Hoewel SQL Server op Linux bijna alle krantenkoppen over v.Next heeft gestolen, zijn er nog enkele andere interessante ontwikkelingen in de volgende versie van ons favoriete databaseplatform. Op het T-SQL-front hebben we eindelijk een ingebouwde manier om gegroepeerde tekenreeksaaneenschakeling uit te voeren:STRING_AGG() .
Laten we zeggen dat we de volgende eenvoudige tabelstructuur hebben:
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
Voor prestatietests gaan we dit invullen met sys.all_objects en sys.all_columns . Maar laten we voor een eenvoudige demonstratie eerst de volgende rijen toevoegen:
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); Als de forums een indicatie zijn, is het een veel voorkomende vereiste om voor elk object een rij te retourneren, samen met een door komma's gescheiden lijst met kolomnamen. (Extrapoleer dat naar elk type entiteit dat u op deze manier modelleert - productnamen die zijn gekoppeld aan een bestelling, namen van onderdelen die betrokken zijn bij de assemblage van een product, ondergeschikten die rapporteren aan een manager, enz.) Dus, bijvoorbeeld, met de bovenstaande gegevens zouden we wil output als volgt:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
De manier waarop we dit in de huidige versies van SQL Server zouden bereiken, is waarschijnlijk om FOR XML PATH te gebruiken , zoals ik in deze eerdere post heb laten zien de meest efficiënte buiten CLR te zijn. In dit voorbeeld ziet het er als volgt uit:
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Zoals te verwachten is, krijgen we dezelfde output die hierboven is gedemonstreerd. In SQL Server v.Next kunnen we dit eenvoudiger uitdrukken:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Nogmaals, dit levert exact dezelfde uitvoer op. En we waren in staat om dit te doen met een native functie, waarbij we zowel de dure FOR XML PATH steigers, en de STUFF() functie die wordt gebruikt om de eerste komma te verwijderen (dit gebeurt automatisch).
Hoe zit het met de bestelling?
Een van de problemen met veel van de kludge-oplossingen voor gegroepeerde aaneenschakeling is dat de volgorde van de door komma's gescheiden lijst als willekeurig en niet-deterministisch moet worden beschouwd.
Voor het XML PATH oplossing, heb ik in een ander eerder bericht aangetoond dat het toevoegen van een ORDER BY is triviaal en gegarandeerd. Dus in dit voorbeeld kunnen we de kolomlijst alfabetisch op kolomnaam ordenen in plaats van het aan SQL Server over te laten om te sorteren (of niet):
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; Uitgang:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1 voegt WITHIN GROUP . toe naar STRING_AGG() , dus met de nieuwe aanpak kunnen we zeggen:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
Nu krijgen we dezelfde resultaten. Merk op dat, net als een normale ORDER BY clausule, kunt u meerdere bestelkolommen of uitdrukkingen toevoegen binnen WITHIN GROUP () .
Ok, al optreden!
Met behulp van quad-core 2,6 GHz-processors, 8 GB geheugen en SQL Server CTP1.1 (14.0.100.187), heb ik een nieuwe database gemaakt, deze tabellen opnieuw gemaakt en rijen toegevoegd uit sys.all_objects en sys.all_columns . Ik heb ervoor gezorgd dat alleen objecten zijn opgenomen die ten minste één kolom hadden:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); Op mijn systeem leverde dit 656 objecten en 8.085 kolommen op (uw systeem kan iets andere getallen opleveren).
