In deel 1 van deze serie hebben we met succes de SuiteCRM-databasestructuur geïmporteerd in onze online databasemodelleringstool. Toen zagen we dat het model 201 tabellen bevat zonder onderlinge relaties. We kregen een wild stel tafels die er echt rommelig uitzagen. In dit artikel laat ik je zien hoe je zo'n groot model kunt organiseren.
Net na het importeren in Vertabelo ziet het SuiteCRM-databasemodel er als volgt uit:
Het model werkt wel, maar niet efficiënt. We zullen het moeten aanpassen om het echt bruikbaar te maken. Omdat we de SuiteCRM-database willen analyseren na acties worden uitgevoerd op de GUI, moeten we tabeldefinities en de relaties tussen tabellen begrijpen. Laten we beginnen met het groeperen van tabellen in onderwerpgebieden en het leggen van de belangrijkste relaties.
Vertabelo biedt drie hoofdtools om u te helpen bij het organiseren van grote diagrammen:
- Onderwerpen
- Tabellen en snelkoppelingen bekijken
- Referentiesnelkoppelingen
Ik zal ze later in dit artikel beschrijven, maar je kunt ook meer leren door deze video te bekijken.
Stap 1. Schakel het automatisch genereren van buitenlandse sleutels uit
Allereerst zullen we het automatisch genereren van externe sleutels uitschakelen. Standaard genereert Vertabelo attributen voor externe sleutels wanneer we relaties van een primaire tabel naar een tabel waarnaar wordt verwezen, ophalen. Dit is meestal een goede zaak, maar niet hier. We hebben al attributen die refererende sleutels vertegenwoordigen. Wat we missen zijn 'echte' relaties tussen tabellen. Als u deze optie wilt uitschakelen, klikt u op 'Mijn account' in het hoofdmenu en zoek de “Persoonlijke voorkeuren” sectie.
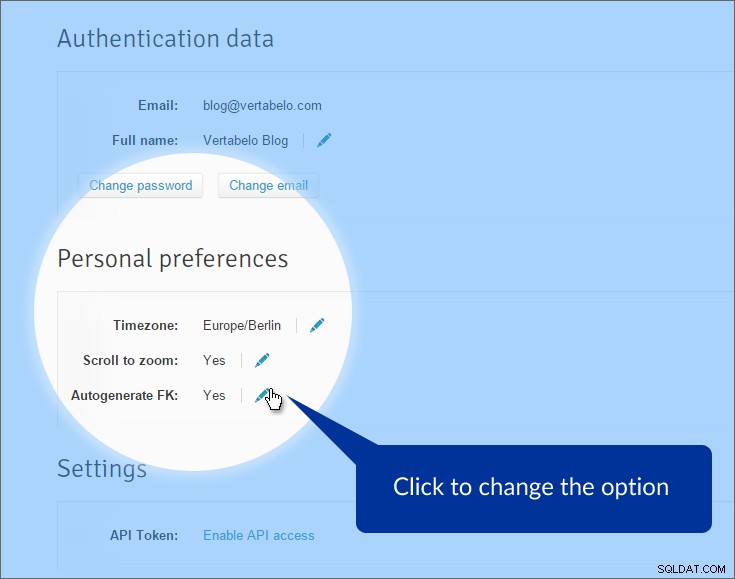
De optie is uitgeschakeld. Als we nu een referentielijn tussen tabellen tekenen, wordt de lijn gemaakt, maar we moeten specificeren welke attributen worden gebruikt, zowel aan de primaire als aan de buitenlandse zijde.
