Voorjaarstransactierouting
Eerst maken we een DataSourceType Java Enum dat onze opties voor transactieroutering definieert:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Om de lees-schrijftransacties naar het primaire knooppunt en alleen-lezen transacties naar het Replica-knooppunt te routeren, kunnen we een ReadWriteDataSource definiëren die verbinding maakt met het primaire knooppunt en een ReadOnlyDataSource die verbinding maken met het Replica-knooppunt.
De read-write en read-only transactierouting wordt gedaan door de Spring AbstractRoutingDataSource abstractie, die wordt geïmplementeerd door de TransactionRoutingDatasource , zoals geïllustreerd door het volgende diagram:
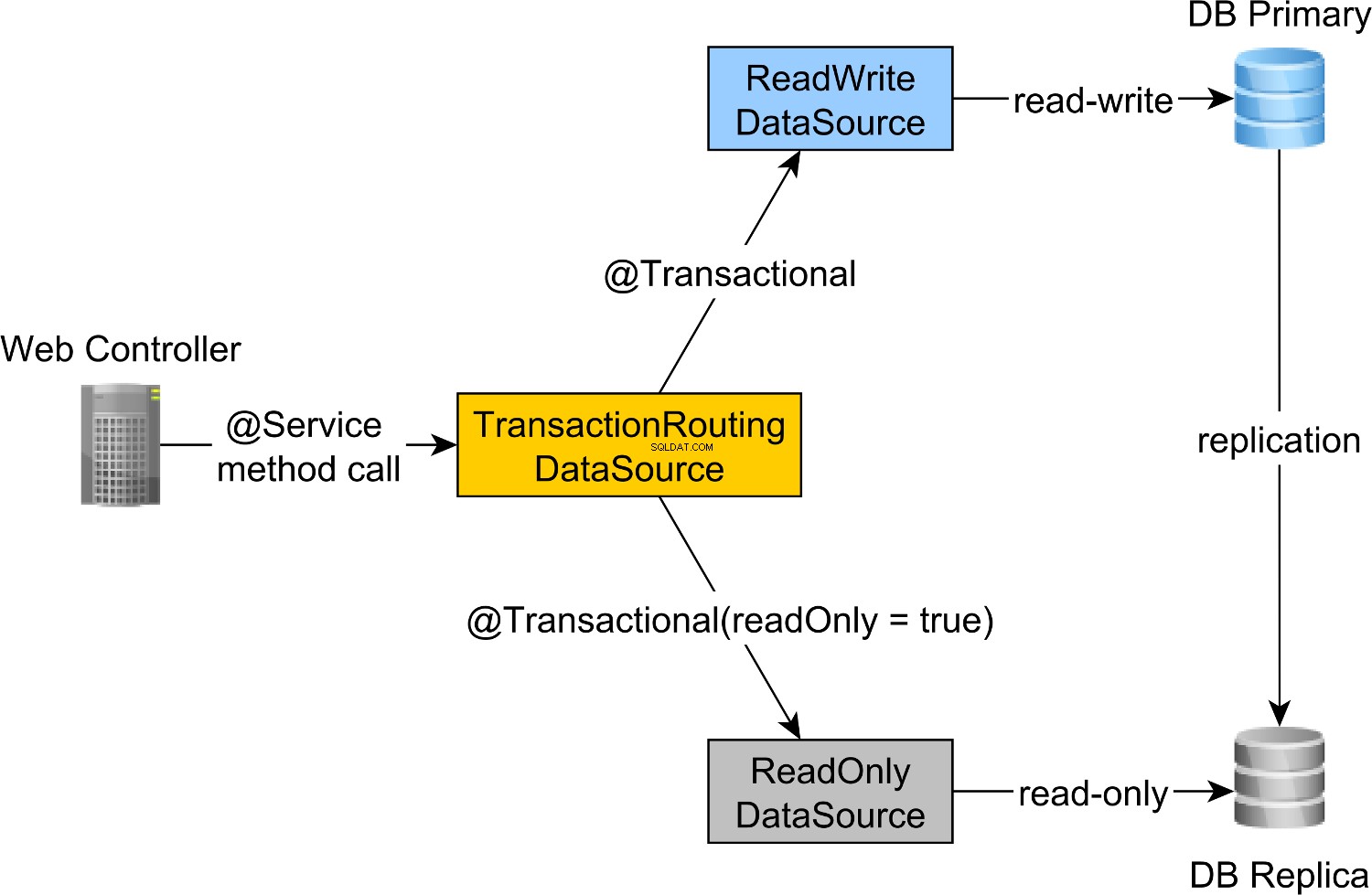
De TransactionRoutingDataSource is zeer eenvoudig te implementeren en ziet er als volgt uit:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
Kortom, we inspecteren de Spring TransactionSynchronizationManager klasse die de huidige transactiecontext opslaat om te controleren of de momenteel lopende Spring-transactie alleen-lezen is of niet.