De plannen
Laten we eerst de abonnementen en Tabel I/O-tabbladen voor onze twee ongeordende query's vergelijken met Plan Explorer. Dit zijn de algemene runtime-statistieken:
 Runtime-statistieken voor XML PATH (boven) en STRING_AGG() (onder)
Runtime-statistieken voor XML PATH (boven) en STRING_AGG() (onder)
Het grafische plan en Tabel I/O van het FOR XML PATH vraag:
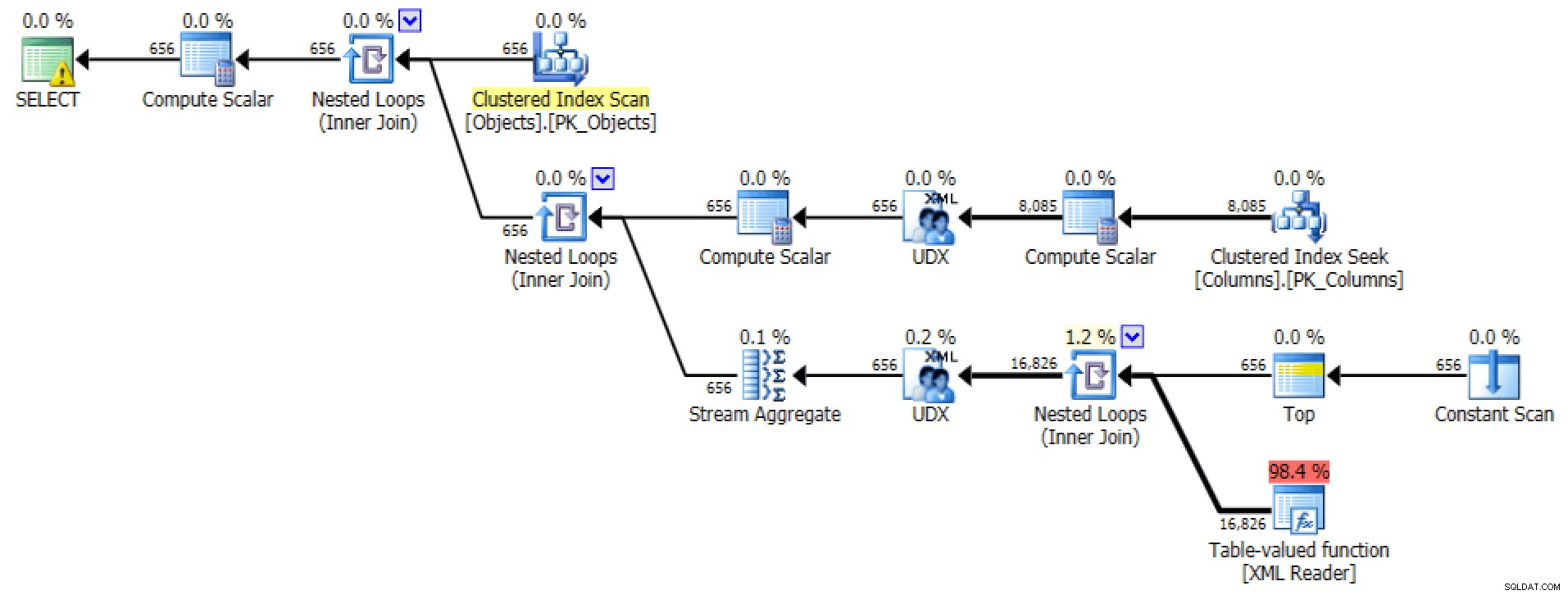
 Plan en tabel I/O voor XML PATH, geen bestelling
Plan en tabel I/O voor XML PATH, geen bestelling
En van de STRING_AGG versie:
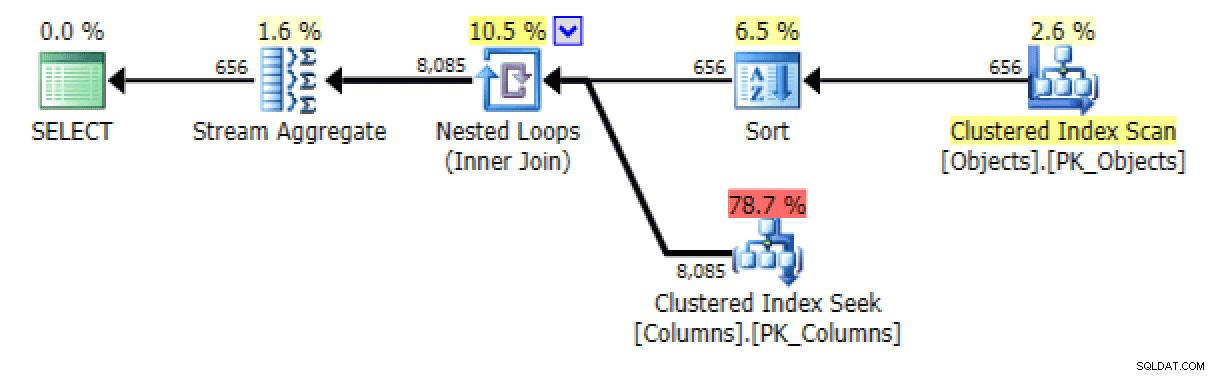
