Databasereplicatie is de technologie om gegevens van de primaire server naar secundaire servers te distribueren. Replicatie werkt volgens het Master-slave-concept waarbij de Master-database gegevens distribueert naar een of meerdere slave-servers. Replicatie kan worden ingesteld tussen meerdere SQL Server-instanties op dezelfde server, OF het kan worden ingesteld tussen meerdere databaseservers binnen dezelfde of geografisch gescheiden datacenters.
Er zijn twee belangrijke voordelen van het gebruik van SQL Server-replicatie:
- Door replicatie te gebruiken, kunnen we bijna realtime gegevens verkrijgen die voor rapportagedoeleinden kunnen worden gebruikt. Als u bijvoorbeeld de schrijfintensieve OLTP-belasting op de ene server en de leesintensieve belasting op een andere server wilt scheiden, kunt u replicatie instellen om gegevens op beide servers gesynchroniseerd te houden.
- Het tweede voordeel is dat u de replicatie zo kunt plannen dat deze op een bepaalde tijd wordt uitgevoerd. Als u bijvoorbeeld wilt dat die rapportserver gegevens van de voltooide dag bevat, kunt u de replicatiemomentopname dienovereenkomstig plannen. We hoeven geen extra logica te schrijven om met actuele gegevens om te gaan.
Replicatie biedt veel flexibiliteit. Met behulp van replicatie kunnen we de rijen uitfilteren en kunnen we ook de subset van gegevens van elke tabel repliceren. We kunnen de gerepliceerde gegevens wijzigen of alleen bijwerken en invoegen en de verwijderingen negeren. We kunnen de gegevens ook repliceren uit een ander databasesysteem zoals Oracle.
Componenten van replicatie
Er zijn zeven kerncomponenten van SQL Server-replicatie. Hieronder volgt de lijst:
- Uitgever.
- Distributeur.
- Abonnee.
- Artikelen.
- Publicatie.
- Push-abonnement.
- Trek abonnement af.
Hieronder volgen de details:
Artikelen
Een artikel is een databaseobject, zoals een SQL-tabel, of een opgeslagen procedure. Zoals ik hierboven al zei, kunnen we met Replicatie gegevens filteren of de geselecteerde tabelkolom repliceren, dus tabelkolommen of rijen worden als artikelen beschouwd.
Publicatie
Artikelen kunnen niet worden gerepliceerd totdat ze onderdeel worden van de publicatie. Publicatie is de groep van de Artikelen/Database-objecten. Het vertegenwoordigt ook de dataset die zal worden gerepliceerd door SQL Server.
Uitgever
Publisher bevat een hoofddatabase met de gegevens die moeten worden gepubliceerd. Het bepaalt welke gegevens over alle abonnees moeten worden verdeeld.
Distributeur
De distributeur is de brug tussen uitgever en abonnee. Distributeur verzamelt alle gepubliceerde gegevens en bewaart deze totdat ze naar alle abonnees worden verzonden. Het is een brug tussen uitgever en abonnee. Het ondersteunt meerdere uitgevers en abonneeconcepten. Het is niet verplicht om de distributeur op een aparte SQL-instantie of een aparte server te configureren. Als we het niet configureren, kan de uitgever optreden als distributeur. Organisaties met grootschalige replicatie kunnen de distributeur configureren op een apart systeem.
Abonnees
De abonnee is het einde van de bron of de bestemming waarnaar gegevens of gerepliceerde publicatie worden verzonden. In replicatie is er één uitgever, deze kan meerdere abonnees hebben.
Push-abonnement
Bij een push-abonnement werkt de uitgever de gegevens bij aan de abonnee. Bij een Push-abonnement is de abonnee passief. De uitgever stuurt artikelen of publicaties naar al zijn abonnees. Op basis van de vereisten van de organisatie kunt u bij het maken van de replicatiewizard op het scherm het abonnement selecteren dat u wilt gebruiken. Transactiereplicatie en peer-to-peer-replicatie gebruiken het Push-abonnement om de realtime beschikbaarheid van gegevens te behouden.
