Een lange tijd geleden beantwoordde ik een vraag over NULL op Stack Exchange met de titel:"Waarom zouden we geen NULL's toestaan?" Ik heb mijn deel van de ergernissen en passies van huisdieren, en de angst voor NULL's staat behoorlijk hoog op mijn lijst. Een collega zei onlangs tegen me, nadat hij de voorkeur had gegeven om een lege string te forceren in plaats van NULL toe te staan:
"Ik hou er niet van om met nulls in code om te gaan."
Het spijt me, maar dat is geen goede reden. Hoe de presentatielaag omgaat met lege strings of NULL's zou niet de driver moeten zijn voor uw tabelontwerp en gegevensmodel. En als u een "gebrek aan waarde" in een kolom toestaat, maakt het dan logisch uit of het "gebrek aan waarde" wordt weergegeven door een tekenreeks met een lengte van nul of een NULL? Of erger nog, een symbolische waarde zoals 0 of -1 voor gehele getallen, of 1900-01-01 voor datums?
Itzik Ben-Gan heeft onlangs een hele serie over NULL's geschreven en ik raad je ten zeerste aan om het allemaal door te nemen:
- NULL-complexiteit – Deel 1
- NULL-complexiteit – Deel 2
- NULL-complexiteit – Deel 3, Ontbrekende standaardfuncties en T-SQL-alternatieven
- NULL-complexiteit – Deel 4, ontbrekende standaard unieke beperking
Maar mijn doel hier is iets minder gecompliceerd dan dat, nadat het onderwerp ter sprake kwam in een andere Stack Exchange-vraag:"Voeg een automatisch nu-veld toe aan een bestaande tabel." Daar voegde de gebruiker een nieuwe kolom toe aan een bestaande tabel, met de bedoeling deze automatisch te vullen met de huidige datum/tijd. Ze vroegen zich af of ze NULL's in die kolom moesten laten voor alle bestaande rijen of een standaardwaarde moesten instellen (zoals 1900-01-01, vermoedelijk, hoewel ze niet expliciet waren).
Het kan voor iemand met kennis van zaken gemakkelijk zijn om oude rijen uit te filteren op basis van een symbolische waarde - hoe kan iemand tenslotte geloven dat een soort Bluetooth-doodad is vervaardigd of gekocht op 01-01-00? Welnu, ik heb dit gezien in huidige systemen waar ze een willekeurig klinkende datum in weergaven gebruiken om als een magisch filter te fungeren, waarbij alleen rijen worden weergegeven waarvan de waarde kan worden vertrouwd. In feite is in alle gevallen die ik tot nu toe heb gezien, de datum in de WHERE-clausule de datum/tijd waarop de kolom (of de standaardbeperking) is toegevoegd. Dat is allemaal prima; het is misschien niet de beste manier om het probleem op te lossen, maar het is een manier.
Als u de tabel echter niet via de weergave opent, kan deze implicatie van een bekende waarde kan nog steeds zowel logische als resultaatgerelateerde problemen veroorzaken. Het logische probleem is simpelweg dat iemand die interactie heeft met de tabel, moet weten dat 1900-01-01 een valse, symbolische waarde is die "onbekend" of "niet relevant" vertegenwoordigt. Om een voorbeeld uit de praktijk te geven:wat was de gemiddelde releasesnelheid, in seconden, voor een quarterback die in de jaren 70 speelde, voordat we zoiets konden meten of volgen? Is 0 een goede symbolische waarde voor "onbekend"? Wat dacht je van -1? Of 100? Terugkomend op data, als een patiënt zonder ID wordt opgenomen in het ziekenhuis en buiten bewustzijn is, wat moeten ze dan als geboortedatum invullen? Ik denk niet dat 1900-01-01 een goed idee is, en het was zeker geen goed idee toen het waarschijnlijker was dat het een echte geboortedatum was.
