Zoals je misschien uit mijn vorige blog hebt opgemerkt, waren de afgelopen maanden druk bezig om Postgres-XL up-to-date te krijgen met de nieuwste 9.5-release van PostgreSQL. Toen we eenmaal een redelijk stabiele versie van Postgres-XL 9.5 hadden, hebben we onze aandacht verlegd naar het meten van de prestaties van deze gloednieuwe versie van Postgres-XL. Onze keuze voor de benchmark wordt grotendeels beïnvloed door de lopende werkzaamheden aan het AXLE-project, gefinancierd door de Europese Unie in het kader van subsidieovereenkomst 318633. Aangezien we TPC BENCHMARK™ H gebruiken om de prestaties te meten van al het andere werk dat in het kader van dit project is gedaan, hebben we besloten om gebruik dezelfde benchmark voor het evalueren van Postgres-XL. Het past ook bij Postgres-XL omdat TPC-H OLAP-workloads probeert te meten, iets wat Postgres-XL goed zou moeten doen.
1. Postgres-XL-cluster instellen
Toen de benchmark eenmaal was bepaald, was een andere grote uitdaging het vinden van de juiste middelen om te testen. We hadden geen toegang tot een groot cluster van fysieke machines. Dus deden we wat de meesten zouden doen. We besloten Amazon AWS te gebruiken voor het opzetten van het Postgres-XL-cluster. AWS biedt een breed scala aan instanties, waarbij elk instantietype verschillende reken- of IO-kracht biedt.
Deze pagina op AWS toont verschillende beschikbare instantietypen, beschikbare bronnen en hun prijzen voor verschillende regio's. Houd er rekening mee dat de prijzen en beschikbaarheid van regio tot regio kunnen verschillen, dus het is belangrijk dat u alle regio's bekijkt. Aangezien Postgres-XL een lage latentie en een hoge doorvoer tussen de componenten vereist, is het ook belangrijk om alle instanties in dezelfde regio te instantiëren. Voor onze 3TB TPC-H hebben we besloten te gaan voor een 16-datanodecluster van i2.xlarge AWS-instanties. Deze instanties hebben elk 4 vCPU, 30 GB RAM en 800 GB SSD, voldoende opslagruimte om alle gedistribueerde tabellen te bewaren, gerepliceerde tabellen (die meer ruimte innemen naarmate het cluster groter wordt), de indexen erop en er is nog steeds voldoende vrije ruimte in tijdelijke tabelruimte voor CREATE INDEX en andere vragen.
2. Benchmark instellen
2.1 TPC Benchmark™ H
De benchmark bevat 22 queries met als doel grote hoeveelheden data te onderzoeken, queries met een hoge mate van complexiteit uit te voeren en antwoord te geven op kritische bedrijfsvragen. We willen opmerken dat de volledige TPC Benchmark™ H-specificatie verschillende tests behandelt, zoals belasting, vermogen en doorvoer testen. Voor onze tests hebben we alleen individuele zoekopdrachten uitgevoerd en niet de volledige testsuite. TPC Benchmark™ H bestaat uit een reeks zakelijke zoekopdrachten die zijn ontworpen om systeemfunctionaliteiten uit te oefenen op een manier die representatief is voor complexe toepassingen voor bedrijfsanalyse. Deze vragen zijn in een realistische context geplaatst, waarbij de activiteit van een groothandel wordt weergegeven om de lezer te helpen zich intuïtief te verhouden tot de componenten van de benchmark.
