De database is een cruciaal en essentieel onderdeel van elk bedrijf of organisatie. De groeiende trends voorspellen dat 82% van de ondernemingen verwacht dat het aantal databases de komende 12 maanden zal toenemen. Een grote uitdaging van elke DBA is om te ontdekken hoe de enorme gegevensgroei kan worden aangepakt, en dit wordt een zeer belangrijk doel. Hoe kunt u de databaseprestaties verbeteren, de kosten verlagen en downtime elimineren om uw gebruikers de best mogelijke ervaring te bieden? Is datacompressie een optie? Laten we beginnen en kijken hoe sommige van de bestaande functies nuttig kunnen zijn om dergelijke situaties aan te pakken.
In dit artikel gaan we leren hoe de oplossing voor gegevenscompressie ons kan helpen de oplossing voor gegevensbeheer te optimaliseren. In deze handleiding behandelen we de volgende onderwerpen:
- Een overzicht van compressie
- Voordelen van compressie
- Een overzicht van gegevens zijn compressietechnieken
- Bespreking van verschillende soorten gegevenscompressie
- Feiten over gegevenscompressie
- Overwegingen voor implementatie
- en meer…
Compressie
De compressie is een techniek en dus een resource-gevoelige operatie, maar met hardware-compromissen. Men moet denken aan het inzetten van datacompressie voor de volgende voordelen:
- Effectief ruimtebeheer
- Efficiënte kostenbesparingstechniek
- Gemak van databaseback-upbeheer
- Effectief N/W bandbreedtegebruik
- Veilig en sneller herstel of herstel
- Betere prestaties – verkleint de geheugenvoetafdruk van het systeem
Opmerking: Als SQL Server CPU- of geheugenbeperking heeft, is compressie mogelijk niet geschikt voor uw omgeving.
Gegevenscompressie is van toepassing op:
- Heel veel
- Geclusterde indexen
- Niet-geclusterde indexen
- Partities
- Geïndexeerde weergaven
Opmerking: Grote objecten worden niet gecomprimeerd (bijvoorbeeld LOB en BLOB)
Meest geschikt voor de volgende toepassingen:
- Log tabellen
- Audittabellen
- Feitentabellen
- Rapportage
Inleiding
Datacompressie is een technologie die al bestaat sinds SQL Server 2008. Het idee van datacompressie is dat je selectief tabellen, indexen of partities binnen een database kunt kiezen. I/O blijft een knelpunt bij het verplaatsen van informatie tussen in en uit de database. Gegevenscompressie maakt gebruik van dit type en helpt de efficiëntie van een database te vergroten. Omdat we weten dat de netwerksnelheden zoveel langzamer zijn dan de verwerkingssnelheid, is het mogelijk om efficiëntiewinsten te vinden door de verwerkingskracht te gebruiken om gegevens in een database te comprimeren, zodat deze sneller reizen. En gebruik dan opnieuw de verwerkingskracht om de gegevens aan de andere kant te decomprimeren. Over het algemeen vermindert gegevenscompressie de ruimte die door de gegevens wordt ingenomen. De techniek van datacompressie is beschikbaar voor elke database en wordt ondersteund door alle edities van SQL Server 2016 SP1. Daarvoor was het alleen beschikbaar op SQL Server Enterprise- of Developer-edities, niet op Standard of Express.
Functieondersteuning

Typen gegevenscompressie
Er zijn twee soorten gegevenscompressie beschikbaar binnen SQL Server, op rijniveau en op paginaniveau.
De compressie op rijniveau werkt achter de schermen en converteert gegevenstypen met een vaste lengte naar typen met variabele lengte. De veronderstelling hier is dat gegevens vaak worden opgeslagen met een type met vaste lengte, zoals char 100, en dat ze niet de volledige 100 tekens voor elk record vullen. Kleine winsten kunnen worden behaald door deze extra ruimte van de tafel te verwijderen. Natuurlijk, als uw datatabellen geen tekst- en numerieke velden met een vaste lengte gebruiken, of als ze dat wel doen en u het volledig toegestane aantal tekens en cijfers opslaat, dan zullen de compressiewinsten onder het rijniveau-schema minimaal zijn op zijn best.
Het concept van compressie is uitgebreid tot alle datatypes met een vaste lengte, inclusief char, int en float. Met SQL Server kunt u ruimte besparen door de gegevens op te slaan alsof het een type met variabele grootte was; de gegevens zullen verschijnen en zich gedragen als een vaste lengte.
