 Is het niet geweldig om een nieuwe versie van SQL Server beschikbaar te hebben? Dit is iets dat maar om de paar jaar gebeurt, en deze maand zagen we er één de algemene beschikbaarheid bereiken. (Ok, ik weet dat we bijna continu een nieuwe versie van SQL Database in Azure krijgen, maar ik reken dit als iets anders.) Deze nieuwe release erkennend, gaat de T-SQL-dinsdag van deze maand (gehost door Michael Swart – @mjswart) over alles wat met SQL Server 2016 te maken heeft!
Is het niet geweldig om een nieuwe versie van SQL Server beschikbaar te hebben? Dit is iets dat maar om de paar jaar gebeurt, en deze maand zagen we er één de algemene beschikbaarheid bereiken. (Ok, ik weet dat we bijna continu een nieuwe versie van SQL Database in Azure krijgen, maar ik reken dit als iets anders.) Deze nieuwe release erkennend, gaat de T-SQL-dinsdag van deze maand (gehost door Michael Swart – @mjswart) over alles wat met SQL Server 2016 te maken heeft!
Dus vandaag wil ik kijken naar de functie Temporal Tables van SQL 2016 en een aantal queryplansituaties bekijken die je zou kunnen zien. Ik ben dol op Temporal Tables, maar ben een beetje een probleem tegengekomen waarvan je misschien op de hoogte wilt zijn.
Nu, ondanks het feit dat SQL Server 2016 nu in RTM is, gebruik ik AdventureWorks2016CTP3, die je hier kunt downloaden – maar download niet alleen AdventureWorks2016CTP3.bak , pak ook SQLServer2016CTP3Samples.zip van dezelfde site.
U ziet dat er in het voorbeeldarchief enkele handige scripts zijn om nieuwe functies uit te proberen, waaronder enkele voor tijdelijke tabellen. Het is win-win - je kunt een heleboel nieuwe functies uitproberen, en ik hoef niet zoveel script in dit bericht te herhalen. Hoe dan ook, pak de twee scripts over Temporal Tables, met AW 2016 CTP3 Temporal Setup.sql , gevolgd door Temporal System-Versioning Sample.sql .
Deze scripts zetten tijdelijke versies van een paar tabellen op, waaronder HumanResources.Employee . Het creëert HumanResources.Employee_Temporal (hoewel het technisch gezien alles had kunnen heten). Aan het einde van de CREATE TABLE statement, verschijnt deze bit, waarbij twee verborgen kolommen worden toegevoegd om aan te geven wanneer de rij geldig is, en om aan te geven dat er een tabel moet worden gemaakt met de naam HumanResources.Employee_Temporal_History om de oude versies op te slaan.
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
Wat ik in dit bericht wil onderzoeken, is wat er gebeurt met queryplannen wanneer de geschiedenis wordt gebruikt.
Als ik de tabel doorzoek om de laatste rij te zien voor een bepaalde BusinessEntityID , krijg ik zoals verwacht een Clustered Index Seek.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
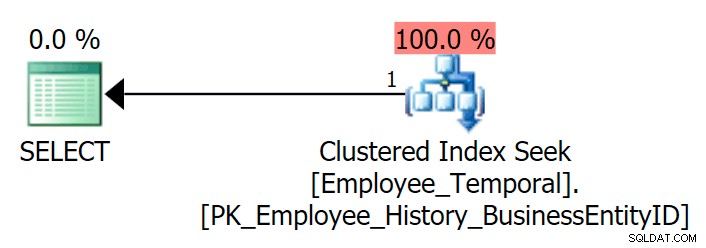
Ik weet zeker dat ik deze tabel zou kunnen opvragen met behulp van andere indexen, als die er waren. Maar in dit geval niet. Laten we er een maken.