2.2 Database-entiteiten, relaties en kenmerken
De componenten van de TPC-H-database zijn gedefinieerd als acht afzonderlijke en afzonderlijke tabellen (de basistabellen). De relaties tussen kolommen van deze tabellen worden geïllustreerd in het volgende diagram. 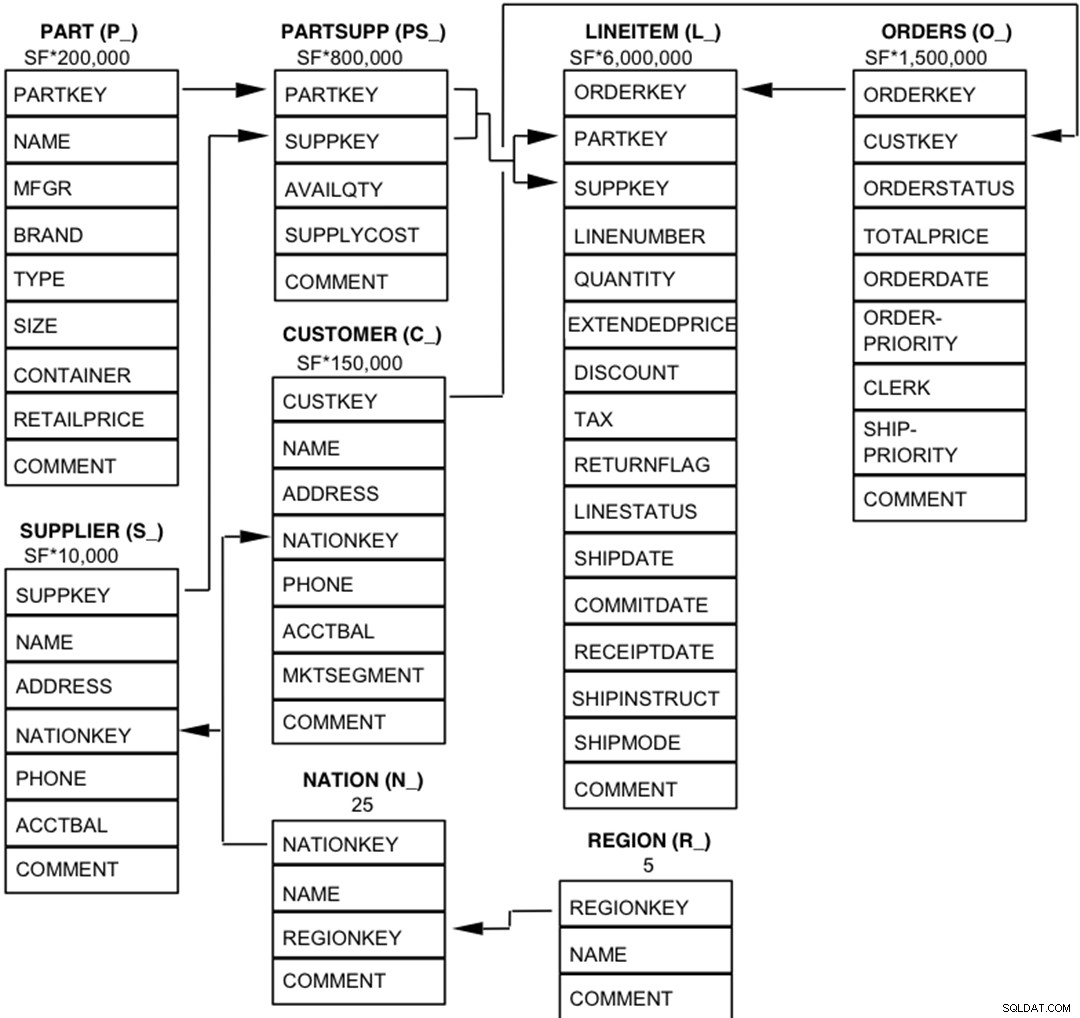 Legende :
Legende :
- De haakjes achter elke tabelnaam bevatten het voorvoegsel van de kolomnamen voor die tabel;
- De pijlen wijzen in de richting van de één-op-veel-relaties tussen tabellen
- Het getal/de formule onder elke tabelnaam vertegenwoordigt de kardinaliteit (aantal rijen) van de tabel. Sommige worden in rekening gebracht door SF, de schaalfactor, om de gekozen databasegrootte te verkrijgen. De kardinaliteit voor de LINEITEM-tabel is bij benadering
2.3 Gegevensdistributie voor Postgres-XL
We analyseerden alle 22 zoekopdrachten in de benchmark en kwamen tot de volgende datadistributiestrategie voor verschillende tabellen in de benchmark.