Stap 2. Groepeer vooraf ingestelde tabellen met onderwerpgebieden
Laten we vervolgens enkele tabellen groeperen. We doen dit met behulp van het Onderwerpgebied tool waarmee tabellen kunnen worden gekoppeld op basis van geselecteerde criteria. In ons geval proberen we tabellen te identificeren die gerelateerd zijn aan of deel uitmaken van hetzelfde proces. Dit resulteert in groepen zoals 'Oproepen', 'Vergaderingen' en 'Campagnes'.
We kunnen een onderwerpgebied maken door op "Nieuw gebied toevoegen" . te klikken icoon in de gereedschapskist:
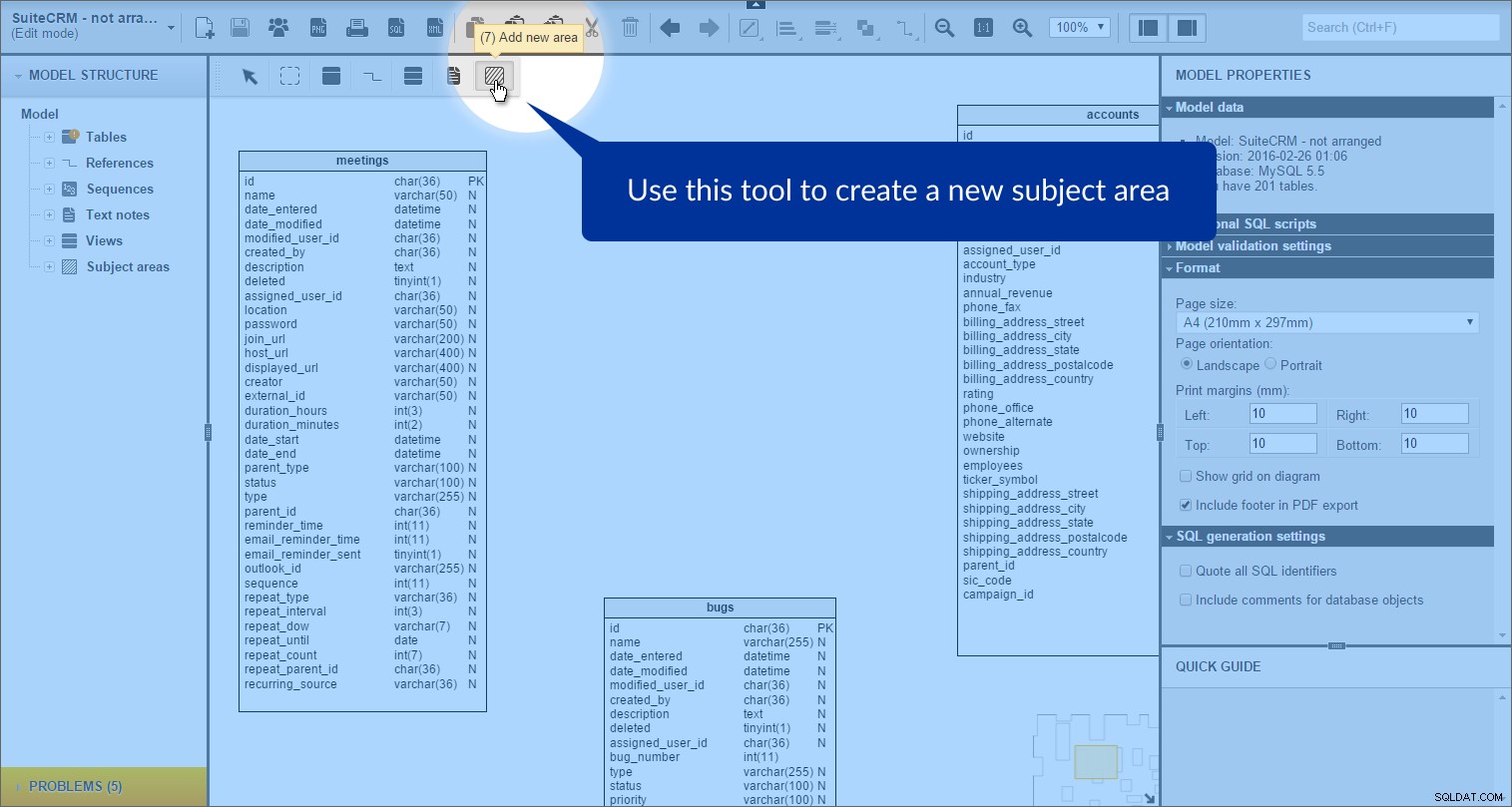
en vervolgens een rechthoek tekenen op ons model:
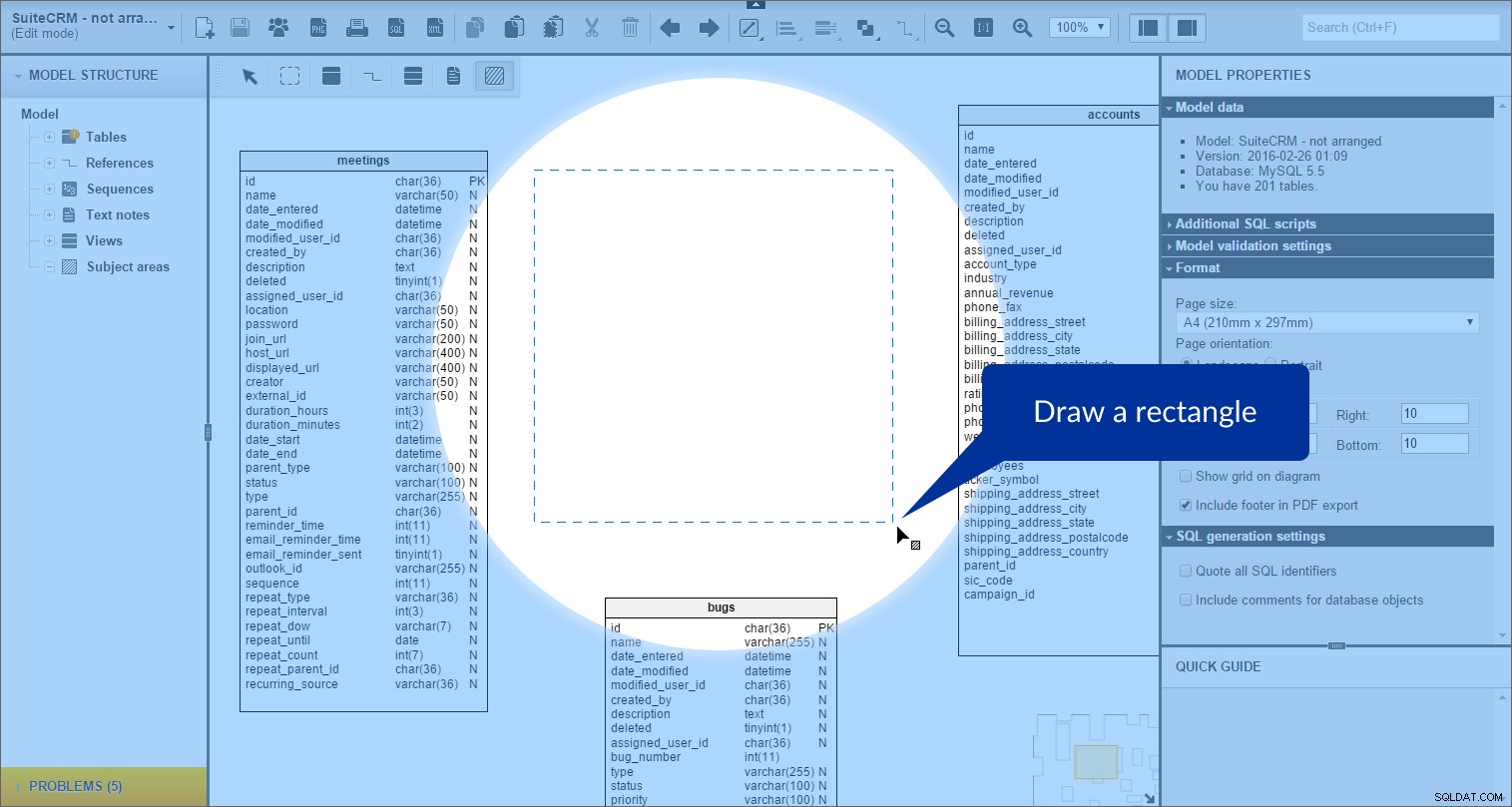
Het onderwerpgebied wordt gemaakt. We kunnen het zien in de “Modelstructuur” paneel aan de linkerkant:
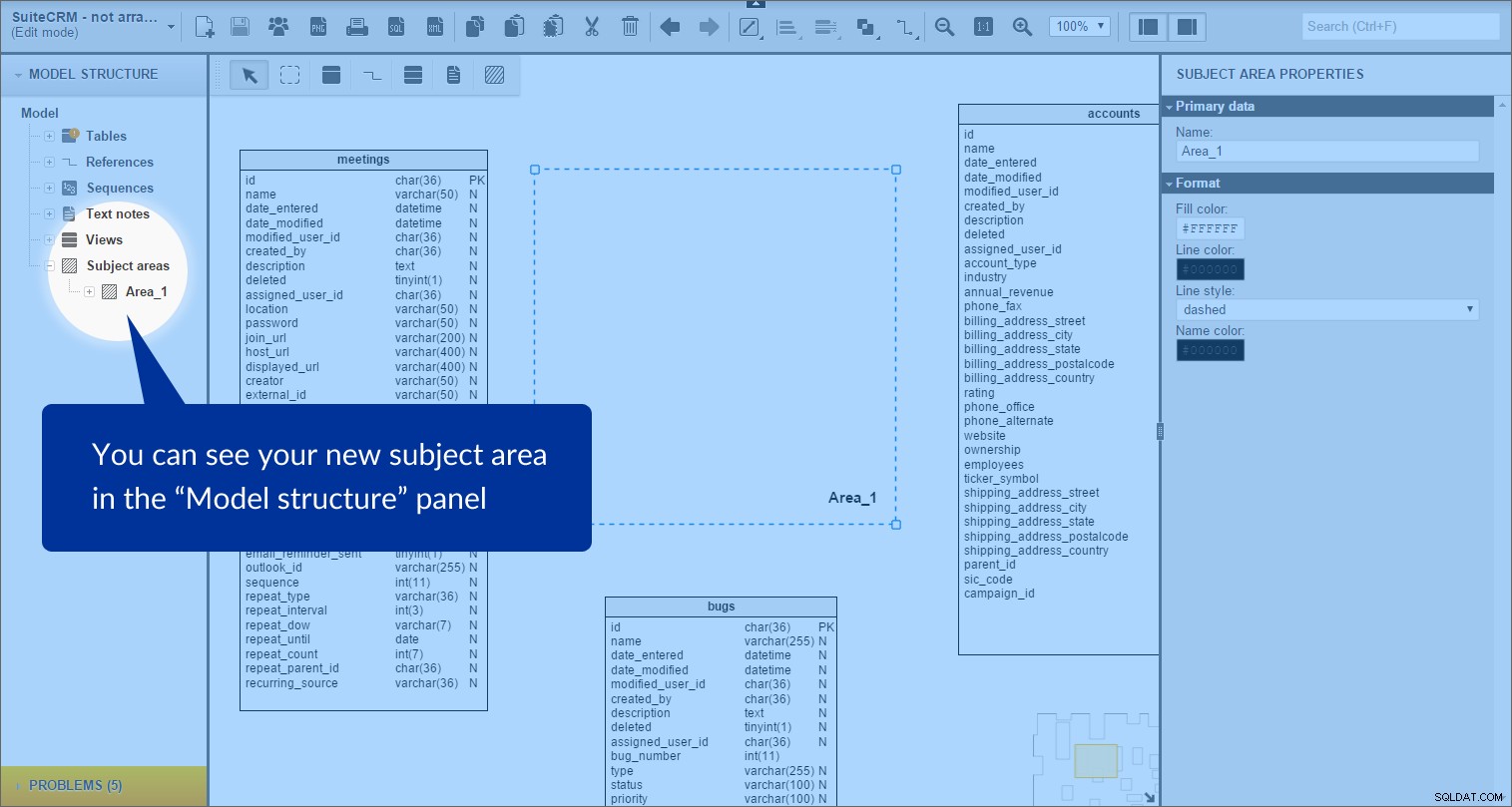
Elk onderwerpgebied bevat een lijst van alle objecten die zich binnen de grenzen ervan bevinden; in dit geval zijn dit tabellen en referentietypes.