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
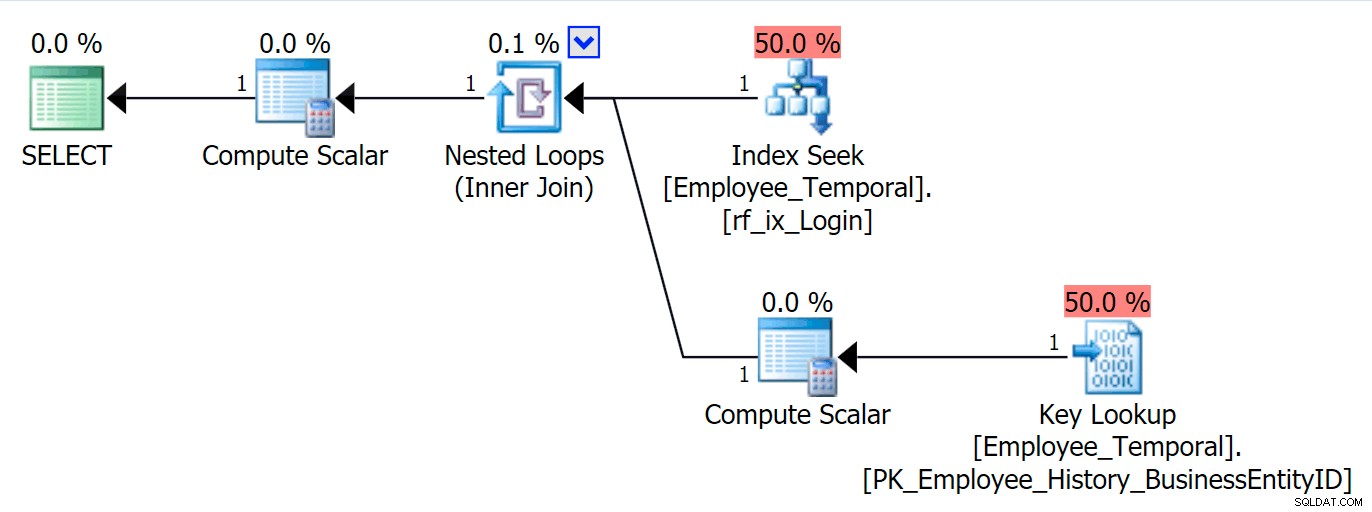
Nu kan ik de tabel opvragen door LoginID , en zal een Key Lookup zien als ik om andere kolommen vraag dan Loginid of BusinessEntityID . Dit is allemaal niet verrassend.
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
Laten we SQL Server Management Studio even gebruiken en eens kijken hoe deze tabel eruitziet in Object Explorer.

We kunnen de geschiedenistabel zien die wordt vermeld onder HumanResources.Employee_Temporal , en de kolommen en indexen van zowel de tabel zelf als de geschiedenistabel. Maar terwijl de indexen in de juiste tabel de primaire sleutel zijn (op BusinessEntityID ) en de index die ik zojuist had gemaakt, heeft de tabel Geschiedenis geen overeenkomende indexen.
De index op de geschiedenistabel staat op ValidTo en ValidFrom . We kunnen met de rechtermuisknop op de index klikken en Eigenschappen selecteren, en we zien dit dialoogvenster:
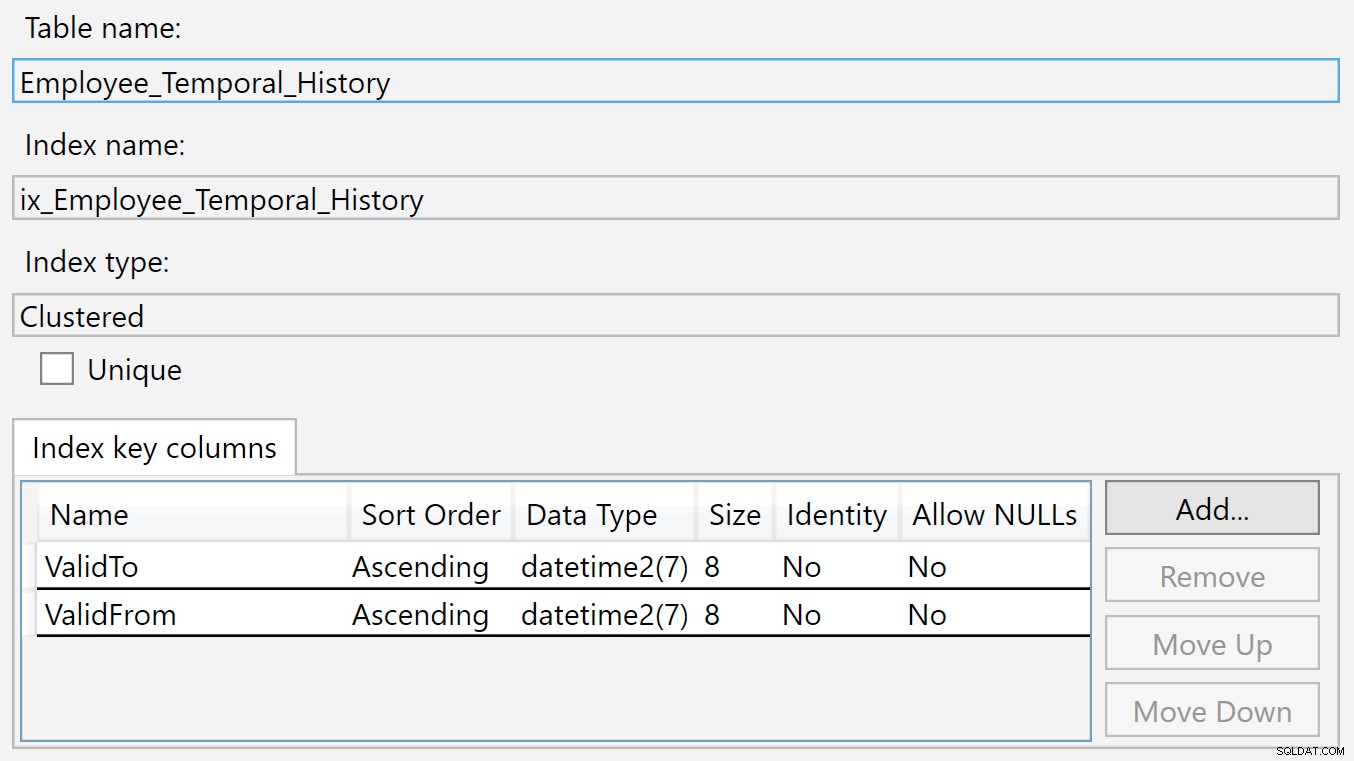