| Tabelnaam | Distributiestrategie |
| LINEITEM | HASH (l_orderkey) |
| ORDERS | HASH (o_orderkey) |
| DEEL | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| KLANT | GEREPLICEERD |
| LEVERANCIER | GEREPLICEERD |
| NATIE | GEREPLICEERD |
| REGIO | GEREPLICEERD |
Merk op dat LINEITEM en ORDERS, de grootste tabellen in de benchmark, vaak worden samengevoegd op de ORDERKEY. Het is dus logisch om deze tabellen op de ORDERKEY te plaatsen. Evenzo worden PART en PARTSUPP vaak samengevoegd op PARTKEY en daarom worden ze bij elkaar geplaatst in de PARTKEY-kolom. De rest van de tabellen worden gerepliceerd om ervoor te zorgen dat ze indien nodig lokaal kunnen worden samengevoegd.
3. Benchmarkresultaten
3.1 Laadtest
We hebben de resultaten vergeleken die zijn verkregen door een 3TB TPC-H Load Test op PostgreSQL 9.6 uit te voeren met het 16-node Postgres-XL-cluster. De volgende grafieken tonen de prestatiekenmerken van Postgres-XL.
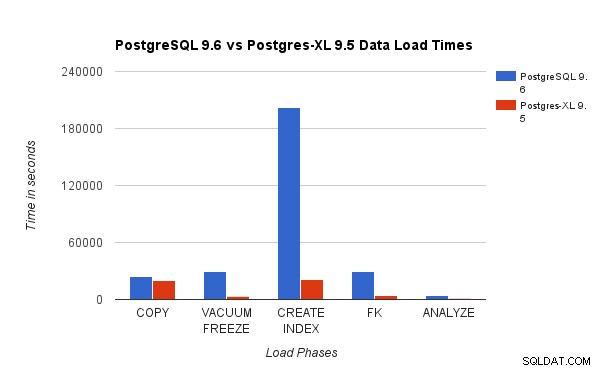 De bovenstaande grafiek toont de tijd die nodig is om verschillende fasen van een laadtest met PostgreSQL en Postgres-XL te voltooien. Zoals te zien is, presteert Postgres-XL iets beter voor COPY en veel beter voor alle andere gevallen. Opmerking :We hebben vastgesteld dat de coördinator veel rekenkracht nodig heeft tijdens de COPY-fase, vooral wanneer er meer dan één COPY-stream tegelijk wordt uitgevoerd. Om dat aan te pakken, werd de coördinator uitgevoerd op een compute-geoptimaliseerde AWS-instantie met 16 vCPU's. Als alternatief hadden we ook meerdere coördinatoren kunnen gebruiken en de rekenbelasting tussen hen kunnen verdelen.
De bovenstaande grafiek toont de tijd die nodig is om verschillende fasen van een laadtest met PostgreSQL en Postgres-XL te voltooien. Zoals te zien is, presteert Postgres-XL iets beter voor COPY en veel beter voor alle andere gevallen. Opmerking :We hebben vastgesteld dat de coördinator veel rekenkracht nodig heeft tijdens de COPY-fase, vooral wanneer er meer dan één COPY-stream tegelijk wordt uitgevoerd. Om dat aan te pakken, werd de coördinator uitgevoerd op een compute-geoptimaliseerde AWS-instantie met 16 vCPU's. Als alternatief hadden we ook meerdere coördinatoren kunnen gebruiken en de rekenbelasting tussen hen kunnen verdelen.
3.2 Vermogenstest
We vergeleken ook de uitvoeringstijden van query's voor 3TB-benchmark op PostgreSQL 9.6 en Postgres-XL 9.5. De volgende grafiek toont prestatiekenmerken van de uitvoering van de query op de twee instellingen.
