Gegevens zijn waarschijnlijk een van de meest waardevolle activa in een bedrijf. Daarom moeten we altijd een Disaster Recovery Plan (DRP) hebben om gegevensverlies bij een ongeval of hardwarestoring te voorkomen.
Een back-up is de eenvoudigste vorm van DR, maar het is misschien niet altijd voldoende om een acceptabele Recovery Point Objective (RPO) te garanderen. Het wordt aanbevolen om ten minste drie back-ups op verschillende fysieke plaatsen op te slaan.
De beste praktijk schrijft voor dat back-upbestanden één lokaal op de databaseserver moeten hebben (voor een sneller herstel), een andere op een gecentraliseerde back-upserver en de laatste in de cloud.
Voor deze blog bekijken we welke opties Amazon AWS biedt voor de opslag van PostgreSQL-back-ups in de cloud en laten we enkele voorbeelden zien hoe u dit kunt doen.
Over Amazon AWS
Amazon AWS is een van 's werelds meest geavanceerde cloudproviders op het gebied van functies en services, met miljoenen klanten. Als we onze PostgreSQL-databases op Amazon AWS willen laten draaien, hebben we enkele opties...
-
Amazon RDS:hiermee kunnen we op een gemakkelijke en snelle manier een PostgreSQL-database (of verschillende databasetechnologieën) in de cloud maken, beheren en schalen.
-
Amazon Aurora:het is een PostgreSQL-compatibele database die is gebouwd voor de cloud. Volgens de AWS-website is het drie keer sneller dan standaard PostgreSQL-databases.
-
Amazon EC2:het is een webservice die aanpasbare rekencapaciteit in de cloud biedt. Het geeft u volledige controle over uw computerbronnen en stelt u in staat om alles over uw instanties in te stellen en te configureren, van uw besturingssysteem tot uw applicaties.
Maar in feite hoeven we onze databases niet op Amazon te hebben om onze back-ups hier op te slaan.
Back-ups opslaan op Amazon AWS
Er zijn verschillende opties om onze PostgreSQL-back-up op AWS op te slaan. Als we onze PostgreSQL-database op AWS gebruiken, hebben we meer opties en (omdat we in hetzelfde netwerk zitten) kan het ook sneller zijn. Laten we eens kijken hoe AWS ons kan helpen onze back-ups op te slaan.
AWS CLI
Laten we eerst onze omgeving voorbereiden om de verschillende AWS-opties te testen. Voor onze voorbeelden gebruiken we een On-prem PostgreSQL 11-server die draait op CentOS 7. Hier moeten we de AWS CLI installeren volgens de instructies van deze site.
Als we onze AWS CLI hebben geïnstalleerd, kunnen we deze testen vanaf de opdrachtregel:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Nu is de volgende stap het configureren van onze nieuwe client met het aws-commando met de configure-optie.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Om deze informatie te krijgen, kun je naar de IAM AWS-sectie gaan en de huidige gebruiker controleren, of als je wilt, kun je een nieuwe aanmaken voor deze taak.
Hierna zijn we klaar om de AWS CLI te gebruiken om toegang te krijgen tot onze Amazon AWS-services.
Amazon S3
Dit is waarschijnlijk de meest gebruikte optie om back-ups in de cloud op te slaan. Amazon S3 kan elke hoeveelheid gegevens overal op internet opslaan en ophalen. Het is een eenvoudige opslagservice die een extreem duurzame, zeer beschikbare en oneindig schaalbare infrastructuur voor gegevensopslag biedt tegen lage kosten.
Amazon S3 biedt een eenvoudige webservice-interface die u kunt gebruiken om elke hoeveelheid gegevens op elk moment en overal op internet op te slaan en op te halen en (met de AWS CLI of AWS SDK) u kan het integreren met verschillende systemen en programmeertalen.
Hoe het te gebruiken
Amazon S3 gebruikt buckets. Het zijn unieke containers voor alles wat je opslaat in Amazon S3. De eerste stap is dus om toegang te krijgen tot de Amazon S3-beheerconsole en een nieuwe bucket te maken.
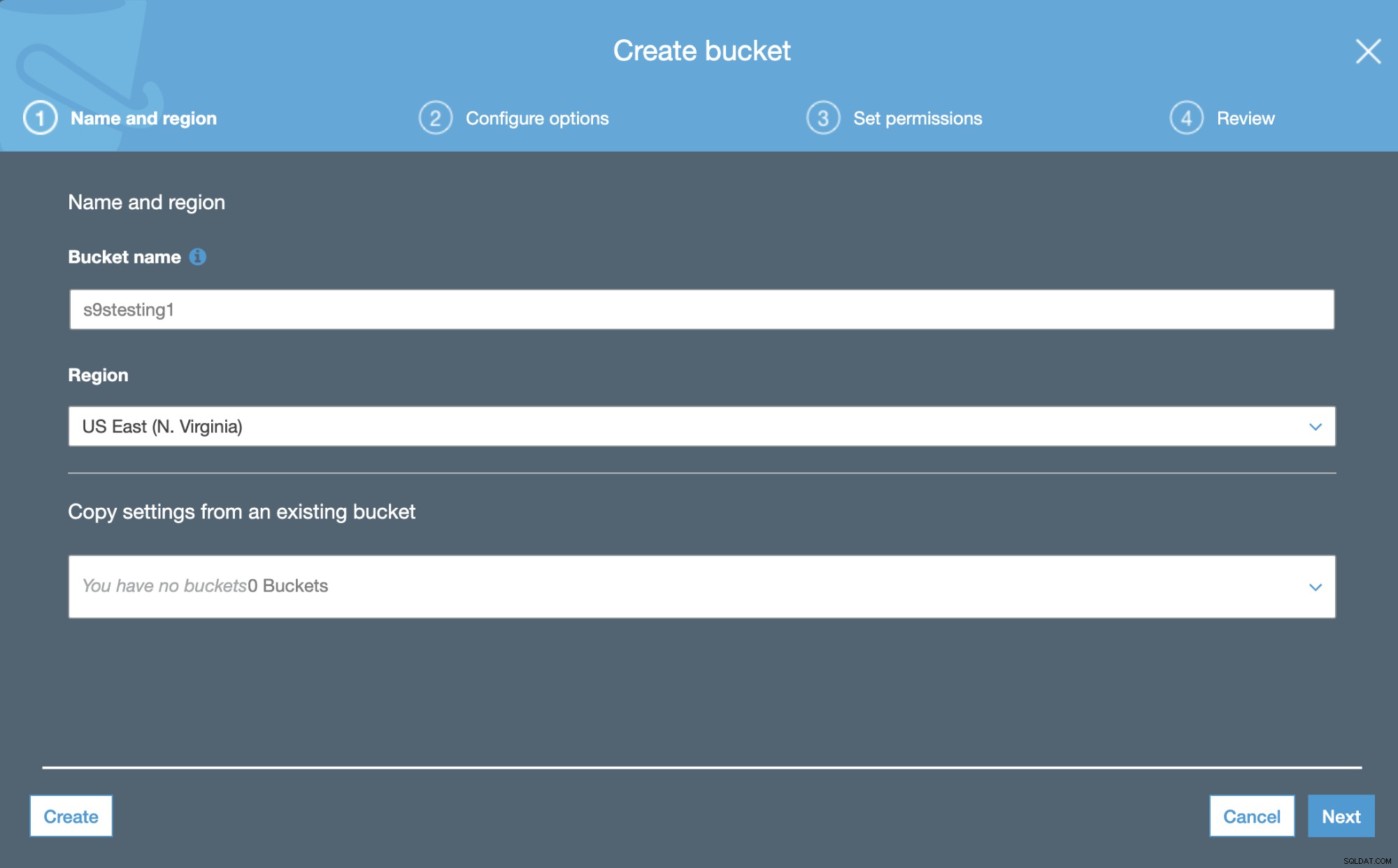
In de eerste stap hoeven we alleen de Bucket-naam en de AWS-regio.
