Ansible is gewoon geweldig en PostgreSQL is zeker geweldig, laten we eens kijken hoe ze verbazingwekkend samenwerken!

====================Prime time aankondiging! ====================
PGConf Europe 2015 vindt dit jaar plaats op 27-30 oktober in Wenen.
Ik neem aan dat je mogelijk geïnteresseerd bent in configuratiebeheer, serverorkestratie, geautomatiseerde implementatie (daarom lees je deze blogpost, toch?) en je vindt het leuk om te werken met PostgreSQL (zeker) op AWS (optioneel), dan wil je misschien deelnemen aan mijn lezing "PostgreSQL beheren met Ansible" op 28 oktober, 15-15:50.
Bekijk het geweldige programma en mis de kans niet om het grootste PostgreSQL-evenement van Europa bij te wonen!
Ik hoop je daar te zien, ja ik drink graag koffie na gesprekken 🙂
====================Prime time aankondiging! ====================
Wat is Ansible en hoe werkt het?
Het motto van Ansible is "simple, agentless en krachtige open source IT-automatisering ” door te citeren uit Ansible-documenten.
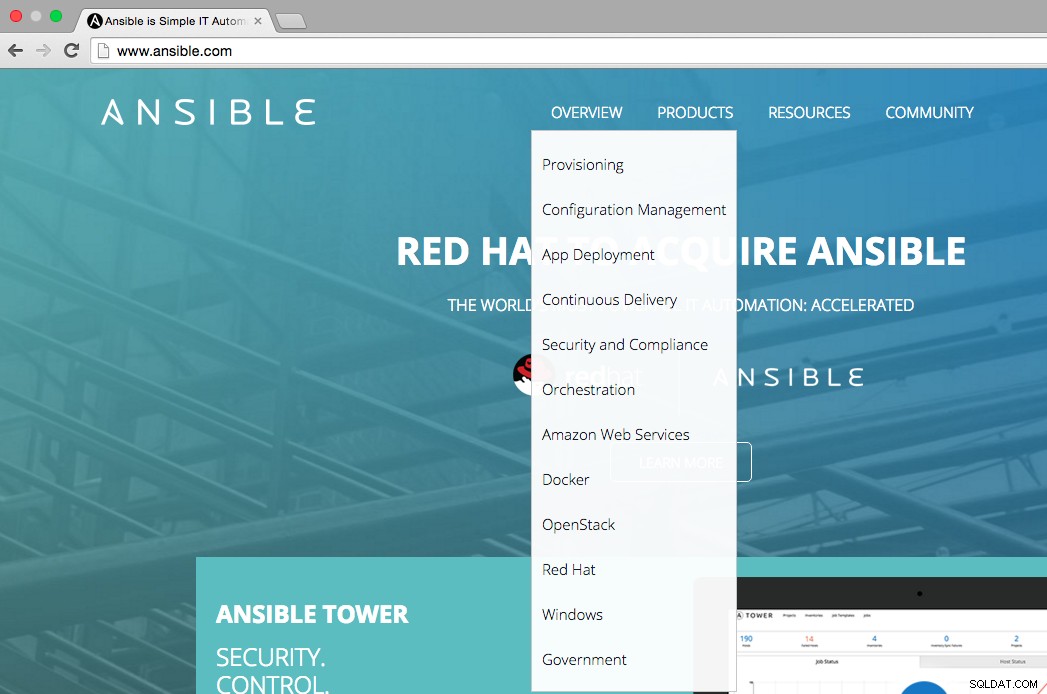
Zoals te zien is in de onderstaande afbeelding, vermeldt de startpagina van Ansible dat de belangrijkste gebruiksgebieden van Ansible zijn:provisioning, configuratiebeheer, app-implementatie, continue levering, beveiliging en compliance, orkestratie. Het overzichtsmenu laat ook zien op welke platforms we Ansible kunnen integreren, namelijk AWS, Docker, OpenStack, Red Hat, Windows.
Laten we de belangrijkste use-cases van Ansible eens bekijken om te begrijpen hoe het werkt en hoe nuttig het is voor IT-omgevingen.
Provisioning
Ansible is je trouwe vriend als je alles in je systeem wilt automatiseren. Het is agentless en u kunt eenvoudig uw zaken (d.w.z. servers, load balancers, switches, firewalls) via SSH beheren. Of uw systemen nu op bare-metal of cloudservers draaien, Ansible zal er zijn en u helpen bij het inrichten van uw instances. Zijn idempotente eigenschappen zorgen ervoor dat je altijd in de staat zult zijn die je wenst (en verwachtte) te zijn.