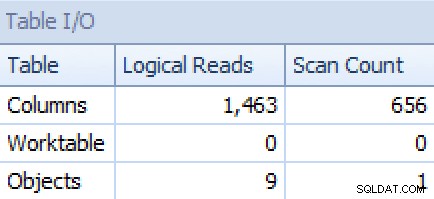 Plan en tabel I/O voor STRING_AGG, geen bestelling
Plan en tabel I/O voor STRING_AGG, geen bestelling
Voor de laatste lijkt het zoeken naar geclusterde indexen een beetje verontrustend. Dit leek een goede reden om de zelden gebruikte FORCESCAN . te testen hint (en nee, dit zou zeker niet helpen bij het FOR XML PATH vraag):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; Nu zien het plan en het tabblad Tabel I/O er veel uit beter, althans op het eerste gezicht:
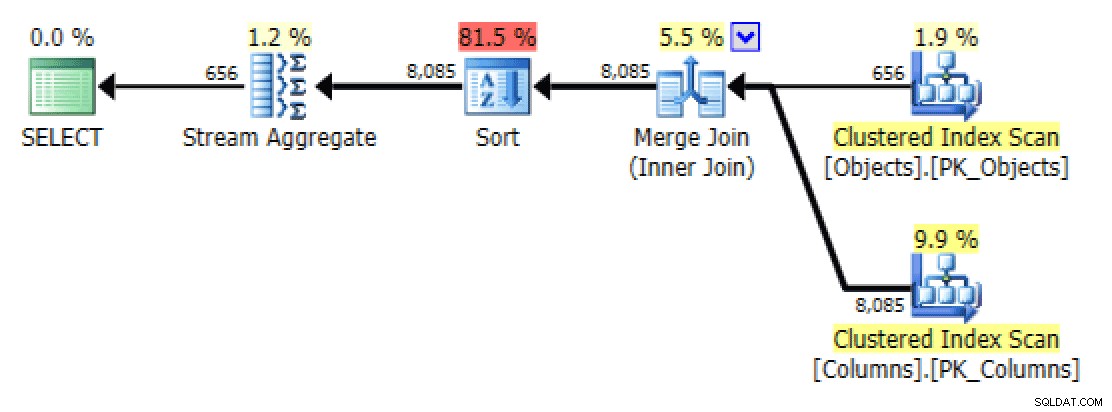