In SuiteCRM zijn er veel tabellen die een gemeenschappelijk voorvoegsel delen. Dus begon ik de vooraf ingestelde tabellen samen te groeperen. Kijk eens naar de “acl” tabellen als voorbeeld. In het paneel "Modelstructuur" vond ik alle tabellen waarvan de namen begonnen met "acl_":
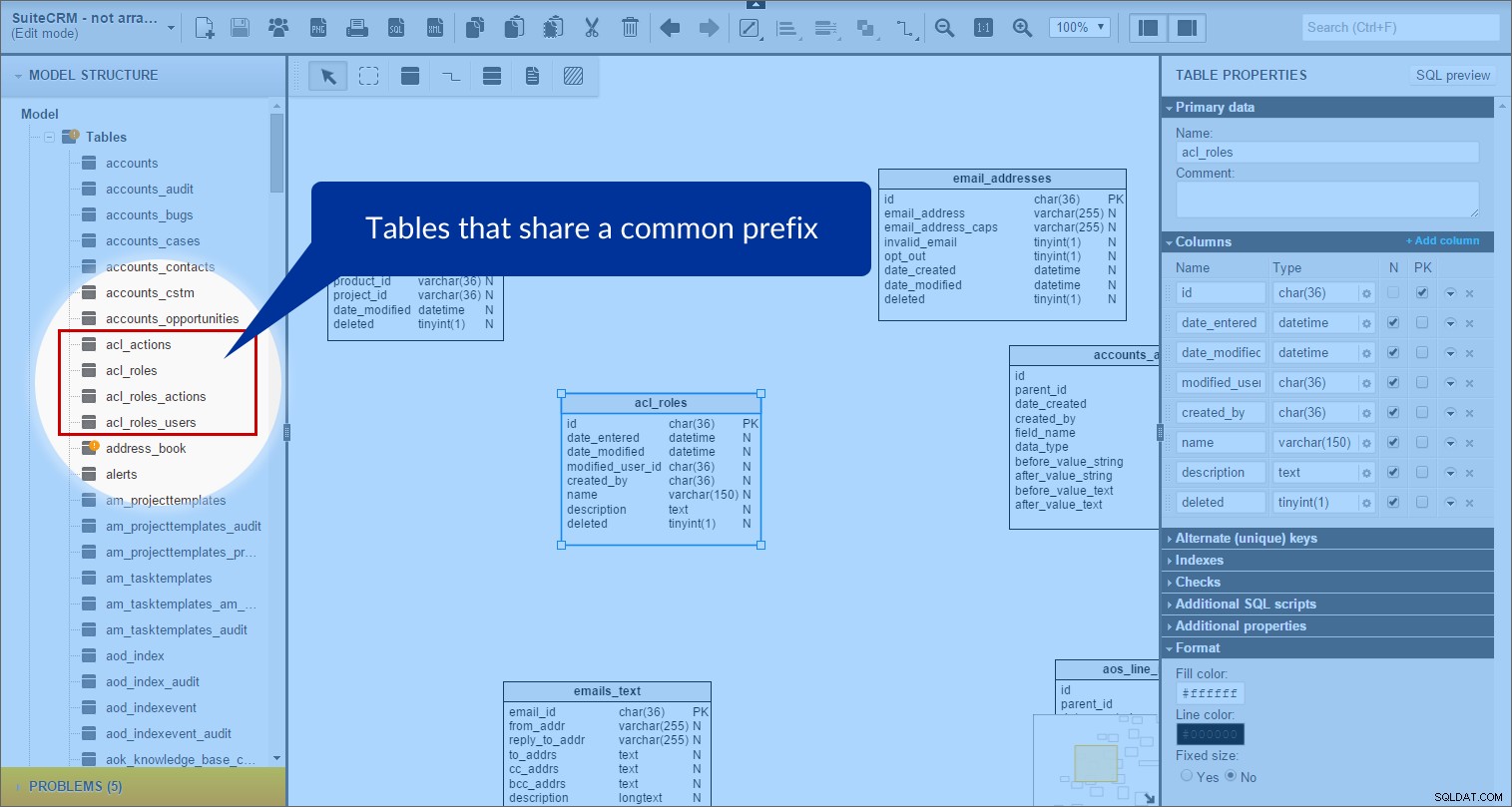
Vervolgens heb ik het onderwerpgebied "acl" in het model gemaakt en alle relevante tabellen erin gesleept. (Voor een betere zichtbaarheid heb ik de achtergrondkleur ingesteld op paars.)
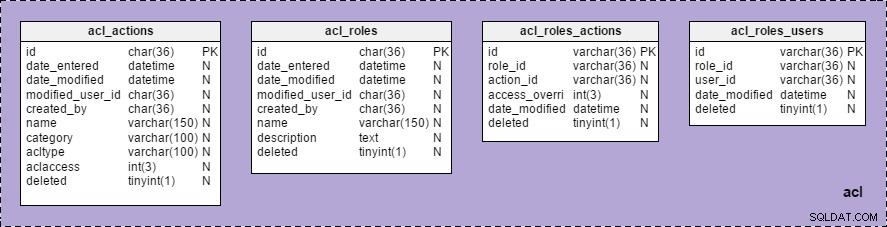
Nu kunnen we de groep "acl" zien, met een lijst van alle tabellen die erbij horen, onder "Onderwerpgebieden" in de "Modelstructuur" :
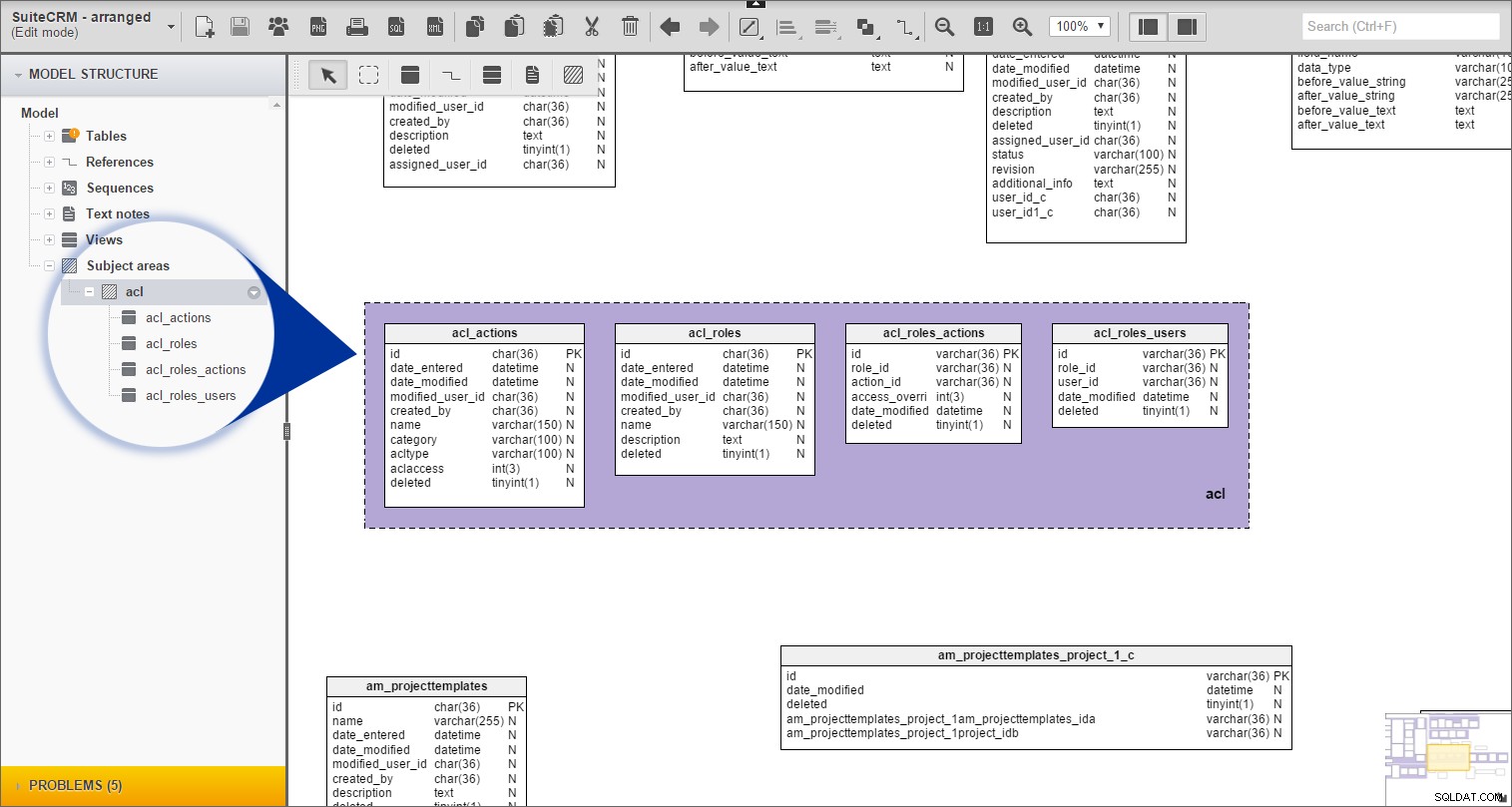
Ik herhaalde dezelfde procedure voor alle overige vooraf ingestelde tabellen.
