In de vorige blogpost heb ik kort uitgelegd hoe we de prestatiecijfers in de pglogical-aankondiging hebben gepubliceerd. In deze blogpost wil ik het hebben over de prestatielimieten van logische replicatieoplossingen in het algemeen, en ook hoe ze van toepassing zijn op pglogical.
fysieke replicatie
Laten we eerst eens kijken hoe fysieke replicatie (ingebouwd in PostgreSQL sinds versie 9.0) werkt. Een enigszins vereenvoudigde afbeelding van de met twee slechts twee knooppunten ziet er als volgt uit:
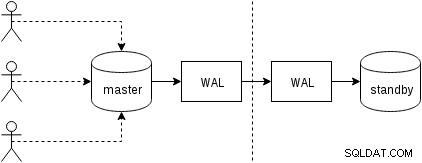
Clients voeren query's uit op het hoofdknooppunt, de wijzigingen worden naar een transactielogboek (WAL) geschreven en via het netwerk naar WAL op het stand-byknooppunt gekopieerd. Het herstel op het standby-proces op de standby leest vervolgens de wijzigingen uit WAL en past deze toe op de gegevensbestanden, net als tijdens herstel. Als de standby-modus in "hot_standby"-modus staat, kunnen clients alleen-lezen query's op het knooppunt uitvoeren terwijl dit gebeurt.
Dit is zeer efficiënt omdat er heel weinig extra verwerking is - wijzigingen worden overgedragen en naar de standby-modus geschreven als een ondoorzichtige binaire blob. Natuurlijk is het herstel niet gratis (zowel qua CPU als I/O), maar het is moeilijk om efficiënter te worden dan dit.
De voor de hand liggende potentiële knelpunten bij fysieke replicatie zijn de netwerkbandbreedte (het overbrengen van de WAL van master naar stand-by) en ook de I/O op de stand-by, die kan worden verzadigd door het herstelproces dat vaak een overvloed aan willekeurige I/O-verzoeken afgeeft ( in sommige gevallen meer dan de master, maar laten we daar niet op ingaan).
logische replicatie
Logische replicatie is iets gecompliceerder, omdat het niet gaat om een ondoorzichtige binaire WAL-stroom, maar om een stroom van "logische" wijzigingen (stel je INSERT-, UPDATE- of DELETE-instructies voor, hoewel dat niet helemaal correct is omdat we te maken hebben met een gestructureerde weergave van de data). Met de logische wijzigingen kunnen interessante dingen worden gedaan, zoals conflictoplossing, alleen geselecteerde tabellen repliceren, naar een ander schema of tussen verschillende versies (of zelfs verschillende databases).
Er zijn verschillende manieren om de wijzigingen te krijgen - de traditionele aanpak is door triggers te gebruiken die de wijzigingen in een tabel vastleggen, en een aangepast proces die wijzigingen continu te laten lezen en ze op stand-by toe te passen door SQL-query's uit te voeren. En dit alles wordt aangestuurd door een extern daemonproces (of mogelijk meerdere processen, die op beide knooppunten draaien), zoals geïllustreerd in de volgende afbeelding

Dat is wat slony of londiste doen, en hoewel het redelijk goed werkte, betekent het veel overhead - het vereist bijvoorbeeld het vastleggen van de gegevenswijzigingen en het meerdere keren schrijven van de gegevens (naar de originele tabel en naar een "log" -tabel, en ook naar WAL voor beide tabellen). We zullen later andere bronnen van overhead bespreken. Hoewel pglogical dezelfde doelen moet bereiken, bereikt het ze anders, dankzij verschillende functies die zijn toegevoegd aan recente PostgreSQL-versies (dus niet beschikbaar toen de andere tools werden geïmplementeerd):

Dat wil zeggen, in plaats van een apart logboek met wijzigingen bij te houden, vertrouwt pglogical op WAL - dit is mogelijk dankzij een logische decodering die beschikbaar is in PostgreSQL 9.4, waarmee logische wijzigingen uit het WAL-logboek kunnen worden gehaald. Hierdoor heeft pglogical geen dure triggers nodig en kan het meestal voorkomen dat de gegevens tweemaal op de master worden geschreven (behalve voor grote transacties die naar de schijf kunnen worden gemorst).