Als u bijvoorbeeld de waarde 100 heeft opgeslagen in een int kolom, de SQL Server hoeft niet alle 32 bits te gebruiken, maar gebruikt gewoon 8 bits (1 byte).
Compressie op paginaniveau tilt de zaken naar een ander niveau. Ten eerste past het automatisch compressie op rijniveau toe op gegevensvelden met een vaste lengte, dus u krijgt die winst automatisch standaard. Bovendien past het iets toe dat prefixcompressie wordt genoemd, en een andere techniek die woordenboekcompressie wordt genoemd.
Rijcompressie
Rijcompressie is een intern compressieniveau dat de vaste tekenreeksen opslaat door gebruik te maken van een formaat met variabele lengte door de lege tekens niet op te slaan. De volgende stappen worden uitgevoerd bij compressie op rijniveau.
- Alle numerieke gegevenstypen zoals int , zweven , decimaal, en geld worden omgezet in gegevenstypen met variabele lengte. 125 opgeslagen in kolom en gegevenstype van de kolom is bijvoorbeeld een geheel getal. Dan weten we dat er 4 bytes worden gebruikt om de integerwaarde op te slaan. Maar 125 kan worden opgeslagen in 1 byte omdat 1 byte waarden van 0 tot 255 kan opslaan. Dus 125 kan worden opgeslagen als een kleine int , zodat 3 bytes kunnen worden opgeslagen.
- Char en Nchar gegevenstypen worden opgeslagen als gegevenstypen met variabele lengte. "SQL" wordt bijvoorbeeld opgeslagen in een char (20) type kolom. Maar na compressie zullen slechts 3 bytes worden gebruikt. Na de gegevenscompressie wordt er bij dit type gegevens geen blanco teken opgeslagen.
- De metadata van het record is verminderd.
- NULL- en 0-waarden zijn geoptimaliseerd en er wordt geen ruimte in beslag genomen.
Paginacompressie
Paginacompressie is een geavanceerd niveau van gegevenscompressie. Standaard implementeert een paginacompressie ook de compressie op rijniveau. Paginacompressie is onderverdeeld in twee typen
- Compressie voorvoegsel en
- Woordenboekcompressie.
Compressie voorvoegsel
Bij prefix-compressie voor elke pagina wordt voor elke kolom op de pagina een gemeenschappelijke waarde opgehaald uit alle rijen en opgeslagen onder de kop in elke kolom. Nu wordt in elke rij een verwijzing naar die waarde opgeslagen in plaats van een algemene waarde.
Woordenboekcompressie
Woordenboekcompressie is vergelijkbaar met prefixcompressie, maar gemeenschappelijke waarden worden opgehaald uit alle kolommen en opgeslagen in de tweede rij na de koptekst. Woordenboekcompressie zoekt naar exacte waardeovereenkomsten in alle kolommen en rijen op elke pagina.
We kunnen compressie op rij- en paginaniveau uitvoeren voor de volgende database-objecten.
- Een tafel opgeslagen op een hoop.
- Een hele tabel opgeslagen als een geclusterde index.
- Geïndexeerde weergave.
- Niet-geclusterde index.
- Gepartitioneerde indexen en tabellen.
Opmerking: We kunnen gegevenscompressie uitvoeren op het moment van creatie, zoals CREATE TABLE, CREATE INDEX of na de creatie met behulp van de ALTER-opdracht met de REBUILD-optie zoals ALTER TABLE .... BOUWEN MET.
Demo
De WideWorldImporters database wordt gebruikt gedurende de gehele demo. Ook een realtime DW database wordt overwogen voor de compressiebewerking.
Laten we de stappen in detail doornemen:
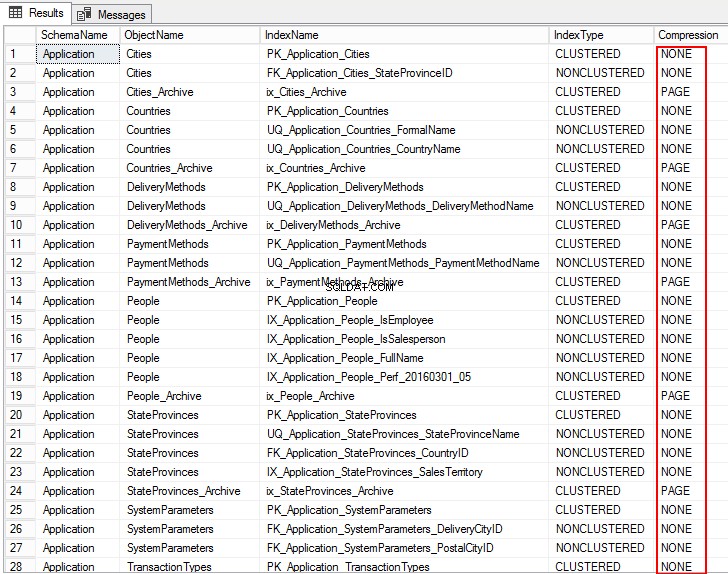
1. Voer de volgende T-SQL uit om de compressie-instellingen voor objecten in de database te bekijken:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
De volgende uitvoer toont het compressietype als PAGINA, RIJ en voor verschillende tabellen is het GEEN. Dit betekent dat het niet is geconfigureerd voor compressie.