Configuratiebeheer
Een van de moeilijkste dingen is om jezelf niet te herhalen in repetitieve operationele taken en hier komt Ansible weer voor de geest als een redder. In de goede oude tijd, toen de tijden slecht waren, schreven systeembeheerders veel scripts en maakten ze verbinding met veel servers om ze toe te passen en het was duidelijk niet het beste in hun leven. Zoals we allemaal weten zijn handmatige taken foutgevoelig en leiden ze tot een heterogene omgeving in plaats van een homogene en beter beheersbare omgeving, wat ons leven zeker stressvoller maakt.
Met Ansible kun je eenvoudige playbooks schrijven (met behulp van zeer informatieve documentatie en de steun van de enorme gemeenschap) en als je eenmaal je taken hebt geschreven, kun je een breed scala aan modules aanroepen (bijv. AWS, Nagios, PostgreSQL, SSH, APT, File modulen). Hierdoor kunt u zich concentreren op creatievere activiteiten dan handmatig configuraties beheren.
App-implementatie
Als de artefacten gereed zijn, is het supereenvoudig om ze op een aantal servers te implementeren. Aangezien Ansible via SSH communiceert, is het niet nodig om uit een repository op elke server te halen of gedoe met oude methoden zoals het kopiëren van bestanden via FTP. Ansible kan artefacten synchroniseren en ervoor zorgen dat alleen nieuwe of bijgewerkte bestanden worden overgedragen en verouderde bestanden worden verwijderd. Dit versnelt ook de bestandsoverdracht en bespaart veel bandbreedte.
Naast het overzetten van bestanden helpt Ansible ook bij het productieklaar maken van servers. Voorafgaand aan de overdracht kan het de bewaking pauzeren, servers van load balancers verwijderen en services stoppen. Na de implementatie kan het services starten, servers toevoegen aan load balancers en de monitoring hervatten.
Dit hoeft niet allemaal tegelijk voor alle servers te gebeuren. Ansible kan op een subset van servers tegelijk werken om implementaties zonder downtime te bieden. Het kan bijvoorbeeld in één keer 5 servers tegelijk inzetten en vervolgens naar de volgende 5 servers wanneer ze klaar zijn.
Nadat dit scenario is geïmplementeerd, kan het overal worden uitgevoerd. Ontwikkelaars of leden van het QA-team kunnen implementaties op hun eigen machines uitvoeren voor testdoeleinden. Om een implementatie om welke reden dan ook terug te draaien, is alle Ansible-behoefte de locatie van de laatst bekende werkende artefacten. Het kan ze vervolgens gemakkelijk opnieuw implementeren op productieservers om het systeem weer in een stabiele staat te brengen.
Continue levering
Continue levering betekent een snelle en eenvoudige aanpak voor releases. Om dat doel te bereiken, is het cruciaal om de beste tools te gebruiken die frequente releases mogelijk maken zonder downtime en die zo min mogelijk menselijke tussenkomst vereisen. Omdat we hierboven hebben geleerd over de toepassingsmogelijkheden van Ansible, is het vrij eenvoudig om implementaties uit te voeren zonder downtime. De andere vereiste voor continue levering is minder handmatige processen en dat betekent automatisering. Ansible kan elke taak automatiseren, van het inrichten van servers tot het configureren van services om productieklaar te worden. Na het maken en testen van scenario's in Ansible, wordt het triviaal om ze voor een continu integratiesysteem te plaatsen en Ansible zijn werk te laten doen.
Beveiliging en naleving
Beveiliging wordt altijd als het belangrijkste beschouwd, maar systemen veilig houden is een van de moeilijkste dingen om te bereiken. U moet zeker zijn van de beveiliging van uw gegevens en van de gegevens van uw klant. Om zeker te zijn van de beveiliging van uw systemen, is het definiëren van beveiliging niet voldoende. U moet die beveiliging kunnen toepassen en uw systemen voortdurend controleren om ervoor te zorgen dat ze voldoen aan die beveiliging.