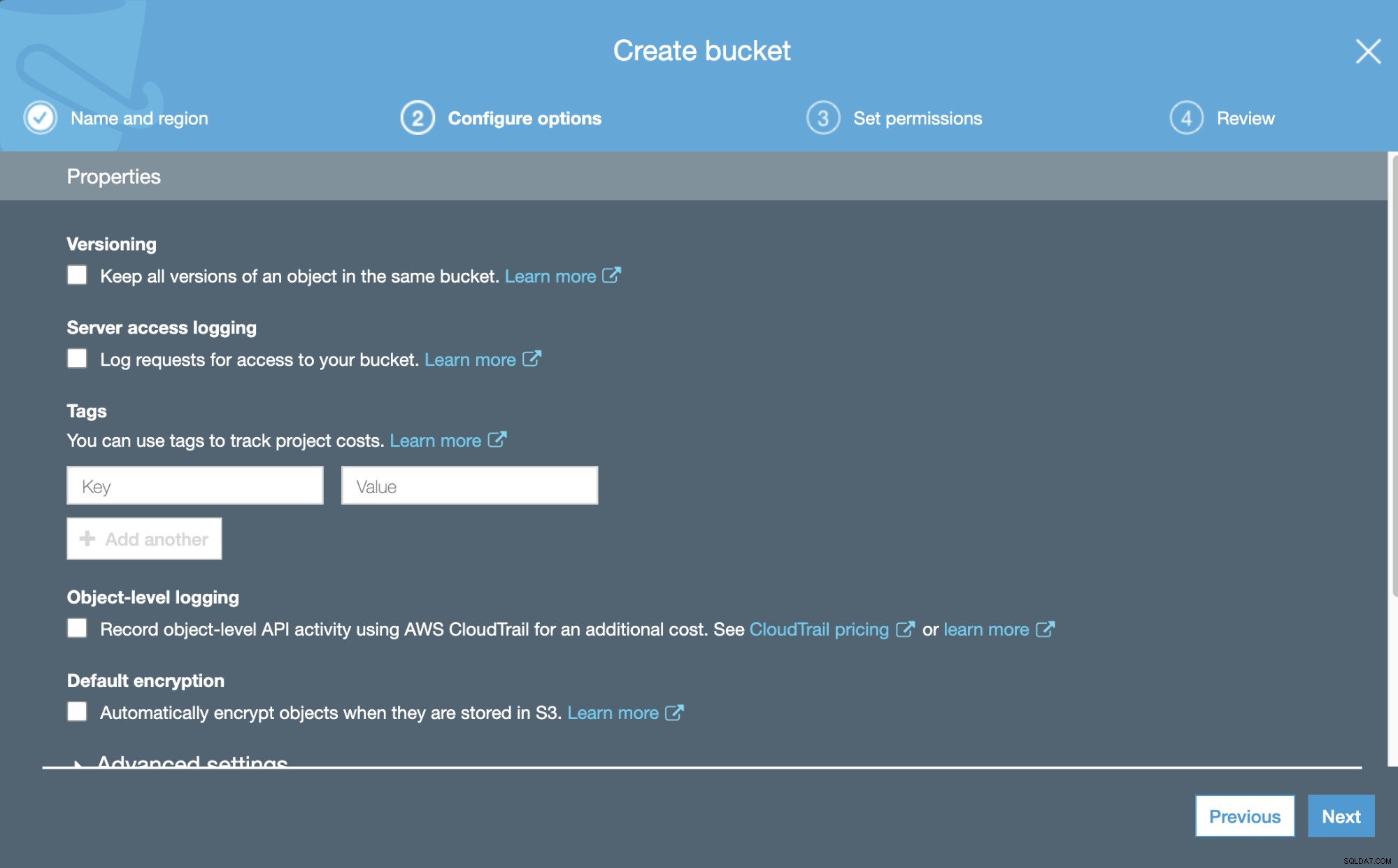
Nu kunnen we enkele details over onze nieuwe Bucket configureren, zoals versiebeheer en loggen.

En dan kunnen we de rechten voor deze nieuwe bucket specificeren.
Nu hebben we onze bucket gemaakt, laten we kijken hoe we die kunnen gebruiken om bewaar onze PostgreSQL-back-ups.
Laten we eerst onze client testen die hem verbindt met S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Het werkt! Met het vorige commando geven we een lijst van de huidige Buckets die zijn gemaakt.
Dus nu kunnen we de back-up uploaden naar de S3-service. Hiervoor kunnen we de opdracht aws sync of aws cp gebruiken.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# We kunnen de inhoud van de bucket bekijken op de AWS-website.
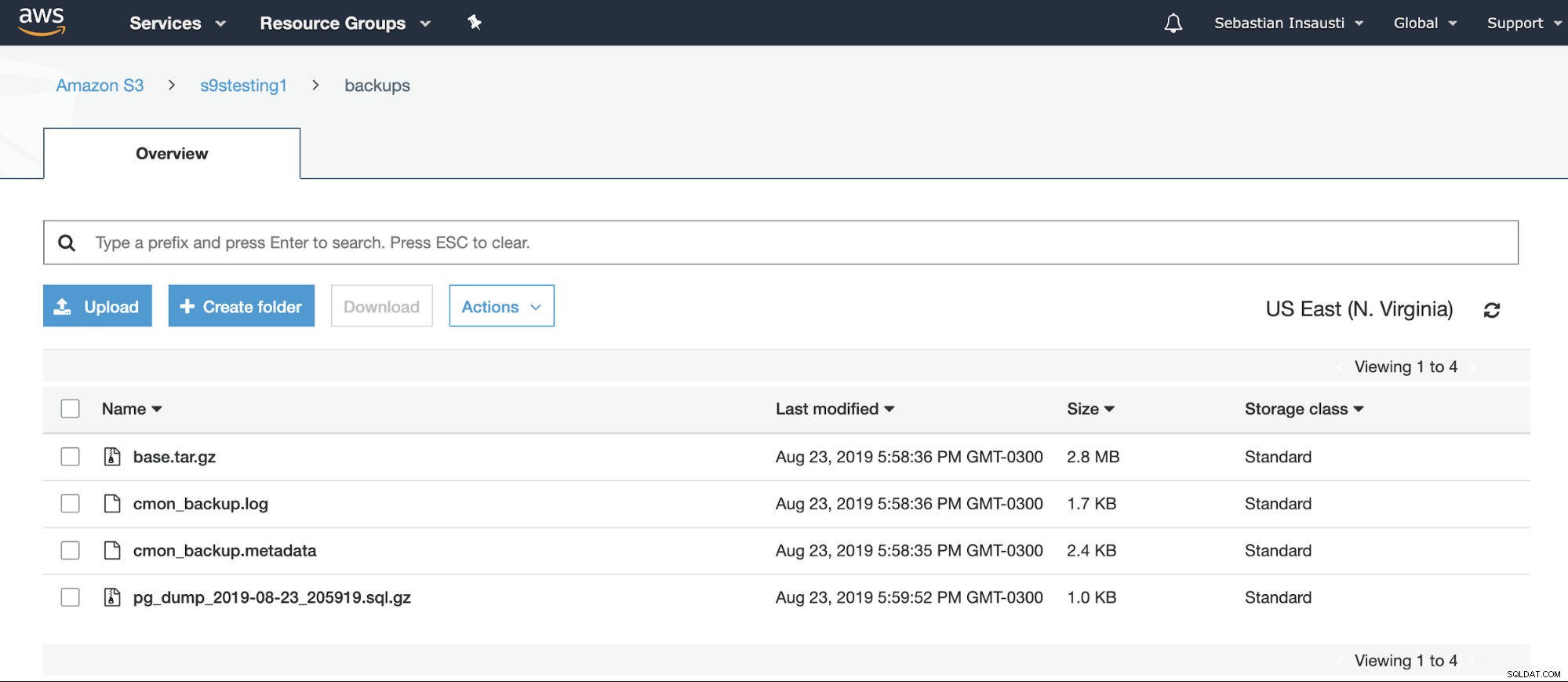
Of zelfs met behulp van de AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzVoor meer informatie over AWS S3 CLI kunt u de officiële AWS-documentatie raadplegen.
Amazon S3-gletsjer
Dit is de goedkopere versie van Amazon S3. Het belangrijkste verschil tussen hen is snelheid en toegankelijkheid. U kunt Amazon S3 Glacier gebruiken als de opslagkosten laag moeten blijven en u geen millisecondentoegang tot uw gegevens nodig heeft. Gebruik is een ander belangrijk verschil tussen beide.
Hoe het te gebruiken
In plaats van Buckets gebruikt Amazon S3 Glacier Vaults. Het is een container voor het opslaan van elk object. De eerste stap is dus om toegang te krijgen tot de Amazon S3 Glacier Management Console en een nieuwe Vault te maken.
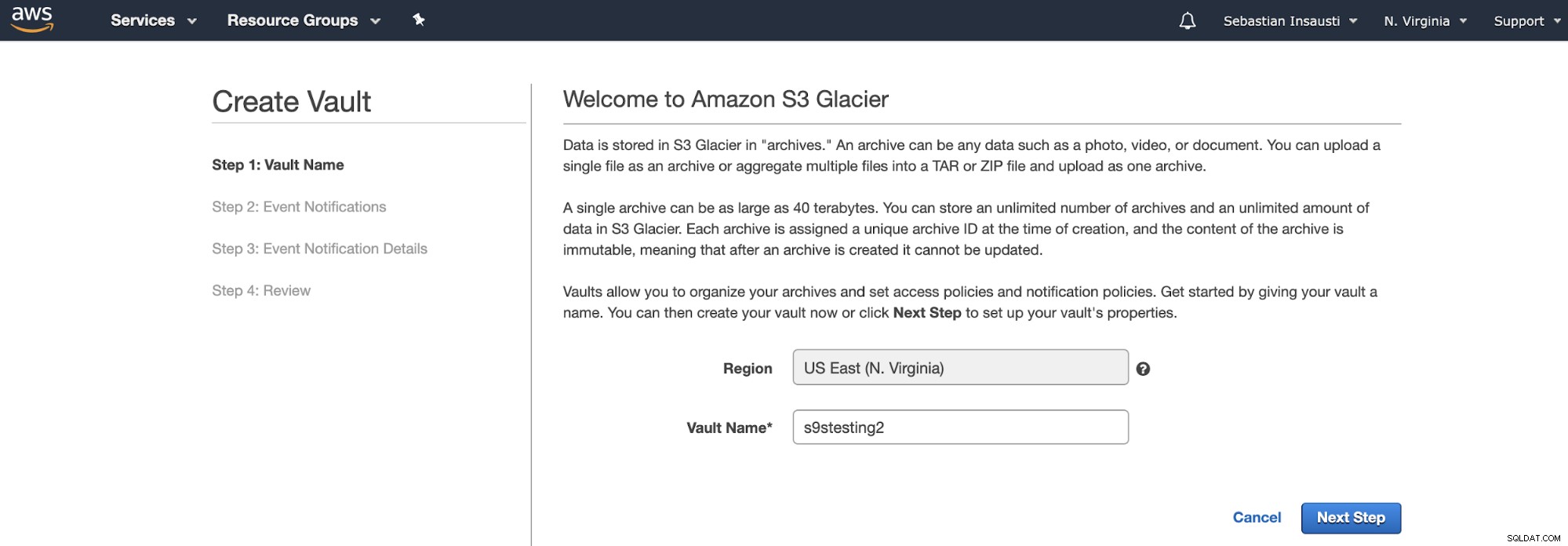
Hier moeten we de kluisnaam en de regio toevoegen en, in de volgende stap kunnen we de gebeurtenismeldingen inschakelen die de Amazon Simple Notification Service (Amazon SNS) gebruiken.
