Inleiding
Terugspoelen zijn specifiek voor operators aan de binnenkant van een geneste loops join of apply. Het idee is om eerder berekende resultaten van een deel van een uitvoeringsplan opnieuw te gebruiken waar het veilig is om dit te doen.
Het canonieke voorbeeld van een plan-operator die kan terugspoelen is de luie Table Spool . Zijn raison d'être is om resultaatrijen van een plan-subboom in de cache op te slaan en die rijen vervolgens opnieuw af te spelen bij volgende iteraties als eventuele gecorreleerde lusparameters ongewijzigd zijn. Het opnieuw afspelen van rijen kan goedkoper zijn dan het opnieuw uitvoeren van de substructuur die ze heeft gegenereerd. Voor meer achtergrondinformatie over deze prestatiespoelen zie mijn eerdere artikel.
De documentatie zegt dat alleen de volgende operators kunnen terugspoelen:
- Tafelspoel
- Rijtelling spoel
- Niet-geclusterde indexspoel
- Tabelwaardefunctie
- Sorteren
- Externe zoekopdracht
- Bevestigen en Filteren operators met een Opstartexpressie
De eerste drie items zijn meestal prestatiespoelen, hoewel ze om andere redenen kunnen worden geïntroduceerd (wanneer ze zowel gretig als lui kunnen zijn).
Tafelwaardige functies gebruik een tabelvariabele, die kan worden gebruikt om resultaten in de cache op te slaan en opnieuw af te spelen in geschikte omstandigheden. Als u geïnteresseerd bent in het terugspoelen van functies met tabelwaarde, raadpleeg dan mijn Q &A over Stack Exchange voor databasebeheerders.
Met die uit de weg, gaat dit artikel uitsluitend over Sorten en wanneer ze kunnen terugspoelen.
Sorteer terugspoelen
Soorten gebruiken opslag (geheugen en misschien schijf als ze morsen), dus ze hebben een faciliteit die in staat is van het opslaan van rijen tussen lus-iteraties. Met name de gesorteerde uitvoer kan in principe worden afgespeeld (teruggespoeld).
Toch is het korte antwoord op de titelvraag:"Do Sorts Rewind?" is:
Ja, maar je zult het niet vaak zien.
Soort typen
Er zijn intern veel verschillende soorten soorten, maar voor onze huidige doeleinden zijn er slechts twee:
- In geheugen sorteren (
CQScanInMemSortNew).- Altijd in het geheugen; kan niet morsen naar schijf.
- Gebruikt standaard bibliotheek snel sorteren.
- Maximaal 500 rijen en twee pagina's van 8 KB in totaal.
- Alle ingangen moeten runtime-constanten zijn. Meestal betekent dit dat de hele sorteersubboom moet bestaan uit alleen Constante scan en/of Compute Scalar operators.
- Alleen expliciet te onderscheiden in uitvoeringsplannen wanneer uitgebreide showplan is ingeschakeld (traceervlag 8666). Dit voegt extra eigenschappen toe aan de Sorteren operator, waarvan er één "InMemory=[0|1]" is.
- Alle andere soorten.
(Beide typen Sorteren operator zijn Top N Sort en Verschillende sortering varianten).
Rewind-gedragingen
-
In-memory sorteringen kan altijd terugspoelen wanneer het veilig is. Als er geen gecorreleerde lusparameters zijn, of als de parameterwaarden ongewijzigd zijn ten opzichte van de onmiddellijk voorafgaande iteratie, kan dit type sortering de opgeslagen gegevens opnieuw afspelen in plaats van operators eronder opnieuw uit te voeren in het uitvoeringsplan.
-
Niet-in-geheugen sorteringen kan terugspoelen indien veilig, maar alleen als de Sorteren operator bevat maximaal één rij . Let op een Sorteren invoer kan voor sommige iteraties één rij opleveren, maar niet voor andere. Het runtime-gedrag kan daarom een complexe mix zijn van terugspoelen en opnieuw binden. Het hangt volledig af van het aantal rijen dat aan de Sorteren . wordt gegeven op elke iteratie tijdens runtime. U kunt over het algemeen niet voorspellen wat een Sorteer zal doen bij elke iteratie door het uitvoeringsplan te inspecteren.
