Gegroepeerde aaneenschakeling is een veelvoorkomend probleem in SQL Server, zonder directe en opzettelijke functies om het te ondersteunen (zoals XMLAGG in Oracle, STRING_AGG of ARRAY_TO_STRING(ARRAY_AGG()) in PostgreSQL en GROUP_CONCAT in MySQL). Het is aangevraagd, maar nog geen succes, zoals blijkt uit deze Connect-items:
- Connect #247118:SQL heeft versie van MySQL group_Concat-functie nodig (uitgesteld)
- Connect #728969:Geordende Set Functies – BINNEN GROEP Clausule (Gesloten omdat dit niet oplost)
** UPDATE januari 2017 ** :STRING_AGG() zit in SQL Server 2017; lees er hier, hier en hier over.
Wat is gegroepeerde aaneenschakeling?
Voor niet-ingewijden is gegroepeerde aaneenschakeling wanneer u meerdere rijen gegevens wilt nemen en deze wilt comprimeren tot een enkele tekenreeks (meestal met scheidingstekens zoals komma's, tabs of spaties). Sommigen noemen dit een 'horizontale samenvoeging'. Een snel visueel voorbeeld dat laat zien hoe we een lijst met huisdieren van elk gezinslid zouden comprimeren, van de genormaliseerde bron tot de "afgeplatte" uitvoer:
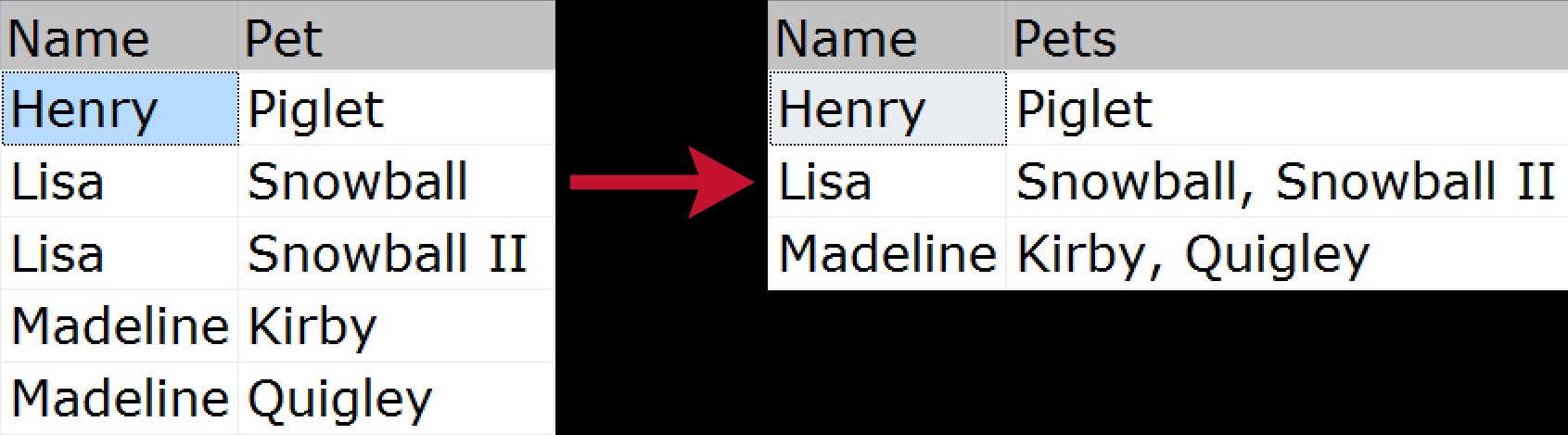
Er zijn in de loop der jaren veel manieren geweest om dit probleem op te lossen; hier zijn er slechts een paar, gebaseerd op de volgende voorbeeldgegevens:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Ik ga geen uitputtende lijst demonstreren van elke gegroepeerde aaneenschakeling die ooit is bedacht, omdat ik me wil concentreren op een paar aspecten van mijn aanbevolen aanpak, maar ik wil wel wijzen op een paar van de meest voorkomende:
Scalaire UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Opmerking:er is een reden waarom we dit niet doen:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Met DISTINCT , de functie wordt voor elke rij uitgevoerd, daarna worden duplicaten verwijderd; met GROUP BY , worden de duplicaten eerst verwijderd.
Common Language Runtime (CLR)
Dit gebruikt de GROUP_CONCAT_S functie gevonden op https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Recursieve CTE
Er zijn verschillende variaties op deze recursie; deze haalt een reeks verschillende namen tevoorschijn als het anker:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Cursor
Hier valt niet veel te zeggen; cursors zijn meestal niet de optimale benadering, maar dit kan uw enige keuze zijn als u vastzit op SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Eigenzinnige update
Sommige mensen * houden * van deze benadering; Ik begrijp de aantrekkingskracht helemaal niet.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; VOOR XML-PAD
Vrij gemakkelijk mijn voorkeursmethode, althans gedeeltelijk omdat het de enige manier is om *garanderen* te bestellen zonder een cursor of CLR te gebruiken. Dat gezegd hebbende, dit is een zeer onbewerkte versie die een aantal andere inherente problemen niet aanpakt die ik verderop zal bespreken:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Ik heb gezien dat veel mensen ten onrechte aannemen dat de nieuwe CONCAT() functie geïntroduceerd in SQL Server 2012 was het antwoord op deze functieverzoeken. Die functie is alleen bedoeld om te werken tegen kolommen of variabelen in een enkele rij; het kan niet worden gebruikt om waarden tussen rijen samen te voegen.