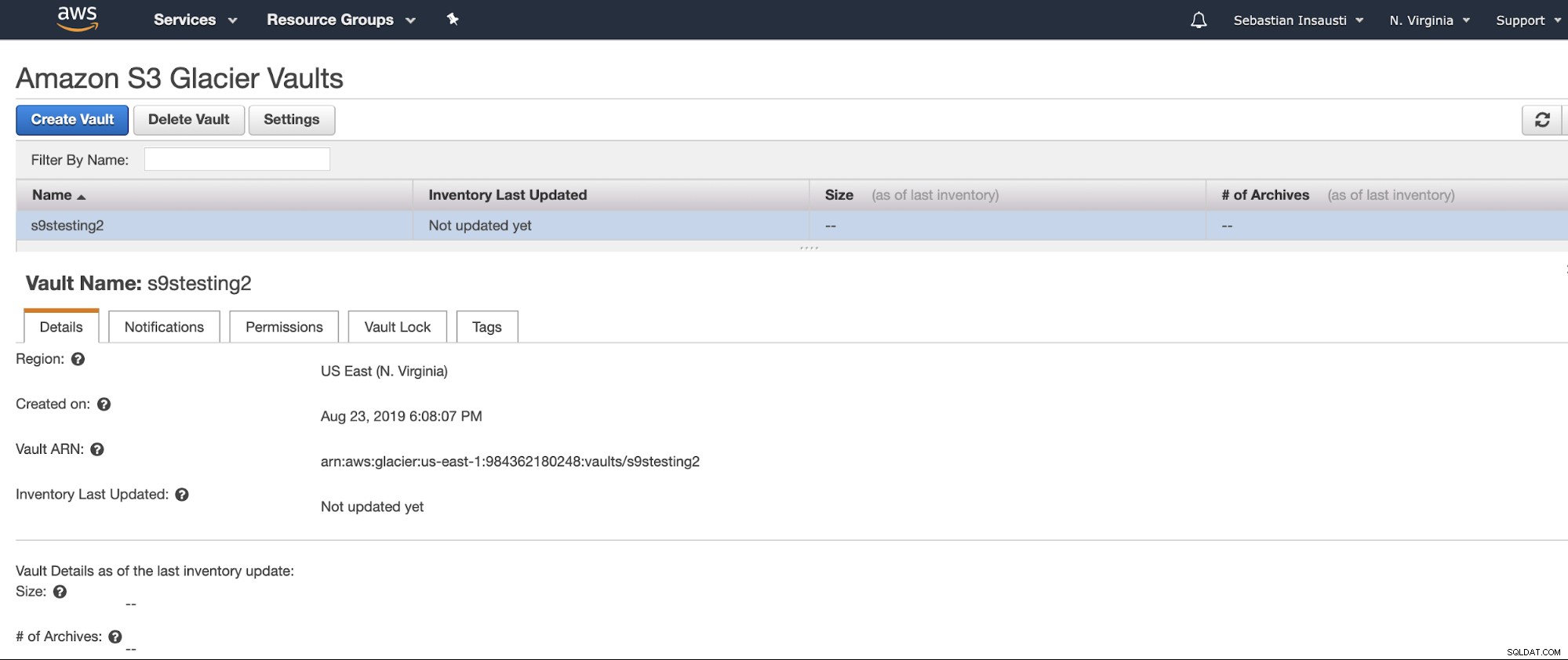
Nu we onze kluis hebben gemaakt, hebben we er toegang toe vanuit de AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Het werkt. Dus nu kunnen we onze back-up hier uploaden.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Een belangrijk ding is dat de Vault-status ongeveer één keer per dag wordt bijgewerkt, dus we moeten wachten tot het bestand is geüpload.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Hier hebben we ons bestand geüpload naar onze S3 Glacier Vault.
Voor meer informatie over AWS Glacier CLI kun je de officiële AWS-documentatie raadplegen.
EC2
Deze back-upopslagoptie is duurder en tijdrovender, maar het is handig als u volledige controle wilt hebben over de back-upopslagomgeving en aangepaste taken op de back-ups wilt uitvoeren (bijv. .)
Amazon EC2 (Elastic Compute Cloud) is een webservice die aanpasbare rekencapaciteit in de cloud biedt. Het geeft u volledige controle over uw computerbronnen en stelt u in staat om alles over uw instanties in te stellen en te configureren, van uw besturingssysteem tot uw toepassingen. Het stelt u ook in staat om snel de capaciteit op te schalen, zowel naar boven als naar beneden, als uw computervereisten veranderen.
Amazon EC2 ondersteunt verschillende besturingssystemen zoals Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux en FreeBSD.
Hoe het te gebruiken
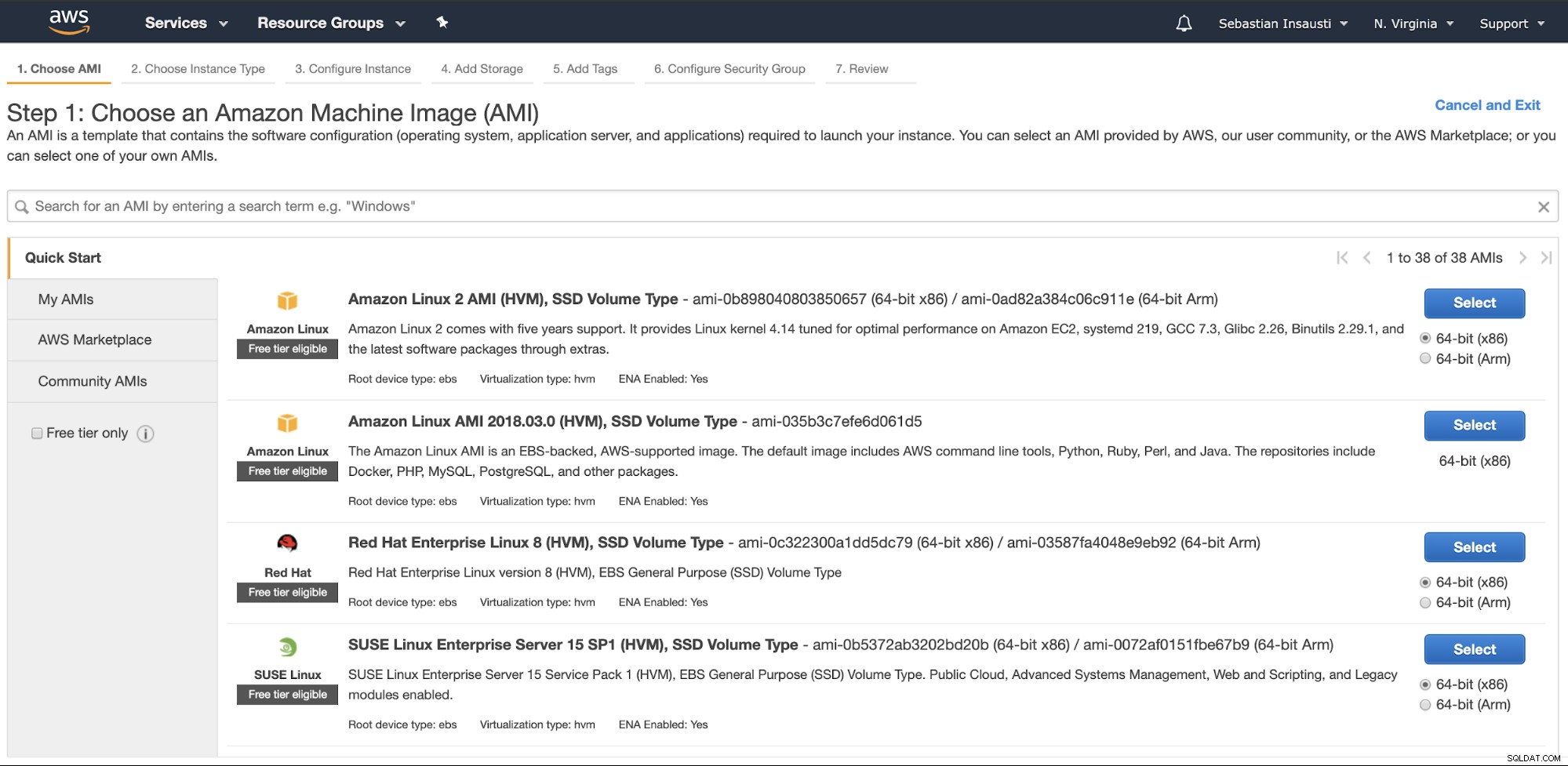
Ga naar het Amazon EC2-gedeelte en druk op Instantie starten. In de eerste stap moet u het EC2-instance-besturingssysteem kiezen.
