
T-SQL Tuesday #78 wordt gehost door Wendy Pastrick, en de uitdaging deze maand is gewoon om "iets nieuws te leren en erover te bloggen". Haar blurb neigt naar nieuwe functies in SQL Server 2016, maar aangezien ik veel daarvan heb geblogd en gepresenteerd, dacht ik dat ik uit de eerste hand iets anders zou ontdekken waar ik altijd oprecht nieuwsgierig naar ben geweest.
Ik heb meerdere mensen zien zeggen dat een hoop voor bepaalde scenario's beter kan zijn dan een geclusterde index. Ik kan het daar niet mee oneens zijn. Een van de interessante redenen die ik heb gezien is echter dat een RID Lookup sneller is dan een Key Lookup. Ik ben een grote fan van geclusterde indexen en geen grote fan van hopen, dus ik vond dat dit wat getest moest worden.
Dus laten we het testen!
Ik dacht dat het goed zou zijn om een database te maken met twee identieke tabellen, behalve dat de ene een geclusterde primaire sleutel had en de andere een niet-geclusterde primaire sleutel. Ik zou tijd nemen om enkele rijen in de tabel te laden, een aantal rijen in een lus bij te werken en uit een index te selecteren (waardoor een sleutel- of RID-zoekopdracht wordt geforceerd).
Systeemspecificaties
Deze vraag komt vaak naar voren, dus om de belangrijke details over dit systeem te verduidelijken, gebruik ik een 8-core VM met 32 GB RAM, ondersteund door PCIe-opslag. SQL Server-versie is 2014 SP1 CU6, zonder speciale configuratiewijzigingen of traceervlaggen:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 april 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) op Windows NT 6.3
De database
Ik heb een database gemaakt met veel vrije ruimte in zowel het gegevens- als het logbestand om te voorkomen dat autogrow-gebeurtenissen de tests verstoren. Ik heb de database ook ingesteld op eenvoudig herstel om de impact op het transactielogboek te minimaliseren.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
De Tafels
Zoals ik al zei, twee tabellen, met als enige verschil of de primaire sleutel geclusterd is.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Een tabel voor het vastleggen van runtime
Ik zou de CPU en dat alles kunnen controleren, maar de nieuwsgierigheid is bijna altijd rond runtime. Dus heb ik een logtabel gemaakt om de looptijd van elke test vast te leggen:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
De invoegtest
Dus, hoe lang duurt het om 2000 rijen, 100 keer in te voegen? Ik haal een aantal behoorlijk basisgegevens uit sys.all_objects , en de definitie mee te nemen voor alle procedures, functies, enz.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; De updatetest
Voor de update-test wilde ik de schrijfsnelheid naar een geclusterde index versus een hoop heel rij voor rij testen. Dus heb ik 200 willekeurige rijen in een #temp-tabel gedumpt en er een cursor omheen gebouwd (de #temp-tabel zorgt er alleen voor dat dezelfde 200 rijen worden bijgewerkt in beide versies van de tabel, wat waarschijnlijk overdreven is).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; De selectietest
Dus, hierboven zag je dat ik een index heb gemaakt met Name als de belangrijkste kolom in elke tabel; om de kosten van het uitvoeren van zoekopdrachten voor een aanzienlijk aantal rijen te evalueren, heb ik een query geschreven die de uitvoer toewijst aan een variabele (waardoor netwerk-I/O en clientweergavetijd worden geëlimineerd), maar het gebruik van de index afdwingt:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Voor deze wilde ik enkele interessante aspecten van de plannen laten zien voordat ik de testresultaten verzamelde. Door ze afzonderlijk tegen elkaar uit te voeren, krijgt u deze vergelijkende statistieken:

Duur is niet van belang voor een enkele verklaring, maar kijk eens naar die leest. Als je langzame opslag gebruikt, is dat een groot verschil dat je niet zult zien op een kleinere schaal en/of op je lokale ontwikkelings-SSD.