Meer over FOR XML PATH
FOR XML PATH('') op zichzelf is niet goed genoeg - het heeft bekende problemen met XML-entitisatie. Als u bijvoorbeeld een van de koosnaampjes bijwerkt met een HTML-haakje of een ampersand:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Deze worden ergens onderweg vertaald naar XML-veilige entiteiten:
Qui>gle&y
Dus ik gebruik altijd PATH, TYPE).value() , als volgt:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Ik gebruik ook altijd NVARCHAR , omdat je nooit weet wanneer een onderliggende kolom Unicode zal bevatten (of later zal worden gewijzigd om dit te doen).
Mogelijk ziet u de volgende varianten in .value() , of zelfs anderen:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Deze zijn onderling uitwisselbaar en vertegenwoordigen uiteindelijk allemaal dezelfde string; de prestatieverschillen tussen hen (meer hieronder) waren verwaarloosbaar en mogelijk volledig niet-deterministisch.
Een ander probleem dat u tegen kunt komen, zijn bepaalde ASCII-tekens die niet in XML kunnen worden weergegeven; bijvoorbeeld als de tekenreeks het teken 0x001A . bevat (CHAR(26) ), krijgt u deze foutmelding:
FOR XML kon de gegevens voor node 'NoName' niet serialiseren omdat het een teken (0x001A) bevat dat niet is toegestaan in XML. Om deze gegevens op te halen met FOR XML, converteert u deze naar binair, varbinair of afbeeldingsgegevenstype en gebruikt u de BINARY BASE64-richtlijn.
Dit lijkt me behoorlijk ingewikkeld, maar hopelijk hoef je je er geen zorgen over te maken omdat je gegevens niet op deze manier opslaat of in ieder geval niet probeert om het in gegroepeerde aaneenschakeling te gebruiken. Als dat zo is, moet u misschien terugvallen op een van de andere benaderingen.
Prestaties
De bovenstaande voorbeeldgegevens maken het gemakkelijk om te bewijzen dat deze methoden allemaal doen wat we verwachten, maar het is moeilijk om ze zinvol te vergelijken. Dus vulde ik de tabel met een veel grotere set:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Voor mij waren dit 575 objecten, met in totaal 7.080 rijen; het breedste object had 142 kolommen. Nogmaals, toegegeven, het was niet mijn bedoeling om elke afzonderlijke benadering die in de geschiedenis van SQL Server is bedacht, te vergelijken; slechts de paar hoogtepunten die ik hierboven heb gepost. Dit waren de resultaten:
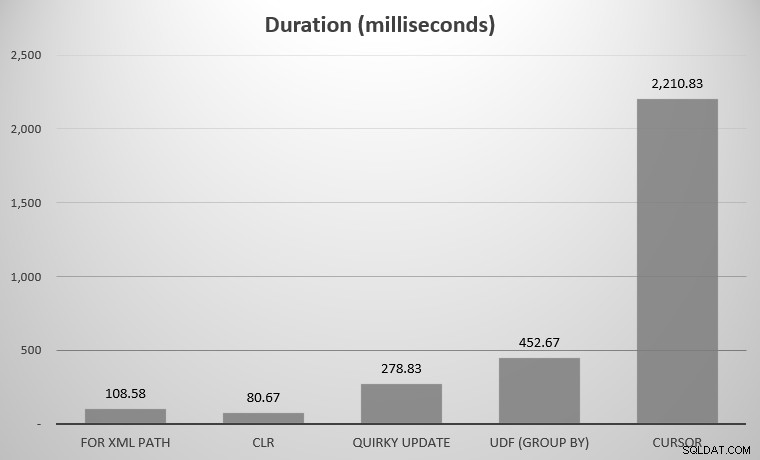
Je merkt misschien dat er een paar kanshebbers ontbreken; de UDF met behulp van DISTINCT en de recursieve CTE waren zo buiten de hitlijsten dat ze de schaal zouden scheeftrekken. Hier zijn de resultaten van alle zeven benaderingen in tabelvorm:
| Aanpak | Duur (milliseconden) |
|---|---|
| VOOR XML-PAD | 108.58 |
| CLR | 80.67 |
| Eigenzinnige update | 278.83 |
| UDF (GROEP OP) | 452.67 |
| UDF (DISTINCT) | 5.893,67 |
| Cursor | 2.210,83 |
| Recursieve CTE | 70.240.58 |
Gemiddelde duur, in milliseconden, voor alle benaderingen
Merk ook op dat de variaties op FOR XML PATH werden onafhankelijk getest maar vertoonden zeer kleine verschillen, dus ik heb ze gewoon voor het gemiddelde gecombineerd. Als je het echt wilt weten, de .[1] notatie werkte het snelst in mijn tests; YMMV.
Conclusie
Als je niet in een winkel bent waar CLR op enigerlei wijze een wegversperring is, en vooral als je niet alleen te maken hebt met simpele namen of andere strings, moet je zeker het CodePlex-project overwegen. Probeer niet het wiel opnieuw uit te vinden, probeer geen onintuïtieve trucs en hacks om CROSS APPLY te maken of andere constructies werken net iets sneller dan de niet-CLR-benaderingen hierboven. Neem gewoon wat werkt en sluit het aan. En ach, aangezien je ook de broncode krijgt, kun je deze verbeteren of uitbreiden als je wilt.
Als CLR een probleem is, dan FOR XML PATH is waarschijnlijk je beste optie, maar je moet nog steeds oppassen voor lastige karakters. Als je vastzit aan SQL Server 2000, is de enige haalbare optie de UDF (of vergelijkbare code die niet in een UDF is verpakt).
Volgende keer
Een aantal dingen die ik in een vervolgpost wil onderzoeken:dubbele items uit de lijst verwijderen, de lijst op iets anders dan de waarde zelf ordenen, gevallen waarin het pijnlijk kan zijn om een van deze benaderingen in een UDF te zetten, en praktische gebruiksscenario's voor deze functionaliteit.