In de volgende stap moet u de bronnen voor de nieuwe instantie kiezen.
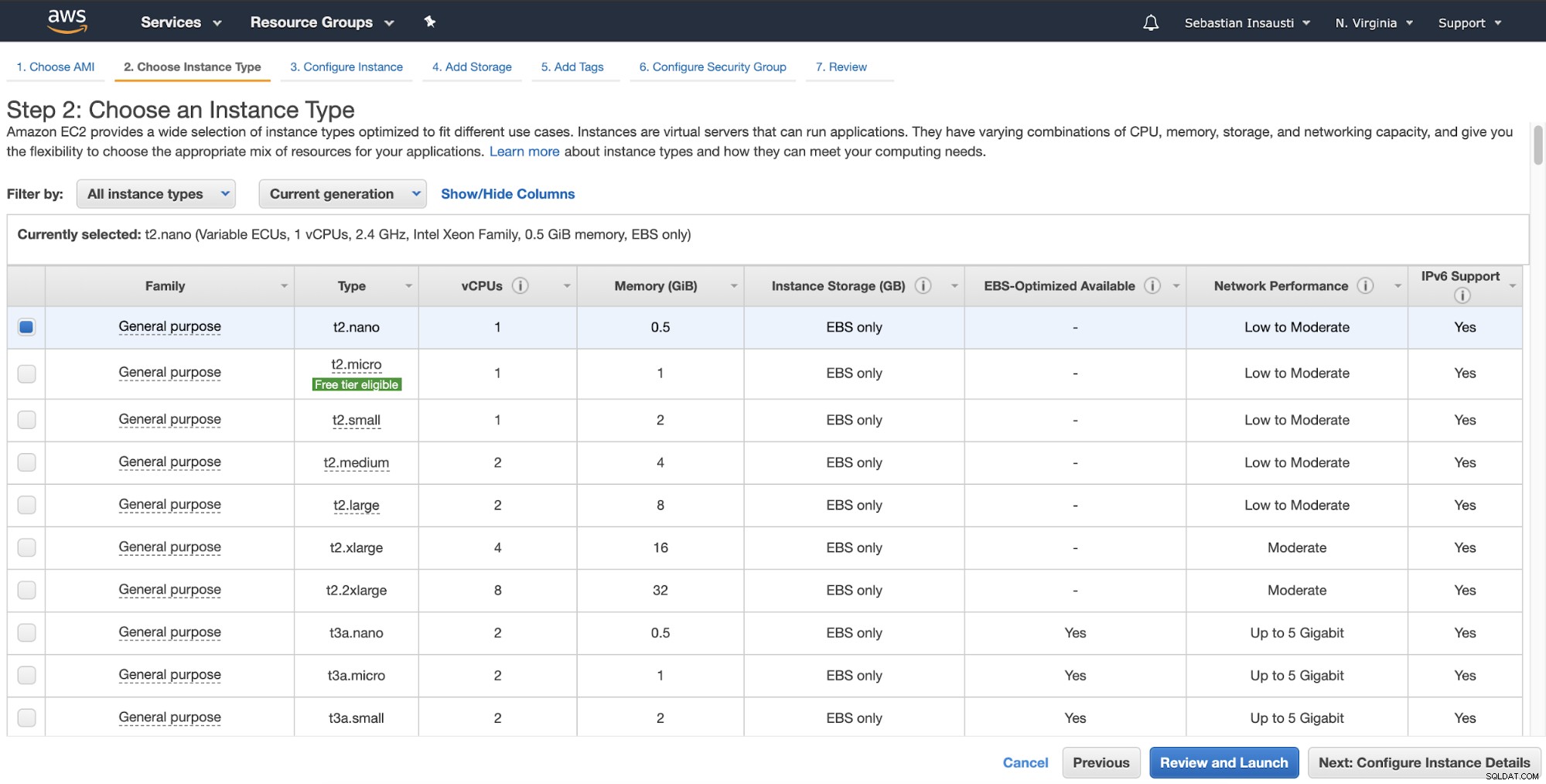
Vervolgens kunt u een meer gedetailleerde configuratie opgeven, zoals netwerk, subnet en meer .
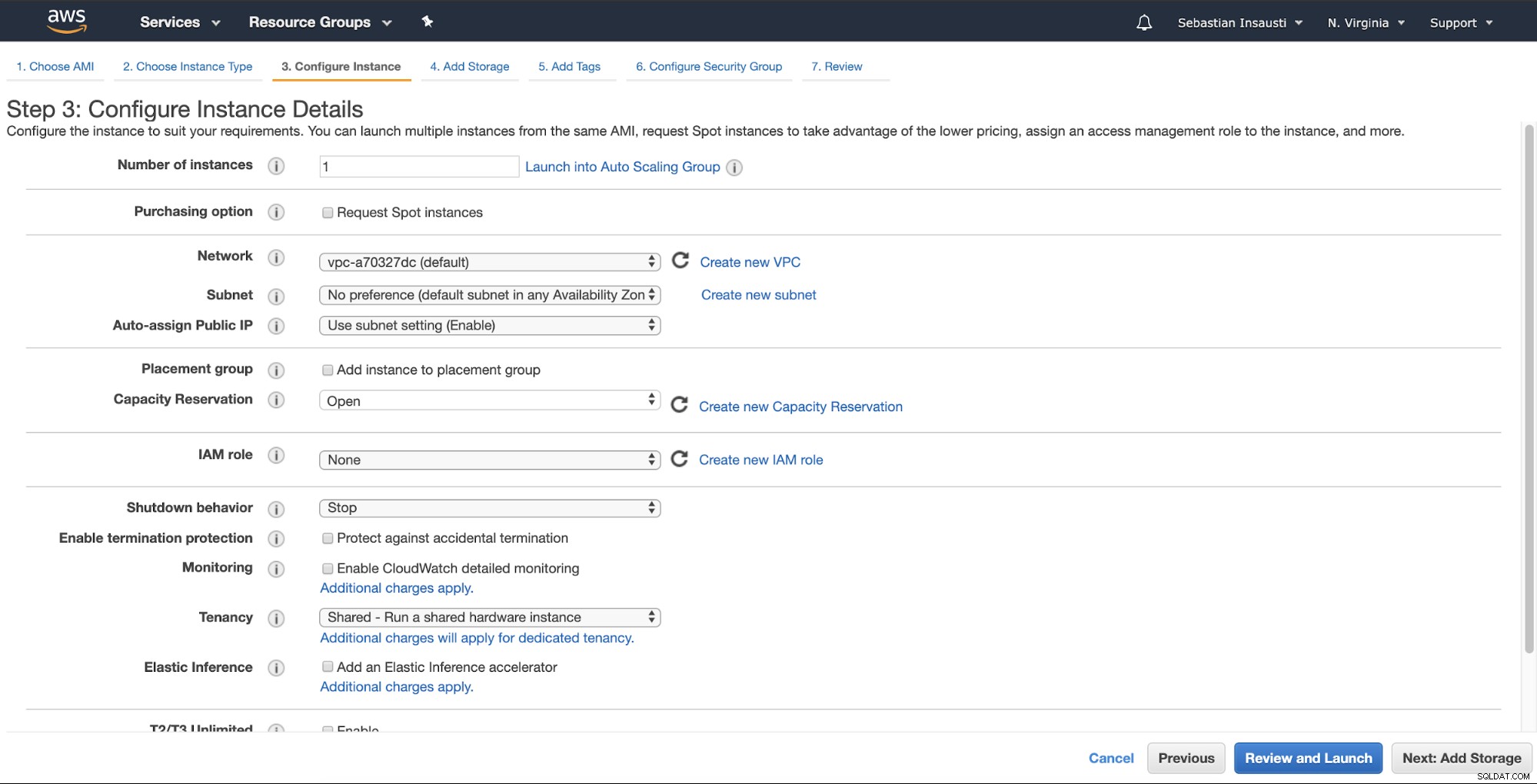
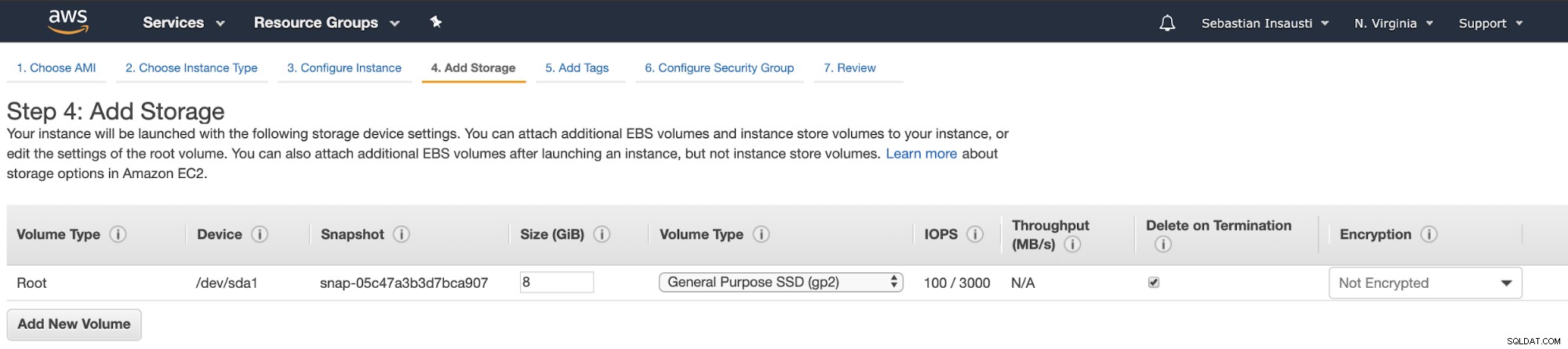
Nu kunnen we meer opslagcapaciteit toevoegen aan deze nieuwe instantie, en als een back-upserver, we zouden het moeten doen.
