In elk van de relationele database-engines is het vereist om een zo goed mogelijk plan te genereren dat overeenkomt met de uitvoering van de query met de minste tijd en middelen. Over het algemeen genereren alle databases plannen in een boomstructuurformaat, waarbij het bladknooppunt van elke planboom tabelscanknooppunt wordt genoemd. Dit specifieke knooppunt van het plan komt overeen met het algoritme dat moet worden gebruikt om gegevens uit de basistabel op te halen.
Beschouw bijvoorbeeld een eenvoudig queryvoorbeeld als SELECT * FROM TBL1, TBL2 waarbij TBL2.ID>1000; en stel dat het gegenereerde plan als volgt is:
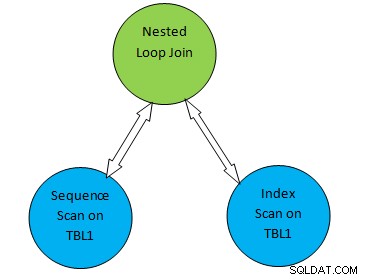
Dus in de bovenstaande planboom, "Sequentiële scan op TBL1" en " Index Scan op TBL2” komt overeen met de tabelscanmethode op respectievelijk tafel TBL1 en TBL2. Dus volgens dit plan wordt TBL1 achtereenvolgens opgehaald van de bijbehorende pagina's en is TBL2 toegankelijk met INDEX Scan.
Het kiezen van de juiste scanmethode als onderdeel van het plan is erg belangrijk voor de algehele queryprestaties.
Laten we, voordat we ingaan op alle soorten scanmethoden die door PostgreSQL worden ondersteund, enkele van de belangrijkste hoofdpunten herzien die vaak zullen worden gebruikt tijdens het doornemen van de blog.
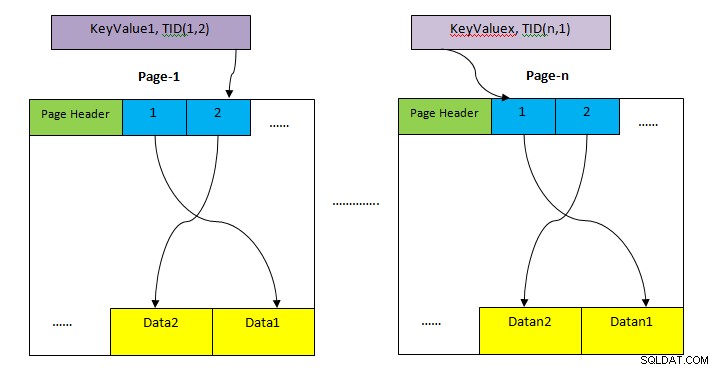
- HEAP: Opbergruimte voor het opbergen van de hele rij van de tafel. Deze is opgedeeld in meerdere pagina's (zoals weergegeven in de bovenstaande afbeelding) en elk paginaformaat is standaard 8KB. Binnen elke pagina verwijst elke itemaanwijzer (bijv. 1, 2, ....) naar gegevens binnen de pagina.
- Indexopslag: Deze opslag slaat alleen sleutelwaarden op, d.w.z. kolomwaarde per index. Dit is ook verdeeld in meerdere pagina's en elk paginaformaat is standaard 8 KB.
- Tuple-identificatie (TID): TID is een nummer van 6 bytes dat uit twee delen bestaat. Het eerste deel is een paginanummer van 4 bytes en de resterende tuple-index van 2 bytes binnen de pagina. De combinatie van deze twee nummers wijst op unieke wijze naar de opslaglocatie voor een bepaalde tuple.
Momenteel ondersteunt PostgreSQL onderstaande scanmethoden waarmee alle vereiste gegevens uit de tabel kunnen worden gelezen:
- Sequentiële scan
- Indexscan
- Alleen indexscan
- Bitmapscan
- TID-scan
Elk van deze scanmethoden is even nuttig, afhankelijk van de zoekopdracht en andere parameters, b.v. tabelkardinaliteit, tabelselectiviteit, schijf-I/O-kosten, willekeurige I/O-kosten, sequentie-I/O-kosten, enz. Laten we een vooraf ingestelde tabel maken en vullen met enkele gegevens, die vaak zullen worden gebruikt om deze scanmethoden beter uit te leggen .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEDus in dit voorbeeld worden één miljoen records ingevoegd en vervolgens wordt de tabel geanalyseerd zodat alle statistieken up-to-date zijn.