Abonnement opvragen
Bij een Pull-abonnement vragen alle abonnees de nieuwe gegevens of bijgewerkte gegevens op bij de uitgever. In een pull-abonnement kunnen we bepalen welke gegevens of gegevenswijzigingen nodig zijn voor abonnees. Het is handig wanneer we de gewijzigde gegevens niet direct nodig hebben.
Replicatietypen
SQL Server ondersteunt drie soorten replicatie:
- Transactionele replicatie.
- Snapshot-replicatie.
- Replicatie samenvoegen.
Transactionele replicatie
Transactiereplicatie, eventuele schemawijzigingen, gegevenswijzigingen die plaatsvinden in de uitgeversdatabase, worden gerepliceerd in de abonneedatabase. Telkens wanneer er bewerkingen voor bijwerken, verwijderen of invoegen plaatsvinden in de uitgeversdatabase, worden de wijzigingen bijgehouden en worden die wijzigingen naar de abonneedatabases verzonden. Transactionele replicatie verzendt slechts een beperkte hoeveelheid gegevens over een netwerk. Bovendien zijn wijzigingen bijna realtime, dus het kan worden gebruikt om de DR-site op te zetten, of het kan worden gebruikt om de rapportageactiviteiten uit te schalen. Transactiereplicatie is ideaal voor de volgende situaties:
- Als u een systeem wilt opzetten waarbij wijzigingen die op de uitgever zijn aangebracht, onmiddellijk moeten worden toegepast op abonnees.
- De uitgever heeft hoog laag INSERT, UPDATES en DELETES.
- Als u heterogene replicatie wilt instellen, uitgever of abonnees voor niet-SQL Server-databases, zoals Oracle.
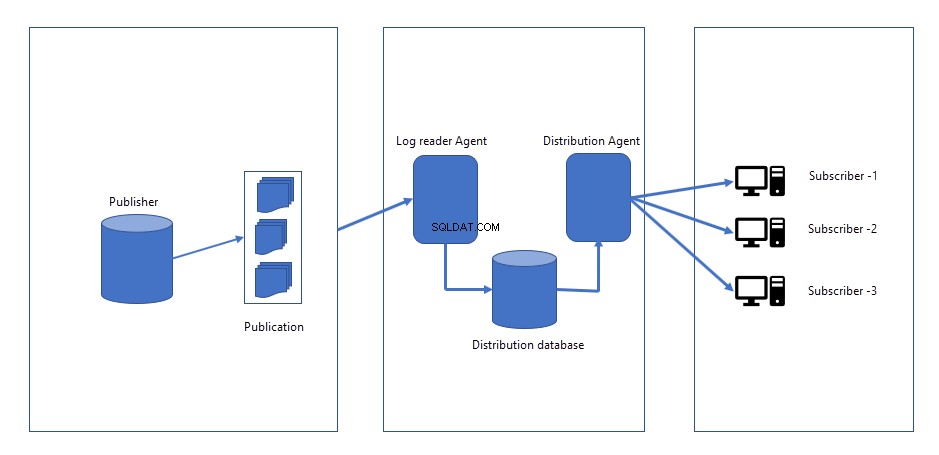
Wanneer er wijzigingen worden aangebracht in de uitgeversdatabase, worden wijzigingen vastgelegd in een logbestand in de uitgeversdatabase. Distributeur / Uitgever site, er worden twee banen gecreëerd.
- Momentopname-agent :Snapshot agent job genereert de snapshot van schema, data van de objecten die we willen repliceren of publiceren. Bestanden van de momentopname kunnen worden opgeslagen op de Publisher-server of netwerklocatie. Wanneer we de replicatie voor de eerste keer starten, wordt een momentopname gemaakt en toegepast op alle abonnees. Snapshot-agent blijft inactief totdat deze handmatig wordt geactiveerd of is gepland om op een specifieke tijd te worden uitgevoerd.
