Overzicht
Oracle Data Mining (ODM) is een onderdeel van de Oracle Advanced Analytics Database Option. ODM bevat een reeks geavanceerde algoritmen voor datamining die zijn ingebed in de database waarmee u geavanceerde analyses op uw gegevens kunt uitvoeren.
Oracle Data Miner is een uitbreiding van Oracle SQL Developer, een grafische ontwikkelomgeving voor Oracle SQL. Oracle Data Miner gebruikt de dataminingtechnologie die is ingebed in Oracle Database om workflows te creëren, uit te voeren en te beheren die dataminingactiviteiten omvatten. De architectuur van ODM wordt geïllustreerd in figuur 1.
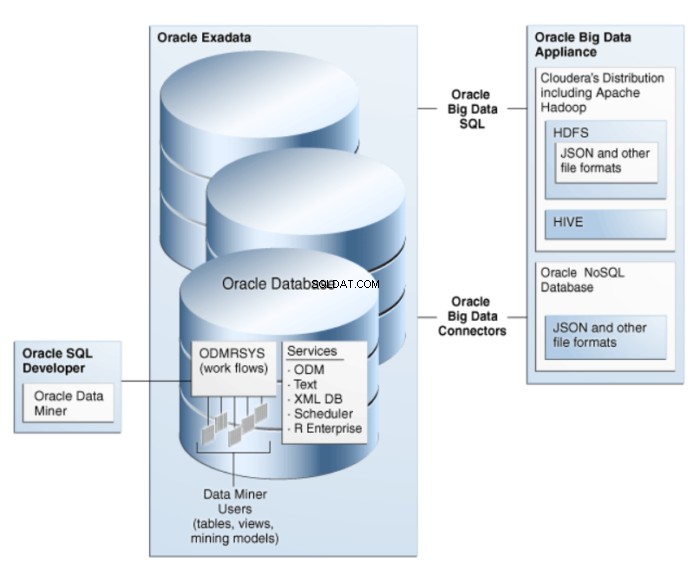
Figuur 1:Oracle Data Mining Architecture for Big Data
Algoritmen worden geïmplementeerd als SQL-functies en maken gebruik van de sterke punten van de Oracle Database. De SQL-dataminingfuncties kunnen transactiegegevens, aggregaties, ongestructureerde gegevens, d.w.z. CLOB-gegevenstype (met Oracle Text) en ruimtelijke gegevens ontginnen.
Elke dataminingfunctie specificeert een klasse van problemen die gemodelleerd en opgelost kunnen worden. Dataminingfuncties vallen over het algemeen in twee categorieën:onder toezicht en zonder toezicht.
Noties van begeleid en niet-gesuperviseerd leren zijn afgeleid van de wetenschap van machine learning, dat een deelgebied van kunstmatige intelligentie wordt genoemd.
Begeleid leren wordt ook wel gestuurd leren genoemd. Het leerproces wordt gestuurd door een eerder bekend afhankelijk attribuut of doel. Gerichte datamining probeert het gedrag van het doelwit te verklaren als een functie van een reeks onafhankelijke attributen of voorspellers.
Ongesuperviseerd leren is niet-gericht. Er is geen onderscheid tussen afhankelijke en onafhankelijke attributen. Er is geen eerder bekend resultaat om het algoritme te begeleiden bij het bouwen van het model. Leren zonder toezicht kan worden gebruikt voor beschrijvende doeleinden.