Het woord "veilig" in de bovenstaande beschrijvingen betekent:Er is geen wijziging in de parameter opgetreden, of er zijn geen operators onder de Sorteren afhankelijk zijn van de gewijzigde waarde.
Belangrijke opmerking over uitvoeringsplannen
Uitvoeringsplannen rapporteren niet altijd correct terugspoelen (en opnieuw binden) voor Sorteren exploitanten. De operator zal rapporteren een terugspoelen als enige gecorreleerde parameters onveranderd zijn, en anders een herbinding.
Voor sorteringen die niet in het geheugen zijn (verreweg de meest voorkomende), zal een gerapporteerde terugspoeling de opgeslagen sorteerresultaten alleen daadwerkelijk afspelen als er maximaal één rij in de sorteeruitvoerbuffer is. Anders zal de sortering rapporteren een terugspoelen, maar de substructuur zal nog steeds volledig opnieuw worden uitgevoerd (een herinbinden).
Controleer het Aantal uitvoeringen . om te controleren hoeveel gerapporteerde terugspoelingen daadwerkelijke terugspoelingen waren eigenschap op operators onder de Sorteren .
Geschiedenis en mijn uitleg
Het Sorteren het terugspoelgedrag van de operator lijkt misschien vreemd, maar het is zo geweest van (tenminste) SQL Server 2000 tot en met SQL Server 2019 (evenals Azure SQL Database). Ik heb er geen officiële uitleg of documentatie over kunnen vinden.
Mijn persoonlijke mening is dat Sorteren terugspoelen is behoorlijk duur vanwege de onderliggende sorteermachines, inclusief spill-faciliteiten, en het gebruik van systeemtransacties in tempdb .
In de meeste gevallen zal de optimizer er beter aan doen om een expliciete performance spool te introduceren wanneer het de mogelijkheid van dubbele gecorreleerde lusparameters detecteert. Spools zijn de goedkoopste manier om gedeeltelijke resultaten te cachen.
Het is mogelijk dat het opnieuw afspelen van een Sorteer resultaat zou alleen maar kostenefficiënter zijn dan een Spool wanneer de Sorteren bevat maximaal één rij. Bij het sorteren van één rij (of geen rijen!) hoeft er eigenlijk helemaal niet te worden gesorteerd, waardoor een groot deel van de overhead kan worden vermeden.
Pure speculatie, maar iemand moest het vragen, dus daar is het.
Demo 1:Onnauwkeurig terugspoelen
Dit eerste voorbeeld bevat twee tabelvariabelen. De eerste bevat drie waarden die drie keer zijn gedupliceerd in kolom c1 . De tweede tabel bevat twee rijen voor elke match op c2 = c1 . De twee overeenkomende rijen worden onderscheiden door een waarde in kolom c3 .
De taak is om de rij uit de tweede tabel met de hoogste c3 . te retourneren waarde voor elke wedstrijd op c1 = c2 . De code is waarschijnlijk duidelijker dan mijn uitleg:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
De NO_PERFORMANCE_SPOOL hint is er om te voorkomen dat de optimizer een prestatiespoel introduceert. Dit kan gebeuren met tabelvariabelen wanneer b.v. traceringsvlag 2453 is ingeschakeld, of uitgestelde compilatie van tabelvariabelen is beschikbaar, zodat de optimizer de werkelijke kardinaliteit van de tabelvariabele kan zien (maar niet de waardeverdeling).