- Log Reader-agent :Logboeklezer-agenttaak wordt continu uitgevoerd. Het leest de wijzigingen (INSERT, UPDATES en DELETES) die zijn opgetreden uit het transactielogboek van de uitgeversdatabase en stuurt ze naar een distributieagent.
- Distributieagent :zodra de wijzigingen zijn opgehaald van de Logboeklezer-agent, verzendt de distributieagent alle wijzigingen naar de abonnees.
Wanneer we transactionele replicatie configureren, voert het de volgende activiteiten uit
- Het wordt gestart door de eerste momentopname te maken van publicatiegegevens en database-objecten en momentopname toegepast op abonnees.
- Logreader-agent bewaakt continu het T-Log van de uitgever en als er wijzigingen optreden, stuurt hij deze naar de distributeur of rechtstreeks naar abonnees.
De volgende afbeelding geeft weer hoe transactionele replicatie werkt:
Voordelen:
- Transactiereplicatie kan worden gebruikt als een standby-SQL-server, of het kan worden gebruikt voor taakverdeling of het scheiden van rapportagesysteem en OLTP-systeem.
- Uitgeversserver repliceert gegevens naar abonneeserver met lage latentie.
- Met behulp van transactionele replicatie kan replicatie op objectniveau worden geïmplementeerd.
- Transactionele replicatie kan worden toegepast wanneer u minder gegevens hoeft te beschermen en u een snel plan voor gegevensherstel moet hebben.
Nadelen:
- Zodra de replicatie tot stand is gebracht, zijn de schemawijzigingen op de uitgever niet van toepassing op de abonneeserver. We moeten die wijzigingen handmatig aanbrengen door een nieuwe momentopname te genereren en deze toe te passen op abonnees.
- Als we de servers veranderen, moeten we de replicatie opnieuw configureren.
- Als transactionele replicatie wordt gebruikt als een DR-configuratie, moeten we handmatig een failover uitvoeren.
Snapshot-replicatie
Snapshot-replicatie genereert een volledige foto/snapshot van publicatie volgens een gedefinieerd schema en stuurt de snapshotbestanden naar abonnees. Wanneer snapshotreplicatie plaatsvindt, worden bestemmingsgegevens vervangen door een nieuwe snapshot. Snapshot-replicatie is de beste optie wanneer gegevens minder vluchtig zijn. Hoofdtabellen zoals Stad, Postcode en Pincode zijn bijvoorbeeld de beste kandidaten voor replicatie van snapshots.
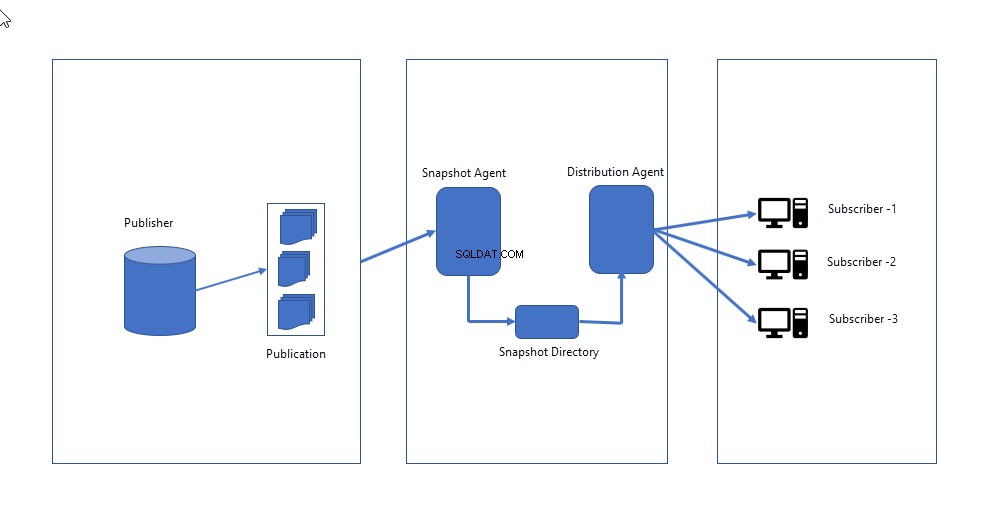
Bij het configureren van snapshotreplicatie worden de volgende belangrijke componenten gedefinieerd:
- Momentopname-agent :Het creëert een compleet beeld van het schema en de gegevens die in de publicatie zijn gedefinieerd en stuurt dit naar de distributeur. Snapshot-agent blijft inactief totdat deze handmatig wordt geactiveerd OF gepland om op een specifieke tijd te worden uitgevoerd.