Stap 3:Schik de resterende tabellen.
Tweemaal dezelfde tabel in het diagram? Tabelsnelkoppelingen!
Er zijn ongeveer 80 vooraf ingestelde tabellen. Nadat ik ze had gegroepeerd, hield ik ongeveer 120 'wilde' tafels over. Deze zijn zinvol:ze slaan informatie op over gebruikers, klanten, oproepen, vergaderingen en andere CRM-dingen. Dat is veel informatie om in het algemeen te bewaren, dus laten we deze tabellen op een rijtje zetten.
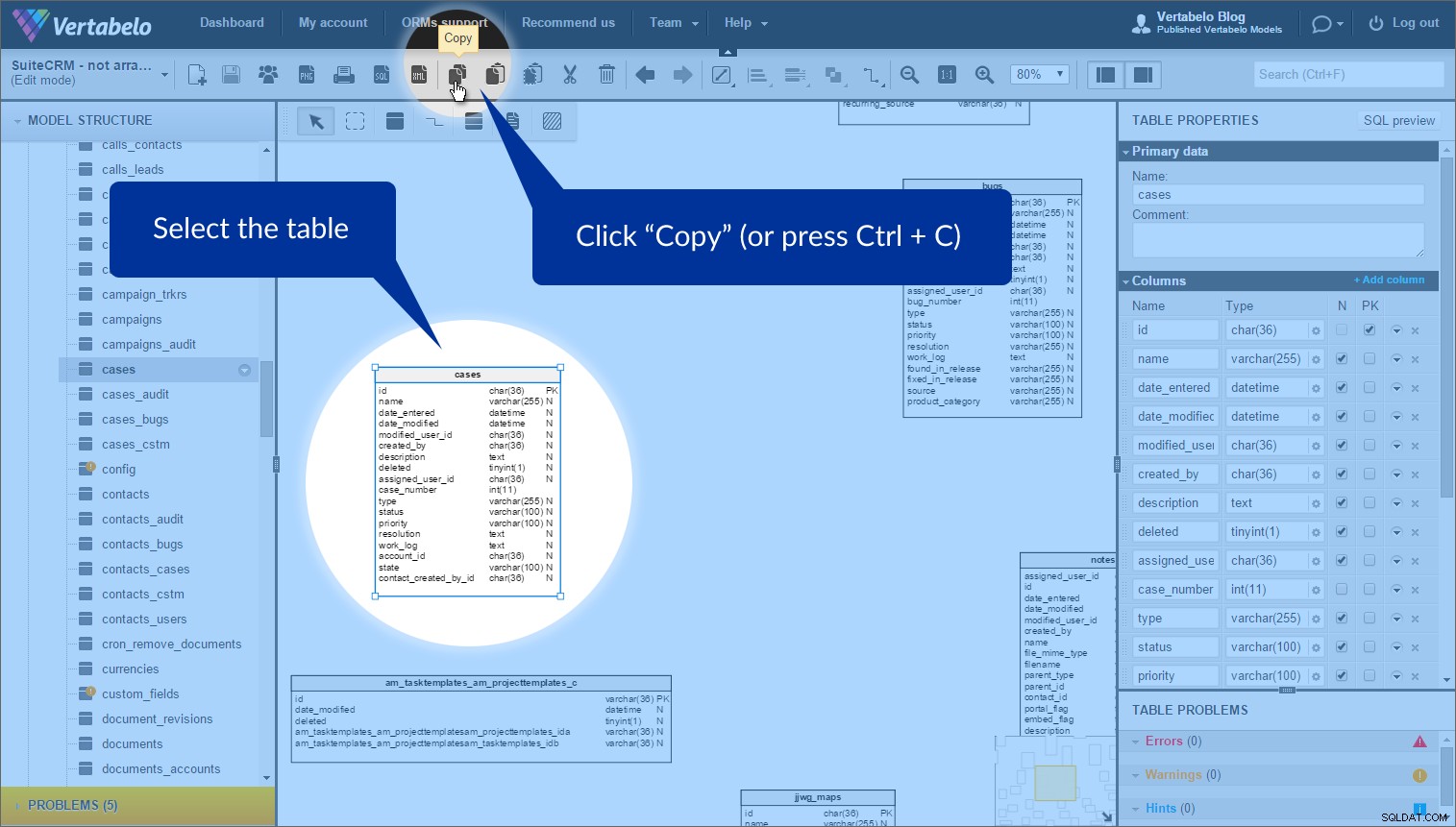
De functie die ik het handigst vond voor het ordenen van deze tabellen heet tabelsnelkoppelingen . Soms wilt u dezelfde tabel meer dan eens in een model gebruiken. (Waarom? Om het model af te vlakken en overlappingen te voorkomen.) We kunnen dit eenvoudig doen door de "Kopieer" te gebruiken en 'Plakken als snelkoppeling' knoppen.