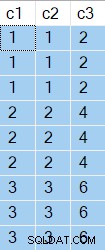
De zoekopdrachtresultaten tonen de c2 en c3 geretourneerde waarden zijn hetzelfde voor elke afzonderlijke c1 waarde:
Het daadwerkelijke uitvoeringsplan voor de query is:
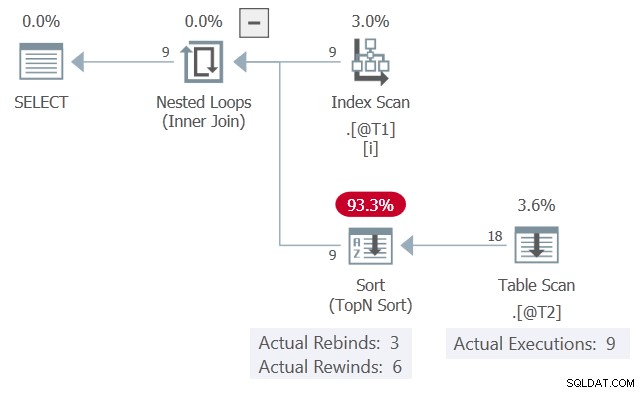
De c1 waarden, in volgorde gepresenteerd, komen 6 keer overeen met de vorige iteratie en veranderen 3 keer. Het Sorteren meldt dit als 6 keer terugspoelen en 3 keer opnieuw binden.
Als dit waar was, zou de Tabelscan zou slechts 3 keer worden uitgevoerd. Het Sorteren zou de resultaten bij de andere 6 gelegenheden opnieuw afspelen (terugspoelen).
Zoals het is, kunnen we de Tabelscan . zien werd 9 keer uitgevoerd, één keer voor elke rij uit tabel @T1 . Er is hier niet teruggespoeld .
Demo 2:Sort Rewinds
Het vorige voorbeeld stond de Sorteren . niet toe terugspoelen omdat (a) het geen In-Memory Sort is; en (b) bij elke iteratie van de lus, de Sorteren bevatte twee rijen. Planverkenner toont in totaal 18 rijen van de Tabelscan , twee rijen op elk van 9 iteraties.
Laten we het voorbeeld nu aanpassen, zodat er maar één . is rij in tabel @T2 voor elke overeenkomende rij van @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
De resultaten zijn hetzelfde als eerder getoond omdat we de overeenkomende rij hebben behouden die het hoogst sorteerde in kolom c3 . Het uitvoeringsplan is ook oppervlakkig gelijkaardig, maar met een belangrijk verschil:
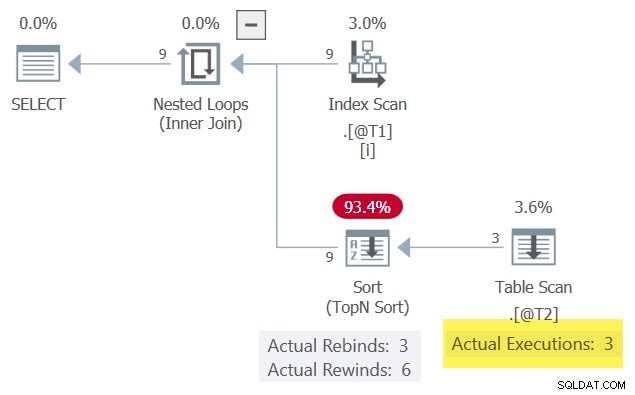
Met één rij in de Sorteren op elk moment kan het terugspoelen wanneer de gecorreleerde parameter c1 verandert niet. De Tabelscan wordt daardoor maar 3 keer uitgevoerd.
Let op de Sorteren produceert meer rijen (9) dan het ontvangt (3). Dit is een goede indicatie dat een Sorteren is erin geslaagd een resultatenset een of meerdere keren in de cache op te slaan - een succesvolle terugspoeling.
Demo 3:Niets terugspoelen
Ik zei al eerder dat een Sorteren kan terugspoelen wanneer het maximaal . bevat één rij.