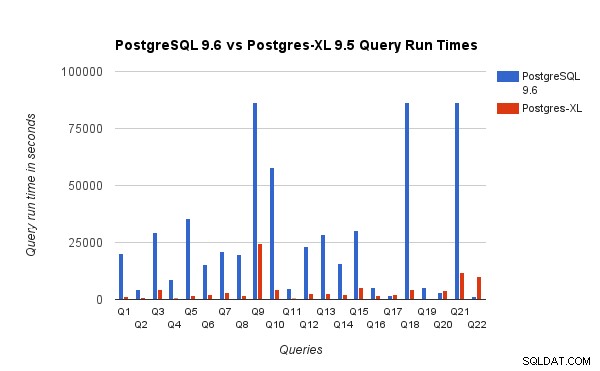 We hebben vastgesteld dat zoekopdrachten gemiddeld ongeveer 6,4 keer sneller werden uitgevoerd op Postgres-XL en ten minste 25% van de zoekopdrachten vertoonden een bijna lineaire prestatieverbetering, met andere woorden, ze presteerden bijna 16 keer sneller op dit 16-node Postgres-XL-cluster. Bovendien toonde ten minste 50% van de zoekopdrachten een 10 keer betere prestatie. We analyseerden de queryprestaties verder en kwamen tot de conclusie dat query's die goed zijn gepartitioneerd over alle beschikbare datanodes, zodat er minimale uitwisseling van gegevens tussen nodes is en zonder herhaalde externe uitvoeringsaanroepen, zeer goed schalen in Postgres-XL. Dergelijke query's hebben meestal een Remote Subquery Scan-knooppunt bovenaan en de substructuur onder het knooppunt wordt parallel uitgevoerd op een of meer knooppunten. Het is ook gebruikelijk om enkele andere knooppunten, zoals een limietknooppunt of een geaggregeerd knooppunt, bovenop het knooppunt Remote Subquery Scan te hebben. Zelfs dergelijke zoekopdrachten presteren zeer goed op Postgres-XL. Query Q1 is een voorbeeld van een query die goed zou moeten schalen met Postgres-XL. Aan de andere kant doen zoekopdrachten die veel uitwisseling van tuples vereisen tussen datanode-datanode en/of coordinator-datanode mogelijk niet goed in Postgres-XL. Evenzo kunnen query's die veel verbindingen tussen knooppunten vereisen, ook slechte prestaties vertonen. U zult bijvoorbeeld merken dat de prestaties van Q22 slecht zijn in vergelijking met een PostgreSQL-server met één knooppunt. Toen we het queryplan voor Q22 analyseerden, zagen we dat er drie niveaus van geneste Remote Subquery Scan-knooppunten in het queryplan zijn, waarbij elk knooppunt een gelijk aantal verbindingen met de datanodes opent. Verder heeft de Nest Loop Anti Join een innerlijke relatie met een Remote Subquery Scan-knooppunt op het hoogste niveau en daarom moet het voor elke tupel van de buitenste relatie een subquery op afstand uitvoeren. Dit resulteert in slechte prestaties bij het uitvoeren van query's.
We hebben vastgesteld dat zoekopdrachten gemiddeld ongeveer 6,4 keer sneller werden uitgevoerd op Postgres-XL en ten minste 25% van de zoekopdrachten vertoonden een bijna lineaire prestatieverbetering, met andere woorden, ze presteerden bijna 16 keer sneller op dit 16-node Postgres-XL-cluster. Bovendien toonde ten minste 50% van de zoekopdrachten een 10 keer betere prestatie. We analyseerden de queryprestaties verder en kwamen tot de conclusie dat query's die goed zijn gepartitioneerd over alle beschikbare datanodes, zodat er minimale uitwisseling van gegevens tussen nodes is en zonder herhaalde externe uitvoeringsaanroepen, zeer goed schalen in Postgres-XL. Dergelijke query's hebben meestal een Remote Subquery Scan-knooppunt bovenaan en de substructuur onder het knooppunt wordt parallel uitgevoerd op een of meer knooppunten. Het is ook gebruikelijk om enkele andere knooppunten, zoals een limietknooppunt of een geaggregeerd knooppunt, bovenop het knooppunt Remote Subquery Scan te hebben. Zelfs dergelijke zoekopdrachten presteren zeer goed op Postgres-XL. Query Q1 is een voorbeeld van een query die goed zou moeten schalen met Postgres-XL. Aan de andere kant doen zoekopdrachten die veel uitwisseling van tuples vereisen tussen datanode-datanode en/of coordinator-datanode mogelijk niet goed in Postgres-XL. Evenzo kunnen query's die veel verbindingen tussen knooppunten vereisen, ook slechte prestaties vertonen. U zult bijvoorbeeld merken dat de prestaties van Q22 slecht zijn in vergelijking met een PostgreSQL-server met één knooppunt. Toen we het queryplan voor Q22 analyseerden, zagen we dat er drie niveaus van geneste Remote Subquery Scan-knooppunten in het queryplan zijn, waarbij elk knooppunt een gelijk aantal verbindingen met de datanodes opent. Verder heeft de Nest Loop Anti Join een innerlijke relatie met een Remote Subquery Scan-knooppunt op het hoogste niveau en daarom moet het voor elke tupel van de buitenste relatie een subquery op afstand uitvoeren. Dit resulteert in slechte prestaties bij het uitvoeren van query's.