Een nieuwe rij wordt ingevoegd in deze geschiedenistabel wanneer deze niet langer geldig is in de hoofdtabel, omdat deze zojuist is verwijderd of gewijzigd. De waarden in de ValidTo kolom zijn natuurlijk gevuld met de huidige tijd, dus ValidTo fungeert als een oplopende sleutel, zoals een identiteitskolom, zodat nieuwe invoegingen aan het einde van de b-tree-structuur verschijnen.
Maar hoe werkt dit als je de tabel wilt opvragen?
Als we onze tabel willen opvragen voor wat er op een bepaald moment in de tijd was, dan zouden we een zoekstructuur moeten gebruiken zoals:
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
Deze query moet de juiste rijen uit de hoofdtabel samenvoegen met de juiste rijen uit de geschiedenistabel.
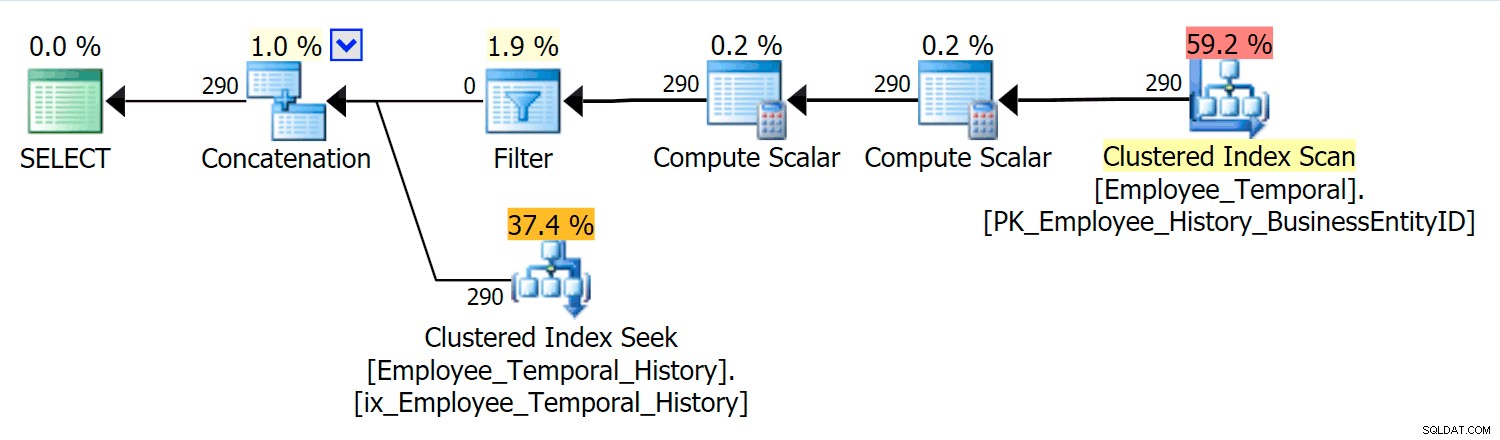
In dit scenario waren de rijen die geldig waren op het moment dat ik koos allemaal uit de geschiedenistabel, maar desalniettemin zien we een geclusterde indexscan tegen de hoofdtabel, die werd gefilterd door een filteroperator. Het predikaat van dit filter is:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Laten we dit zo nog eens bekijken.