Selecteer gewoon de tabel waarvoor u een snelkoppeling wilt maken en klik op “Kopiëren” in de bovenste werkbalk (of druk op Ctrl + C ):
Om een snelkoppeling te maken, klikt u op “Plakken als snelkoppeling” (of druk op Ctrl + K ). Daarna verschijnt een nieuwe tabel met een gestippelde omtrek:
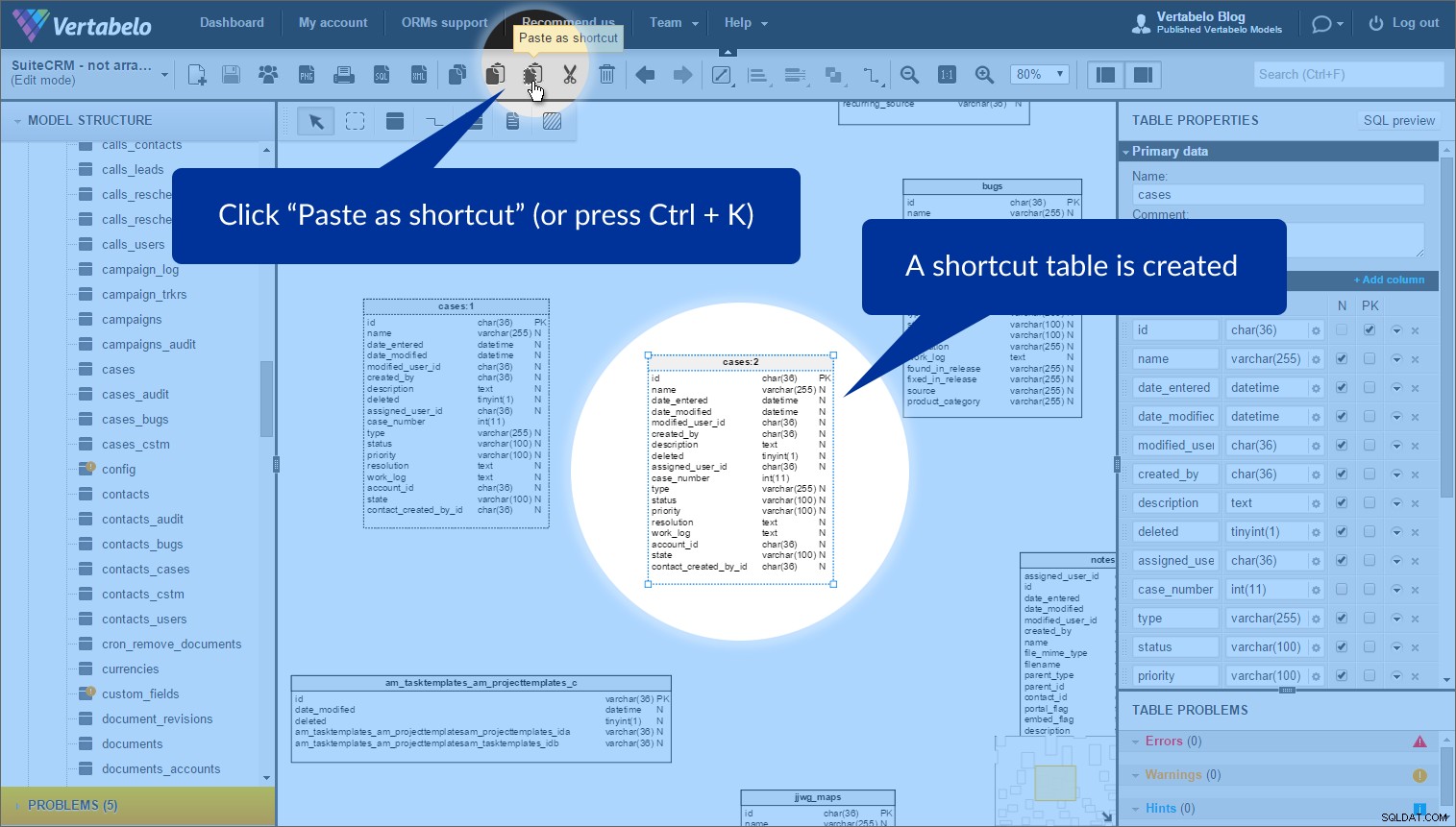
Dit is niet een kopie van de tabel, maar een ander exemplaar van de originele tabel. We kunnen het overal in ons model plaatsen. Ik heb exemplaren van dezelfde tabel in verschillende onderwerpgebieden gebruikt om overlappende verwijzingen te voorkomen. Het is de moeite waard om te vermelden dat elke tabelinstantie een toegewezen onderwerpgebiednaam heeft (naast de naam) terwijl het zich binnen dat onderwerpgebied bevindt.
Een goed voorbeeld van hoe dit werkt zijn de users tafel. Het is te vinden in "Gebruikers en accounts", "Rollen", "Documenten" en andere onderwerpen. We zullen dit later in het model zien.
