Vorige maand heb ik een Special Islands-uitdaging behandeld. De taak was om perioden van activiteit te identificeren voor elke service-ID, waarbij een tussenruimte van maximaal een invoeraantal seconden werd toegestaan (@allowedgap ). Het voorbehoud was dat de oplossing compatibel moest zijn met pre-2012, dus je kon geen functies zoals LAG en LEAD gebruiken, of vensterfuncties samenvoegen met een frame. Ik heb een aantal zeer interessante oplossingen gepost in de commentaren van Toby Ovod-Everett, Peter Larsson en Kamil Kosno. Zorg ervoor dat je hun oplossingen doorneemt, want ze zijn allemaal behoorlijk creatief.
Vreemd genoeg liep een aantal van de oplossingen langzamer met de aanbevolen index dan zonder. In dit artikel geef ik daar een verklaring voor.
Hoewel alle oplossingen interessant waren, wilde ik me hier concentreren op de oplossing van Kamil Kosno, een ETL-ontwikkelaar bij Zopa. In zijn oplossing gebruikte Kamil een zeer creatieve techniek om LAG en LEAD na te bootsen zonder LAG en LEAD. U zult de techniek waarschijnlijk handig vinden als u LAG/LEAD-achtige berekeningen moet uitvoeren met code die compatibel is met vóór 2012.
Waarom zijn sommige oplossingen sneller zonder de aanbevolen index?
Ter herinnering, ik stelde voor om de volgende index te gebruiken om de oplossingen voor de uitdaging te ondersteunen:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Mijn pre-2012-compatibele oplossing was de volgende:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; In figuur 1 staat het plan voor mijn oplossing met de aanbevolen index.
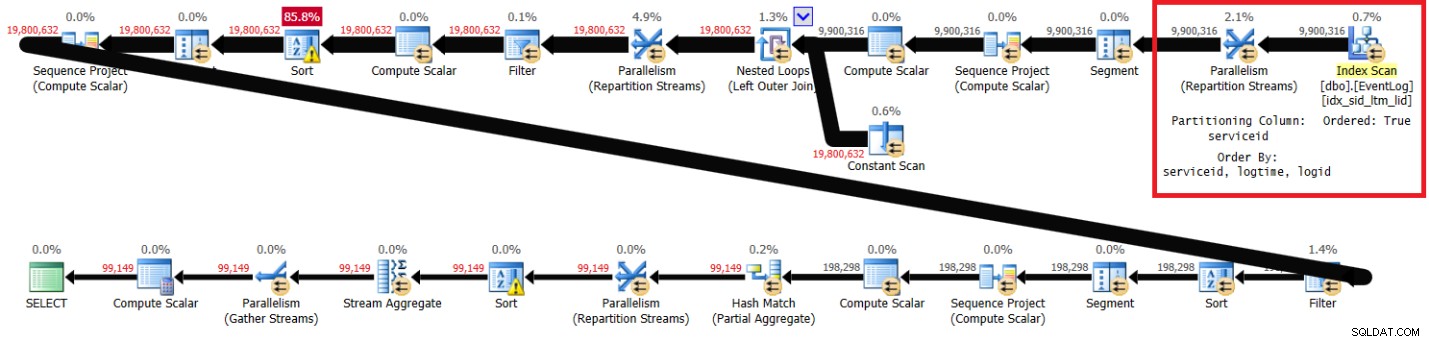 Figuur 1:Plan voor Itziks oplossing met aanbevolen index
Figuur 1:Plan voor Itziks oplossing met aanbevolen index
Merk op dat het plan de aanbevolen index scant in sleutelvolgorde (Geordende eigenschap is True), de streams verdeelt op service-id met behulp van een order-behoudende uitwisseling, en vervolgens de initiële berekening van rijnummers toepast op basis van indexvolgorde zonder dat er gesorteerd hoeft te worden. Hieronder volgen de prestatiestatistieken die ik heb gekregen voor het uitvoeren van deze query op mijn laptop (verstreken tijd, CPU-tijd en hoogste wachttijd uitgedrukt in seconden):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Ik liet toen de aanbevolen index vallen en voerde de oplossing opnieuw uit:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ik heb het plan weergegeven in figuur 2.
