rn =1)SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
Je ziet meteen dat het plan complexer is dan de vorige twee, wat niet verwonderlijk is gezien de complexere vraag:
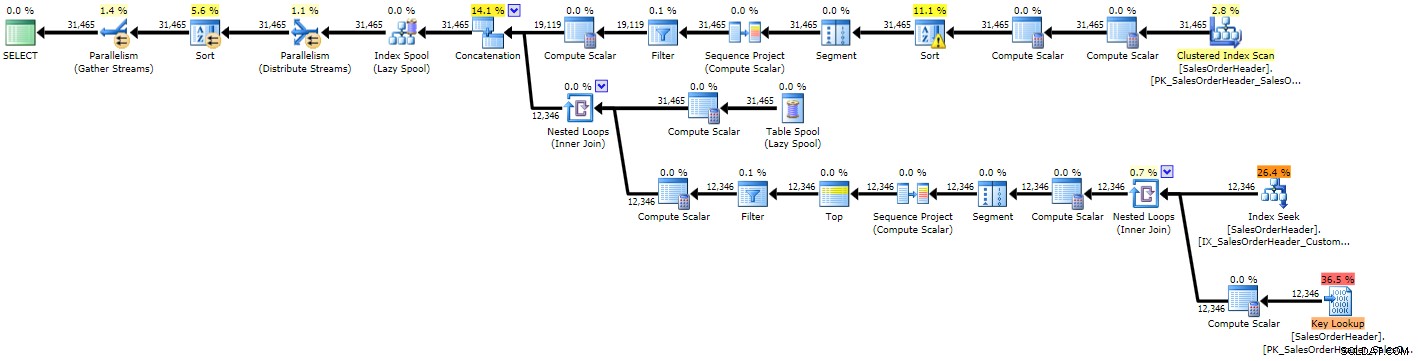 Uitvoeringsplan voor recursieve CTE (klik om te vergroten)
Uitvoeringsplan voor recursieve CTE (klik om te vergroten)
Vanwege enkele slechte schattingen zien we een indexzoekopdracht met een bijbehorende sleutelzoekopdracht die waarschijnlijk beide had moeten worden vervangen door een enkele scan, en we krijgen ook een sorteerbewerking die uiteindelijk naar tempdb moet gaan (u kunt dit zien in de tooltip als u de muisaanwijzer op de sorteeroperator met het waarschuwingspictogram plaatst):

MAX() OVER (RIJEN NIET GEBONDEN)
Dit is een oplossing die alleen beschikbaar is in SQL Server 2012 en hoger, omdat het gebruik maakt van nieuw geïntroduceerde extensies voor vensterfuncties.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER (VERDELING OP CustomerID ORDER DOOR SalesOrderID RIJEN ONGEBONDEN VOORAFGAAND aan) VAN Sales.SalesOrderHeaderORDER BY CustomerID;<, SalesOrderID; /pre>Het plan laat precies zien waarom het beter schaalt dan alle andere; het heeft slechts één geclusterde index-scanbewerking, in tegenstelling tot twee (of de slechte keuze van een scan en zoeken + opzoeken in het geval van de recursieve CTE):
Uitvoeringsplan voor MAX() OVER() (klik om te vergroten)
Prestatievergelijking
De plannen doen ons zeker geloven dat de nieuwe
MAX() OVER()mogelijkheid in SQL Server 2012 is een echte winnaar, maar hoe zit het met tastbare runtime-statistieken? Hier zijn hoe de executies vergeleken:
De eerste twee zoekopdrachten waren bijna identiek; terwijl in dit geval de
CROSS APPLYwas met een kleine marge beter in termen van totale duur, de gecorreleerde subquery verslaat het soms een beetje. De recursieve CTE is elke keer aanzienlijk langzamer en je kunt de factoren zien die daaraan bijdragen, namelijk de slechte schattingen, het enorme aantal leesbewerkingen, het opzoeken van de sleutel en de extra sorteerbewerking. En zoals ik eerder heb aangetoond met lopende totalen, is de SQL Server 2012-oplossing in bijna elk aspect beter.Conclusie
Als je SQL Server 2012 of hoger gebruikt, wil je zeker bekend raken met alle uitbreidingen van de vensterfuncties die voor het eerst werden geïntroduceerd in SQL Server 2005 - ze kunnen je behoorlijk serieuze prestatieverbeteringen geven bij het opnieuw bezoeken van code die nog steeds wordt uitgevoerd " op de oude manier." Als je meer wilt weten over enkele van deze nieuwe mogelijkheden, raad ik het boek van Itzik Ben-Gan ten zeerste aan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Als u SQL Server 2012 nog niet gebruikt, kunt u in deze test tenminste kiezen tussen
CROSS APPLYen de gecorreleerde subquery. Zoals altijd moet je verschillende methoden testen tegen je gegevens op je hardware.