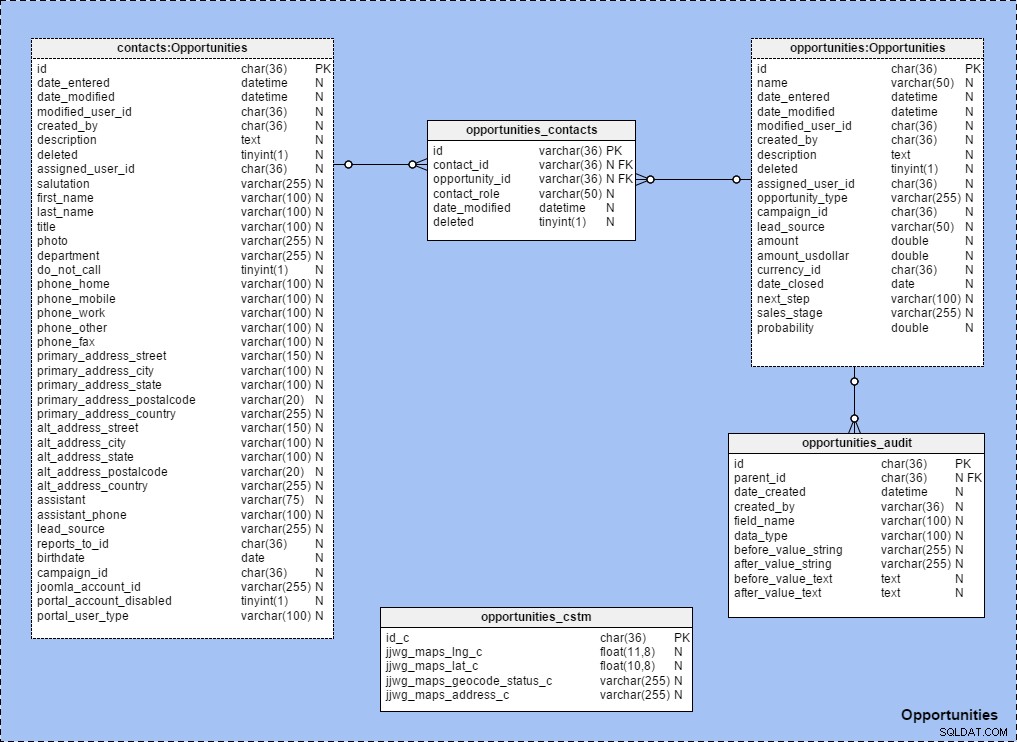
Ik gebruik veel sneltoetsen voor tabellen bij het maken van onderwerpgebieden met vaste relaties tussen tabellen. Om te zien hoe dit werkt, kijkt u naar het hieronder in kaart gebrachte onderwerp "Opportunities". Merk op dat alle tabellen binnen dat onderwerpgebied de volgende regel hebben:{tabelnaam} :{naam onderwerpgebied} .
Wanneer we de {subject area name} expand uitvouwen in het paneel "Modelstructuur" kunnen we duidelijk zien dat het tabellen en verwijzingen bevat:
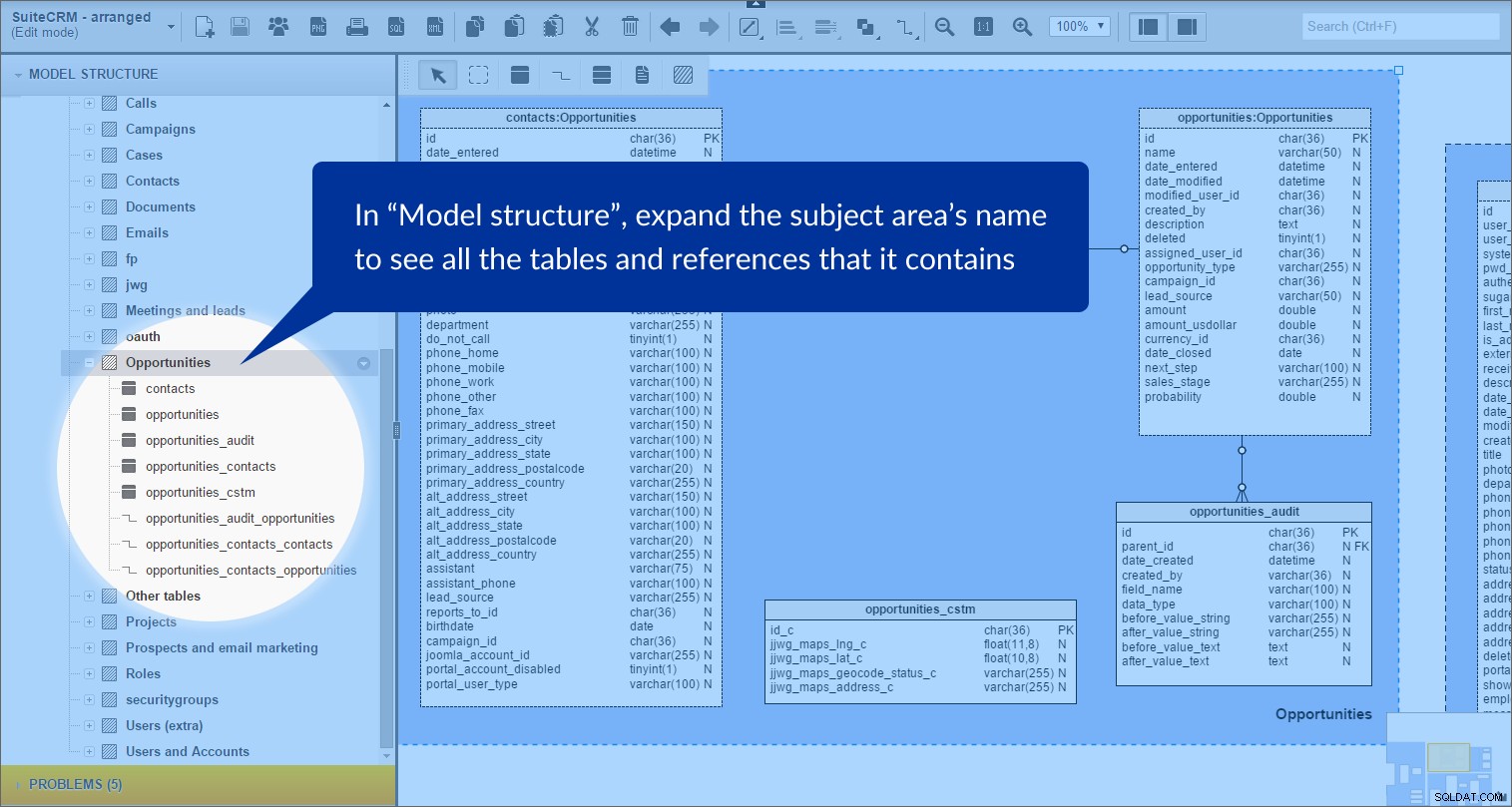
Dit deed ik voor de volgende vakgebieden:“Oproepen”, “Cases”, “Campagne”, “Contacten”, “Documenten”, “Vergadering en leads”, “oauth”, “Projecten”, “Prospects en e-mailmarketing”, "Rollen" en "Gebruikers en accounts". Al deze gebieden delen een lichtblauwe achtergrond.