Ansible is gebruiksvriendelijk, of het nu gaat om het instellen van firewallregels, het vergrendelen van gebruikers en groepen of het toepassen van aangepast beveiligingsbeleid. Het is van nature veilig omdat u dezelfde configuratie herhaaldelijk kunt toepassen en het zal alleen de noodzakelijke wijzigingen aanbrengen om het systeem weer in overeenstemming te brengen.
Orkestratie
Ansible zorgt ervoor dat alle gegeven taken in de juiste volgorde staan en zorgt voor een harmonie tussen alle middelen die het beheert. Het orkestreren van complexe multi-tier implementaties is eenvoudiger met de configuratiebeheer- en implementatiemogelijkheden van Ansible. Als we bijvoorbeeld kijken naar de implementatie van een softwarestack, zijn zorgen zoals ervoor zorgen dat alle databaseservers gereed zijn voordat applicatieservers worden geactiveerd of het netwerk configureren voordat servers aan de load balancer worden toegevoegd, geen ingewikkelde problemen meer.
Ansible helpt ook bij het orkestreren van andere orkestratietools zoals Amazon's CloudFormation, OpenStack's Heat, Docker's Swarm, enz. Op deze manier, in plaats van verschillende platforms, talen en regels te leren; gebruikers kunnen zich alleen concentreren op de YAML-syntaxis en krachtige modules van Ansible.
Wat is een Ansible-module?
Modules of modulebibliotheken bieden Ansible-middelen om bronnen op lokale of externe servers te controleren of te beheren. Ze vervullen verschillende functies. Een module kan bijvoorbeeld verantwoordelijk zijn voor het herstarten van een machine of het kan gewoon een bericht op het scherm weergeven.
Ansible stelt gebruikers in staat om hun eigen modules te schrijven en biedt ook kant-en-klare kern- of extra's-modules.
Hoe zit het met Ansible-playbooks?
Met Ansible kunnen we ons werk op verschillende manieren organiseren. In de meest directe vorm kunnen we met Ansible-modules werken met behulp van de "ansible ” opdrachtregeltool en het inventarisbestand.
Inventaris
Een van de belangrijkste concepten is de inventaris . We hebben een inventarisatiebestand nodig om Ansible te laten weten welke servers het nodig heeft om verbinding te maken via SSH, welke verbindingsinformatie het nodig heeft en optioneel welke variabelen aan die servers zijn gekoppeld.
Het inventarisbestand heeft een INI-achtig formaat. In het inventarisbestand kunnen we meer dan één hosts specificeren en deze onder meer dan één hostgroepen groeperen.
Ons voorbeeldbestand hosts.ini ziet er als volgt uit:
[dbservers]
db.example.com
Hier hebben we een enkele host genaamd "db.example.com" in een hostgroep genaamd "dbservers". In het inventarisbestand kunnen we ook aangepaste SSH-poorten, SSH-gebruikersnamen, SSH-sleutels, proxy-informatie, variabelen, enz. opnemen.
Aangezien we een inventarisbestand gereed hebben, kunnen we, om de uptime van onze databaseservers te zien, het "commando van Ansible aanroepen ”-module en voer de “uptime . uit ” commando op die servers:
ansible dbservers -i hosts.ini -m command -a "uptime"
Hier hebben we Ansible geïnstrueerd om hosts uit het hosts.ini-bestand te lezen, ze te verbinden met SSH, de "uptime uit te voeren ” op elk van hen en druk vervolgens hun uitvoer af op het scherm. Dit type module-uitvoering wordt een ad-hocopdracht genoemd .
De uitvoer van het commando is als volgt:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Als onze oplossing echter meer dan één stap bevat, wordt het moeilijk om deze alleen te beheren met behulp van ad-hocopdrachten.
Hier komen Ansible-playbooks. Het stelt ons in staat om onze oplossing te organiseren in een playbook-bestand door alle stappen te integreren door middel van taken, variabelen, rollen, sjablonen, handlers en een inventaris.
Laten we een paar van deze termen kort bekijken om te begrijpen hoe ze ons kunnen helpen.
Taken
Een ander belangrijk concept zijn taken. Elke Ansible-taak bevat een naam, een aan te roepen module, moduleparameters en optioneel pre-/postvoorwaarden. Ze stellen ons in staat om Ansible-modules aan te roepen en informatie door te geven aan opeenvolgende taken.