Na het decoderen van elke transactie wordt deze overgebracht naar de stand-by en het toepassingsproces past de wijzigingen toe op de stand-by-database. pglogical past de wijzigingen niet toe door reguliere SQL-query's uit te voeren, maar op een lager niveau, waarbij de overhead wordt omzeild die gepaard gaat met het ontleden en plannen van SQL-query's. Dit geeft pglogical een aanzienlijk voordeel ten opzichte van de bestaande oplossingen die allemaal door de SQL-laag gaan (en dus de parsering en planning betalen).
potentiële knelpunten
Het is duidelijk dat logische replicatie onderhevig is aan dezelfde knelpunten als fysieke replicatie, d.w.z. het is mogelijk om het netwerk te verzadigen bij het overbrengen van de wijzigingen, en I/O op de stand-by wanneer ze op de stand-by worden toegepast. Er is ook een behoorlijke hoeveelheid overhead vanwege extra stappen die niet aanwezig zijn in een fysieke replicatie.
We moeten op de een of andere manier de logische wijzigingen verzamelen, terwijl fysieke replicatie de WAL eenvoudigweg doorstuurt als een stroom bytes. Zoals reeds vermeld, zijn bestaande oplossingen meestal afhankelijk van triggers die de wijzigingen naar een "log" -tabel schrijven. pglogical vertrouwt in plaats daarvan op het write-ahead log (WAL) en logische decodering om hetzelfde te bereiken, wat goedkoper is dan triggers en ook de gegevens in de meeste gevallen niet twee keer hoeft te schrijven (met de toegevoegde bonus dat we de wijzigingen automatisch toepassen in vastleggingsvolgorde).
Dat wil niet zeggen dat er geen mogelijkheden zijn voor aanvullende verbetering - de decodering gebeurt bijvoorbeeld momenteel alleen als de transactie is vastgelegd, dus bij grote transacties kan dit de replicatievertraging vergroten. Fysieke replicatie streamt eenvoudig de WAL-wijzigingen naar het andere knooppunt en heeft deze beperking dus niet. Grote transacties kunnen ook op schijf terechtkomen, waardoor dubbele schrijfbewerkingen ontstaan, omdat de upstream ze moet opslaan totdat ze worden vastgelegd en ze naar de downstream kunnen worden verzonden.
Toekomstige werkzaamheden zijn gepland om pglogical in staat te stellen grote transacties te streamen terwijl ze nog in de upstream aan de gang zijn, waardoor de latentie tussen upstream-commit en downstream-commit wordt verminderd en de upstream-schrijfversterking wordt verminderd.
Nadat de wijzigingen zijn overgebracht naar de stand-by, moet het toepassingsproces ze op de een of andere manier daadwerkelijk toepassen. Zoals vermeld in de vorige sectie, deden de bestaande oplossingen dat door SQL-opdrachten te construeren en uit te voeren, terwijl pglogical de SQL-laag en de bijbehorende overhead volledig omzeilt.
Toch maakt dat de toepassing niet helemaal gratis, omdat het nog steeds dingen moet uitvoeren zoals het opzoeken van primaire sleutels, het bijwerken van indexen, het uitvoeren van triggers en het uitvoeren van verschillende andere controles. Maar het is aanzienlijk goedkoper dan de op SQL gebaseerde aanpak. In zekere zin werkt het veel als COPY en is het vooral snel op eenvoudige tafels zonder triggers, externe sleutels, enz.
In alle logische replicatieoplossingen vindt elk van deze stappen (decoderen en toepassen) plaats in een enkel proces, dus er is een vrij beperkte hoeveelheid CPU-tijd. Dit is waarschijnlijk het meest dringende knelpunt in alle bestaande oplossingen, omdat je misschien een behoorlijk stevige machine hebt met tientallen of zelfs honderden clients die parallel query's uitvoeren, maar dat alles moet door één enkel proces gaan om die wijzigingen te decoderen (op de master) en één proces dat die wijzigingen toepast (in de stand-bymodus).
De beperking van "één proces" kan enigszins worden versoepeld door afzonderlijke databases te gebruiken, aangezien elke database door een afzonderlijk proces wordt afgehandeld. Als het gaat om een enkele database, zijn er toekomstige werkzaamheden gepland om de toepassing via een pool van achtergrondmedewerkers parallel te laten lopen om dit knelpunt te verhelpen.