Algoritmen onder toezicht van Oracle Data Mining
| Techniek | Toepasselijkheid | Algoritmen (korte beschrijving) |
|---|---|---|
Classificatie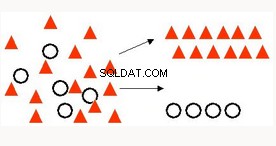 | Meest gebruikte techniek voor het voorspellen van een specifieke uitkomst, bijvoorbeeld identificatie van kankertumorcellen, sentimentanalyse, classificatie van geneesmiddelen, spamdetectie. | Gegeneraliseerde lineaire modellen Logistische regressie - klassieke statistische techniek die beschikbaar is in de Oracle-database in een zeer performante, schaalbare, geparalliseerde implementatie (van toepassing op alle OAA ML-algoritmen). Ondersteunt tekst en transactiegegevens (geldt voor bijna alle OAA ML-algoritmen) Naive Bayes - Snel, eenvoudig, algemeen toepasbaar. Ondersteuning van Vector Machine - Machine learning-algoritme, ondersteunt tekst en brede gegevens. Decision Tree - Populair ML-algoritme voor interpreteerbaarheid. Biedt voor mensen leesbare "regels". |
Regressie | Techniek voor het voorspellen van een continue numerieke uitkomst zoals astronomische data-analyse, het genereren van inzichten over consumentengedrag, winstgevendheid en andere zakelijke factoren, het berekenen van causale verbanden tussen parameters in biologische systemen. | Gegeneraliseerde lineaire modellen Meervoudige regressie - klassieke statistische techniek, maar nu beschikbaar in de Oracle Database als een zeer performante, schaalbare, geparalliseerde implementatie. Ondersteunt nokregressie, het maken van functies en het selecteren van functies. Ondersteunt tekst en transactiegegevens. Ondersteunt Vector Machine - Machine learning-algoritme, ondersteunt tekst en brede gegevens. |
Kenmerkbelang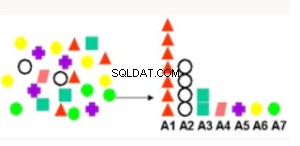 | Rangschikt attributen volgens de sterkte van de relatie met het doelkenmerk. Gebruiksvoorbeelden zijn onder meer het vinden van factoren die het meest worden geassocieerd met klanten die op een aanbieding reageren, factoren die het meest worden geassocieerd met gezonde patiënten. | Minimale lengte beschrijving - beschouwt elk attribuut als een eenvoudig voorspellend model van de doelklasse en biedt relatieve invloed. |
Oracle datamining zonder toezicht algoritmen
| Techniek | Toepasselijkheid | Algoritmen |
|---|---|---|
Clustering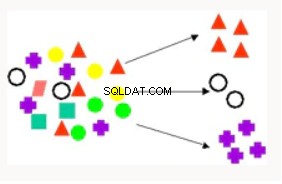 | Clustering wordt gebruikt om de records van een database te verdelen in subsets of clusters waarbij elementen in een cluster een set gemeenschappelijke eigenschappen delen. Voorbeelden zijn het vinden van nieuwe klantsegmenten en filmaanbevelingen. | K-Means - Ondersteunt tekstmining, hiërarchische clustering, gebaseerd op afstand. Orthogonale partitioneringsclustering - Hiërarchische clustering, gebaseerd op dichtheid. Verwachtingsmaximalisatie - Clustertechniek die goed presteert bij dataminingproblemen met gemengde gegevens (dichte en schaarse). |
Anomaliedetectie | Anomaliedetectie identificeert datapunten, gebeurtenissen en/of observaties die afwijken van het normale gedrag van een dataset. Veelvoorkomende voorbeelden zijn bankfraude, een structureel defect, medische problemen of fouten in een tekst | One-Class Support Vector Machine - traint niet-gecodeerde gegevens en probeert te bepalen of een testpunt bij de distributie van trainingsgegevens hoort. |
Functie selecteren en extraheren | Produceert nieuwe attributen als lineaire combinatie van bestaande attributen. Toepasbaar voor tekstgegevens, latente semantische analyse (LSA), gegevenscompressie, gegevensontleding en -projectie en patroonherkenning. | Niet-negatieve matrixfactorisatie - koppelt de oorspronkelijke gegevens aan de nieuwe set attributen Principal Components Analysis (PCA) - creëert nieuwe, minder samengestelde attributen die alle attributes. Singular Vector Decomposition - gevestigde methode voor het extraheren van kenmerken die een breed scala aan toepassingen heeft. |
Associatie | Vindt regels die verband houden met veelvoorkomende items, die worden gebruikt voor marktmandanalyse, cross-sell, analyse van hoofdoorzaken. Handig voor productbundeling en defectanalyse. | Apriori - Een boom gehasht om informatie in een database te verzamelen |
De Oracle Data Mining-optie inschakelen
Vanaf 12c Release 2 de Oracle Advanced Analytics Optie omvat Data Mining en Oracle R-functionaliteit.
