Opmerking:dit bericht is oorspronkelijk alleen gepubliceerd in ons eBook, High Performance Techniques for SQL Server, Volume 2. U kunt hier meer informatie vinden over onze eBooks.
Samenvatting:dit artikel onderzoekt een aantal verrassende gedragingen van INSTEAD OF triggers en onthult een ernstige fout bij het schatten van kardinaliteit in SQL Server 2014.
Triggers en rijversies
Alleen DML AFTER-triggers gebruiken rijversiebeheer (vanaf SQL Server 2005) om de ingevoegde en verwijderd pseudo-tabellen binnen een triggerprocedure. Dit punt wordt niet duidelijk gemaakt in veel van de officiële documentatie. Op de meeste plaatsen zegt de documentatie eenvoudig dat rijversiebeheer wordt gebruikt om de ingevoegde . te bouwen en verwijderd tabellen in triggers zonder kwalificatie (voorbeelden hieronder):
Gebruik van bronnen voor rijversies
Inzicht krijgen in op rijversies gebaseerde isolatieniveaus
Triggeruitvoering controleren bij bulksgewijs importeren van gegevens
Vermoedelijk zijn de originele versies van deze vermeldingen geschreven voordat IN PLAATS VAN triggers aan het product werden toegevoegd, en nooit bijgewerkt. Of dat, of het is een simpele (maar herhaalde) vergissing.
Hoe dan ook, de manier waarop rij-versiebeheer werkt met AFTER-triggers is vrij intuïtief. Deze triggers vuren na de wijzigingen in kwestie zijn uitgevoerd, dus het is gemakkelijk te zien hoe het onderhouden van versies van de gewijzigde rijen de database-engine in staat stelt om de ingevoegde en verwijderd pseudo-tabellen. De verwijderde pseudo-tabel is opgebouwd uit versies van de betrokken rijen voordat de wijzigingen plaatsvonden; de ingevoegde pseudo-tabel wordt gevormd uit de versies van de betrokken rijen op het moment dat de triggerprocedure begon.
In plaats van triggers
IN PLAATS VAN triggers zijn anders omdat dit type DML-trigger volledig vervangt de geactiveerde actie. De ingevoegde en verwijderd pseudo-tabellen vertegenwoordigen nu veranderingen die zou hebben gemaakt, was de triggering-instructie daadwerkelijk uitgevoerd. Rijversiebeheer kan niet worden gebruikt voor deze triggers omdat er per definitie geen wijzigingen zijn opgetreden. Dus, als er geen rijversies worden gebruikt, hoe doet SQL Server dat dan?
Het antwoord is dat SQL Server het uitvoeringsplan voor de activerende DML-instructie wijzigt wanneer er een INSTEAD OF-trigger bestaat. In plaats van de betrokken tabellen rechtstreeks te wijzigen, schrijft het uitvoeringsplan informatie over de wijzigingen naar een verborgen werktabel. Deze werktabel bevat alle gegevens die nodig zijn om de oorspronkelijke wijzigingen uit te voeren, het type wijziging dat op elke rij moet worden uitgevoerd (verwijderen of invoegen), evenals alle informatie die nodig is in de trigger voor een OUTPUT-clausule.
Uitvoeringsplan zonder trigger
Om dit alles in actie te zien, zullen we eerst een eenvoudige test uitvoeren zonder dat er een IN PLAATS VAN een trigger aanwezig is:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Het uitvoeringsplan voor het verwijderen is heel eenvoudig:
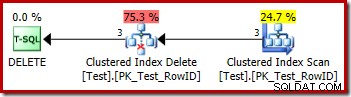
Elke rij die in aanmerking komt, wordt rechtstreeks doorgegeven aan een Clustered Index Delete-operator, die deze verwijdert. Makkelijk.