Als we klaar zijn met de aanmaaktaak, kunnen we naar de sectie Instanties gaan om zie onze nieuwe EC2-instantie.
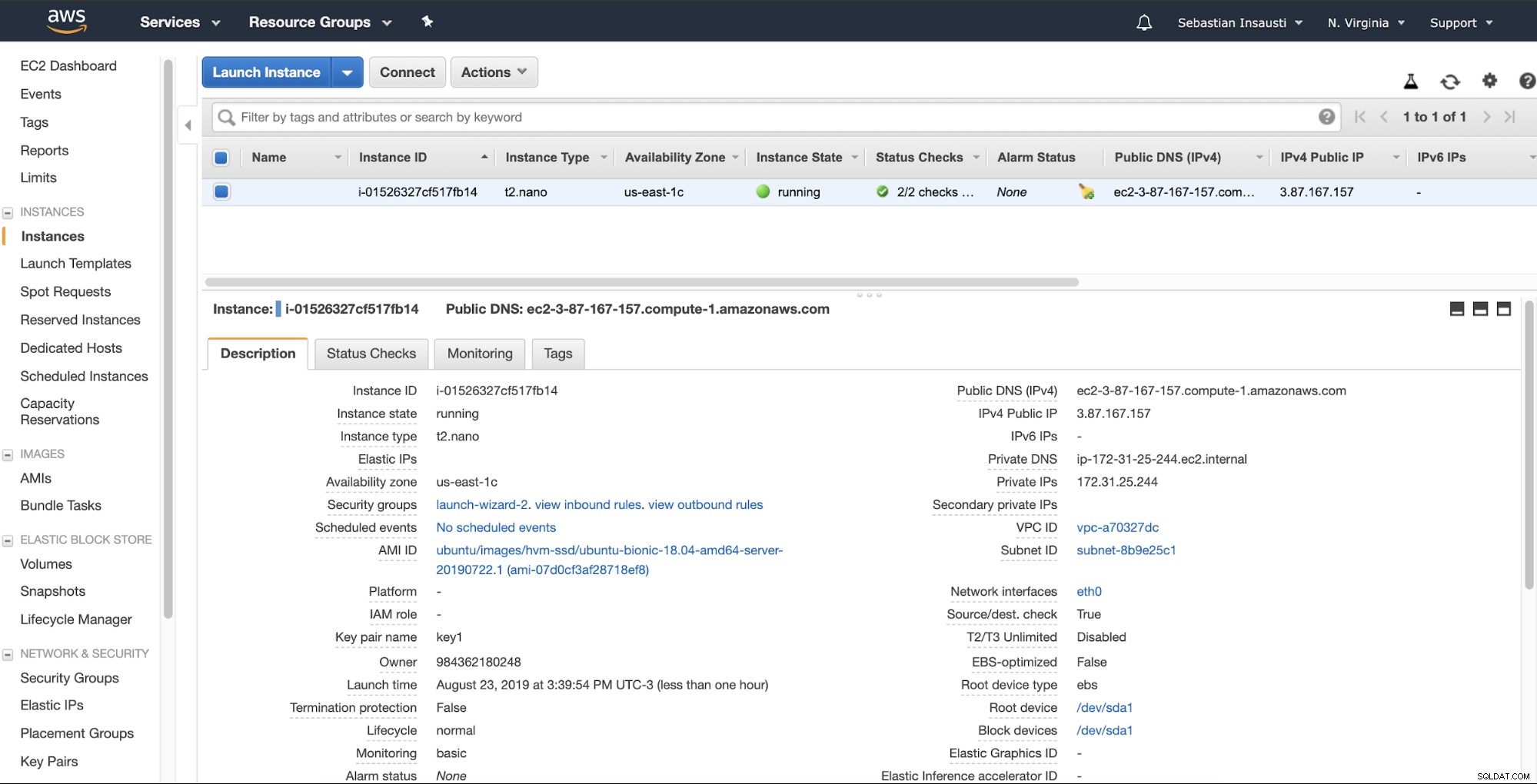
Als de instantie gereed is (instantiestatus actief), kunt u de back-ups hier, bijvoorbeeld door het via SSH of FTP te verzenden met behulp van de openbare DNS die door AWS is gemaakt. Laten we een voorbeeld bekijken met Rsync en een ander met het SCP Linux-commando.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00AWS-back-up
AWS Backup is een gecentraliseerde back-upservice die u back-upbeheermogelijkheden biedt, zoals back-upplanning, retentiebeheer en back-upbewaking, evenals extra functies, zoals lifecycling-back-ups tegen een lage prijs opslaglaag, back-upopslag en encryptie die onafhankelijk is van de brongegevens, en back-uptoegangsbeleid.
U kunt AWS Backup gebruiken om back-ups van EBS-volumes, RDS-databases, DynamoDB-tabellen, EFS-bestandssystemen en Storage Gateway-volumes te beheren.
Hoe het te gebruiken
Ga naar het gedeelte AWS Backup op de AWS Management Console.
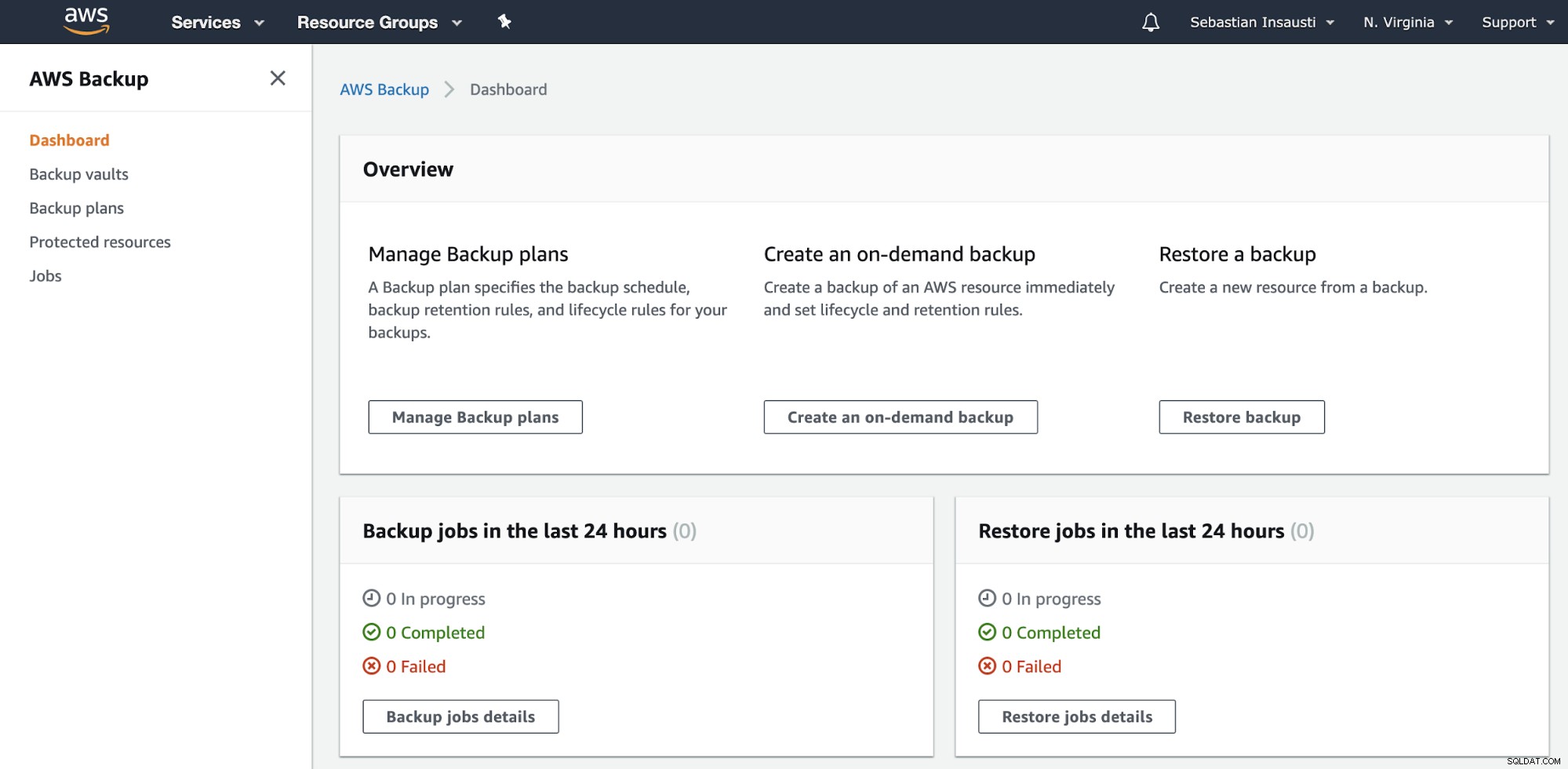
Hier heb je verschillende opties, zoals Plannen, Maken of Herstellen van een back-up . Laten we eens kijken hoe we een nieuwe back-up kunnen maken.