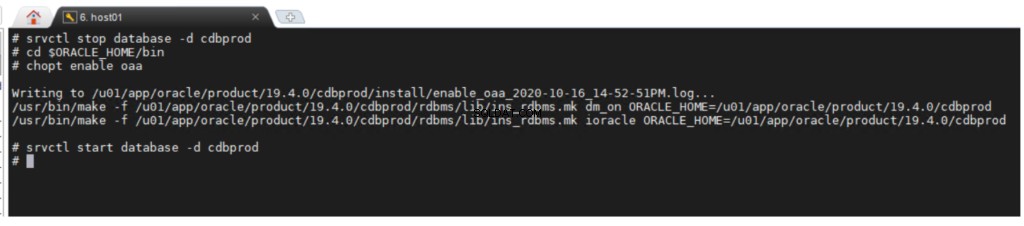
De optie Oracle Advanced Analytics is standaard ingeschakeld tijdens de installatie van Oracle Database Enterprise Edition. Als u een databaseoptie wilt in- of uitschakelen, kunt u het opdrachtregelprogramma chopt . gebruiken .
chopt [ enable | disable ] oaa
Om de Oracle Advanced Analytics-optie in te schakelen:
Tabelruimte maken in een ODM-schema
Alle gebruikers hebben een permanente tablespace en een tijdelijke tablespace nodig om hun werk te doen, het kan erg handig zijn om een apart gebied in uw database te hebben waar u al uw datamining-objecten kunt maken.
De usr_dm_01 schema bevat al uw dataminingwerken.
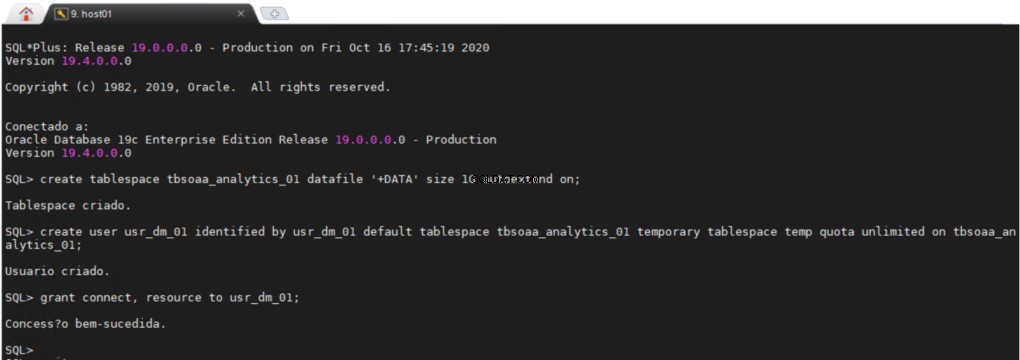
De ODM-repository maken
U moet een Oracle Data Mining Repository maken in de databank. Ga naar Data Miner Navigator in SQL Developer.
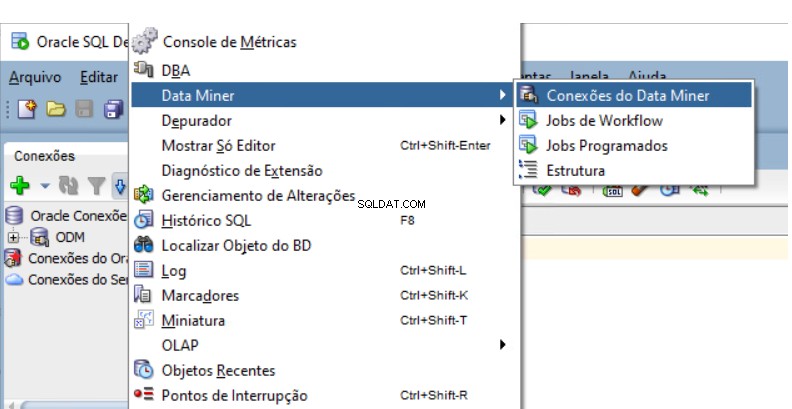
Selecteer Beeld -> Data Miner -> Data Miner-verbindingen:
Er wordt een nieuw tabblad geopend naast uw bestaande tabblad Verbindingen:
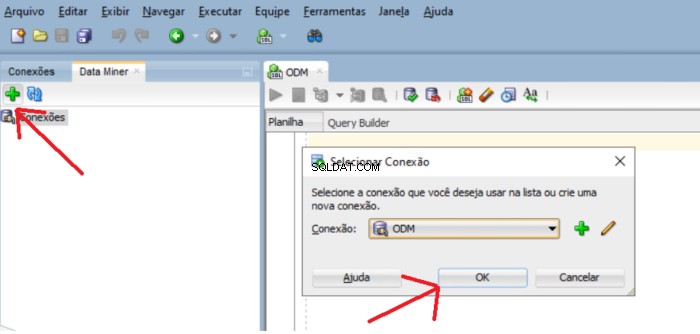
Toevoegen usr_dm_01 schema toevoegen aan deze lijst, klik op de groene plusvensters en OK
Als de repository niet bestaat, verschijnt er een bericht waarin u wordt gevraagd of u de repository wilt installeren. Klik op de Ja knop om door te gaan met de installatie.