2. Om de compressie te schatten, voert u de volgende door het systeem opgeslagen procedure sp_estimate_data_compression_savings uit . In dit geval wordt de opgeslagen procedure uitgevoerd op de PurchaseOrderLines-tabellen.
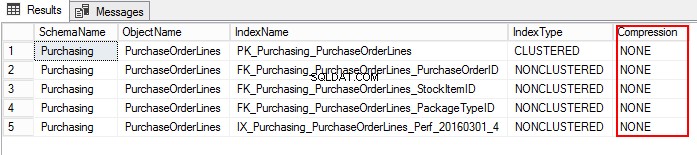
3. Laten we de compressie-instelling van PurchaseOrderLines achterhalen door de volgende T-SQL uit te voeren:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

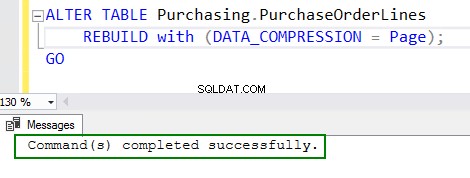
4. Schakel compressie in door het ALTER-tabelcommando uit te voeren:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
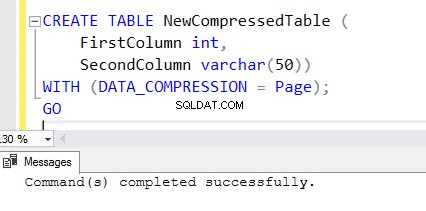
5. Als u een nieuwe tabel wilt maken met de functie voor compressie, voegt u de clausule WITH toe aan het einde van de CREATE TABLE-instructie. U kunt de onderstaande CREATE TABLE-instructie zien die is gebruikt om NewCompressedTable te maken .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Gegevenscompressiefeiten
Laten we wat van de feitelijke informatie over compressie doornemen
- Compressie kan niet worden toegepast op systeemtabellen
- Een tabel kan niet worden ingeschakeld voor compressie als de rij groter is dan 8060 bytes.
- Gecomprimeerde gegevens worden in de bufferpool opgeslagen; het betekent snellere reactietijden
- Als u compressie inschakelt, kunnen queryplannen worden gewijzigd omdat de gegevens worden opgeslagen met een ander aantal pagina's en een ander aantal rijen per pagina.
- Niet-geclusterde indexen nemen geen compressie-eigenschap over
- Als een geclusterde index op een heap wordt gemaakt, neemt de geclusterde index de compressiestatus van de heap over, tenzij een alternatieve compressiestatus is opgegeven.
- De compressies op ROW- en PAGE-niveau kunnen offline of online worden in- en uitgeschakeld.
- Als de heap-instelling wordt gewijzigd, moeten alle niet-geclusterde indexen opnieuw worden opgebouwd.
- De schijfruimtevereisten voor het in- of uitschakelen van de rij- of paginacompressie zijn dezelfde als voor het maken of opnieuw opbouwen van een index.
- Als partities worden gesplitst met behulp van de instructie ALTER PARTITION, nemen beide partities het gegevenscompressiekenmerk van de oorspronkelijke partitie over.
- Als twee partities worden samengevoegd, erft de resulterende partitie het gegevenscompressiekenmerk van de doelpartitie.
- Om van partitie te wisselen, moet de datacompressie-eigenschap van de partitie overeenkomen met de compressie-eigenschap van de tabel.
- Columnstore-tabellen en indexen worden altijd opgeslagen met de Columnstore-compressie.
- Gegevenscompressie is niet compatibel met dunne kolommen, dus de tabel kan niet worden gecomprimeerd.
Realtime scenario
Laten we de datacompressietechniek doornemen en de belangrijkste parameters van datacompressie begrijpen.