De overige tabellen zijn gegroepeerd op basis van hun naam en vermoedelijke betekenis:"E-mails", "Gebruikers (extra)" en "Overige tabellen". Deze groepen hebben hun achtergrondkleur ingesteld op lichtrood.
Wanneer u dubbelklikt op een tabelnaam in de navigatiestructuur, zoomt de weergave naar die tabel in het model en selecteert deze. Wanneer u inzoomt door met het muiswiel te draaien, zoomt de weergave in de richting van de muisaanwijzer.Het gearrangeerde model
Ik heb de eerder beschreven opties gebruikt om het model zoveel mogelijk af te vlakken en tabellen logisch te groeperen. Het resultaat is 26 onderwerpgebieden, waarvan sommige alleen tabellen bevatten, terwijl andere tabellen en relaties hebben. Laten we elke categorie kort bekijken:
Onderwerpgebieden die tabellen en relaties bevatten:
"Oproepen", "Campagnes", "Cases", "Contacten", "Documenten", "Vergaderingen en leads", "Opportunities", "Projecten", "Vooruitzichten en e-mailmarketing", "Rollen", "Gebruikers en accounts"
Alle relaties zijn ingesteld als niet-verplicht. Hierdoor blijft de informatie behouden dat deze tabellen gerelateerd zijn en via welke attribuut(en).
Onderwerpgebieden die alleen tabellen bevatten:
“acl”, “am”, “aod”, “aok”, “aop”, “aor”, “aos”, “aow”, “E-mails”, “fp”, “jwg”, “oauth”, “security_groups ”, “Gebruikers extra”
Dit betekent niet dat er hier geen relaties bestaan; ze worden gewoon niet benadrukt.
Het onderwerpgebied "Andere tabellen" is voor tabellen die niet echt in een specifieke groep passen.
Hoe ziet het model eruit?
Het herschikte model ziet er als volgt uit:
Er is duidelijk een naamgevingsconventie gebruikt. Hier is een overzicht van de richtlijnen die we hebben gevolgd:
- Tabelnamen zijn meestal meervoud:
users,contracts,folders,roles,tasks. Sommige tabelnamen zijn enkelvoud, zoalsproject. - De primaire sleutel in de meeste tabellen heet gewoon
iden is van het type char(36). - Als een één-op-veel-relatie optreedt, wordt de refererende sleutel gewoonlijk
parent_idgenoemd . (Voorbeeld:contacts_audit.parent_idis een verwijzing naarcontacts.id.) - In veel-op-veel relaties, "
parent_id” kan niet worden gebruikt als naam voor meerdere kolommen. In plaats daarvan wordt een enkelvoudige tabelnaam met het achtervoegsel "_id" gebruikt. (Voorbeeld:contacts_bugs.bug_idis een verwijzing naarbug.id.) - Er zijn situaties waarin dezelfde kolom wordt gebruikt als externe sleutel voor meerdere tabellen. (Voorbeeld:
calls.parent_idwordt verwezen naar de id-kolom in elk van de volgende tabellen:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Ik heb de waarden in de database niet gecontroleerd, maar ik vermoed dat deze tabellen niet dezelfde sleutelwaarden bevatten. Aangezien ze allemaal van het type char(36) zijn, wordt waarschijnlijk een combinatie van tabelnaam en autoincrement gebruikt. We zullen dat controleren in komende artikelen.) - We gebruiken dezelfde namen voor kolommen die dezelfde betekenis hebben in verschillende tabellen. (Voorbeeld:
modified_user_id,created_byenassigned_user_idzijn in veel tabellen in het model terug te vinden. Ze verwijzen allemaal naarusers.id.)
Wat nu?
In de komende artikelen zullen we de SuiteCRM GUI gebruiken en de veranderingen die dit met zich meebrengt in de database in de gaten houden. Met die informatie proberen we het model aan te passen, vakgebieden te reorganiseren en waar nodig verbanden te leggen. We zoeken ook naar andere SuiteCRM-specifieke regels, zoals de manier waarop primaire sleutels worden gegenereerd.
Het verwerken van grote databasediagrammen is nooit een gemakkelijke taak. Net als het bouwen van een goede basis voor een huis, zal het nu meer tijd besteden aan de fundamenten later voordelen opleveren. Als we modellen willen analyseren zoals die achter SuiteCRM, is analyseren voordat we de modelstructuur en gedefinieerde tabelrelaties hebben georganiseerd, Sisyphus-stijl.