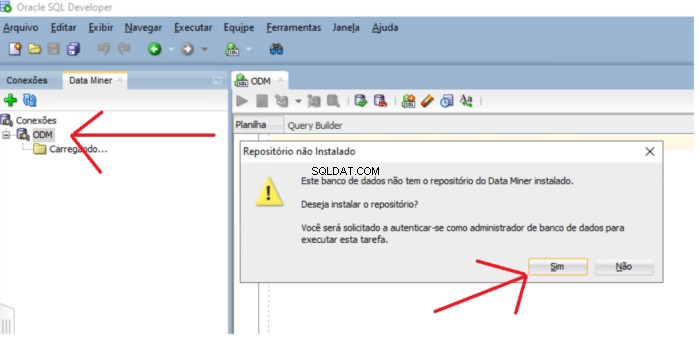
U moet het SYS-wachtwoord invoeren
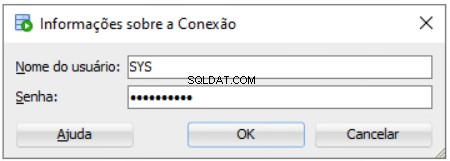
Installatie-instelling opslagplaats
Voortgangsvenster Data Miner Repository installeren
Taak succesvol voltooid
Logbestand
Oracle Data Mining-componenten
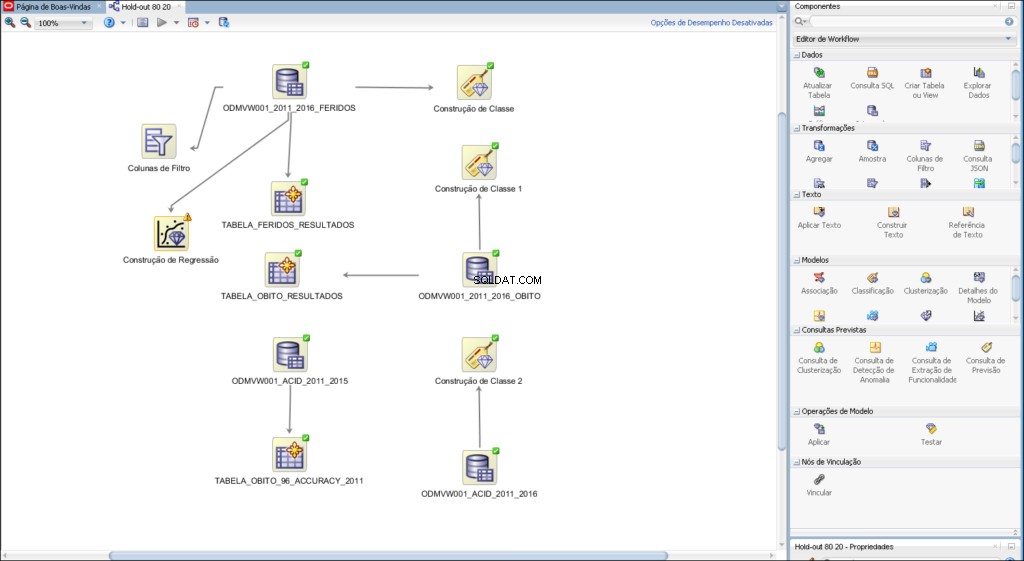
De workflow stelt u in staat een reeks knooppunten op te bouwen die alle vereiste verwerkingen op uw gegevens uitvoeren.
Voorbeeld van een workflow ontwikkeld voor predictive analytics
ODM-gegevenswoordenboekweergaven
U kunt informatie over mijnbouwmodellen verkrijgen uit de datadictionary.
De weergaven van de datadictionary van Data Mining worden als volgt samengevat:
Opmerking:* kan worden vervangen door ALL_, USER_, DBA_ en CDB_
*_MINING_MODELS :Informatie over de mijnbouwmodellen die zijn gemaakt.