Sequentiële scan
Zoals de naam al doet vermoeden, wordt een sequentiële scan van een tabel gedaan door achtereenvolgens alle itemaanwijzers van alle pagina's van de overeenkomstige tabellen te scannen. Dus als er 100 pagina's zijn voor een bepaalde tabel en dan zijn er 1000 records in elke pagina, als onderdeel van de sequentiële scan zal het 100*1000 records ophalen en controleren of het overeenkomt met het isolatieniveau en ook volgens de predikaatclausule. Dus zelfs als er maar 1 record is geselecteerd als onderdeel van de hele tabelscan, zal het 100.000 records moeten scannen om een gekwalificeerd record te vinden volgens de voorwaarde.
Volgens de bovenstaande tabel en gegevens resulteert de volgende zoekopdracht in een sequentiële scan, aangezien de meeste gegevens worden geselecteerd.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)OPMERKING
Hoewel het zonder berekening en vergelijking van de abonnementskosten bijna onmogelijk is om te bepalen welk soort scans zullen worden gebruikt. Maar om de sequentiële scan te kunnen gebruiken, moeten ten minste onderstaande criteria overeenkomen:
- Geen index beschikbaar op sleutel, die deel uitmaakt van het predikaat.
- De meeste rijen worden opgehaald als onderdeel van de SQL-query.
TIPS
In het geval dat maar een heel klein percentage van de rijen wordt opgehaald en het predikaat in een (of meer) kolom staat, probeer dan de prestaties te evalueren met of zonder index.
Indexscan
In tegenstelling tot Sequential Scan, haalt Index Scan niet alle records opeenvolgend op. Het gebruikt eerder een andere gegevensstructuur (afhankelijk van het type index) die overeenkomt met de index die bij de zoekopdracht is betrokken en de vereiste gegevens (volgens predikaat) clausule lokaliseren met zeer minimale scans. Vervolgens verwijst de gevonden invoer met behulp van de indexscan rechtstreeks naar gegevens in het heapgebied (zoals weergegeven in de bovenstaande afbeelding), die vervolgens wordt opgehaald om de zichtbaarheid te controleren volgens het isolatieniveau. Er zijn dus twee stappen voor indexscan:
- Gegevens ophalen uit indexgerelateerde gegevensstructuur. Het retourneert de TID van de overeenkomstige gegevens in een heap.
- Vervolgens wordt de bijbehorende heap-pagina rechtstreeks geopend om volledige gegevens te krijgen. Deze extra stap is vereist om de onderstaande redenen:
- Query heeft mogelijk gevraagd om meer kolommen op te halen dan wat beschikbaar is in de corresponderende index.
- Zichtbaarheidsinformatie wordt niet bijgehouden samen met indexgegevens. Dus om de zichtbaarheid van gegevens per isolatieniveau te controleren, moet het toegang hebben tot heapgegevens.
Nu vragen we ons misschien af waarom Index Scan niet altijd wordt gebruikt als het zo efficiënt is. Dus zoals we weten, heeft alles wat kosten. Hier zijn de kosten gerelateerd aan het type I/O dat we doen. In het geval van Index Scan is Random I/O betrokken, aangezien voor elk record dat in indexopslag wordt gevonden, het overeenkomstige gegevens uit HEAP-opslag moet halen, terwijl in het geval van Sequential Scan Sequence I/O betrokken is, wat ongeveer slechts 25% kost van willekeurige I/O-timing.
Dus Index-scan moet alleen worden gekozen als de algehele winst hoger is dan de overhead die wordt veroorzaakt door willekeurige I/O-kosten.
Volgens de bovenstaande tabel en gegevens, zal de volgende query resulteren in een indexscan omdat er slechts één record wordt geselecteerd. Dus willekeurige I/O is minder en het zoeken naar het bijbehorende record gaat snel.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Alleen indexscan
Index Only Scan is vergelijkbaar met Index Scan, behalve de tweede stap, d.w.z. zoals de naam al aangeeft, scant het alleen de indexgegevensstructuur. Er zijn twee aanvullende voorwaarden om Index Only Scan te kunnen vergelijken met Index Scan:
- Query zou alleen sleutelkolommen moeten ophalen die deel uitmaken van de index.