Voer de volgende T-SQL uit om de ruimte te controleren die door elke tabel wordt gebruikt. De uitvoer van de query geeft ons gedetailleerde informatie over het gebruik van elke tabel. Dit zou de beslissende factor zijn voor de implementatie van de datacompressie.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
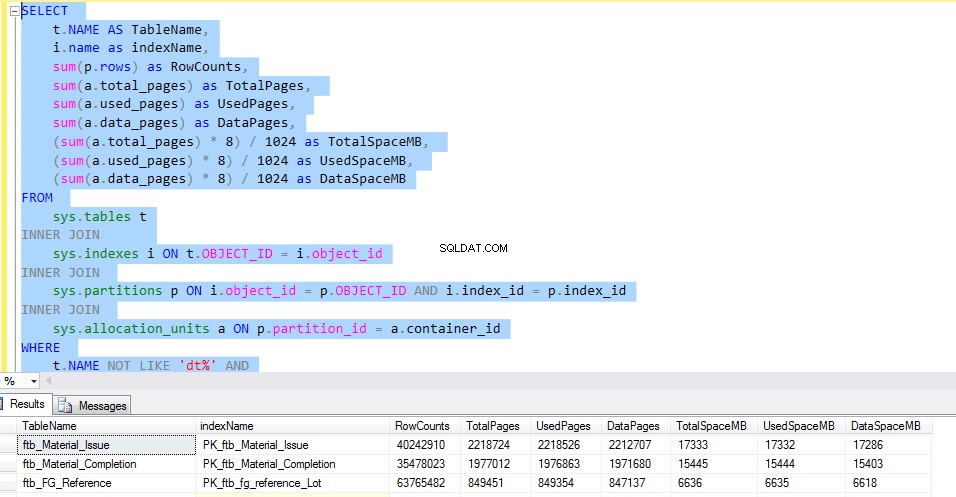
Laten we eens kijken naar de ftb_material_Issue feiten tabel. De feitentabel heeft numerieke BIGINT-gegevenstypen.
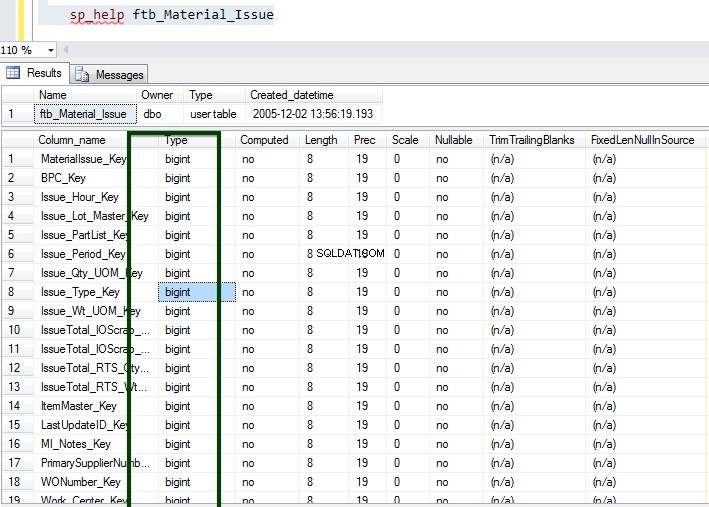
Voer nu de opgeslagen procedure sp_spaceused uit om de details van de tabel te begrijpen. U kunt hier meer leren over het sp_spaceused-commando.
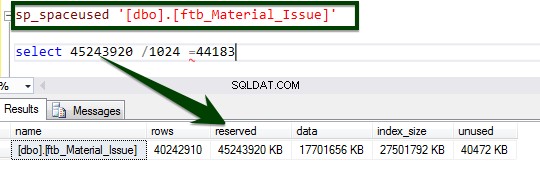
Schakel de compressie op tabelniveau in door de volgende T-SQL uit te voeren. De volgende T-SQL is uitgevoerd op de server en het duurde 34 minuten en 14 seconden om de pagina op tabelniveau te comprimeren.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
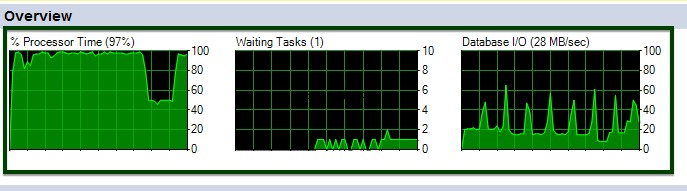
U kunt de CPU- en I/O-fluctuaties zien tijdens de uitvoering van het ALTER-tabelcommando.