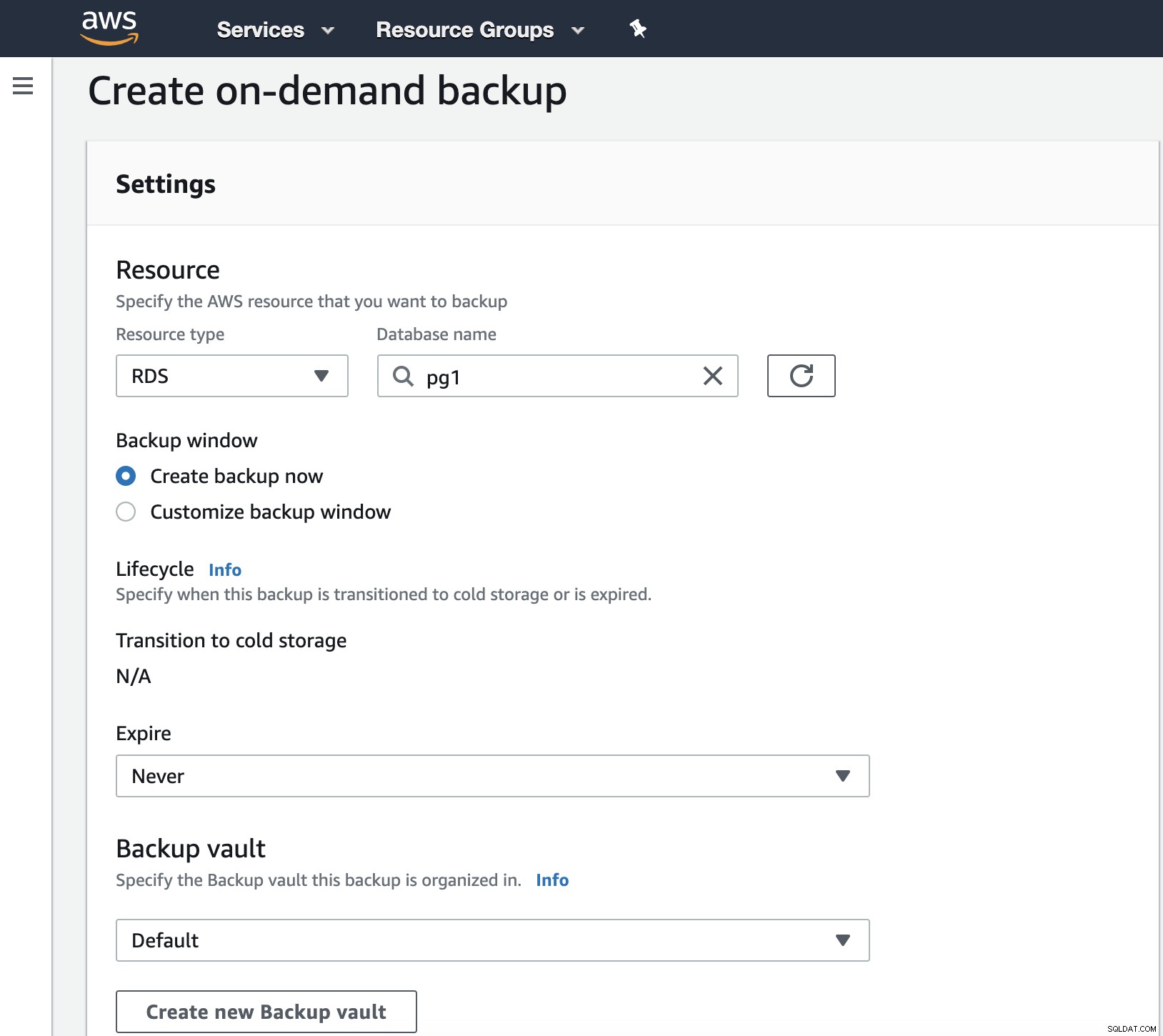
In deze stap moeten we het brontype kiezen dat DynamoDB kan zijn, RDS, EBS, EFS of Storage Gateway en meer details zoals de vervaldatum, back-upkluis en de IAM-rol.
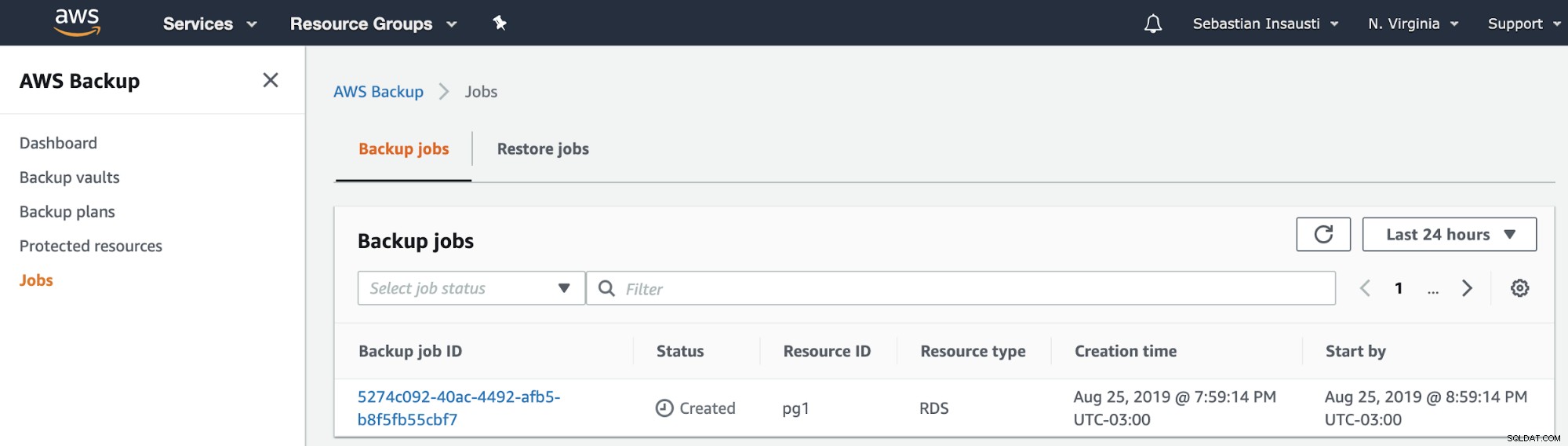
Vervolgens kunnen we de nieuwe taak zien die is gemaakt in de sectie AWS-back-uptaken .
Momentopname
Nu kunnen we deze bekende optie in alle virtualisatie-omgevingen vermelden. De snapshot is een back-up die op een specifiek tijdstip is gemaakt en AWS stelt ons in staat deze te gebruiken voor de AWS-producten. Laten we een voorbeeld geven van een RDS-snapshot.