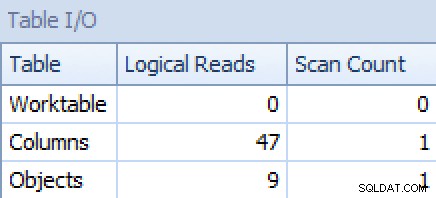 Plan en tabel I/O voor STRING_AGG(), geen bestelling, met FORCESCAN
Plan en tabel I/O voor STRING_AGG(), geen bestelling, met FORCESCAN
De geordende versies van de query's genereren ongeveer dezelfde plannen. Voor het FOR XML PATH versie is een sortering toegevoegd:
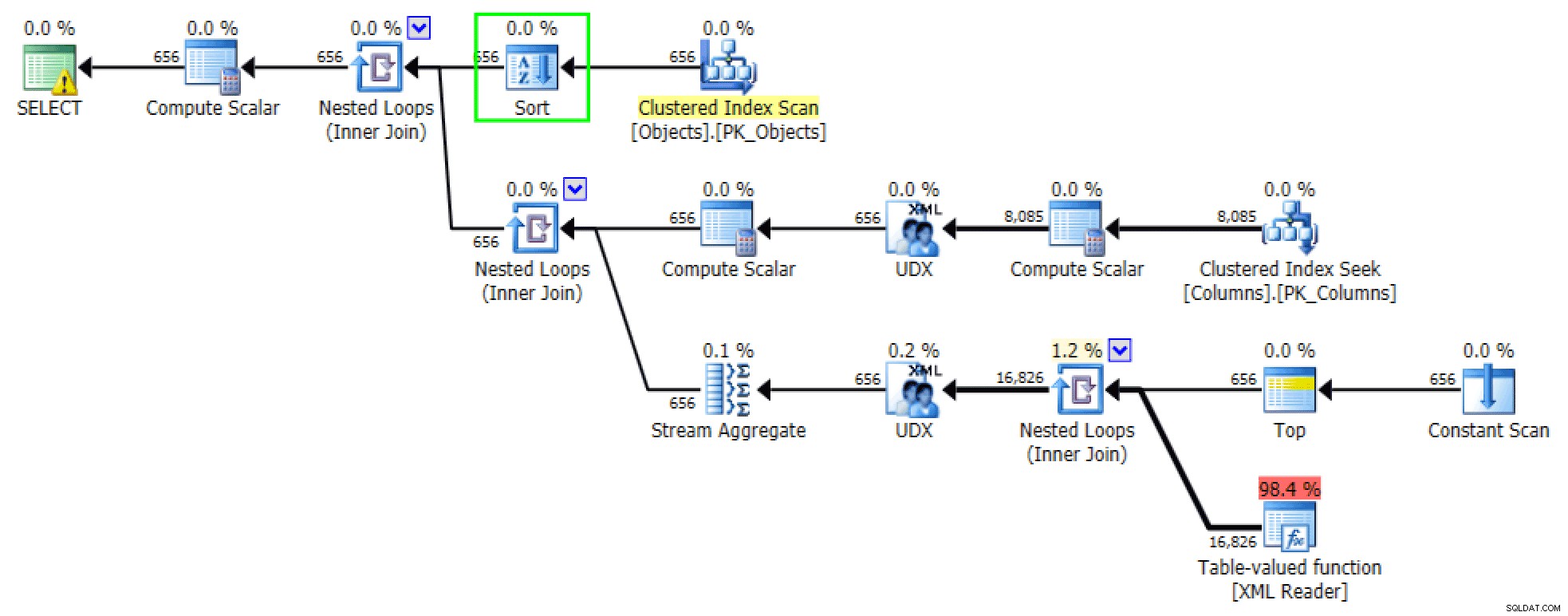 Sorteren toegevoegd in FOR XML PATH-versie
Sorteren toegevoegd in FOR XML PATH-versie
Voor STRING_AGG() , wordt in dit geval gekozen voor een scan, ook zonder de FORCESCAN hint, en er is geen extra sorteerbewerking vereist - dus het plan ziet er identiek uit aan de FORCESCAN versie.