Uitvoeringsplan met een IN PLAATS VAN trigger
Laten we nu de test aanpassen om een INSTEAD OF DELETE-trigger op te nemen (een die voor de eenvoud dezelfde verwijderactie uitvoert):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Het uitvoeringsplan voor de DELETE is nu heel anders:
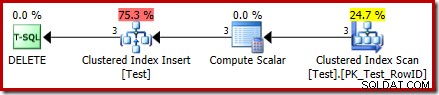
De operator Clustered Index Delete is vervangen door een Clustered Index Invoegen . Dit is de invoeging van de verborgen werktabel, die hernoemd is (in de weergave van het openbare uitvoeringsplan) naar de naam van de basistabel die wordt beïnvloed door de verwijdering. Het hernoemen vindt plaats wanneer het XML-showplan wordt gegenereerd op basis van de interne uitvoeringsplanweergave, dus er is geen gedocumenteerde manier om de verborgen werktabel te zien.
Als gevolg van deze wijziging lijkt het plan daarom een insert . uit te voeren naar de basistabel om te verwijderen rijen ervan. Dit is verwarrend, maar het onthult in ieder geval de aanwezigheid van een IN PLAATS VAN trigger. Het vervangen van de operator Insert door een Delete kan nog verwarrender zijn. Misschien is het ideaal een nieuw grafisch pictogram voor een IN PLAATS VAN een trigger-werktafel? Hoe dan ook, het is wat het is.
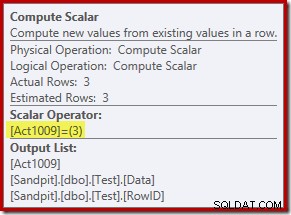
De nieuwe Compute Scalar-operator definieert het type actie dat op elke rij wordt uitgevoerd. Deze actiecode is een geheel getal, met de volgende betekenissen:
- 3 =VERWIJDEREN
- 4 =INSERT
- 259 =VERWIJDEREN in een SAMENVOEGEN abonnement
- 260 =INSERT in een MERGE-abonnement
Voor deze zoekopdracht is de actie een constante 3, wat betekent dat elke rij moet worden verwijderd :
Acties bijwerken
Even terzijde, een IN PLAATS VAN UPDATE-uitvoeringsplan vervangt een enkele Update-operator door twee Geclusterde index voegt toe aan dezelfde verborgen werktabel – een voor de ingevoegde pseudo-tabelrijen, en één voor de verwijderde pseudo-tabel rijen. Een voorbeeld uitvoeringsplan:

EEN MERGE die een UPDATE uitvoert, produceert om vergelijkbare redenen ook een uitvoeringsplan met twee toevoegingen aan dezelfde basistabel:

Het trigger-uitvoeringsplan
Het uitvoeringsplan voor de triggerbody heeft ook enkele interessante functies:
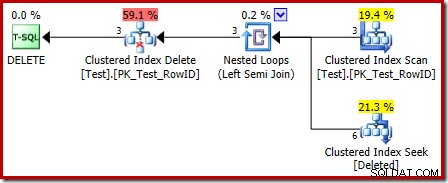
Het eerste dat opvalt, is dat het grafische pictogram dat wordt gebruikt voor de verwijderde tabel niet hetzelfde is als het pictogram dat wordt gebruikt in AFTER-triggerplannen:
De weergave in het INSTEAD OF triggerplan is een Clustered Index Seek. Het onderliggende object is dezelfde interne werktabel die we eerder zagen, maar hier heet het deleted in plaats van de naam van de basistabel te krijgen, vermoedelijk voor een soort van consistentie met AFTER-triggers.