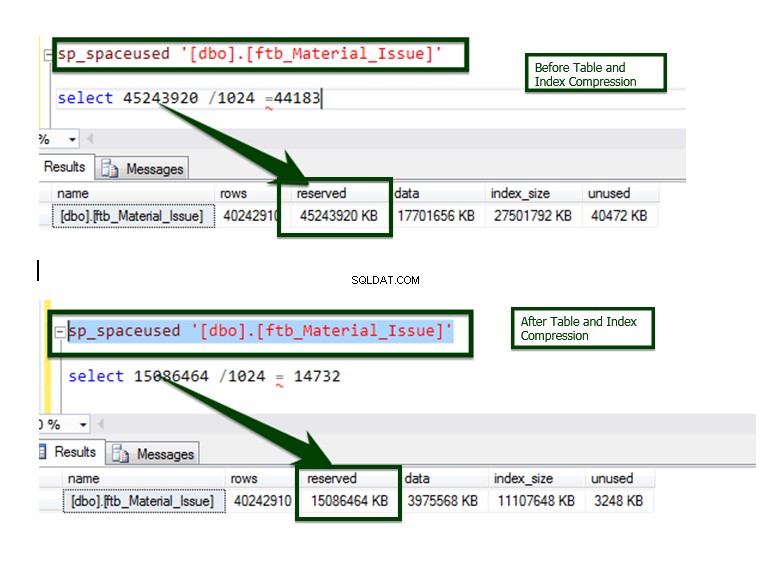
Laten we nu de Vergelijking van gegevenscompressie voor v/s na doen. De tabelgrootte van ongeveer ~45 GB is teruggebracht tot ~15 GB.
Het proces wordt op de meeste objecten geïmplementeerd met behulp van een geautomatiseerd script en hier is het eindresultaat van de vergelijking.
Gegevensvergelijking tussen voor en na de indexcompressie.

Samenvatting
Gegevenscompressie is een zeer effectieve techniek om de omvang van gegevens te verkleinen; minder data vereist minder I/O-processen. Het toevoegen van compressie aan de database verhoogt de belasting van de CPU-vereisten. U moet ervoor zorgen dat u over de beschikbare verwerkingscapaciteit beschikt om deze wijzigingen op een efficiënte manier op te vangen. Het is dus beter om eerst een beetje onderzoek te doen en te zien welke soorten winst kunnen worden verwacht voordat u de wijzigingen toepast om gegevenscompressie mogelijk te maken. Het is zeer voordelig bij het opzetten van een clouddatabase waar kosten gemoeid zijn.
Voer de compressies uit (doe ze niet allemaal tegelijk) en comprimeer tijdens perioden van lage activiteit. Gegevenscompressie en back-upcompressie gaan goed samen en kunnen resulteren in extra opslagruimtebesparing, dus ga je gang en geniet ervan.
Compressie verkleint niet alleen de fysieke bestandsgrootte, maar vermindert ook de schijf-I/O, wat de prestaties van veel databasetoepassingen aanzienlijk kan verbeteren, samen met databaseback-ups.
Beslissen om compressie te implementeren is gemakkelijker als we de onderliggende infrastructuur en zakelijke vereisten kennen. We kunnen de beschikbare systeemprocedure zeker gebruiken om compressiebesparingen te begrijpen en te schatten. Deze opgeslagen procedure biedt geen dergelijke details die u vertellen hoe de compressie uw systeem positief of negatief zal beïnvloeden. Het is duidelijk dat er compromissen zijn met elke vorm van compressie. Als u dezelfde patronen van enorme gegevens hebt, is compressie de sleutel tot ruimtebesparing. Nu de CPU-kracht toeneemt en elk systeem gebonden is aan structuren met meerdere kernen, kan compressie voor veel systemen geschikt zijn. Ik zou aanraden om je systemen te testen. Test om ervoor te zorgen dat de prestaties niet negatief worden beïnvloed. Als een index veel updates en verwijderingen heeft, kunnen de CPU-kosten voor het comprimeren en decomprimeren van de gegevens opwegen tegen de I/O- en RAM-besparingen door gegevenscompressie. Niet elke database of tabel zal automatisch een goede kandidaat zijn om compressie op toe te passen, dus het is het beste om eerst een beetje onderzoek te doen om te zien welke winsten kunnen worden verwacht voordat u de wijzigingen toepast om gegevenscompressie op uw databases mogelijk te maken. U moet compressie testen om te zien of het goed werkt in uw omgeving, omdat het mogelijk niet goed werkt in databases met zware invoegingen.
Referenties
Edities en ondersteunde functies van SQL Server 2016
Gegevenscompressie
Implementatie van rijcompressie
Implementatie van paginacompressie