- Distributeur-agent :Het stuurt de snapshot-bestanden naar abonnees en past schema en gegevens toe door de bestaande te vervangen.
Snapshot-replicatie voert de volgende activiteiten uit:
- Op het gedefinieerde schema plaatst de snapshot-agent een gedeelde vergrendeling op het schema en de te publiceren gegevens.
- Gehele momentopname van gepubliceerde gegevens gekopieerd naar de distributeur. Snapshot-agent maakt drie bestanden
- Bestand naar aangemaakt databaseschema van gepubliceerde gegevens.
- BCP-bestand om gegevens binnen SQL-tabellen te exporteren
- Indexbestanden om indexgegevens te exporteren.
- Zodra bestanden zijn gemaakt, geeft snapshot-agent gedeelde vergrendelingen op gepubliceerde gegevens en gegevens vrij.
- Distributeursagenten starten en vervangen het abonneeschema en de gegevens met behulp van bestanden die door de snapshotagent zijn gemaakt.
De volgende afbeelding illustreert hoe snapshot-replicatie werkt.
Voordelen
- Snapshot-replicatie is heel eenvoudig in te stellen. Als gegevens niet vaak worden gewijzigd, is snapshotreplicatie een zeer geschikte optie.
- Je kunt bepalen wanneer je gegevens wilt verzenden. Bijvoorbeeld een hoofdtabel die veel gegevens bevat, maar minder vaak verandert dan dat u de gegevens kunt repliceren als er weinig verkeer is.
Nadelen
- Momentopname gegenereerd door de snapshot-agent bevat gewijzigde en ongewijzigde gepubliceerde gegevens, daarom kan de snapshot die via het netwerk wordt verzonden, latentie veroorzaken en andere bewerkingen beïnvloeden.
- Naarmate de gegevens toenemen, neemt de grootte van de momentopname toe en kost het meer tijd om de momentopname te maken en te distribueren naar abonnees.
Replicatie samenvoegen
Samenvoegreplicatie kan worden gebruikt wanneer we wijzigingen op meerdere servers moeten beheren en deze wijzigingen moeten worden geconsolideerd.
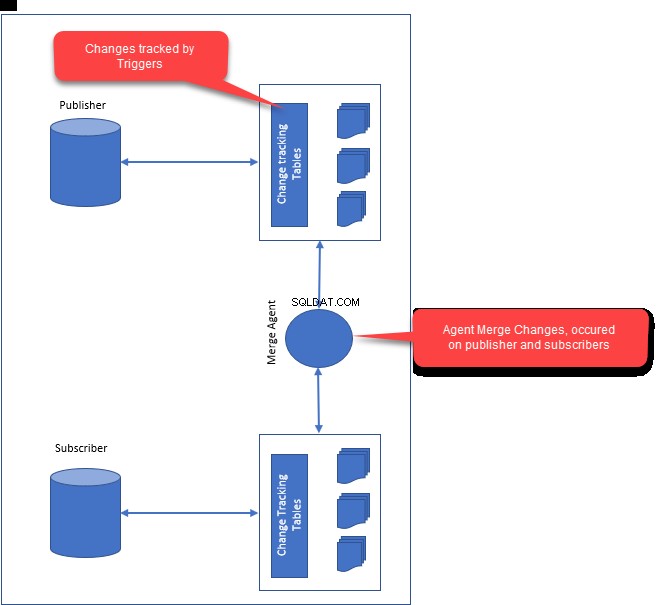
Wanneer we samenvoegreplicatie configureren, worden de volgende componenten gemaakt:
- Momentopname-agent :Snapshot-agent genereert de eerste snapshot van publicatiegegevens en database-objecten. Zodra de momentopname is gemaakt, wordt deze gedistribueerd naar alle abonnees.