Om dat in actie te zien met nul rijen , veranderen we in een OUTER APPLY en plaats geen rijen in tabel @T2 . Om redenen die binnenkort duidelijk zullen worden, zullen we ook stoppen met het projecteren van kolom c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
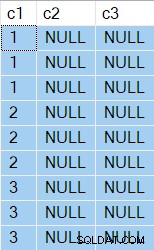
De resultaten hebben nu NULL in kolom c3 zoals verwacht:
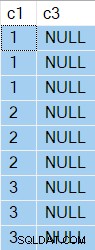
Het uitvoeringsplan is:
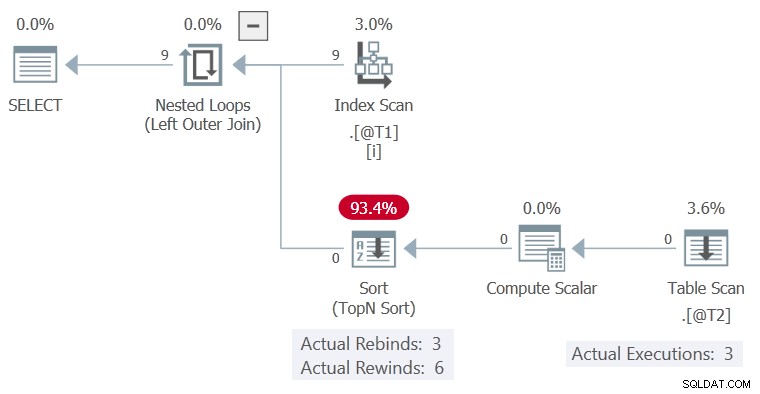
Het Sorteren kon terugspoelen zonder rijen in de buffer, dus de Table Scan werd slechts 3 keer uitgevoerd, telkens kolom c1 gewijzigde waarde.
Demo 4:Maximaal terugspoelen!
Net als de andere operators die terugspoelen ondersteunen, is een Sorteren zal alleen opnieuw binden zijn substructuur als een gecorreleerde parameter is gewijzigd en de substructuur hangt op de een of andere manier af van die waarde.
De kolom c2 herstellen projectie naar demo 3 zal dit in actie laten zien:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
De resultaten tonen nu twee NULL kolommen natuurlijk:
Het uitvoeringsplan is heel anders:
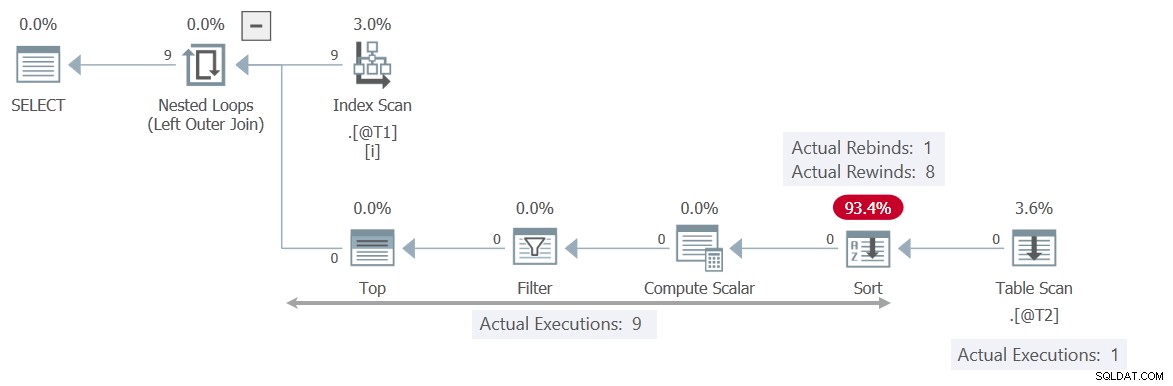
Deze keer de Filter bevat het vinkje T2.c2 = T1.c1 , waardoor de Tabelscan onafhankelijk van de huidige waarde van de gecorreleerde parameter c1 . Het Sorteren kan veilig 8 keer terugspoelen, wat betekent dat de scan slechts één keer wordt uitgevoerd .