Prestatie-implicaties van tokenwaarden
Vanuit prestatieperspectief kunnen nep- of "token"-waarden zoals 1900-01-01 of 9999-21-31 problemen veroorzaken. Laten we een paar hiervan bekijken met een voorbeeld dat losjes is gebaseerd op de recente vraag die hierboven is genoemd. We hebben een Widgets-tabel en, na wat garantieteruggaven, hebben we besloten om een EnteredService-kolom toe te voegen waarin we de huidige datum/tijd voor nieuwe rijen invoeren. In het ene geval laten we alle bestaande rijen op NULL en in het andere geval werken we de waarde bij naar onze magische datum 1900-01-01. (We laten elke vorm van compressie voorlopig buiten het gesprek.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Nu zullen we dezelfde 100.000 rijen in elke tabel invoegen:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Dan kunnen we de nieuwe kolom toevoegen en 10% van de bestaande waarden bijwerken met een verdeling van huidige datums, en de andere 90% naar onze symbolische datum alleen in een van de tabellen:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Ten slotte kunnen we indexen toevoegen:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Gebruikte ruimte
Ik hoor altijd "schijfruimte is goedkoop" als we het hebben over keuzes voor gegevenstypes, fragmentatie en tokenwaarden versus NULL. Mijn zorg gaat niet zozeer over de schijfruimte die deze extra betekenisloze waarden in beslag nemen. Het is meer dat, wanneer de tabel wordt opgevraagd, het geheugen verspilt. Hier kunnen we snel een idee krijgen van hoeveel ruimte onze tokenwaarden innemen voor en nadat de kolom en index zijn toegevoegd:
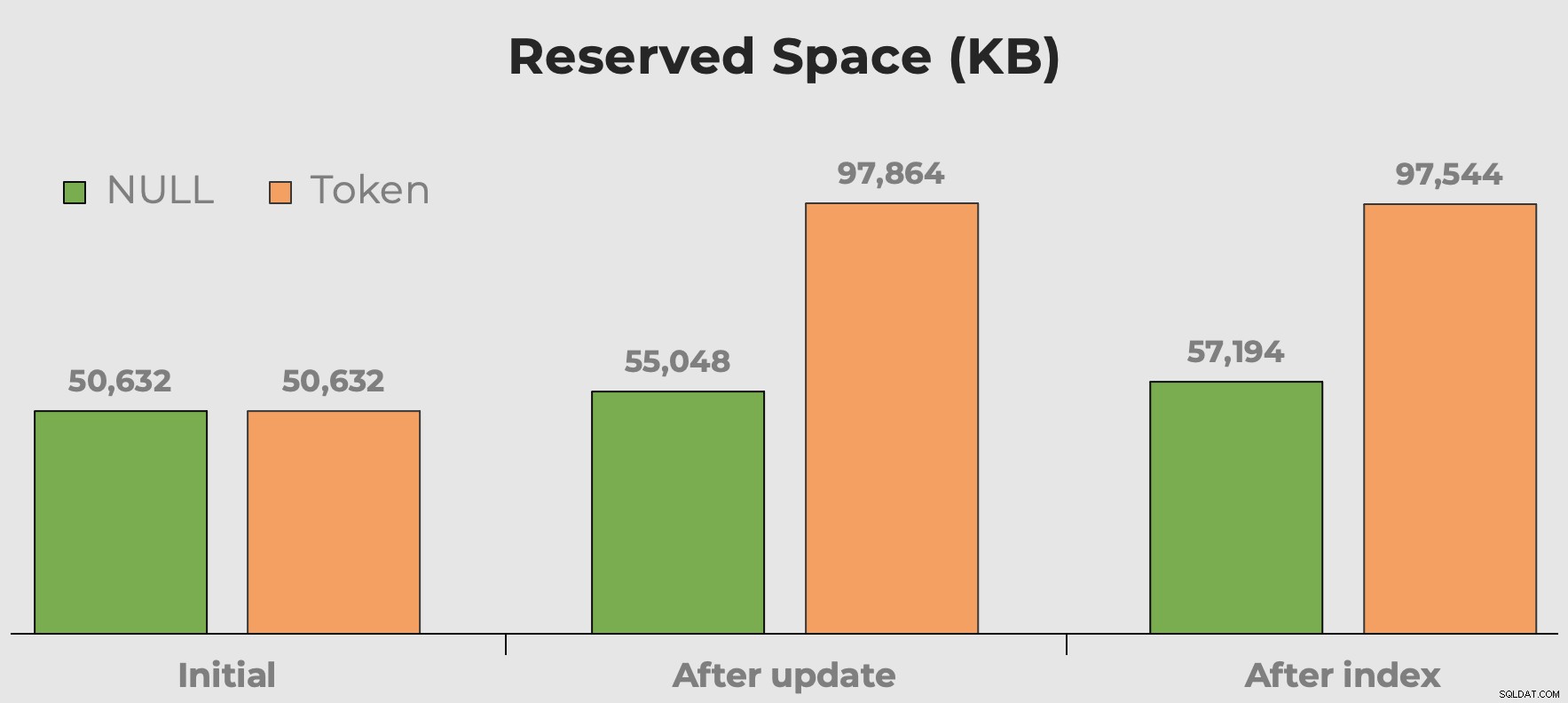 Gereserveerde ruimte van de tabel na het toevoegen van een kolom en het toevoegen van een index. Ruimte verdubbelt bijna met tokenwaarden.