- Agent samenvoegen :Merge agent is verantwoordelijk voor het oplossen van de conflicten tussen uitgever en abonnees. Eventuele conflicten worden opgelost via de merge-agent die gebruikmaakt van conflictoplossing. Afhankelijk van hoe je de conflictoplossing hebt geconfigureerd, worden de conflicten opgelost door de samenvoegagent.
Wanneer we samenvoegreplicatie configureren, voert het de volgende activiteiten uit:
- Het wordt gestart door een momentopname te maken van publicatiegegevens en database-objecten en momentopname toegepast op abonnees.
- Tijdens het configureren van samenvoegreplicatie, creëert het triggers voor uitgever en abonnee. Triggers zijn verantwoordelijk voor het bijhouden van latere wijzigingen en tabelwijzigingen op uitgever en abonnees.
- Als uitgever en abonnees verbinding maken met het netwerk, worden wijzigingen van gegevensrijen en schemawijzigingen met elkaar gesynchroniseerd. Terwijl de wijzigingen van de uitgever en abonnees worden samengevoegd, lost de merge-agent de conflicten op op basis van de voorwaarden die zijn gedefinieerd in de merge-agent.
Samenvoegreplicatie wordt gebruikt in server-naar-clientomgevingen en is ideaal voor situaties waarin abonnees gegevens van de uitgever moeten ophalen, offline wijzigingen moeten aanbrengen en vervolgens wijzigingen moeten synchroniseren met de uitgever en andere abonnees.
Er kunnen praktische situaties zijn waarin dezelfde rij wordt gewijzigd door verschillende uitgevers en abonnees. Op dat moment zal de Merge-agent kijken welke conflictoplossing is gedefinieerd en dienovereenkomstig wijzigingen aanbrengen.
SQL Server identificeert een kolom op unieke wijze met behulp van een globaal unieke id voor elke rij in een gepubliceerde tabel. Als de tabel al een unieke id-kolom heeft, gebruikt SQL Server automatisch die kolom. Anders wordt er een rowguid-kolom aan de tabel toegevoegd en wordt een index gemaakt op basis van de kolom.
Triggers worden aangemaakt op de gepubliceerde tabellen voor zowel uitgevers als abonnees. Ze worden gebruikt om de wijzigingen bij te houden op basis van de rij- of kolomwijzigingen.
De volgende afbeelding illustreert hoe samenvoegreplicatie werkt:
Voordelen:
- Dit is de enige manier om wijzigingen op meerdere servergegevens te consolideren.
Nadelen:
- Het kost veel tijd om beide uiteinden te repliceren en te synchroniseren.
- Er is weinig consistentie omdat veel partijen moeten worden gesynchroniseerd.
- Er kunnen conflicten optreden tijdens het samenvoegen van replicatie als dezelfde rijen worden beïnvloed in meer dan één abonnee en uitgever. Het kan worden opgelost met behulp van de conflictoplossing, maar het maakt het instellen van de replicatie ingewikkelder.
T-SQL-code om de replicatieconfiguratie te bekijken
Ik heb de snapshot-replicatie en transactionele replicatie geconfigureerd op twee instanties van mijn machine. Met behulp van SQL dynamisch beheer (DMV's) kunnen we de configuratie van replicatie controleren. Om de configuratie van replicatie te bekijken, kunnen we T-SQL-code gebruiken. Scriptcode bevat het volgende:
- Abonnee database naam.
- Naam uitgever.
- Abonnementstype.
- Uitgeversdatabase.
- Naam replicatie-agent.
Hieronder staat het script:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Hieronder volgt de uitvoer:

Samenvatting
In dit artikel heb ik uitgelegd:
- Het fundament en de voordelen van replicatie en zijn componenten.
- Transactionele replicatie.
- Snapshot-replicatie.
- Replicatie samenvoegen.