De determineCurrentLookupKey methode retourneert de discriminatorwaarde die zal worden gebruikt om de read-write of de read-only JDBC DataSource te kiezen .
Lente lezen-schrijven en alleen-lezen JDBC DataSource-configuratie
De DataSource configuratie ziet er als volgt uit:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
De /META-INF/jdbc-postgresql-replication.properties resource-bestand biedt de configuratie voor de read-write en read-only JDBC DataSource componenten:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
De jdbc.url.primary eigenschap definieert de URL van het primaire knooppunt terwijl de jdbc.url.replica definieert de URL van het Replica-knooppunt.
De readWriteDataSource Spring-component definieert de lees-schrijf JDBC DataSource terwijl de readOnlyDataSource component definieert de alleen-lezen JDBC DataSource .
Merk op dat zowel de read-write en read-only databronnen HikariCP gebruiken voor het poolen van verbindingen.
De actualDataSource fungeert als een façade voor de read-write en read-only databronnen en wordt geïmplementeerd met behulp van de TransactionRoutingDataSource hulpprogramma.
De readWriteDataSource is geregistreerd met behulp van de DataSourceType.READ_WRITE sleutel en de readOnlyDataSource met behulp van de DataSourceType.READ_ONLY sleutel.
Dus bij het uitvoeren van een lees-schrijf @Transactional methode, de readWriteDataSource wordt gebruikt tijdens het uitvoeren van een @Transactional(readOnly = true) methode, de readOnlyDataSource zal in plaats daarvan worden gebruikt.
Merk op dat de
additionalPropertiesmethode definieert dehibernate.connection.provider_disables_autocommitHibernate-eigenschap, die ik aan Hibernate heb toegevoegd om de database-acquisitie voor RESOURCE_LOCAL JPA-transacties uit te stellen.Niet alleen dat de
hibernate.connection.provider_disables_autocommitstelt u in staat om beter gebruik te maken van databaseverbindingen, maar dit is de enige manier waarop we dit voorbeeld kunnen laten werken, aangezien, zonder deze configuratie, de verbinding wordt verkregen voordat dedetermineCurrentLookupKeywordt aangeroepen methodeTransactionRoutingDataSource.
De resterende Spring-componenten die nodig zijn voor het bouwen van de JPA EntityManagerFactory worden gedefinieerd door de AbstractJPAConfiguration basisklasse.
Kortom, de actualDataSource wordt verder verpakt door DataSource-Proxy en verstrekt aan de JPA EntityManagerFactory . Je kunt de broncode op GitHub controleren voor meer details.
Testtijd
Om te controleren of de transactieroutering werkt, gaan we het PostgreSQL-querylogboek inschakelen door de volgende eigenschappen in te stellen in de postgresql.conf configuratiebestand:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
De log_min_duration_statement eigenschapinstelling is voor het loggen van alle PostgreSQL-instructies, terwijl de tweede de databasenaam toevoegt aan het SQL-logboek.
Dus bij het aanroepen van de newPost en findAllPostsByTitle methoden, zoals deze:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
We kunnen zien dat PostgreSQL de volgende berichten logt:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
De log-instructies met behulp van de high_performance_java_persistence prefix werden uitgevoerd op het primaire knooppunt terwijl degenen die de high_performance_java_persistence_replica gebruiken op het Replica-knooppunt.
Dus alles werkt als een tierelier!
Alle broncode is te vinden in mijn High-Performance Java Persistence GitHub-repository, dus je kunt het ook uitproberen.
Conclusie
U moet ervoor zorgen dat u de juiste grootte instelt voor uw verbindingspools, want dat kan een enorm verschil maken. Hiervoor raad ik aan om Flexy Pool te gebruiken.
U moet zeer ijverig zijn en ervoor zorgen dat u alle alleen-lezen transacties dienovereenkomstig markeert. Het is ongebruikelijk dat slechts 10% van uw transacties alleen-lezen is. Zou het kunnen dat u zo'n meest schrijven-toepassing hebt of dat u schrijftransacties gebruikt waarbij u alleen query-instructies geeft?
Voor batchverwerking heeft u zeker lees-schrijftransacties nodig, dus zorg ervoor dat u JDBC-batchverwerking inschakelt, zoals deze:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Voor batchverwerking kunt u ook een aparte DataSource . gebruiken die een andere verbindingspool gebruikt die verbinding maakt met het primaire knooppunt.
Zorg ervoor dat uw totale verbindingsgrootte van alle verbindingspools kleiner is dan het aantal verbindingen waarmee PostgreSQL is geconfigureerd.
Elke batchtaak moet een speciale transactie gebruiken, dus zorg ervoor dat u een redelijke batchgrootte gebruikt.
Meer nog, u wilt sloten vasthouden en transacties zo snel mogelijk afronden. Als de batchprocessor gelijktijdige verwerkingswerkers gebruikt, zorg er dan voor dat de grootte van de bijbehorende verbindingspool gelijk is aan het aantal werkers, zodat ze niet wachten tot anderen verbindingen vrijgeven.