Vorige week heb ik een paar snelle prestatievergelijkingen gemaakt, waarbij ik gebruik maakte van de nieuwe STRING_AGG() functie tegen het traditionele FOR XML PATH aanpak die ik al tijden gebruik. Ik heb zowel ongedefinieerde/willekeurige volgorde als expliciete volgorde getest, en STRING_AGG() kwam in beide gevallen als beste uit de bus:
- SQL Server v.Next:STRING_AGG() Prestaties, Deel 1
Voor die tests heb ik verschillende dingen weggelaten (niet allemaal opzettelijk):
- Mikael Eriksson en Grzegorz Łyp wezen er allebei op dat ik niet de absoluut meest efficiënte
FOR XML PATHgebruikte. bouwen (en voor de duidelijkheid, ik heb dat nooit gedaan). - Ik heb geen tests uitgevoerd op Linux; alleen op Windows. Ik verwacht niet dat die heel verschillend zullen zijn, maar aangezien Grzegorz heel verschillende tijdsduren zag, is dit nader onderzoek waard.
- Ik heb ook alleen getest wanneer uitvoer een eindige, niet-LOB-tekenreeks zou zijn - wat volgens mij de meest voorkomende gebruikssituatie is (ik denk niet dat mensen gewoonlijk elke rij in een tabel samenvoegen tot één door komma's gescheiden string, maar dit is de reden waarom ik in mijn vorige post om uw use-case (s) heb gevraagd).
- Voor de besteltests heb ik geen index gemaakt die nuttig zou kunnen zijn (of iets geprobeerd waarbij alle gegevens uit één enkele tabel kwamen).
In dit bericht ga ik een paar van deze items behandelen, maar niet allemaal.
VOOR XML-PAD
Ik had het volgende gebruikt:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Na deze opmerking van Mikael heb ik mijn code bijgewerkt om in plaats daarvan deze iets andere constructie te gebruiken:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux versus Windows
Aanvankelijk had ik alleen de moeite genomen om tests op Windows uit te voeren:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Maar Grzegorz maakte duidelijk dat hij (en vermoedelijk vele anderen) alleen toegang had tot de Linux-smaak van CTP 1.1. Dus heb ik Linux aan mijn testmatrix toegevoegd:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Enkele interessante maar volledig tangentiële observaties:
@@VERSIONtoont geen editie in deze build, maarSERVERPROPERTY('Edition')retourneert de verwachteDeveloper Edition (64-bit).- Op basis van de bouwtijden die in de binaire bestanden zijn gecodeerd, lijken de Windows- en Linux-versies nu op hetzelfde moment en uit dezelfde bron te zijn gecompileerd. Of dit was een gek toeval.
Ongeordende tests
Ik begon met het testen van de willekeurig geordende uitvoer (waar er geen expliciet gedefinieerde volgorde is voor de aaneengeschakelde waarden). In navolging van Grzegorz gebruikte ik WideWorldImporters (standaard), maar voerde een join uit tussen Sales.Orders en Sales.OrderLines . De fictieve vereiste hier is om een lijst van alle bestellingen uit te voeren, en samen met elke bestelling, een door komma's gescheiden lijst van elke StockItemID .
Sinds StockItemID is een geheel getal, we kunnen een gedefinieerde varchar . gebruiken , wat betekent dat de string 8000 tekens lang kan zijn voordat we ons zorgen hoeven te maken dat we MAX nodig hebben. Aangezien een int een maximale lengte van 11 kan hebben (echt 10, indien niet ondertekend), plus een komma, betekent dit dat een bestelling in het ergste geval ongeveer 8.000/12 (666) voorraadartikelen moet ondersteunen (bijv. alle StockItemID-waarden hebben 11 cijfers). In ons geval is de langste ID 3 cijfers, dus totdat er gegevens worden toegevoegd, zouden we in feite 8.000/4 (2.000) unieke voorraadartikelen in een enkele bestelling nodig hebben om MAX te rechtvaardigen. In ons geval zijn er in totaal maar 227 artikelen op voorraad, dus MAX is niet nodig, maar dat moet je goed in de gaten houden. Als zo'n grote reeks in uw scenario mogelijk is, moet u varchar(max) gebruiken in plaats van de standaard (STRING_AGG() retourneert nvarchar(max) , maar wordt afgekapt tot 8.000 bytes tenzij de invoer is een MAX-type).
