JPA (Java-persistentie-annotatie ) is de standaardoplossing van Java om de kloof tussen objectgeoriënteerde domeinmodellen en relationele databasesystemen te overbruggen. Het idee is om Java-klassen toe te wijzen aan relationele tabellen en eigenschappen van die klassen aan de rijen in de tabel. Dit verandert de semantiek van de algehele ervaring van Java-codering door twee verschillende technologie naadloos samen te laten werken binnen hetzelfde programmeerparadigma. Dit artikel geeft een overzicht en de ondersteunende implementatie in Java.
Een overzicht
Relationele databases zijn misschien wel de meest stabiele van alle persistentietechnologieën die beschikbaar zijn in computergebruik in plaats van alle complexiteit die ermee gepaard gaat. Dat komt omdat vandaag, zelfs in het tijdperk van zogenaamde "big data", "NoSQL" relationele databases constant in trek en bloeiend zijn. Relationele databases zijn stabiele technologie, niet alleen door woorden, maar door het bestaan ervan door de jaren heen. NoSQL is misschien goed voor het verwerken van grote hoeveelheden gestructureerde gegevens in de onderneming, maar de talrijke transactionele workloads kunnen beter worden afgehandeld via relationele databases. Er zijn ook enkele geweldige analytische tools die zijn gekoppeld aan relationele databases.
Om te communiceren met relationele databases heeft ANSI een taal gestandaardiseerd genaamd SQL (Gestructureerde Query-taal ). Een verklaring die in deze taal is geschreven, kan zowel worden gebruikt voor het definiëren als voor het manipuleren van gegevens. Maar het probleem van SQL bij het omgaan met Java is dat ze een niet-overeenkomende syntactische structuur hebben en in de kern heel anders zijn, wat betekent dat SQL procedureel is, terwijl Java objectgeoriënteerd is. Er wordt dus gezocht naar een werkende oplossing zodat Java objectgeoriënteerd kan spreken en de relationele database elkaar toch zou kunnen verstaan. JPA is het antwoord op die oproep en biedt het mechanisme om een werkende oplossing tussen de twee tot stand te brengen.
Relatief met objecttoewijzing
Java-programma's werken samen met relationele databases met behulp van de JDBC (Java Database-connectiviteit )-API. Een JDBC-stuurprogramma is de sleutel tot de connectiviteit en stelt een Java-programma in staat om die database te manipuleren met behulp van de JDBC API. Zodra de verbinding tot stand is gebracht, vuurt het Java-programma SQL-query's af in de vorm van String s om te communiceren over het maken, invoegen, bijwerken en verwijderen van bewerkingen. Dit is voldoende voor alle praktische doeleinden, maar onhandig vanuit het oogpunt van een Java-programmeur. Wat als de structuur van relationele tabellen kan worden omgevormd tot pure Java-klassen en je ze dan op de gebruikelijke objectgeoriënteerde manier kunt behandelen? De structuur van een relationele tabel is een logische weergave van gegevens in tabelvorm. Tabellen zijn samengesteld uit kolommen die entiteitskenmerken beschrijven en rijen zijn de verzameling entiteiten. Een WERKNEMER-tabel kan bijvoorbeeld de volgende entiteiten met hun kenmerken bevatten.
| Emp_number | Naam | dept_no | Salaris | Plaats |
| 112233 | Peter | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Rijen zijn uniek per primaire sleutel (emp_number) binnen een tabel; dit maakt snel zoeken mogelijk. Een tabel kan gerelateerd zijn aan een of meer tabellen door een sleutel, zoals een externe sleutel (dept_no), die betrekking heeft op de equivalente rij in een andere tabel.
Volgens de Java Persistence 2.1-specificatie voegt JPA ondersteuning toe voor het genereren van schema's, typeconversiemethoden, het gebruik van entiteitsgrafieken in query's en zoekbewerkingen, niet-gesynchroniseerde persistentiecontext, het aanroepen van opgeslagen procedures en injectie in entiteitslistenerklassen. Het bevat ook verbeteringen aan de Java Persistence-querytaal, de Criteria API en de mapping van native queries.
Kortom, het doet er alles aan om de illusie te wekken dat er geen procedurele rol is bij het omgaan met relationele databases en dat alles objectgeoriënteerd is.