De Clustered Index Seek in de History-tabel moet duidelijk gebruikmaken van een Seek-predicaat op ValidTo. Het begin van de zoekbereikscan is HumanResources.Employee_Temporal_History.ValidTo > Scalaire operator ('2016-06-12 11:22:00') , maar er is geen End, omdat elke rij een ValidTo . heeft na de tijd waar we om geven is een kandidatenrij en moet worden getest op een geschikte ValidFrom waarde door het resterende predikaat, dat is HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Nu zijn intervallen moeilijk te indexeren; dat is een bekend iets dat op veel blogs is besproken. De meest effectieve oplossingen zijn creatieve manieren om query's te schrijven, maar dergelijke slimmigheden zijn niet ingebouwd in Temporal Tables. U kunt echter ook indexen op andere kolommen plaatsen, zoals op ValidFrom, of zelfs indexen hebben die overeenkomen met de soorten query's die u op de hoofdtabel zou kunnen hebben. Met een geclusterde index als samengestelde sleutel op beide ValidTo en ValidFrom , worden deze twee kolommen in elke andere kolom opgenomen, wat een goede gelegenheid biedt voor wat restpredikaattests.
Als ik weet in welke login-id ik geïnteresseerd ben, krijgt mijn plan een andere vorm.
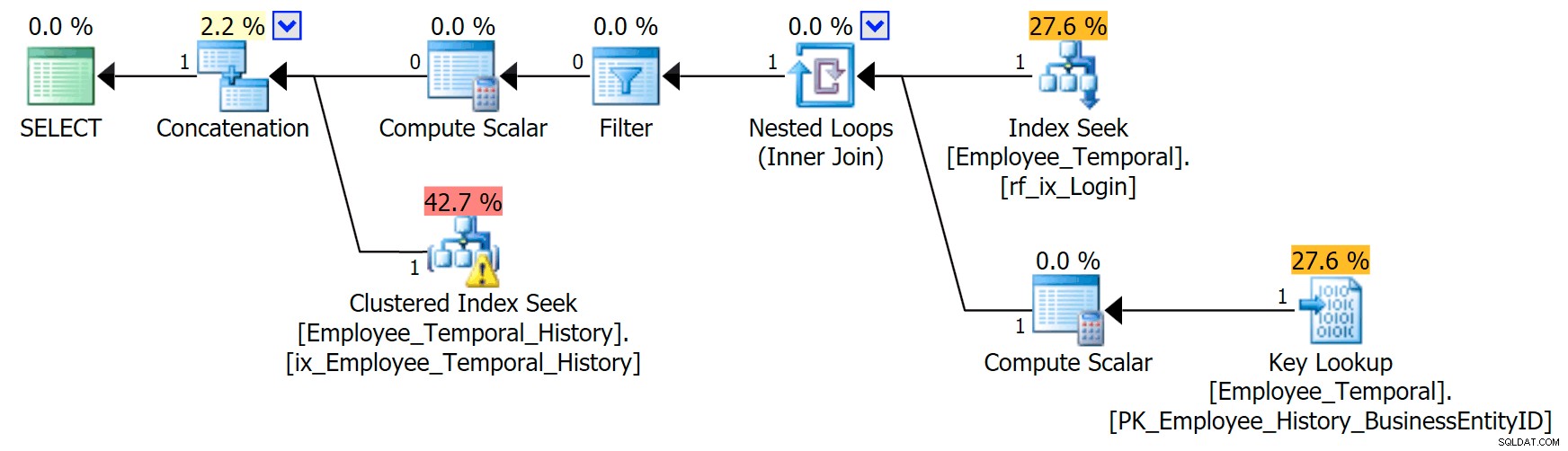
De bovenste tak van de aaneenschakelingsoperator ziet er hetzelfde uit als voorheen, hoewel die filteroperator de strijd is aangegaan om alle ongeldige rijen te verwijderen, maar de geclusterde indexzoekfunctie op de