De initiële zoekopdrachten (om voorbeelduitvoer te tonen en om de duur van enkele uitvoeringen te observeren):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Ik negeerde de ontledings- en compileertijdgegevens volledig, omdat ze altijd precies nul waren of dichtbij genoeg om niet relevant te zijn. Er waren kleine afwijkingen in de uitvoeringstijden voor elke run, maar niet veel - de opmerkingen hierboven weerspiegelen de typische delta in runtime (STRING_AGG leek daar een klein voordeel te halen uit parallellisme, maar alleen op Linux, terwijl FOR XML PATH niet op beide platforms). Beide machines hadden een enkele socket, toegewezen quad-core CPU, 8 GB geheugen, kant-en-klare configuratie en geen andere activiteit.
Toen wilde ik op schaal testen (eenvoudig een enkele sessie die 500 keer dezelfde query uitvoert). Ik wilde niet alle uitvoer, zoals in de bovenstaande query, 500 keer retourneren, omdat dat SSMS zou hebben overweldigd - en hopelijk vertegenwoordigt het hoe dan ook geen real-world queryscenario's. Dus ik heb de uitvoer toegewezen aan variabelen en heb zojuist de totale tijd voor elke batch gemeten:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Ik heb die tests drie keer uitgevoerd en het verschil was enorm - bijna een orde van grootte. Hier is de gemiddelde duur van de drie tests:
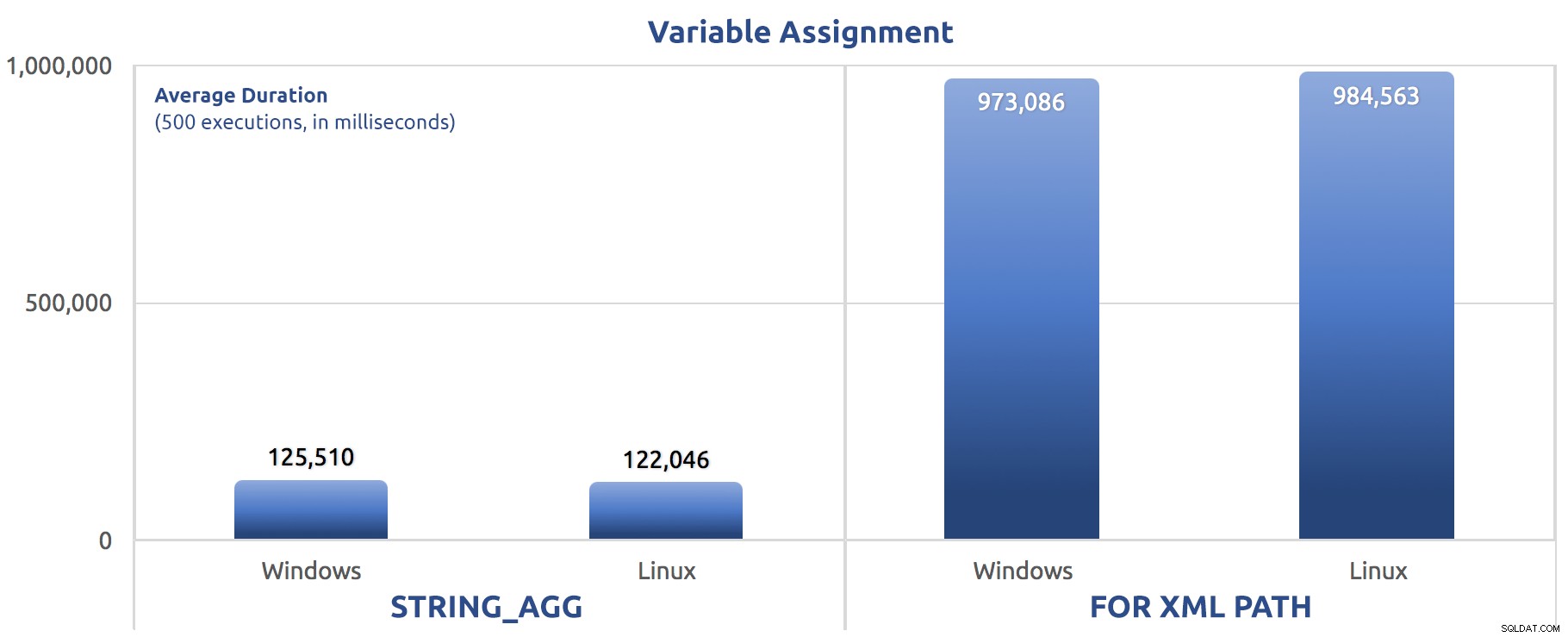 Gemiddelde duur, in milliseconden, voor 500 uitvoeringen van variabele toewijzing
Gemiddelde duur, in milliseconden, voor 500 uitvoeringen van variabele toewijzing
Ik heb op deze manier ook een aantal andere dingen getest, vooral om er zeker van te zijn dat ik de soorten tests dekte die Grzegorz uitvoerde (zonder het LOB-gedeelte).