- Alle tuples (records) op de geselecteerde heap-pagina moeten zichtbaar zijn. Zoals besproken in de vorige sectie houdt de indexgegevensstructuur geen zichtbaarheidsinformatie bij, dus om alleen gegevens uit de index te selecteren, moeten we voorkomen dat we controleren op zichtbaarheid en dit kan gebeuren als alle gegevens van die pagina als zichtbaar worden beschouwd.
De volgende zoekopdracht resulteert in een scan met alleen index. Hoewel deze zoekopdracht bijna hetzelfde is wat betreft het selecteren van het aantal records, maar omdat alleen het sleutelveld (d.w.z. "num") wordt geselecteerd, wordt alleen Index Scannen gekozen.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Bitmapscan
Bitmapscan is een mix van Indexscan en Sequentiële scan. Het probeert het nadeel van Index-scan op te lossen, maar behoudt zijn volledige voordeel. Zoals hierboven besproken, moet het voor elke gegevens in de indexgegevensstructuur de overeenkomstige gegevens op de heap-pagina vinden. Dus als alternatief moet het een keer de indexpagina ophalen en dan gevolgd door een heap-pagina, wat veel willekeurige I/O veroorzaakt. Dus de bitmap-scanmethode maakt gebruik van het voordeel van indexscan zonder willekeurige I/O. Dit werkt op twee niveaus, zoals hieronder:
- Bitmap-indexscan:eerst worden alle indexgegevens uit de indexgegevensstructuur opgehaald en wordt een bitmap van alle TID's gemaakt. Voor een eenvoudig begrip kunt u overwegen dat deze bitmap een hash bevat van alle pagina's (gehasht op basis van paginanummer) en dat elk pagina-item een array bevat van alle offset binnen die pagina.
- Bitmap Heap Scan:zoals de naam al aangeeft, leest het de bitmap van pagina's en scant vervolgens de gegevens van de heap die overeenkomen met de opgeslagen pagina en offset. Aan het einde controleert het op zichtbaarheid en predikaat enz. en retourneert het de tuple op basis van de uitkomst van al deze controles.
Onderstaande zoekopdracht zal resulteren in Bitmap-scan omdat het niet heel weinig records selecteert (d.w.z. te veel voor indexscan) en tegelijkertijd niet een groot aantal records selecteert (d.w.z. te weinig voor een sequentiële scannen).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Beschouw nu onderstaande query, die hetzelfde aantal records selecteert, maar alleen sleutelvelden (d.w.z. alleen indexkolommen). Omdat het alleen de sleutel selecteert, hoeft het niet naar heap-pagina's te verwijzen voor andere delen van gegevens en is er daarom geen willekeurige I/O bij betrokken. Deze zoekopdracht kiest dus alleen index scannen in plaats van bitmap scannen.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID-scan
TID, zoals hierboven vermeld, is een nummer van 6 bytes dat bestaat uit een paginanummer van 4 bytes en een resterende tuple-index van 2 bytes binnen de pagina. TID-scan is een heel specifiek soort scan in PostgreSQL en wordt alleen geselecteerd als er TID in het querypredicaat staat. Overweeg de onderstaande vraag om de TID-scan te demonstreren:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Dus hier in het predikaat wordt TID gegeven in plaats van een exacte waarde van de kolom als voorwaarde te geven. Dit lijkt op ROWID-gebaseerd zoeken in Oracle.
Bonus
Alle scanmethoden worden veel gebruikt en zijn beroemd. Deze scanmethoden zijn ook beschikbaar in bijna alle relationele databases. Maar er is onlangs een andere scanmethode in discussie in de PostgreSQL-gemeenschap en ook recentelijk toegevoegd aan andere relationele databases. Het heet "Loose IndexScan" in MySQL, "Index Skip Scan" in Oracle en "Jump Scan" in DB2.
Deze scanmethode wordt gebruikt voor een specifiek scenario waarin de afzonderlijke waarde van de leidende sleutelkolom van de B-Tree-index is geselecteerd. Als onderdeel van deze scan vermijdt het het doorlopen van alle gelijke sleutelkolomwaarden, maar doorloopt u gewoon de eerste unieke waarde en springt u vervolgens naar de volgende grote.
Dit werk is nog steeds aan de gang in PostgreSQL met de voorlopige naam als "Index Skip Scan" en we kunnen dit in een toekomstige release verwachten.