JPA-implementatie
JPA beschrijft relationeel gegevensbeheer in Java-toepassing. Het is een specificatie en er zijn een aantal implementaties van. Enkele populaire implementaties zijn Hibernate, EclipseLink en Apache OpenJPA. JPA definieert de metadata via annotaties in Java-klassen of via XML-configuratiebestanden. We kunnen echter zowel XML als annotatie gebruiken om de metadata te beschrijven. In een dergelijk geval overschrijft de XML-configuratie de annotaties. Dit is redelijk omdat annotaties worden geschreven met de Java-code, terwijl XML-configuratiebestanden extern zijn aan Java-code. Daarom moeten er later, indien van toepassing, wijzigingen worden aangebracht in de metadata; in het geval van op annotaties gebaseerde configuratie, is directe toegang tot Java-code vereist. Dit is misschien niet altijd mogelijk. In zo'n geval kunnen we nieuwe of gewijzigde metadataconfiguratie in een XML-bestand schrijven zonder enige verandering in de originele code en toch het gewenste effect hebben. Dit is het voordeel van het gebruik van XML-configuratie. Configuratie op basis van annotaties is echter handiger in het gebruik en de populaire keuze onder programmeurs.
- Sluimerstand is de populaire en meest geavanceerde van alle JPA-implementaties vanwege Red Hat. Het gebruikt zijn eigen tweaks en toegevoegde functies die naast de JPA-implementatie kunnen worden gebruikt. Het heeft een grotere gebruikersgemeenschap en is goed gedocumenteerd. Enkele van de extra eigen functies zijn ondersteuning voor multi-tenancy, het deelnemen aan niet-geassocieerde entiteiten bij query's, tijdstempelbeheer, enzovoort.
- EclipseLink is gebaseerd op TopLink en is een referentie-implementatie van JPA-versies. Het biedt standaard JPA-functionaliteiten, afgezien van enkele interessante propriëtaire functies, zoals ondersteuning van multi-tenancy, verwerking van databasewijzigingen, enzovoort.
JPA gebruiken in een Java SE-programma
Om JPA in een Java-programma te gebruiken, hebt u een JPA-provider nodig, zoals Hibernate of EclipseLink, of een andere bibliotheek. U hebt ook een JDBC-stuurprogramma nodig dat verbinding maakt met de specifieke relationele database. In de volgende code hebben we bijvoorbeeld de volgende bibliotheken gebruikt:
- Aanbieder: EclipseLink
- JDBC-stuurprogramma: JDBC-stuurprogramma voor MySQL (connector/J)
We zullen een relatie leggen tussen twee tabellen—Werknemer en Afdeling—als één-op-één en één-op-veel, zoals weergegeven in het volgende OER-diagram (zie figuur 1).
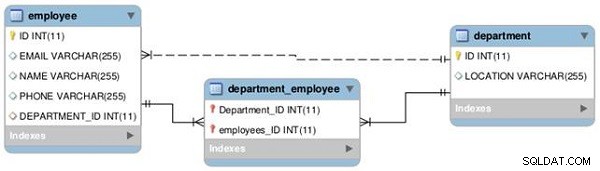
Figuur 1: Tabelrelaties
De medewerker tabel wordt als volgt toegewezen aan een entiteitsklasse met behulp van annotatie:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
En, de afdeling tabel wordt als volgt toegewezen aan een entiteitsklasse:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Het configuratiebestand, persistence.xml , wordt gemaakt in de META-INF map. Dit bestand bevat de verbindingsconfiguratie, zoals het gebruikte JDBC-stuurprogramma, gebruikersnaam en wachtwoord voor databasetoegang en andere relevante informatie die de JPA-provider nodig heeft om de databaseverbinding tot stand te brengen.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Entiteiten houden zichzelf niet vol. Logica moet worden toegepast om entiteiten te manipuleren om hun aanhoudende levenscyclus te beheren. De EntityManager Dankzij de interface die door de JPA wordt geleverd, kan de toepassing entiteiten in de relationele database beheren en zoeken. We maken een query-object met behulp van EntityManager communiceren met de database. EntityManager verkrijgen voor een bepaalde database gebruiken we een object dat een EntityManagerFactory implementeert koppel. Er is een statische methode, genaamd createEntityManagerFactory , in de Persistentie klasse die EntityManagerFactory . retourneert voor de persistentie-eenheid gespecificeerd als een String argument. In de volgende rudimentaire implementatie hebben we de logica geïmplementeerd.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Nu zijn we klaar om de hoofdinterface van de applicatie te maken. Hier hebben we alleen de invoegbewerking geïmplementeerd omwille van de eenvoud en ruimtebeperkingen.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Opmerking: Raadpleeg de juiste Java API-documentatie voor gedetailleerde informatie over API's die in de voorgaande code zijn gebruikt. |
Conclusie
Zoals duidelijk zou moeten zijn, is de kernterminologie van de JPA- en Persistence-context uitgebreider dan de glimp die hier wordt gegeven, maar beginnen met een snel overzicht is beter dan lange ingewikkelde vuile code en hun conceptuele details. Als je een beetje programmeerervaring hebt in core JDBC, zul je ongetwijfeld waarderen hoe JPA je leven eenvoudiger kan maken. We zullen geleidelijk dieper in JPA duiken naarmate we verder gaan in komende artikelen.