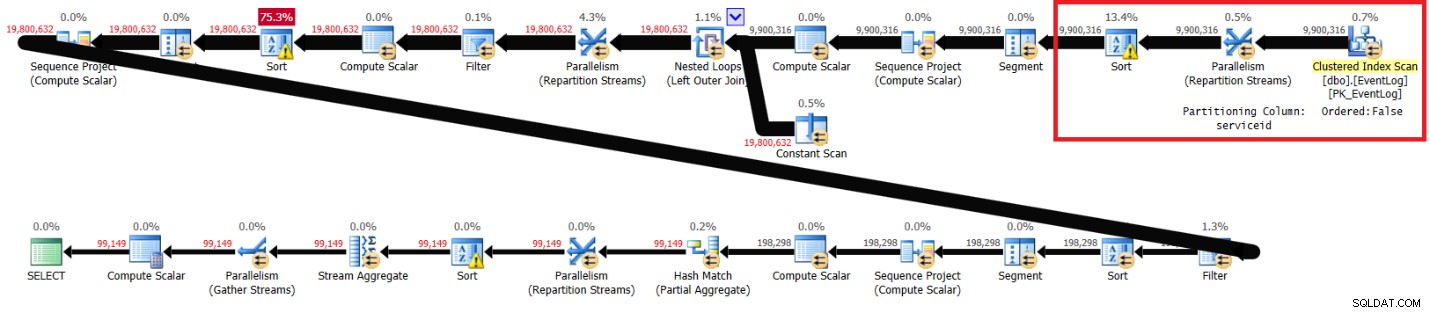 Figuur 2:Plan voor Itziks oplossing zonder aanbevolen index
Figuur 2:Plan voor Itziks oplossing zonder aanbevolen index
De gemarkeerde secties in de twee plannen laten het verschil zien. Het plan zonder de aanbevolen index voert een ongeordende scan uit van de geclusterde index, verdeelt de streams op service-id met behulp van een niet-bestaande uitwisseling en sorteert vervolgens de rijen zoals de vensterfunctie nodig heeft (op service-id, logtime, logid). De rest van het werk lijkt in beide plannen hetzelfde te zijn. Je zou denken dat het plan zonder de aanbevolen index langzamer zou moeten zijn, omdat het een extra soort heeft dat het andere plan niet heeft. Maar hier zijn de prestatiestatistieken die ik voor dit abonnement op mijn laptop heb:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
Er komt meer CPU-tijd bij kijken, wat deels te wijten is aan de extra sortering; er is meer I/O bij betrokken, waarschijnlijk als gevolg van extra sortering; de verstreken tijd is echter ongeveer 30 procent sneller. Wat zou dit kunnen verklaren? Een manier om dit te achterhalen is door de query in SSMS uit te voeren met de optie Live Query Statistics ingeschakeld. Toen ik dit deed, eindigde de meest rechtse Parallelism (Repartition Streams)-operator in 6 seconden zonder de aanbevolen index en in 35 seconden met de aanbevolen index. Het belangrijkste verschil is dat de eerste de gegevens krijgt die vooraf zijn besteld uit een index en een uitwisseling is die de bestelling behoudt. De laatste krijgt de gegevens ongeordend en is geen uitwisseling die de bestelling behoudt. Bestellingsbehoudende uitwisselingen zijn doorgaans duurder dan niet-bestellende uitwisselingen. Ook, in ieder geval in het meest rechtse deel van het plan tot de eerste sortering, levert de eerste de rijen in dezelfde volgorde als de uitwisselingspartitioneringskolom, zodat je niet alle threads krijgt om de rijen echt parallel te verwerken. De laatste levert de rijen ongeordend, zodat je alle threads krijgt om rijen echt parallel te verwerken. Je kunt zien dat de hoogste wachttijd in beide plannen CXPACKET is, maar in het eerste geval is de wachttijd het dubbele van die van de laatste, wat je vertelt dat parallellisme-afhandeling in het laatste geval meer optimaal is. Er kunnen nog andere factoren in het spel zijn waar ik niet aan denk. Als je aanvullende ideeën hebt die het verrassende prestatieverschil kunnen verklaren, deel ze dan alsjeblieft.
Op mijn laptop resulteerde dit in de uitvoering zonder dat de aanbevolen index sneller was dan die met de aanbevolen index. Maar op een andere testmachine was het andersom. Je hebt tenslotte een extra soort, met morspotentieel.