- Alleen de lengte van de uitvoer selecteren
- De maximale lengte van de uitvoer ophalen (van een willekeurige rij)
- Alle uitvoer selecteren in een nieuwe tabel
Alleen de lengte van de uitvoer selecteren
Deze code loopt alleen door elke bestelling, voegt alle StockItemID-waarden samen en retourneert vervolgens alleen de lengte.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Voor de batchversie heb ik opnieuw variabele toewijzing gebruikt in plaats van te proberen veel resultatensets terug te sturen naar SSMS. De variabele toewijzing zou op een willekeurige rij terechtkomen, maar dit vereist nog steeds volledige scans, omdat de willekeurige rij niet als eerste wordt geselecteerd.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Prestatiestatistieken van 500 uitvoeringen:
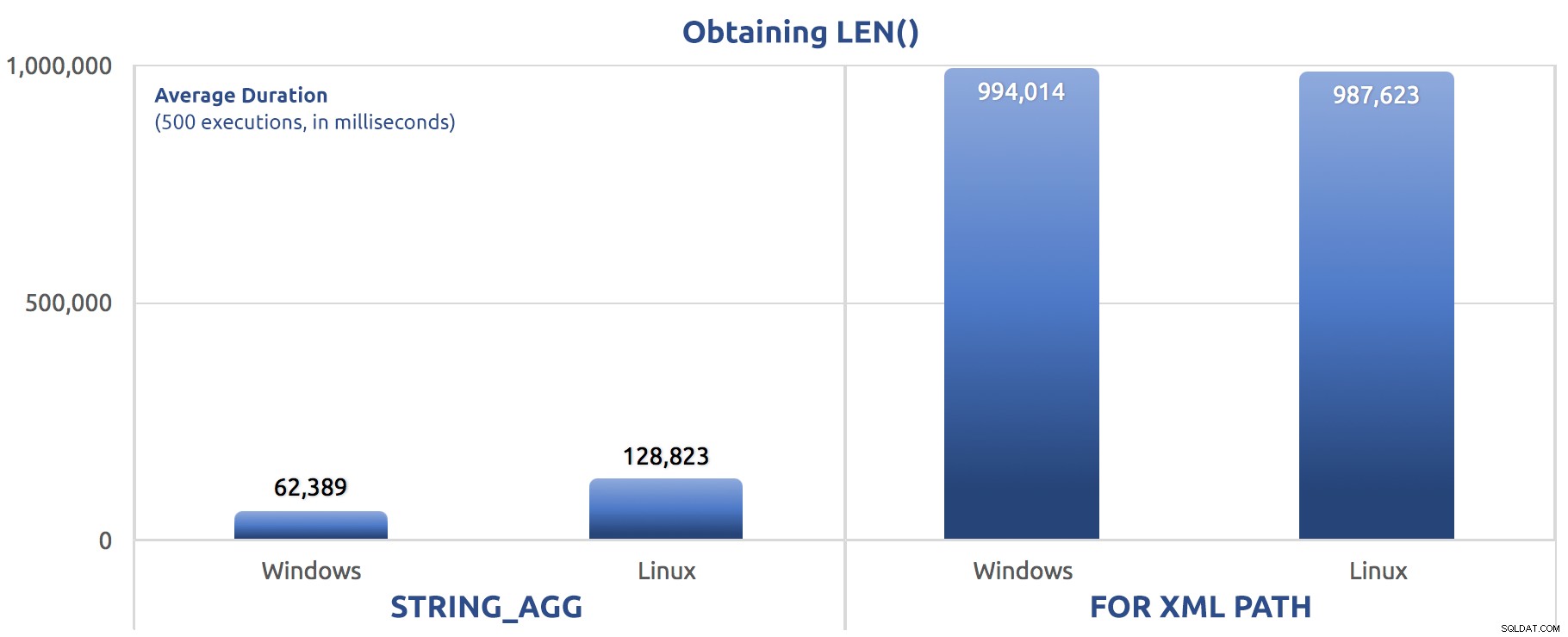 500 uitvoeringen van het toewijzen van LEN() aan een variabele
500 uitvoeringen van het toewijzen van LEN() aan een variabele
Nogmaals, we zien FOR XML PATH is veel langzamer, zowel op Windows als Linux.