Gereserveerde ruimte van de tabel na het toevoegen van een kolom en het toevoegen van een index. Ruimte verdubbelt bijna met tokenwaarden.
Uitvoering van zoekopdracht
Het is onvermijdelijk dat iemand aannames doet over de gegevens in de tabel en een query gaat uitvoeren op de kolom EnteredService alsof alle waarden daar legitiem zijn. Bijvoorbeeld:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; De tokenwaarden kunnen in sommige gevallen met schattingen knoeien, maar wat nog belangrijker is, ze zullen onjuiste (of op zijn minst onverwachte) resultaten opleveren. Hier is het uitvoeringsplan voor de query tegen de tabel met tokenwaarden:
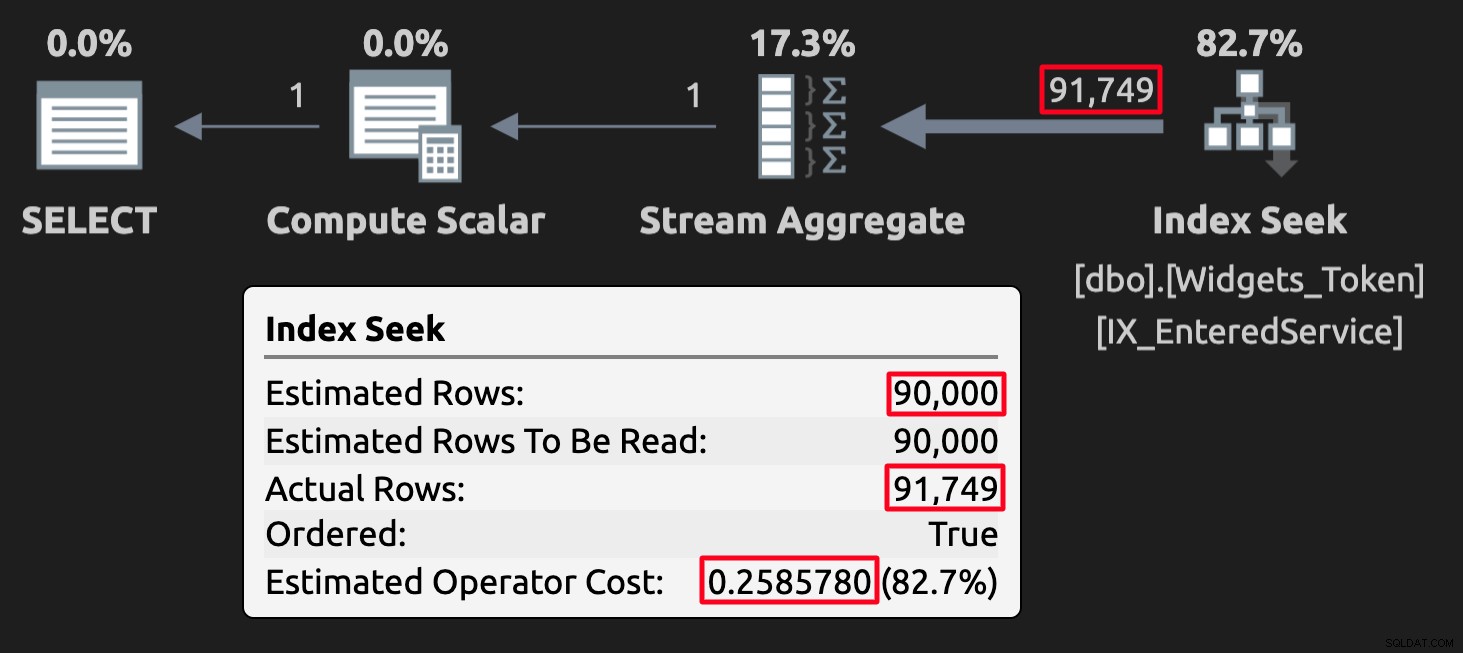 Uitvoeringsplan voor de tokentabel; let op de hoge kosten.
Uitvoeringsplan voor de tokentabel; let op de hoge kosten.