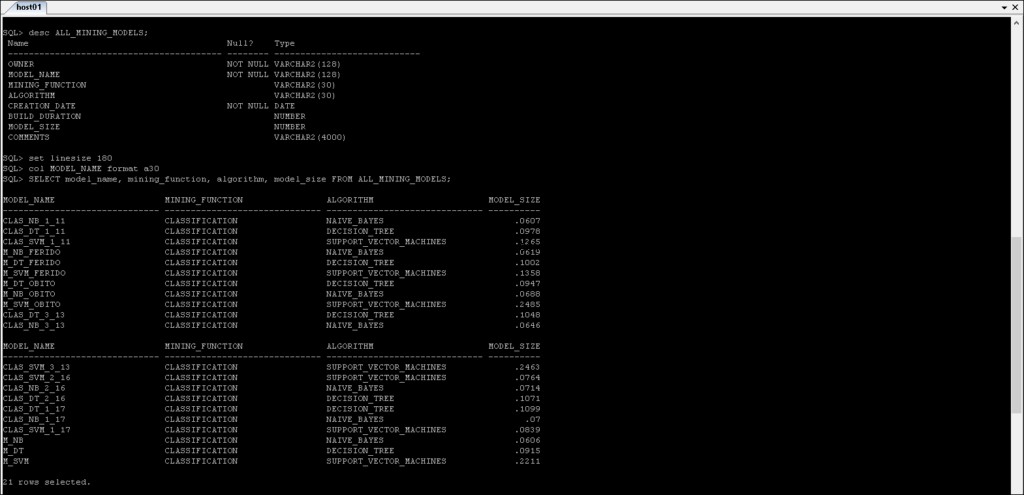
*_MINING_MODEL_ATTRIBUTES :Bevat de details van de attributen die zijn gebruikt om het Oracle Data Mining-model te creëren.
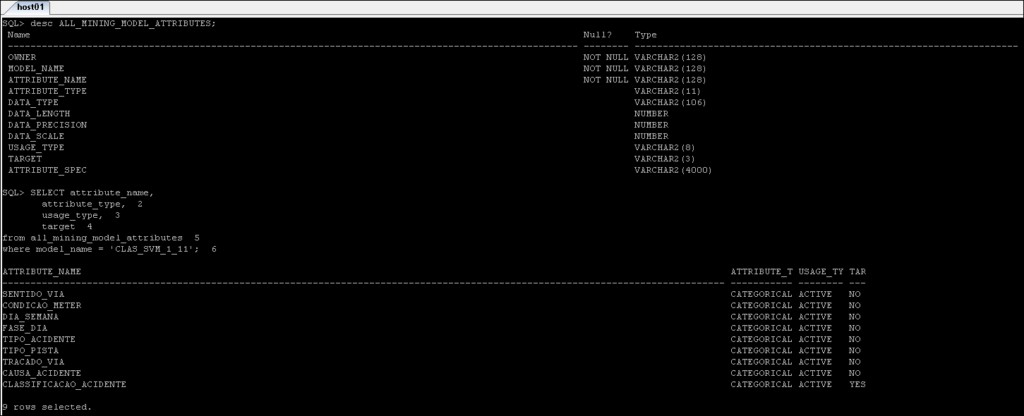
*_MINING_MODEL_SETTINGS :Geeft informatie terug over de instellingen voor de mijnbouwmodellen waartoe u toegang hebt.
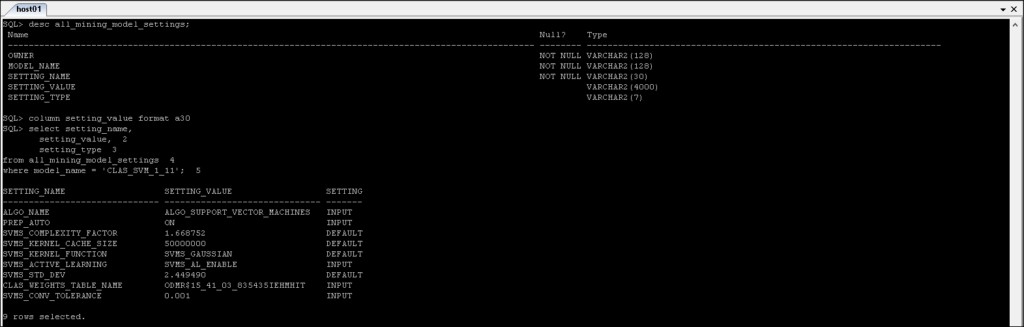
Referenties
Oracle Data Mining Gebruikershandleiding. Beschikbaar op:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Schaalbare voorspellende analyses in de database. Beschikbaar op:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Overzicht Oracle Data Miner-systeem. Beschikbaar op:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124