onderste tak heeft een waarschuwing. Dit is een waarschuwing voor een resterend predikaat, zoals de voorbeelden in een eerdere post van mij. Het kan filteren op vermeldingen die geldig zijn tot een bepaald punt na de tijd waar we om geven, maar het Resterende predikaat filtert nu naar de LoginID evenals ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Wijzigingen in de rijen van rob0 zullen een klein deel van de rijen in de geschiedenis zijn. Deze kolom zal niet uniek zijn zoals in de hoofdtabel, omdat de rij misschien meerdere keren is gewijzigd, maar er is nog steeds een goede kandidaat voor indexering.
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
Deze nieuwe index heeft een opmerkelijk effect op ons plan.
Het is nu veranderd onze Clustered Index Seek in een Clustered Index Scan!!
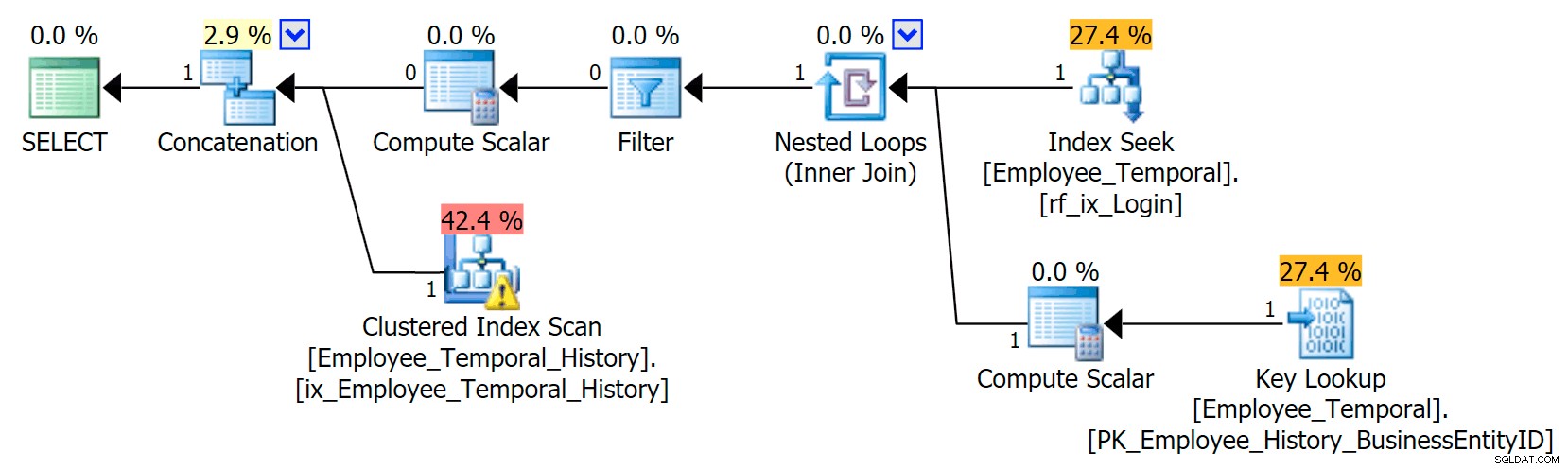
U ziet dat de Query Optimizer nu uitwerkt dat u het beste de nieuwe index kunt gebruiken. Maar het besluit ook dat de moeite om opzoekingen te doen om alle andere kolommen te krijgen (omdat ik om alle kolommen vroeg) gewoon te veel werk zou zijn. Het omslagpunt was bereikt (helaas een onjuiste veronderstelling in dit geval), en in plaats daarvan werd gekozen voor een Clustered Index SCAN. Ook al zou het zonder de niet-geclusterde index de beste optie zijn geweest om een geclusterde index te gebruiken, wanneer de niet-geclusterde index is overwogen en afgewezen vanwege omslagpuntredenen, kiest deze ervoor om te scannen.