En hier is het uitvoeringsplan voor de query tegen de tabel met NULL's:
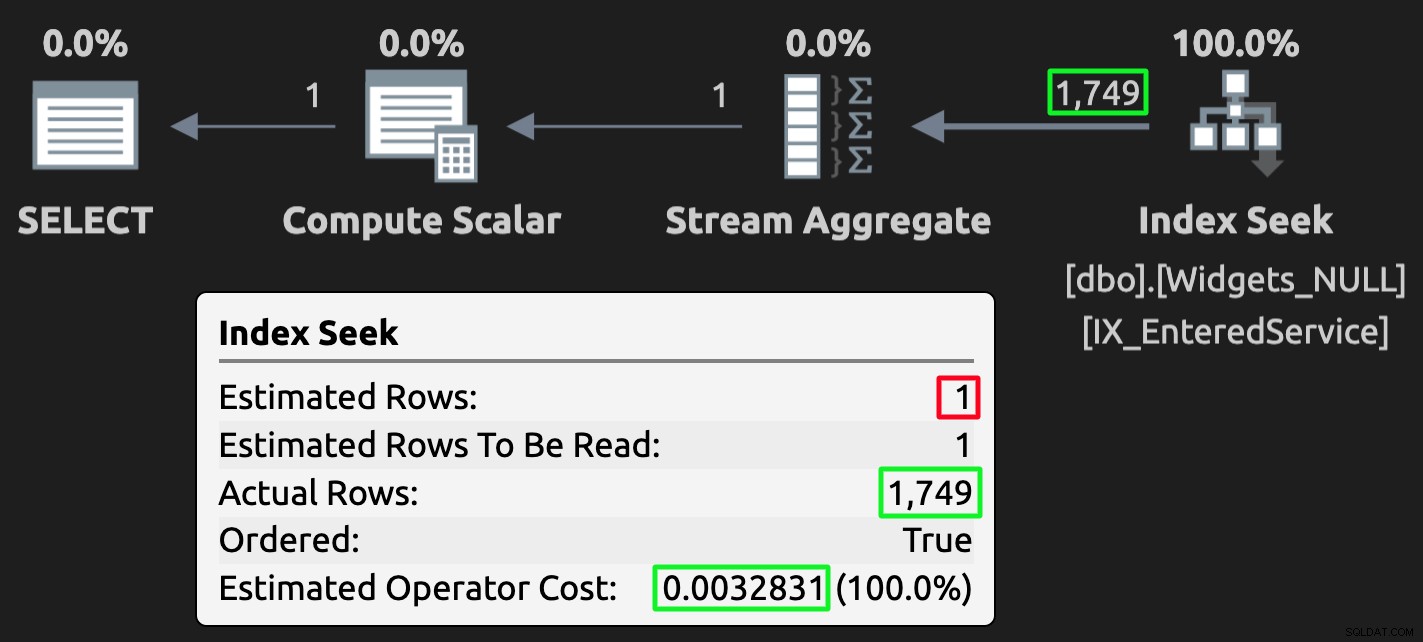 Uitvoeringsplan voor de NULL-tabel; verkeerde schatting, maar veel lagere kosten.
Uitvoeringsplan voor de NULL-tabel; verkeerde schatting, maar veel lagere kosten.
Hetzelfde zou andersom gebeuren als de zoekopdracht vroeg om>={some date} en 9999-12-31 werd gebruikt als de magische waarde voor onbekend.
Nogmaals, voor de mensen die toevallig weten dat de resultaten verkeerd zijn, specifiek omdat je tokenwaarden hebt gebruikt, is dit geen probleem. Maar iedereen die dat niet weet, inclusief toekomstige collega's, andere erfgenamen en beheerders van de code, en zelfs toekomstige jij met geheugenuitdagingen, zal waarschijnlijk struikelen.
Conclusie
De keuze om NULL's in een kolom toe te staan (of om NULL's helemaal te vermijden) mag niet worden gereduceerd tot een ideologische of op angst gebaseerde beslissing. Er zijn echte, tastbare nadelen aan het ontwerpen van uw datamodel om ervoor te zorgen dat geen enkele waarde NULL kan zijn, of het gebruik van betekenisloze waarden om iets weer te geven dat gemakkelijk helemaal niet had kunnen worden opgeslagen. Ik suggereer niet dat elke kolom in uw model NULL's moet toestaan; alleen dat je niet gekant bent tegen het idee van NULL's.