Variabelen
Er zijn ook variabelen. Ze zijn erg handig voor het hergebruiken van informatie die we hebben verstrekt of verzameld. We kunnen ze definiëren in de inventaris, in externe YAML-bestanden of in playbooks.
Playbook
Ansible-playbooks worden geschreven met behulp van de YAML-syntaxis. Het kan meer dan één toneelstuk bevatten. Elk stuk bevat de naam van de hostgroepen waarmee verbinding moet worden gemaakt en de taken die het moet uitvoeren. Het kan ook variabelen/rollen/handlers bevatten, indien gedefinieerd.
Nu kunnen we een heel eenvoudig draaiboek bekijken om te zien hoe het kan worden gestructureerd:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeIn dit zeer eenvoudige playbook vertelden we Ansible dat het zou moeten werken op servers die zijn gedefinieerd in de hostgroep "dbservers". We hebben een variabele gemaakt met de naam "wie" en vervolgens hebben we onze taken gedefinieerd. Merk op dat we bij de eerste taak waarbij we een foutopsporingsbericht afdrukken, de variabele "who" gebruikten en ervoor zorgden dat Ansible "Hello World" op het scherm afdrukte. In de tweede taak vertelden we Ansible om verbinding te maken met elke host en vervolgens de "uptime" -opdracht daar uit te voeren.
Ansible PostgreSQL-modules
Ansible levert een aantal modules voor PostgreSQL. Sommige bevinden zich onder kernmodules, terwijl andere te vinden zijn onder extra modules.
Alle PostgreSQL-modules vereisen dat het Python psycopg2-pakket op dezelfde machine met de PostgreSQL-server wordt geïnstalleerd. Psycopg2 is een PostgreSQL-databaseadapter in de programmeertaal Python.
Op Debian/Ubuntu-systemen kan het psycopg2-pakket worden geïnstalleerd met de volgende opdracht:
apt-get install python-psycopg2
Nu gaan we deze modules in detail bekijken. We zullen bijvoorbeeld werken aan een PostgreSQL-server op host db.example.com op poort 5432 met postgres gebruiker en een leeg wachtwoord.
postgresql_db
Deze kernmodule maakt of verwijdert een bepaalde PostgreSQL-database. In Ansible-terminologie zorgt het ervoor dat een bepaalde PostgreSQL-database aanwezig of afwezig is.
De belangrijkste optie is de vereiste parameter “naam ”. Het vertegenwoordigt de naam van de database in een PostgreSQL-server. Een andere belangrijke parameter is “state ”. Het vereist een van de twee waarden:present of afwezig . Dit stelt ons in staat om een database aan te maken of te verwijderen die wordt geïdentificeerd door de waarde gegeven in de naam parameter.
Sommige workflows vereisen mogelijk ook specificatie van verbindingsparameters zoals login_host , poort , login_user , en login_password .
Laten we een database maken met de naam "module_test ” op onze PostgreSQL-server door onderstaande regels toe te voegen aan ons playbook-bestand:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Hier hebben we verbinding gemaakt met onze testdatabaseserver op db.example.com met de gebruiker; postgres . Het hoeft echter niet de postgres . te zijn gebruiker als gebruikersnaam kan van alles zijn.
Het verwijderen van de database is net zo eenvoudig als het maken ervan:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Let op de waarde "afwezig" in de parameter "status".
postgresql_ext
Van PostgreSQL is bekend dat het zeer nuttige en krachtige extensies heeft. Een recente extensie is bijvoorbeeld tsm_system_rows wat helpt bij het ophalen van het exacte aantal rijen in tabellensteekproeven. (Voor meer informatie kun je mijn vorige bericht over tableampling-methoden bekijken.)
Deze extras-module voegt PostgreSQL-extensies toe aan of verwijdert ze uit een database. Het vereist twee verplichte parameters:db en naam . De db parameter verwijst naar de databasenaam en de naam parameter verwijst naar de extensienaam. We hebben ook de staat parameter die aanwezig . nodig heeft of afwezig waarden en dezelfde verbindingsparameters als in de postgresql_db-module.
Laten we beginnen met het maken van de extensie waar we het over hadden:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Met deze kernmodule kunnen gebruikers en rollen worden toegevoegd aan of verwijderd uit een PostgreSQL-database.
Het is een zeer krachtige module omdat het ervoor zorgt dat een gebruiker aanwezig is in de database, maar het tegelijkertijd ook mogelijk maakt om privileges of rollen te wijzigen.