Frustrerend genoeg heb ik deze index nog maar net gemaakt en de statistieken zouden goed moeten zijn. Het zou moeten weten dat een zoekactie die precies één zoekopdracht vereist, beter zou moeten zijn dan een geclusterde indexscan (alleen op basis van statistieken - als u dacht dat het dit zou moeten weten omdat LoginID uniek is in de hoofdtabel, onthoud dat dit niet altijd zo is geweest). Dus ik vermoed dat zoekacties in geschiedenistabellen vermeden moeten worden, hoewel ik hier nog niet genoeg onderzoek naar heb gedaan.
Als we nu alleen kolommen zouden opvragen die in onze niet-geclusterde index voorkomen, zouden we veel beter gedrag krijgen. Nu er geen opzoeking nodig is, wordt onze nieuwe index op de geschiedenistabel graag gebruikt. Het moet nog steeds een restpredicaat toepassen op basis van alleen kunnen filteren op LoginID en ValidTo , maar het gedraagt zich veel beter dan in een geclusterde indexscan te vallen.
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
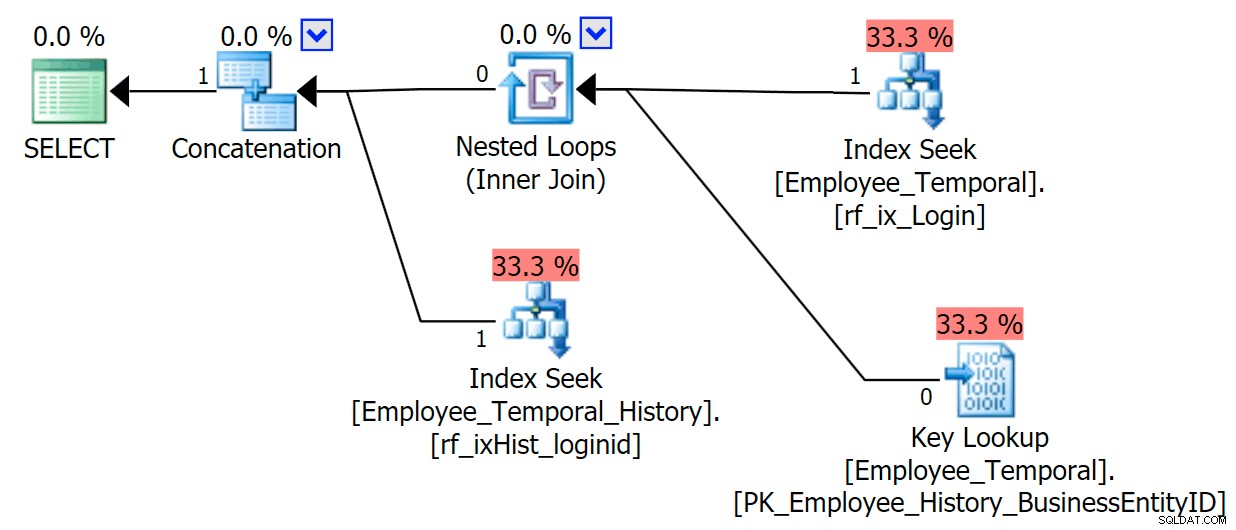
Dus indexeer uw geschiedenistabellen op extra manieren, rekening houdend met hoe u ze gaat opvragen. Voeg de nodige kolommen toe om zoekacties te vermijden, want u vermijdt echt scans.
Deze geschiedenistabellen kunnen groot worden als gegevens regelmatig veranderen. Houd er dus rekening mee hoe ze worden behandeld. Dezelfde situatie doet zich voor bij gebruik van de andere FOR SYSTEM_TIME constructies, dus u moet (zoals altijd) de plannen die uw zoekopdrachten produceren, bekijken en indexeren om er zeker van te zijn dat u goed gepositioneerd bent om gebruik te maken van wat een zeer krachtige functie van SQL Server 2016 is.