De maximale lengte van de uitgang selecteren
Een kleine variatie op de vorige test, deze haalt gewoon het maximum lengte van de aaneengeschakelde uitvoer:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ En op schaal wijzen we die uitvoer gewoon weer toe aan een variabele:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Prestatieresultaten, voor 500 uitvoeringen, gemiddeld over drie runs:
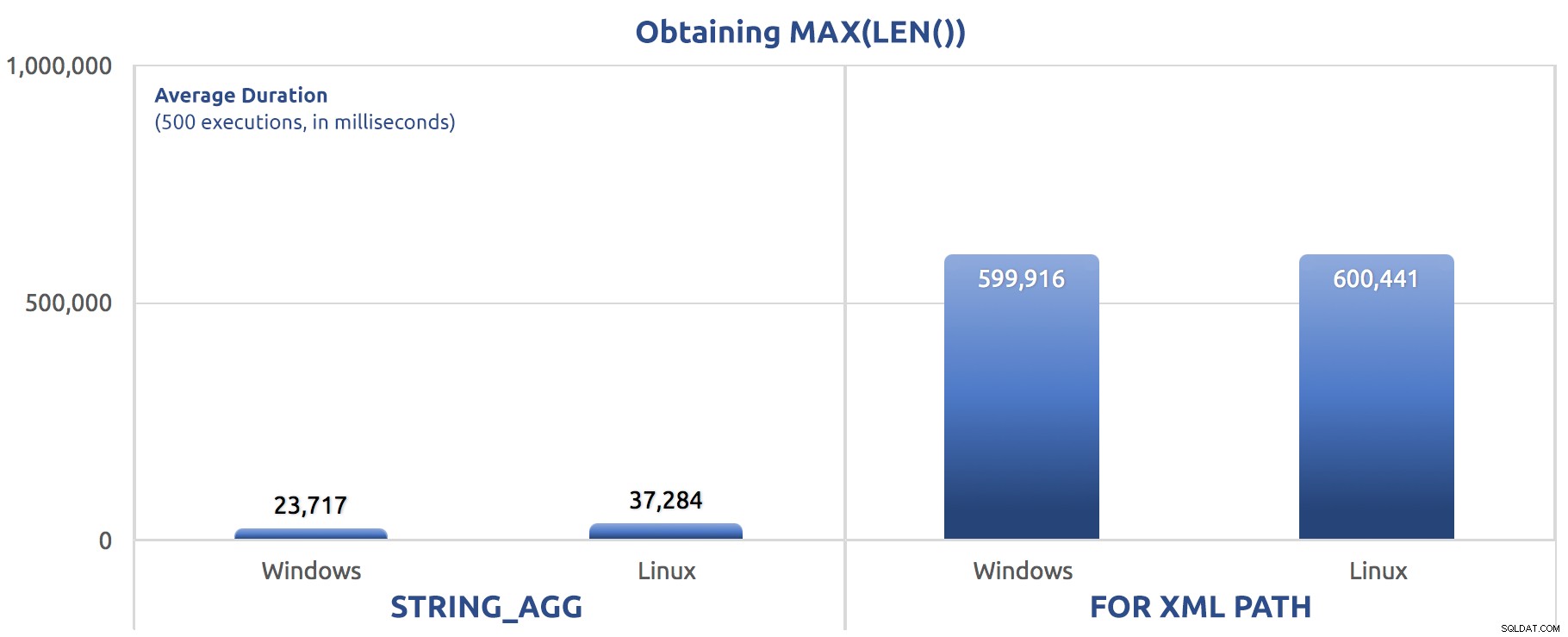 500 uitvoeringen van het toewijzen van MAX(LEN()) aan een variabele
500 uitvoeringen van het toewijzen van MAX(LEN()) aan een variabele
Je zou een patroon kunnen opmerken in deze tests - FOR XML PATH is altijd een hond, zelfs met de prestatieverbeteringen die in mijn vorige bericht zijn voorgesteld.
SELECTEER IN
Ik wilde zien of de methode van aaneenschakeling enige invloed had op schrijven de gegevens terug naar schijf, zoals het geval is in sommige andere scenario's:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
In dit geval zien we dat misschien SELECT INTO kon profiteren van een beetje parallellisme, maar toch zien we FOR XML PATH worstelen, met looptijden die een orde van grootte langer zijn dan STRING_AGG .