Uit nieuwsgierigheid testte ik een seriële uitvoering (met de MAXDOP 1-optie) met de aanbevolen index op zijn plaats, en kreeg de volgende prestatiestatistieken op mijn laptop:
elapsed: 42, CPU: 40, logical reads: 143,519
Zoals u kunt zien, is de runtime vergelijkbaar met de runtime van de parallelle uitvoering met de aanbevolen index op zijn plaats. Ik heb maar 4 logische CPU's in mijn laptop. Natuurlijk kan uw kilometerstand variëren met verschillende hardware. Het punt is dat het de moeite waard is om verschillende alternatieven te testen, inclusief met en zonder indexering waarvan je zou denken dat dat zou moeten helpen. De resultaten zijn soms verrassend en contra-intuïtief.
Kamils oplossing
Ik was erg geïntrigeerd door de oplossing van Kamil en vond vooral de manier waarop hij LAG en LEAD emuleerde met een pre-2012-compatibele techniek leuk.
Hier is de code die de eerste stap in de oplossing implementeert:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Deze code genereert de volgende uitvoer (alleen gegevens voor service-id 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
Deze stap berekent twee rijnummers die voor elke rij één uit elkaar liggen, gepartitioneerd op service-id en geordend op logtijd. Het huidige rijnummer vertegenwoordigt de eindtijd (noem het end_time), en het huidige rijnummer min één staat voor de starttijd (noem het start_time).
De volgende code implementeert de tweede stap van de oplossing:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Deze stap genereert de volgende uitvoer:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Met deze stap wordt elke rij ongedaan gemaakt in twee rijen, waarbij elke logboekvermelding wordt gedupliceerd:een keer voor het type tijd start_time en een andere voor eind_time. Zoals u kunt zien, verschijnt elk rijnummer, behalve de minimale en maximale rijnummers, twee keer:een keer met de logtijd van de huidige gebeurtenis (start_time) en een andere met de logtijd van de vorige gebeurtenis (end_time).
De volgende code implementeert de derde stap in de oplossing:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Deze code genereert de volgende uitvoer:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Deze stap draait de gegevens, groepeert paren rijen met hetzelfde rijnummer en retourneert één kolom voor de huidige gebeurtenislogboektijd (start_time) en een andere voor de vorige gebeurtenislogboektijd (eind_time). Dit onderdeel emuleert effectief een LAG-functie.
De volgende code implementeert de vierde stap in de oplossing:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Deze code genereert de volgende uitvoer:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Deze stap filtert paren waarbij het verschil tussen de vorige eindtijd en de huidige starttijd groter is dan de toegestane tussenruimte, en rijen met slechts één gebeurtenis. Nu moet u de starttijd van elke huidige rij verbinden met de eindtijd van de volgende rij. Dit vereist een LEAD-achtige berekening. Om dit te bereiken, maakt de code opnieuw rijnummers die één uit elkaar liggen, maar deze keer vertegenwoordigt het huidige rijnummer de starttijd (start_time_grp ) en het huidige rijnummer min één vertegenwoordigt de eindtijd (end_time_grp).
Net als voorheen is de volgende stap (nummer 5) het ongedaan maken van de draaiing van de rijen. Hier is de code die deze stap implementeert:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Uitgang:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Zoals je kunt zien, is de grp-kolom uniek voor elk eiland binnen een service-ID.
Stap 6 is de laatste stap in de oplossing. Hier is de code die deze stap implementeert, die ook de volledige oplossingscode is:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Deze stap genereert de volgende uitvoer:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Deze stap groepeert de rijen op service-id en grp, filtert alleen relevante groepen en retourneert de minimale start_time als het begin van het eiland en de maximale eindtijd als het einde van het eiland.
Afbeelding 3 heeft het plan dat ik voor deze oplossing heb gekregen met de aanbevolen index op zijn plaats:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Plan met aanbevolen index in figuur 3.