Demo 5:sorteren in geheugen
Het volgende voorbeeld toont een In-Memory Sorteren operator:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); De resultaten die u krijgt, variëren van uitvoering tot uitvoering, maar hier is een voorbeeld:
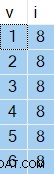
Het interessante zijn de waarden in kolom i zal altijd hetzelfde zijn — ondanks de ORDER BY NEWID() clausule.
Je hebt waarschijnlijk al geraden dat de reden hiervoor de Sorteren . is cacheresultaten (terugspoelen). Het uitvoeringsplan toont de Constant Scan slechts één keer uitvoeren, in totaal 11 rijen produceren:
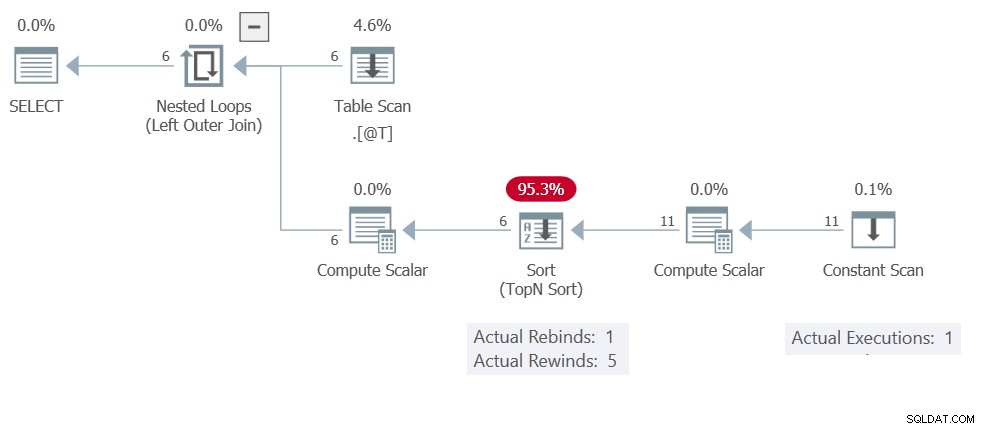
Dit Sorteren heeft alleen Compute Scalar en Constante scan operatoren op de invoer, dus het is een In geheugen sorteren . Onthoud dat deze niet beperkt zijn tot maximaal één rij — ze kunnen 500 rijen en 16 KB herbergen.
Zoals eerder vermeld, is het niet mogelijk om expliciet te zien of een Sorteren is In-Memory of niet door een regulier uitvoeringsplan te inspecteren. We hebben uitgebreide showplan-uitvoer nodig , ingeschakeld met ongedocumenteerde traceringsvlag 8666. Als dat is ingeschakeld, verschijnen er extra operatoreigenschappen:
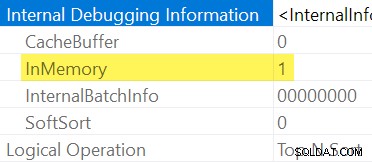
Als het niet praktisch is om ongedocumenteerde traceervlaggen te gebruiken, kunt u afleiden dat een Sorteren is "InMemory" door zijn Invoergeheugenfractie nul zijn, en Geheugengebruik elementen die niet beschikbaar zijn in showplan na uitvoering (op SQL Server-versies die die informatie ondersteunen).
Terug naar het uitvoeringsplan:er zijn geen gecorreleerde parameters, dus de Sorteren is vrij om 5 keer terug te spoelen, wat betekent dat de Constant Scan wordt maar één keer uitgevoerd. Verander gerust de TOP (1) naar TOP (3) of wat je maar wilt. Het terugspoelen betekent dat de resultaten hetzelfde zijn (cache/teruggespoeld) voor elke invoerrij.