De batchversie heeft zojuist de SET STATISTICS-commando's verwisseld voor SELECT sysdatetime(); en dezelfde GO 500 . toegevoegd na de twee hoofdbatches zoals bij de vorige tests. Hier is hoe dat uitpakte (nogmaals, vertel me of je deze eerder hebt gehoord):
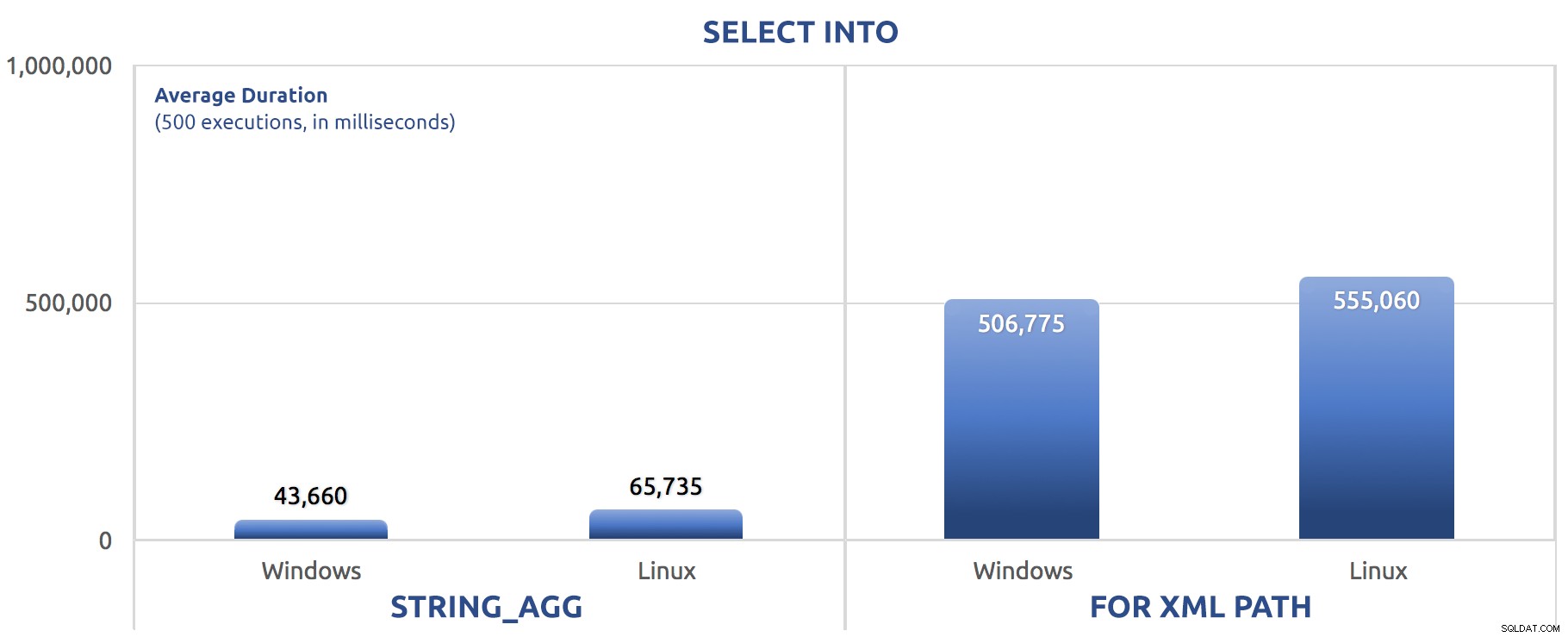 500 uitvoeringen van SELECT INTO
500 uitvoeringen van SELECT INTO
Bestelde tests
Ik heb dezelfde tests uitgevoerd met de geordende syntaxis, bijvoorbeeld:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Dit had heel weinig invloed op iets - dezelfde set van vier testopstellingen vertoonde over de hele linie bijna identieke statistieken en patronen.
Ik ben benieuwd of dit anders is wanneer de aaneengeschakelde uitvoer in niet-LOB staat of waar de aaneenschakeling strings moet bestellen (met of zonder een ondersteunende index).
Conclusie
Voor niet-LOB-tekenreeksen , is het mij duidelijk dat STRING_AGG heeft een definitief prestatievoordeel ten opzichte van FOR XML PATH , zowel op Windows als Linux. Merk op dat, om de eis van varchar(max) te vermijden, of nvarchar(max) , heb ik niets gebruikt dat lijkt op de tests die Grzegorz uitvoerde, wat zou betekenen dat alle waarden uit een kolom, over een hele tabel, in een enkele reeks zouden worden samengevoegd. In mijn volgende bericht zal ik de gebruikssituatie bekijken waarbij de uitvoer van de aaneengeschakelde string mogelijk groter is dan 8.000 bytes, en dus LOB-typen en -conversies zouden moeten worden gebruikt.