De zoekbewerking op de verwijderde tabel is misschien niet wat u verwachtte (als u een zoekopdracht op RowID verwachtte):
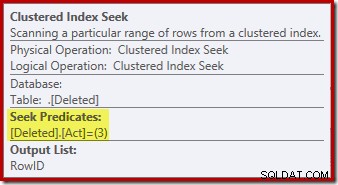
Dit 'zoeken' retourneert alle rijen uit de werktabel die een actiecode van 3 (verwijderen) hebben, waardoor deze exact gelijk is aan de Deleted Scan operator gezien in NA triggerplannen. Dezelfde interne werktabel wordt gebruikt om rijen te bewaren voor beide ingevoegde en verwijderd pseudo-tabellen in IN PLAATS VAN triggers. Het equivalent van een Ingevoegde scan is een zoekactie op actiecode 4 (wat mogelijk is in een delete trigger, maar het resultaat is altijd leeg). Er zijn geen indexen op de interne werktabel, afgezien van de niet-unieke geclusterde index op de actie kolom alleen. Bovendien zijn er geen statistieken gekoppeld aan deze interne index.
De analyse tot nu toe doet je misschien afvragen waar de join tussen de RowID-kolommen wordt uitgevoerd. Deze vergelijking vindt plaats bij de operator Nested Loops Left Semi Join als een residuaal predikaat:
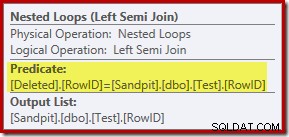
Nu we weten dat het 'zoeken' in feite een volledige scan is van de verwijderde tabel, lijkt het uitvoeringsplan dat is gekozen door de query-optimizer behoorlijk inefficiënt. De algemene stroom van het uitvoeringsplan is dat elke rij uit de testtabel potentieel wordt vergeleken met de volledige set van verwijderde rijen, wat veel lijkt op een cartesiaans product.
De goedmaker is dat de join een semi-join is, wat betekent dat het vergelijkingsproces voor een bepaalde testrij stopt zodra de eerste verwijderd rij voldoet aan het residuaal predikaat. Toch lijkt de strategie merkwaardig. Misschien zou het uitvoeringsplan beter zijn als de testtabel meer rijen bevatte?
Triggertest met 1.000 rijen
Het volgende script kan worden gebruikt om de trigger te testen met een groter aantal rijen. We beginnen met 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Het uitvoeringsplan voor de triggerbody is nu:
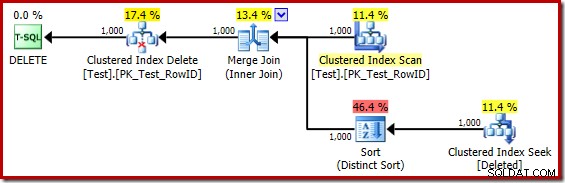
Door de (misleidende) Clustered Index Seek mentaal te vervangen door een Deleted Scan, ziet het plan er over het algemeen redelijk goed uit. De optimizer heeft gekozen voor een één-op-veel Merge Join in plaats van een Nested Loops Semi Join, wat redelijk lijkt. The Distinct Sort is echter een merkwaardige toevoeging:
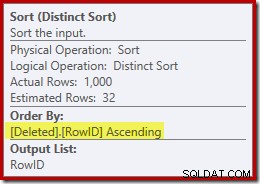
Deze soort vervult twee functies. Ten eerste voorziet het de merge-join van de gesorteerde invoer die het nodig heeft, wat redelijk genoeg is omdat er geen index op de interne werktafel is om de noodzakelijke volgorde te bieden. Het tweede dat de soort doet, is onderscheid maken op RowID. Dit lijkt misschien vreemd, omdat RowID de primaire sleutel is van de basistabel.
Het probleem is dat rijen in de verwijderde tabel zijn gewoon kandidaat-rijen die de oorspronkelijke DELETE-query identificeerde. In tegenstelling tot een AFTER-trigger, zijn deze rijen nog niet gecontroleerd op beperkingen of sleutelovertredingen, dus de queryprocessor heeft geen garantie dat ze in feite uniek zijn.
Over het algemeen is dit een zeer belangrijk punt om in gedachten te houden met INSTEAD OF triggers:er is geen garantie dat de aangeboden rijen voldoen aan een van de beperkingen op de basistabel (inclusief NOT NULL). Dit is niet alleen belangrijk voor de triggerauteur om te onthouden; het beperkt ook de vereenvoudigingen en transformaties die de query-optimizer kan uitvoeren.
