Een Oracle-ontwikkelaar die vaak reguliere expressies in code gebruikt, wordt vroeg of laat geconfronteerd met een fenomeen dat inderdaad mystiek is. Langdurig zoeken naar de oorzaak van het probleem kan leiden tot gewichtsverlies, eetlust en verschillende soorten psychosomatische aandoeningen veroorzaken - dit alles kan worden voorkomen met behulp van de regexp_replace-functie. Het kan maximaal 6 argumenten hebben:
REGEXP_REPLACE (
- source_string,
- sjabloon,
- substituting_string,
- de startpositie van het zoeken naar overeenkomsten met een sjabloon (standaard 1),
- een plaats van voorkomen van de sjabloon in een brontekenreeks (standaard is 0 gelijk aan alle exemplaren),
- modifier (tot nu toe is het een dark horse)
)
Retourneert de gewijzigde source_string waarin alle exemplaren van de sjabloon worden vervangen door de waarde die is doorgegeven in de parameter substituting_string. Vaak wordt een korte versie van de functie gebruikt, waarbij de eerste 3 argumenten worden opgegeven, wat voldoende is om veel problemen op te lossen. Ik zal hetzelfde doen. Stel dat we alle tekenreekstekens moeten maskeren met sterretjes in de tekenreeks 'MASK:kleine letters'. Om het bereik van kleine letters te specificeren, moet het '[a-z]'-patroon passen.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Verwachting
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realiteit
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Als deze gebeurtenis niet in uw database is gereproduceerd, heeft u tot nu toe geluk. Maar vaker begin je in code te graven, tekenreeksen van de ene set tekens naar de andere te converteren en uiteindelijk komt er wanhoop.
Een probleem definiëren
De vraag rijst:wat is er zo speciaal aan de letter 'A' dat deze niet is vervangen omdat de rest van de hoofdletters niet ook vervangen had mogen worden. Misschien zijn er andere correcte letters behalve deze. Het is noodzakelijk om naar het hele alfabet van hoofdletters te kijken.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Echter
Als het zesde argument van de functie niet expliciet is opgegeven, bijvoorbeeld, 'i' is niet hoofdlettergevoelig of 'c' is hoofdlettergevoelig bij het vergelijken van een brontekenreeks met een sjabloon, reguliere expressie gebruikt standaard de parameter NLS_SORT van de sessie/database. Bijvoorbeeld:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Deze parameter specificeert de sorteermethode in ORDER BY. Als we het hebben over het sorteren van eenvoudige individuele karakters, dan komt een bepaald binair getal (NLSSORT-code) overeen met elk van hen en de sortering vindt feitelijk plaats op de waarde van deze getallen.
Laten we om dit te illustreren de eerste en laatste paar tekens van het alfabet nemen, zowel kleine letters als hoofdletters, en deze in een voorwaardelijk ongeordende tabelreeks plaatsen en deze ABC noemen. Laten we deze set dan sorteren op het SYMBOOL-veld en de NLSSORT-code in de HEX-indeling naast elk symbool weergeven.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
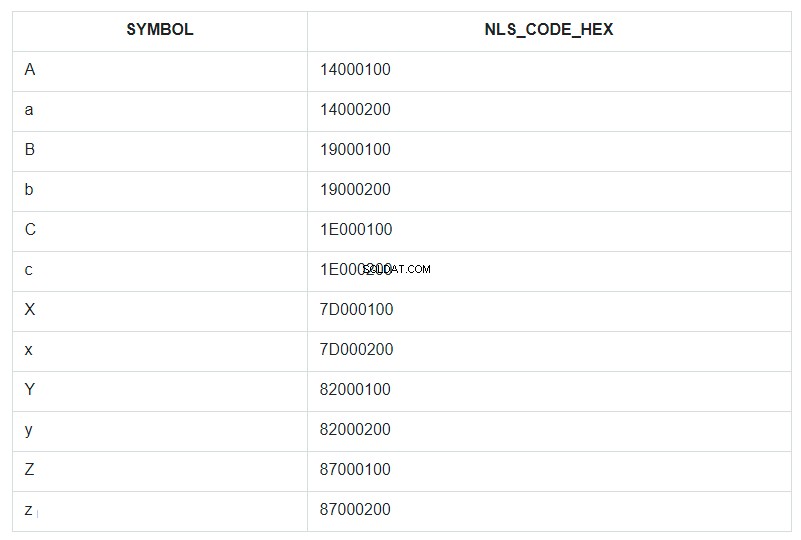
In de zoekopdracht wordt ORDER BY gespecificeerd voor het veld SYMBOL, maar in de database ging het sorteren op de waarden uit het veld NLS_CODE_HEX.
Ga nu terug naar het bereik van de sjabloon en kijk naar de tabel - wat is verticaal tussen het symbool 'a' (code 14000200) en 'z' (code 87000200)? Alles behalve de hoofdletter 'A'. Dat is alles wat is vervangen door een asterisk. En de code 14000100 van de letter 'A' is niet inbegrepen in het vervangingsbereik van 14000200 tot 87000200.
Genezen
Geef expliciet de hoofdlettergevoeligheidsmodifier op
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Sommige bronnen zeggen dat modifier 'c' standaard is ingesteld, maar we hebben zojuist gezien dat dit niet helemaal waar is. En als iemand het niet heeft gezien, dan is de parameter NLS_SORT van zijn sessie/database hoogstwaarschijnlijk ingesteld op BINARY en wordt de sortering uitgevoerd in overeenstemming met echte codes van tekens. Als u de sessieparameter wijzigt, wordt het probleem inderdaad opgelost.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Tests zijn uitgevoerd in Oracle 12c.
Voel je vrij om je opmerkingen achter te laten en wees voorzichtig.