Ik begin met de tweede vraag, die is makkelijker. De dplyr . gebruiken pakket, kunt u top_n . gebruiken om de n grootste rijen voor een bepaalde kolom te krijgen. Bijvoorbeeld:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Merk op dat je meer dan n rijen krijgt als er gelijke punten zijn voor de nde plaats. Dus top_n(p_ash_r_100, 10, SMPL_CNT) zal de volledige set met voorbeeldgegevens retourneren vanwege de 17-voudige gelijkspel voor de 4e.
Wat betreft de eerste vraag, de documentatie voor geom_area geeft een aanwijzing:
Dit suggereert dat geom_area verwacht dat de kolom die is toegewezen aan x numeriek moet zijn. Gebaseerd op de vermelding voor p_ash_r_100 , SMPL_TIME lijkt een karaktervector te zijn. Met het lubridate pakket, kunnen we SMPL_TIME . converteren naar een datum-tijd met dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
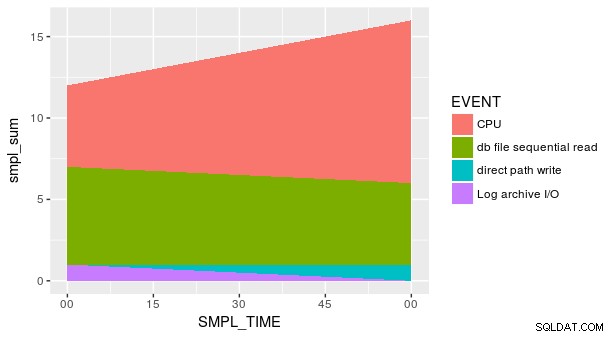
Dit is echter niet genoeg om de gewenste plot te krijgen, aangezien er meerdere waarden zijn van y voor elke combinatie van x en fill (wat de juiste esthetiek is voor geom_area , niet "col "). We moeten de gegevens samenvatten voordat we plotten:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
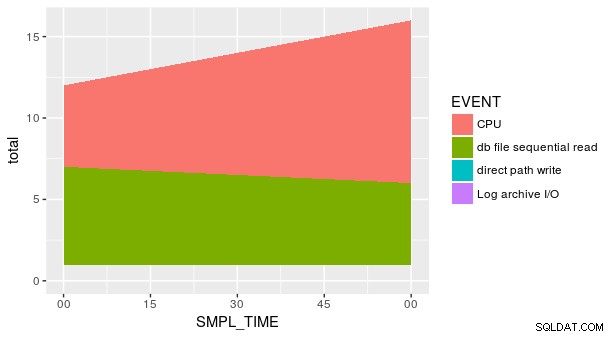
Toch klopt het plot nog steeds niet. Dit komt omdat elke combinatie van SMPL_TIME en EVENT komt niet voor in de dataset. We moeten geom_area expliciet vertellen dat y is gelijk aan nul voor de ontbrekende rijen. Een manier is om de handige fill . te gebruiken argument in tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()