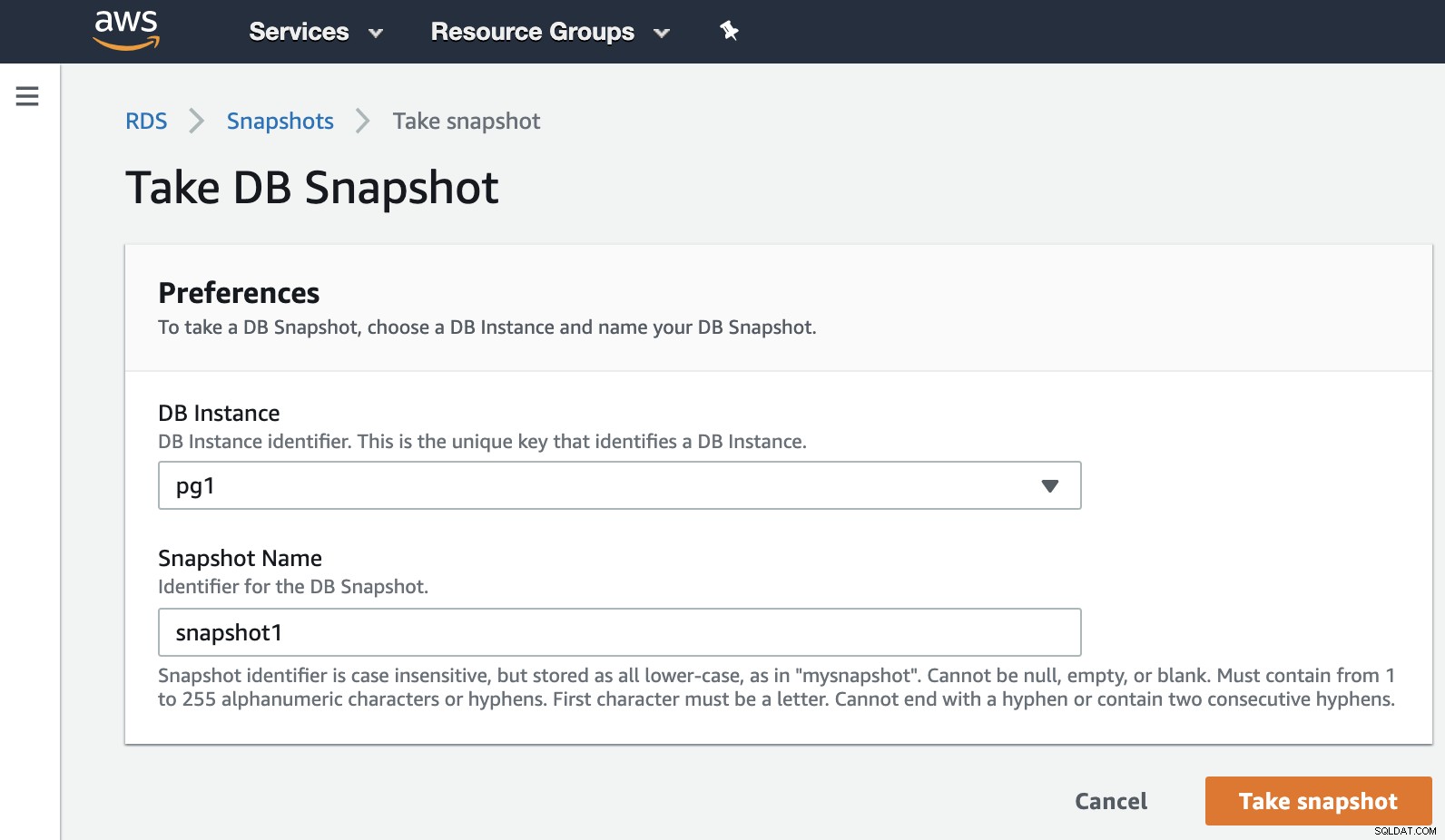
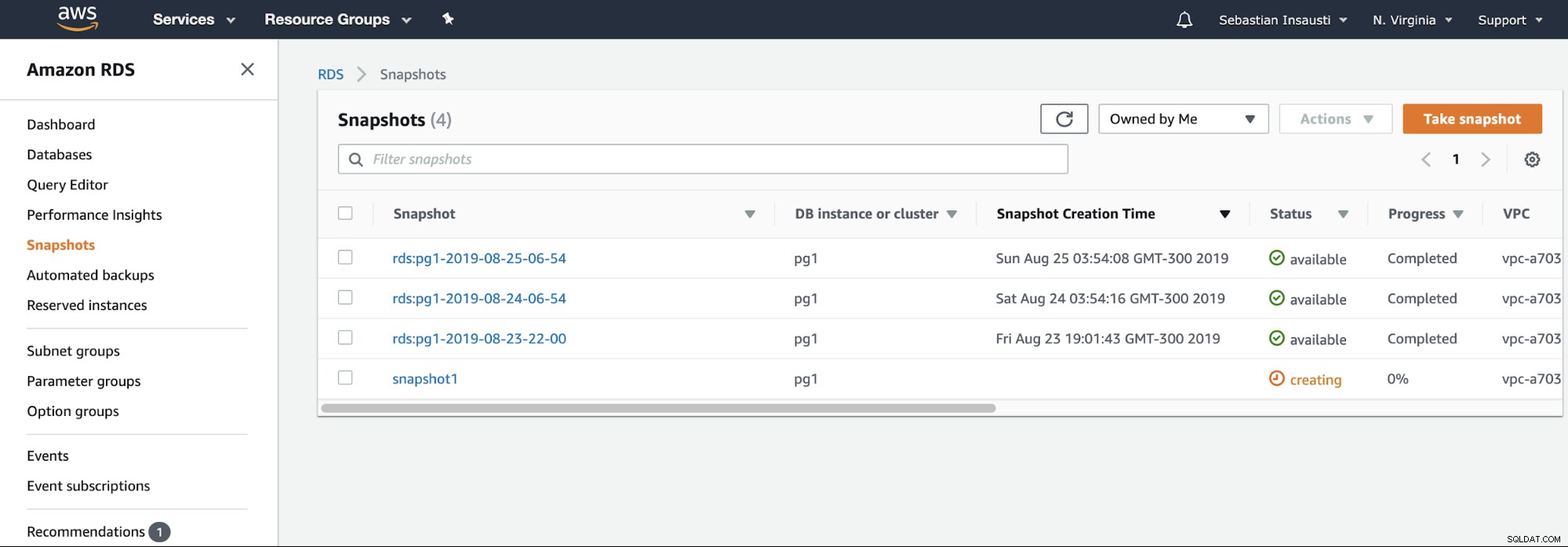
We hoeven alleen de instantie te kiezen en de snapshotnaam toe te voegen, en dat is het. We kunnen deze en de vorige snapshot zien in de sectie RDS Snapshot.
Uw back-ups beheren met ClusterControl
ClusterControl is een uitgebreid beheersysteem voor open source-databases dat implementatie- en beheerfuncties automatiseert, evenals gezondheids- en prestatiebewaking. ClusterControl ondersteunt implementatie, beheer, monitoring en schaling voor verschillende databasetechnologieën en -omgevingen, inclusief EC2. We kunnen dus bijvoorbeeld onze EC2-instantie op AWS maken en onze databaseservice implementeren/importeren met ClusterControl.

Een back-up maken
Ga voor deze taak naar ClusterControl -> Cluster selecteren -> Back-up -> Back-up maken.
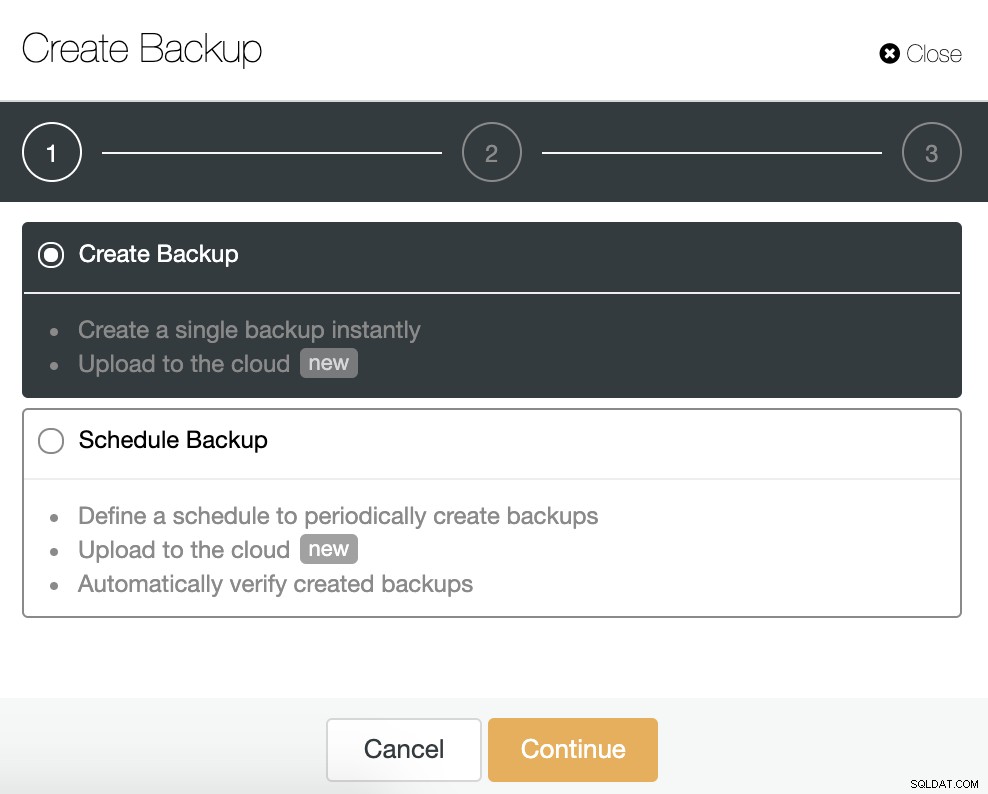
We kunnen een nieuwe back-up maken of een geplande back-up configureren. Voor ons voorbeeld maken we direct een enkele back-up.