Laten we beginnen met naar de parameters te kijken. De enige verplichte parameter hier is "name ”, wat verwijst naar een gebruiker of een rolnaam. Ook, zoals in de meeste Ansible-modules, is de “state ” parameter is belangrijk. Het kan een van aanwezige . hebben of afwezig waarden en de standaardwaarde is aanwezig .
Naast verbindingsparameters zoals in eerdere modules, zijn enkele andere belangrijke optionele parameters:
- db :Naam van de database waar toestemmingen worden verleend
- wachtwoord :Wachtwoord van de gebruiker
- priv :Rechten in “priv1/priv2” of tabelrechten in “table:priv1,priv2,…” formaat
- role_attr_flags :Rolattributen. Mogelijke waarden zijn:
- [NO]SUPERUSER
- [NO]CREATEROL
- [NO]SCHEPPER
- [NO]CREATEDB
- [NO]INHERIT
- [NO]LOGIN
- [NO]REPLICATIE
Om een nieuwe gebruiker met de naam ada . aan te maken met wachtwoord lovelace en een verbindingsprivilege voor de database module_test , kunnen we het volgende aan ons playbook toevoegen:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Nu we de gebruiker klaar hebben, kunnen we haar enkele rollen toewijzen. Om "ada" toe te staan om in te loggen en databases aan te maken:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
We kunnen ook globale of op tabellen gebaseerde privileges verlenen, zoals "INSERT ”, “UPDATE ”, “SELECTEER ”, en “VERWIJDEREN ” met de priv parameter. Een belangrijk punt om te overwegen is dat een gebruiker niet kan worden verwijderd totdat alle verleende rechten eerst zijn ingetrokken.
postgresql_privs
Deze kernmodule verleent of trekt privileges in op PostgreSQL-databaseobjecten. Ondersteunde objecten zijn:tabel , volgorde , functie , database , schema , taal , tabelruimte , en groep .
Vereiste parameters zijn "database"; naam van de database om rechten aan toe te kennen/in te trekken, en “rollen”; een door komma's gescheiden lijst met rolnamen.
De belangrijkste optionele parameters zijn:
- typ :Type van het object waarvoor u rechten wilt instellen. Kan een van de volgende zijn:tabel, volgorde, functie, database, schema, taal, tabelruimte, groep . Standaardwaarde is tabel .
- objs :Database-objecten om privileges in te stellen. Kan meerdere waarden hebben. In dat geval worden objecten gescheiden door een komma.
- privé :door komma's gescheiden lijst met rechten die kunnen worden verleend of ingetrokken. Mogelijke waarden zijn:ALLE , SELECTEER , UPDATE , INSERT .
Laten we eens kijken hoe dit werkt door alle privileges toe te kennen aan de "public ” schema naar “ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Een van de zeer krachtige functies van PostgreSQL is de ondersteuning voor vrijwel elke taal die als proceduretaal kan worden gebruikt. Deze extra module voegt proceduretalen toe, verwijdert of wijzigt ze met een PostgreSQL-database.
De enige verplichte parameter is "lang ”; naam van de proceduretaal die moet worden toegevoegd of verwijderd. Andere belangrijke opties zijn "db ”; naam van de database waaraan de taal is toegevoegd of waaruit de taal is verwijderd, en “vertrouwen ”; optie om de taal vertrouwd of niet vertrouwd te maken voor de geselecteerde database.
Laten we de PL/Python-taal voor onze database inschakelen:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Alles samenvoegen
Nu we weten hoe een Ansible-playbook is gestructureerd en welke PostgreSQL-modules voor ons beschikbaar zijn, kunnen we onze kennis nu combineren in een Ansible-playbook.
De uiteindelijke vorm van ons playbook main.yml is als volgt:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Nu kunnen we ons playbook uitvoeren met de opdracht "ansible-playbook":
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Je kunt de inventaris en het playbook-bestand vinden in mijn GitHub-repository die voor deze blogpost is gemaakt. Er is ook een ander playbook genaamd "remove.yml" dat alles ongedaan maakt wat we in het hoofdplaybook hebben gedaan.
Voor meer informatie over Ansible:
- Bekijk hun goedgeschreven documenten.
- Bekijk de Ansible-snelstartvideo wat een erg handige tutorial is.
- Volg hun webinar-schema, er staan een aantal coole aankomende webinars op de lijst.