U kunt last hebben van de ORDER BY NEWID() clausule die het terugspoelen niet verhindert. Dit is inderdaad een controversieel punt, maar helemaal niet beperkt tot soorten. Voor een uitgebreidere discussie (waarschuwing:mogelijk konijnenhol) zie deze Q &A. De korte versie is dat dit een bewuste productontwerpbeslissing is, waarbij de prestaties worden geoptimaliseerd, maar er zijn plannen om het gedrag in de loop van de tijd intuïtiever te maken.
Demo 6:Geen sortering in het geheugen
Dit is hetzelfde als demo 5, behalve dat de gerepliceerde tekenreeks één teken langer is:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Nogmaals, de resultaten zullen per uitvoering verschillen, maar hier is een voorbeeld. Let op de i waarden zijn nu niet allemaal hetzelfde:

Het extra teken is net genoeg om de geschatte grootte van de gesorteerde gegevens over 16 KB te duwen. Dit betekent een In-Memory Sort kan niet worden gebruikt en het terugspoelen verdwijnt.
Het uitvoeringsplan is:
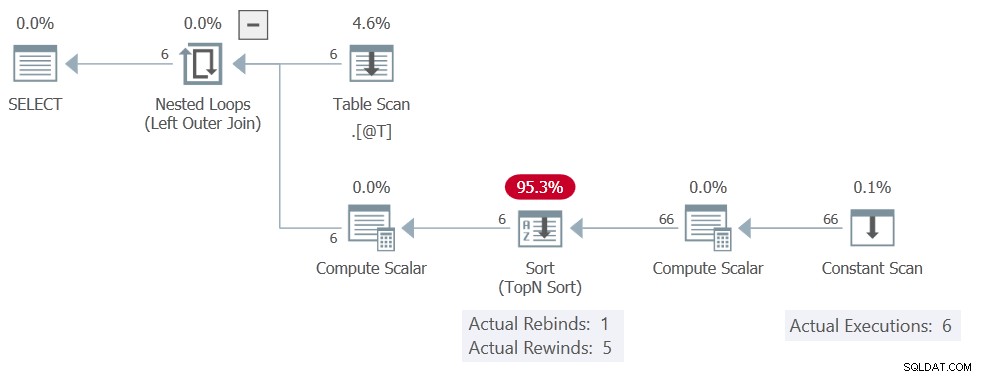
Het Sorteren nog rapporten 5 keer terugspoelen, maar de Constant Scan wordt 6 keer uitgevoerd, wat betekent dat er niet echt is teruggespoeld. Het produceert alle 11 rijen op elk van de 6 uitvoeringen, wat een totaal van 66 rijen oplevert.
Samenvatting en laatste gedachten
U ziet geen Sorteren operator echt heel vaak terugspoelen, hoewel je het zult zien zegt dat het deed best veel.
Onthoud, een normale Sorteer kan alleen terugspoelen als het veilig is en er is maximaal één rij tegelijk in de sortering. "Veilig" zijn betekent ofwel geen verandering in de luscorrelatieparameters, of niets onder de Sorteren wordt beïnvloed door de parameterwijzigingen.
Een In-memory sortering kan werken op maximaal 500 rijen en 16 KB aan gegevens afkomstig van Constant Scan en Compute Scalar alleen exploitanten. Het zal ook alleen terugspoelen als het veilig is (productfouten terzijde!) maar is niet beperkt tot maximaal één rij.
Dit lijken misschien esoterische details, en ik veronderstel dat ze dat ook zijn. Dus zeggend, hebben ze me meer dan eens geholpen een uitvoeringsplan te begrijpen en goede prestatieverbeteringen te vinden. Misschien vindt u de informatie ooit ook nuttig.
Pas op voor Soorten die meer rijen produceren dan ze op hun invoer hebben!
Als u een realistischer voorbeeld wilt zien van Sorteren terugspoelen op basis van een demo die Itzik Ben-Gan gaf in deel één van zijn Closest Match serie zie Dichtstbijzijnde match met Sort Rewinds.