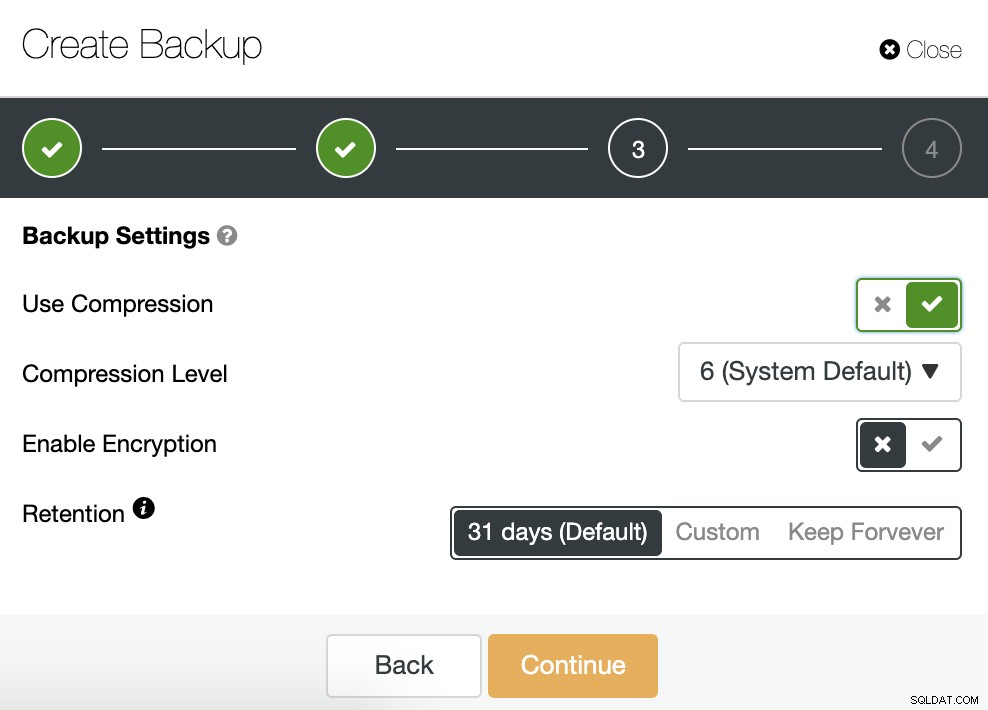
We moeten één methode kiezen, de server waarvan de back-up wordt genomen , en waar we de back-up willen opslaan. We kunnen onze back-up ook uploaden naar de cloud (AWS, Google of Azure) door de bijbehorende knop in te schakelen.
Vervolgens specificeren we het gebruik van compressie, het compressieniveau, encryptie en retentie periode voor onze back-up.
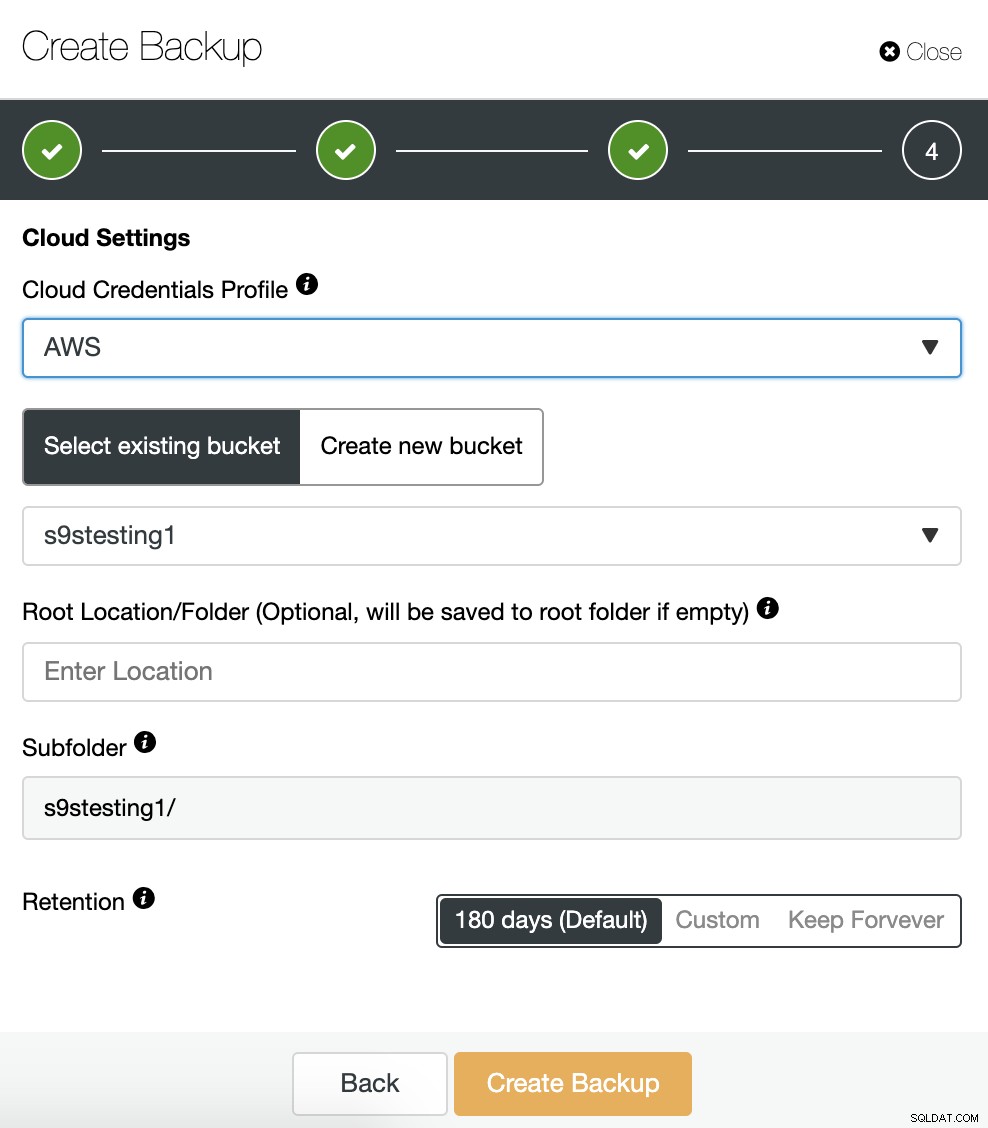
Als we de optie voor het uploaden naar de cloud hebben ingeschakeld, zullen we zien een sectie om de cloudprovider (in dit geval AWS) en de inloggegevens op te geven (ClusterControl -> Integraties -> Cloudproviders). Voor AWS gebruikt het de S3-service, dus we moeten een bucket selecteren of zelfs een nieuwe maken om onze back-ups op te slaan.
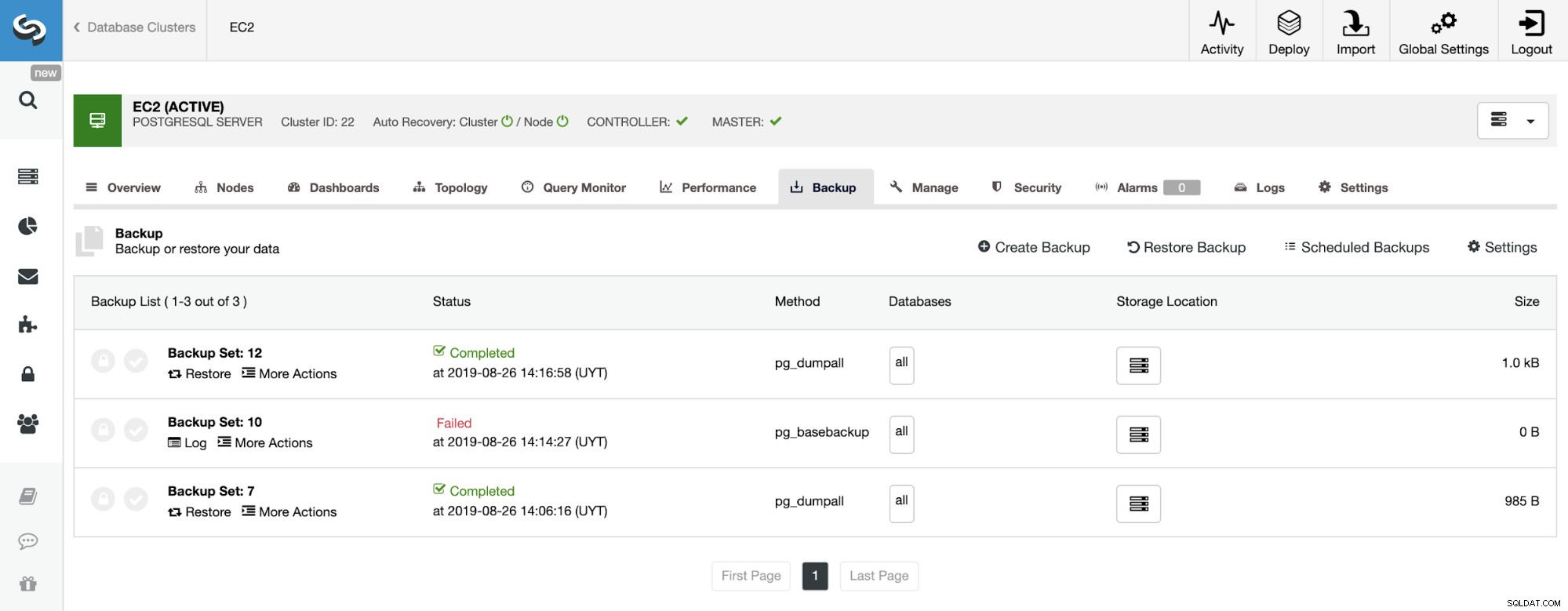
In de back-upsectie kunnen we de voortgang van de back-up zien, en informatie zoals methode, grootte, locatie en meer.
Conclusie
Met Amazon AWS kunnen we onze PostgreSQL-back-ups opslaan, of we het nu als databasecloudprovider gebruiken of niet. Om een effectief back-upplan te hebben, moet u overwegen om ten minste één databaseback-upkopie in de cloud op te slaan om gegevensverlies in het geval van een hardwarestoring in een andere back-upopslag te voorkomen. Met de cloud kunt u zoveel back-ups opslaan als u wilt opslaan of waarvoor u wilt betalen.