Een tweede probleem dat wordt weergegeven in de sorteereigenschappen hierboven, maar niet is gemarkeerd, is dat de geschatte uitvoer slechts 32 rijen is. Aan de interne werktabel zijn geen statistieken gekoppeld, dus de optimizer gissingen ten gevolge van de Distinct operatie. We 'weten' dat de RowID-waarden uniek zijn, maar zonder harde informatie om verder te gaan, maakt de optimizer een slechte gok. Dit probleem zal ons in de volgende test blijven achtervolgen.
Triggertest met 5.000 rijen
Pas nu het testscript aan om 5.000 rijen te genereren:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; Het trigger-uitvoeringsplan is:
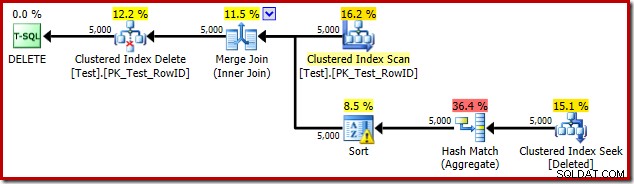
Deze keer heeft de optimizer besloten om de onderscheiden- en sorteerbewerkingen te splitsen. Het onderscheiden op RowID wordt uitgevoerd door de Hash Match (Aggregate) operator:
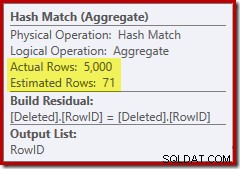
Merk op dat de schatting van de optimizer voor de uitvoer 71 rijen is. In feite overleven alle 5.000 rijen de verschillende omdat RowID uniek is. De onnauwkeurige schatting betekent dat een onvoldoende deel van de toekenning van het querygeheugen aan de Sort wordt toegewezen, wat uiteindelijk terechtkomt bij tempdb :
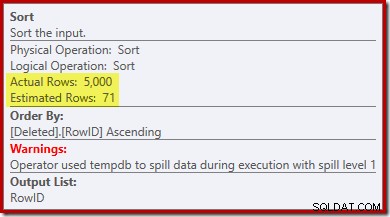
Deze test moet worden uitgevoerd op SQL Server 2012 of hoger om de sorteerwaarschuwing in het uitvoeringsplan te zien. In eerdere versies bevat het plan geen informatie over lekkages - een Profiler-tracering op de Sort Warnings-gebeurtenis zou nodig zijn om het te onthullen (en u zou dat op de een of andere manier moeten correleren met de bronquery).
Triggertest met 5.000 rijen op SQL Server 2014
Als de vorige test wordt herhaald op SQL Server 2014, in een database die is ingesteld op compatibiliteitsniveau 120, zodat de nieuwe kardinaliteitsschatter (CE) wordt gebruikt, is het triggeruitvoeringsplan weer anders:
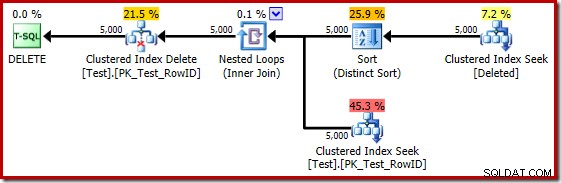
In sommige opzichten lijkt dit uitvoeringsplan een verbetering. De (onnodige) Distinct Sort is er nog steeds, maar de algemene strategie lijkt natuurlijker:voor elke afzonderlijke kandidaat RowID in de verwijderde tabel, voeg u bij de basistabel (dus controleer of de kandidaatrij echt bestaat) en verwijder deze vervolgens.