4. Een paar AWS-lessen
Tijdens het benchmarken van Postgres-XL hebben we een paar lessen geleerd over het gebruik van AWS. We dachten dat ze nuttig zouden zijn voor iedereen die Postgres-XL op AWS wil gebruiken/testen.
- AWS biedt verschillende soorten instanties. U moet uw werkbelasting en benodigde hoeveelheid opslagruimte zorgvuldig evalueren voordat u een specifiek instantietype kiest.
- Aan de meeste van de voor opslag geoptimaliseerde instanties zijn tijdelijke schijven gekoppeld. U hoeft niets extra te betalen voor die schijven, ze zijn gekoppeld aan de instantie en presteren vaak beter dan EBS. Maar je moet ze expliciet aankoppelen om ze te kunnen gebruiken. Houd er echter rekening mee dat de gegevens die op deze schijven zijn opgeslagen niet permanent zijn en worden gewist als de instantie wordt gestopt. Zorg er dus voor dat u voorbereid bent om met die situatie om te gaan. Omdat we AWS voornamelijk gebruikten voor benchmarking, hebben we besloten om deze kortstondige schijven te gebruiken.
- Als u EBS gebruikt, zorg er dan voor dat u de juiste ingerichte IOPS kiest. Een te lage waarde veroorzaakt een zeer trage IO, maar een zeer hoge waarde kan uw AWS-factuur aanzienlijk verhogen, vooral wanneer u te maken hebt met een groot aantal knooppunten.
- Zorg ervoor dat u de instanties in dezelfde zone start om de latentie te verminderen en de doorvoer voor verbindingen ertussen te verbeteren.
- Zorg ervoor dat u instanties zo configureert dat ze een privénetwerk gebruiken om met elkaar te praten.
- Kijk naar spot-instanties. Ze zijn relatief goedkoper. Aangezien AWS spotinstanties naar believen kan beëindigen, bijvoorbeeld als de spotprijs hoger wordt dan uw maximale biedprijs, moet u daarop voorbereid zijn. Postgres-XL kan gedeeltelijk of volledig onbruikbaar worden, afhankelijk van welke nodes worden beëindigd. AWS ondersteunt een concept van launch_group. Als er meerdere instanties in dezelfde launch_group zijn gegroepeerd, als AWS besluit één instantie te beëindigen, worden alle instanties beëindigd.
5. Conclusie
We kunnen door middel van verschillende benchmarks laten zien dat Postgres-XL heel goed kan schalen voor een groot aantal echte, complexe zoekopdrachten. Deze benchmarks helpen ons de mogelijkheden van Postgres-XL als een effectieve oplossing voor OLAP-workloads aan te tonen. Onze experimenten laten ook zien dat er enkele prestatieproblemen zijn met Postgres-XL, vooral voor zeer grote clusters en wanneer de planner een slechte keuze maakt voor een plan. We hebben ook waargenomen dat wanneer er een zeer groot aantal gelijktijdige verbindingen met een datanode is, de prestaties verslechteren. We zullen blijven werken aan deze prestatieproblemen. We willen ook de mogelijkheden van Postgres-XL als OLTP-oplossing testen door de juiste workloads te gebruiken.