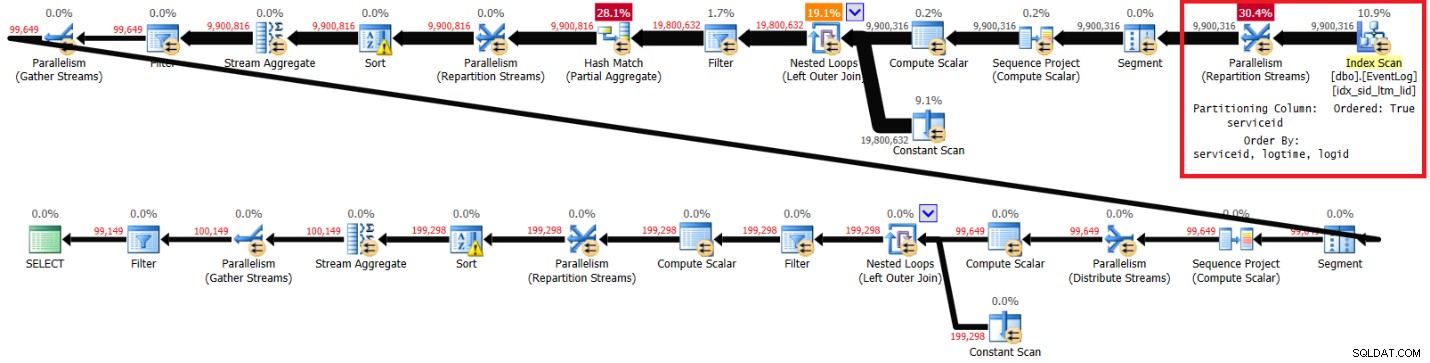 Figuur 3:Plan voor Kamils oplossing met aanbevolen index
Figuur 3:Plan voor Kamils oplossing met aanbevolen index
Hier zijn de prestatiestatistieken die ik voor deze uitvoering op mijn laptop heb gekregen:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Ik liet toen de aanbevolen index vallen en voerde de oplossing opnieuw uit:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Ik heb het plan weergegeven in figuur 4 voor de uitvoering zonder de aanbevolen index.
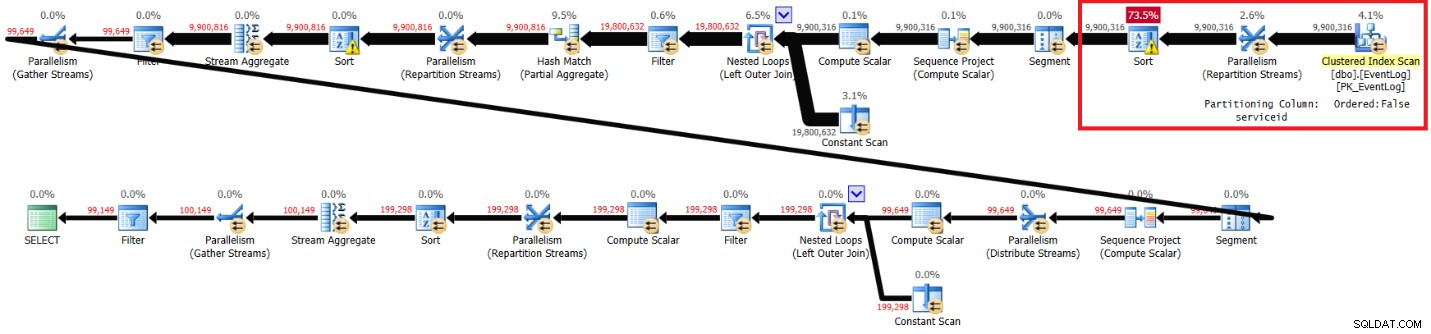 Figuur 4:Plan voor Kamils oplossing zonder aanbevolen index
Figuur 4:Plan voor Kamils oplossing zonder aanbevolen index
Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
De looptijden, CPU-tijden en CXPACKET-wachttijden lijken erg op mijn oplossing, hoewel de logische waarden lager zijn. De oplossing van Kamil werkt ook sneller op mijn laptop zonder de aanbevolen index, en het lijkt erop dat dit om vergelijkbare redenen is.
Conclusie
Anomalieën zijn een goede zaak. Ze maken je nieuwsgierig en zorgen ervoor dat je de oorzaak van het probleem gaat onderzoeken en als resultaat nieuwe dingen leert. Het is interessant om te zien dat sommige zoekopdrachten op bepaalde machines sneller verlopen zonder de aanbevolen indexering.
Nogmaals bedankt aan Toby, Peter en Kamil voor jullie oplossingen. In dit artikel heb ik Kamils oplossing behandeld, met zijn creatieve techniek om LAG en LEAD na te bootsen met rijnummers, ondraaiend en draaiend. U zult deze techniek handig vinden wanneer u LAG- en LEAD-achtige berekeningen nodig heeft die moeten worden ondersteund in omgevingen van vóór 2012.