Op schaal
Als we kijken naar een plan en eenmalige runtime-statistieken, kunnen we misschien een idee krijgen of STRING_AGG() presteert beter dan het bestaande FOR XML PATH oplossing, maar een grotere test is misschien logischer. Wat gebeurt er als we de gegroepeerde aaneenschakeling 5.000 keer uitvoeren?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
Nadat ik dit script vijf keer had uitgevoerd, nam ik het gemiddelde van de duur en hier zijn de resultaten:
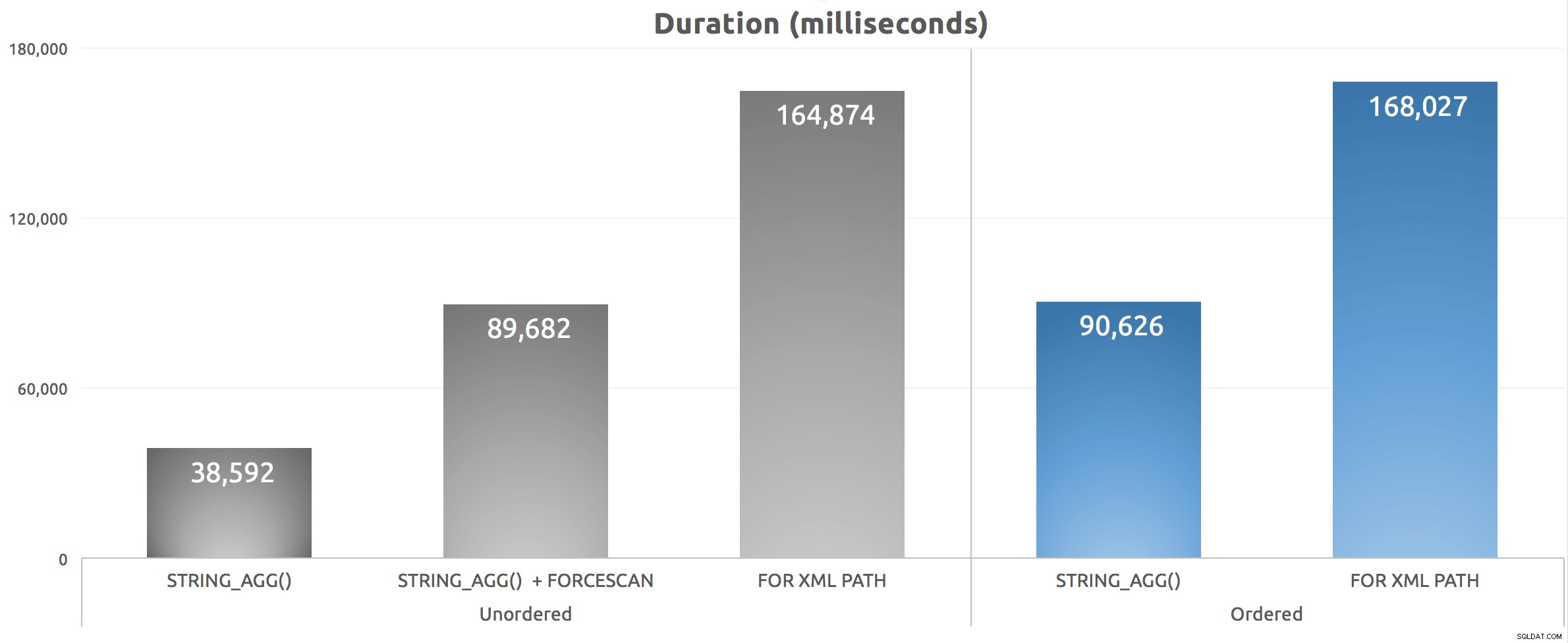 Duur (milliseconden) voor verschillende benaderingen van gegroepeerde aaneenschakeling
Duur (milliseconden) voor verschillende benaderingen van gegroepeerde aaneenschakeling
We kunnen zien dat onze FORCESCAN hint heeft de zaken echt erger gemaakt - terwijl we de kosten hebben verschoven van het zoeken naar geclusterde indexen, was het soort eigenlijk veel erger, hoewel de geschatte kosten ze relatief gelijkwaardig achtten. Wat nog belangrijker is, we kunnen zien dat STRING_AGG() biedt wel een prestatievoordeel, ongeacht of de aaneengeschakelde snaren op een specifieke manier moeten worden besteld. Net als bij STRING_SPLIT() , waar ik in maart naar keek, ben ik behoorlijk onder de indruk dat deze functie ruim vóór "v1" schaalt.
Ik heb verdere tests gepland, misschien voor een toekomstige post:
- Als alle gegevens uit één enkele tabel komen, met en zonder een index die ordening ondersteunt
- Vergelijkbare prestatietests op Linux
Als je in de tussentijd specifieke gebruiksscenario's hebt voor gegroepeerde aaneenschakeling, deel ze dan hieronder (of e-mail me op abertrand@sentryone.com). Ik sta er altijd voor open om ervoor te zorgen dat mijn tests zo realistisch mogelijk zijn.