En dan de plannen die de twee verschillende zoekopdrachten tonen, met behulp van SQL Sentry Plan Explorer:

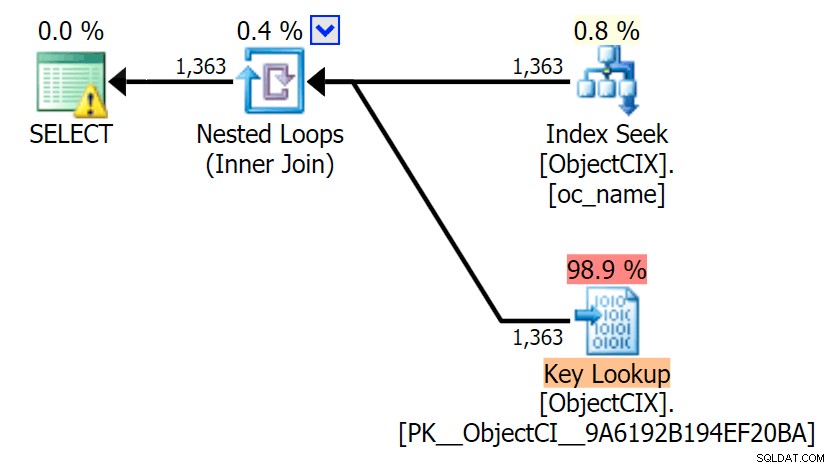
De plannen zien er bijna identiek uit, en je merkt het verschil in reads in SSMS misschien niet, tenzij je Statistics I/O vastlegt. Zelfs de geschatte I/O-kosten voor de twee zoekacties waren vergelijkbaar:1,69 voor de sleutelzoekactie en 1,59 voor de RID-zoekactie. (Het waarschuwingspictogram in beide plannen is voor een ontbrekende dekkingsindex.)
Het is interessant om op te merken dat als we een zoekopdracht niet forceren en SQL Server laat beslissen wat te doen, het in beide gevallen een standaardscan kiest - geen ontbrekende indexwaarschuwing, en kijken hoeveel dichterbij de uitlezingen zijn:

De optimizer weet dat een scan in dit geval veel goedkoper zal zijn dan zoeken + opzoeken. Ik koos alleen voor het effect een LOB-kolom voor variabele toewijzing, maar de resultaten waren ook vergelijkbaar met een niet-LOB-kolom.
De testresultaten
Met de Timings-tabel op zijn plaats, kon ik de tests gemakkelijk meerdere keren uitvoeren (ik heb een dozijn tests uitgevoerd) en vervolgens met gemiddelden voor de tests komen met de volgende vraag:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Een eenvoudig staafdiagram laat zien hoe ze zich verhouden:
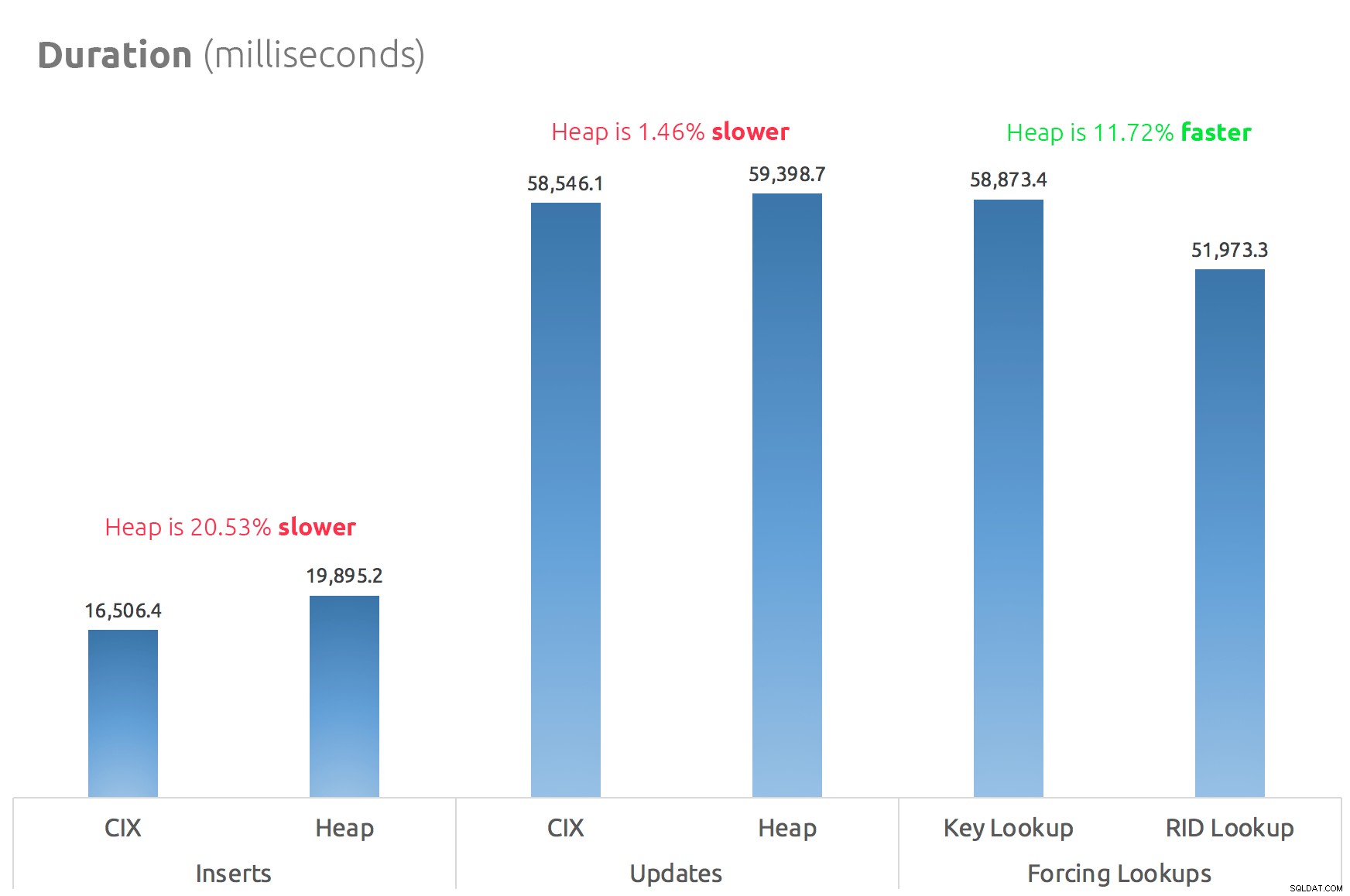
Conclusie
Dus de geruchten zijn waar:in dit geval is een RID Lookup in ieder geval aanzienlijk sneller dan een Key Lookup. Rechtstreeks naar file:page:slot gaan is uiteraard efficiënter in termen van I/O dan het volgen van de b-tree (en als je geen moderne opslag hebt, kan de delta veel meer opvallen).
Of je daar gebruik van wilt maken en alle andere heap-aspecten mee wilt nemen, hangt af van je werklast - de heap is iets duurder voor schrijfbewerkingen. Maar dit is niet definitief – dit kan sterk variëren, afhankelijk van de tabelstructuur, indexen en toegangspatronen.
Ik heb hier heel eenvoudige dingen getest, en als je hierover twijfelt, raad ik je ten zeerste aan om je werkelijke werklast op je eigen hardware te testen en voor jezelf te vergelijken (en vergeet niet dezelfde werklast te testen waar dekkende indexen aanwezig zijn; u zult waarschijnlijk veel betere algemene prestaties krijgen als u zoekopdrachten gewoon helemaal kunt elimineren). Zorg ervoor dat u alle statistieken meet die voor u belangrijk zijn; alleen omdat ik me concentreer op de duur, wil nog niet zeggen dat dit degene is waar je het meest om moet geven. :-)