Helaas is het plan voor 2014 gebaseerd op slechtere kardinaliteitsschattingen dan we zagen in SQL Server 2012. Schakelen tussen SQL Sentry Plan Explorer om de geschatte weer te geven rijtellingen laten het probleem duidelijk zien:
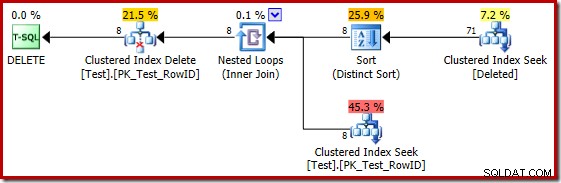
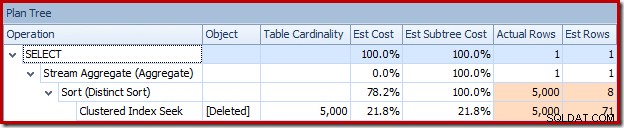
De optimizer koos een strategie voor geneste lussen voor de join omdat het een zeer klein aantal rijen op de bovenste invoer verwachtte. Het eerste probleem doet zich voor bij de Clustered Index Seek. De optimizer weet dat de verwijderde tabel op dit moment 5.000 rijen bevat, zoals we kunnen zien door over te schakelen naar de Plan Tree-weergave en de optionele kolom Tabelkardinaliteit toe te voegen (waarvan ik zou willen dat deze standaard was opgenomen):
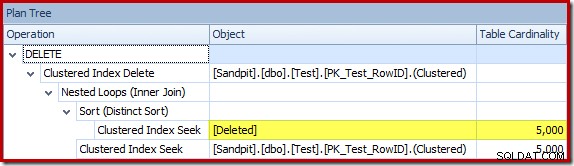
De 'oude' kardinaliteitsschatter in SQL Server 2012 en eerder is slim genoeg om te weten dat de 'seek' op de interne werktabel alle 5.000 rijen zou opleveren (dus koos het voor een merge-join). De nieuwe CE is niet zo slim. Het ziet de werktafel als een 'zwarte doos' en gokt op het effect van het zoeken op actiecode =3:
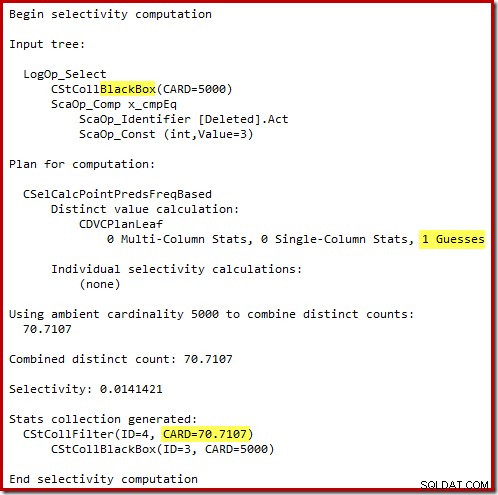
De schatting van 71 rijen (naar boven afgerond) is een behoorlijk miserabele uitkomst, maar de fout wordt nog groter wanneer de nieuwe CE de rijen schat voor de afzonderlijke bewerking op die 71 rijen:
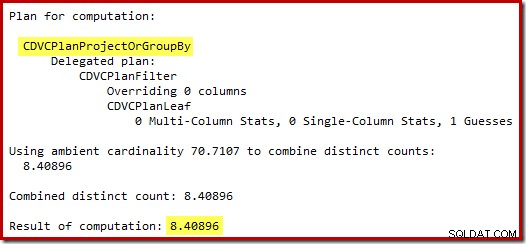
Op basis van de verwachte 8 rijen kiest de optimizer de Nested Loops-strategie. Een andere manier om deze schattingsfouten te zien, is door de volgende instructie aan de triggerbody toe te voegen (alleen voor testdoeleinden):
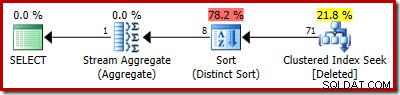
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
Het geschatte plan toont de schattingsfouten duidelijk:
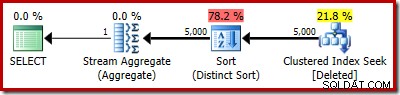
Het werkelijke plan toont natuurlijk nog steeds 5.000 rijen:
Of u kunt de schatting tegelijkertijd met de werkelijke vergelijken in de Plan Tree-weergave:
Een miljoen rijen...
De slechte schattingen bij gebruik van de kardinaliteitsschatter van 2014 zorgen ervoor dat de optimizer een strategie voor geneste lussen selecteert, zelfs als de testtabel een miljoen rijen bevat. De nieuwe CE van 2014 geschat plan voor die test is:
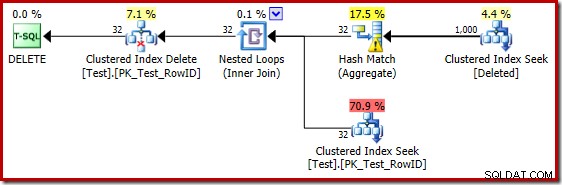
De 'zoeken' schat 1.000 rijen van de bekende kardinaliteit van 1.000.000 en de duidelijke schatting is 32 rijen. Het post-uitvoeringsplan onthult het effect op het geheugen dat is gereserveerd voor de Hash Match:
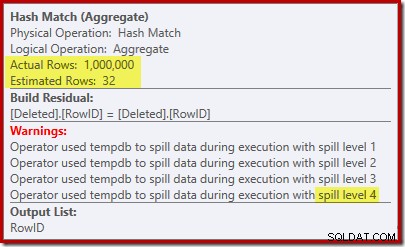
Met slechts 32 rijen verwacht, komt de Hash Match in de problemen, waarbij recursief de hash-tabel wordt gemorst voordat hij uiteindelijk wordt voltooid.
Laatste gedachten
Hoewel het waar is dat een trigger nooit mag worden geschreven om iets te doen dat kan worden bereikt met declaratieve referentiële integriteit, is het ook waar dat een goed geschreven trigger die een efficiënte . gebruikt uitvoeringsplan kan qua prestaties vergelijkbaar zijn met de kosten van het onderhouden van een extra niet-geclusterde index.
Er zijn twee praktische problemen met de bovenstaande verklaring. Ten eerste (en met de beste wil van de wereld) schrijven mensen niet altijd goede triggercode. Ten tweede kan het moeilijk zijn om onder alle omstandigheden een goed uitvoeringsplan van de query-optimizer te krijgen. De aard van triggers is dat ze worden aangeroepen met een breed scala aan invoerkardinaliteiten en gegevensdistributies.
Zelfs voor AFTER-triggers, het ontbreken van indexen en statistieken over de verwijderde en ingevoegd pseudo-tabellen betekent dat de selectie van plannen vaak gebaseerd is op gissingen of verkeerde informatie. Zelfs wanneer in eerste instantie een goed plan is gekozen, kunnen latere uitvoeringen hetzelfde plan opnieuw gebruiken wanneer een hercompilatie een betere keuze zou zijn geweest. Er zijn manieren om de beperkingen te omzeilen, voornamelijk door het gebruik van tijdelijke tabellen en expliciete indexen/statistieken, maar zelfs daar is grote voorzichtigheid geboden (aangezien triggers een vorm van opgeslagen procedure zijn).
Met INSTEAD OF triggers kunnen de risico's nog groter zijn omdat de inhoud van de ingevoegde en verwijderd tabellen zijn niet-geverifieerde kandidaten - de query-optimizer kan geen beperkingen op de basistabel gebruiken om het uitvoeringsplan te vereenvoudigen en te verfijnen. De nieuwe kardinaliteitsschatter in SQL Server 2014 vertegenwoordigt ook een echte stap terug als het gaat om IN PLAATS VAN triggerplannen. Gissen naar het effect van een zoekactie die de motor zelf introduceerde, is een verrassende en onwelkome vergissing.