TeamCity is een server voor continue integratie en continue levering, gebouwd in Java. Het is beschikbaar als cloudservice en on-premises. Zoals u zich kunt voorstellen, zijn tools voor continue integratie en levering cruciaal voor softwareontwikkeling en moet hun beschikbaarheid onaangetast blijven. Gelukkig kan TeamCity worden geïmplementeerd in een zeer beschikbare modus.
Deze blogpost gaat over het voorbereiden en implementeren van een maximaal beschikbare omgeving voor TeamCity.
Het milieu
TeamCity bestaat uit verschillende elementen. Er is een Java-toepassing en een database die er een back-up van maakt. Het maakt ook gebruik van agenten die communiceren met de primaire TeamCity-instantie. De implementatie met hoge beschikbaarheid bestaat uit verschillende TeamCity-instanties, waarbij de ene optreedt als de primaire en de andere als secundaire. Die instanties delen de toegang tot dezelfde database en de gegevensdirectory. Een handig schema is beschikbaar op de TeamCity-documentatiepagina, zoals hieronder weergegeven:

Zoals we kunnen zien, zijn er twee gedeelde elementen: de gegevensmap en de databank. We moeten ervoor zorgen dat die ook in hoge mate beschikbaar zijn. Er zijn verschillende opties die je kunt gebruiken om een gedeelde mount te bouwen; we zullen echter GlusterFS gebruiken. Wat de database betreft, we zullen een van de ondersteunde relationele databasebeheersystemen gebruiken:PostgreSQL, en we zullen ClusterControl gebruiken om er een hoge beschikbaarheidsstack omheen te bouwen.
GlusterFS configureren
Laten we beginnen met de basis. We willen hostnamen en /etc/hosts configureren op onze TeamCity-knooppunten, waar we ook GlusterFS zullen implementeren. Om dat te doen, moeten we de repository voor de nieuwste pakketten van GlusterFS op al deze pakketten instellen:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateDan kunnen we de GlusterFS op al onze TeamCity-knooppunten installeren:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS gebruikt poort 24007 voor connectiviteit tussen de nodes; we moeten ervoor zorgen dat het open en toegankelijk is voor alle knooppunten.
Zodra de connectiviteit aanwezig is, kunnen we een GlusterFS-cluster maken door vanaf één knooppunt te draaien:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Nu kunnen we testen hoe de status eruitziet:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Het lijkt erop dat alles in orde is en de connectiviteit is aanwezig.
Vervolgens moeten we een blokapparaat voorbereiden dat door GlusterFS kan worden gebruikt. Dit moet op alle knooppunten worden uitgevoerd. Maak eerst een partitie:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Formaat vervolgens die partitie:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Ten slotte moeten we op alle knooppunten een map maken die wordt gebruikt om de partitie aan te koppelen en fstab te bewerken om ervoor te zorgen dat deze bij het opstarten wordt aangekoppeld:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabLaten we nu controleren of dit werkt:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Nu kunnen we een van de knooppunten gebruiken om het GlusterFS-volume te maken en te starten:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successHoud er rekening mee dat we de waarde '3' gebruiken voor het aantal replica's. Dit betekent dat elk volume in drie exemplaren zal bestaan. In ons geval zal elke steen, elk /dev/sdb1-volume op alle knooppunten alle gegevens bevatten.
Zodra de volumes zijn gestart, kunnen we hun status verifiëren:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksZoals je kunt zien, ziet alles er goed uit. Wat belangrijk is, is dat GlusterFS poort 49152 heeft gekozen voor toegang tot dat volume, en we moeten ervoor zorgen dat het bereikbaar is op alle knooppunten waar we het gaan koppelen.
De volgende stap is het installeren van het GlusterFS-clientpakket. Voor dit voorbeeld moeten we het geïnstalleerd hebben op dezelfde nodes als de GlusterFS-server:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Vervolgens moeten we op alle knooppunten een directory maken die als gedeelde gegevensdirectory voor TeamCity kan worden gebruikt. Dit moet op alle knooppunten gebeuren:
example@sqldat.com:~# sudo mkdir /teamcity-storageKoppel als laatste het GlusterFS-volume op alle knooppunten:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageHiermee zijn de voorbereidingen voor gedeelde opslag voltooid.
Een zeer beschikbare PostgreSQL-cluster bouwen
Zodra de configuratie van de gedeelde opslag voor TeamCity is voltooid, kunnen we nu onze database-infrastructuur met hoge beschikbaarheid bouwen. TeamCity kan verschillende databases gebruiken; we zullen echter PostgreSQL gebruiken in deze blog. We gebruiken ClusterControl om de databaseomgeving te implementeren en vervolgens te beheren.
TeamCity's handleiding voor het bouwen van multi-node implementatie is nuttig, maar het lijkt de hoge beschikbaarheid van alles behalve TeamCity weg te laten. De handleiding van TeamCity suggereert een NFS- of SMB-server voor gegevensopslag, die op zichzelf geen redundantie heeft en een single point of failure zal worden. We hebben dit aangepakt door GlusterFS te gebruiken. Ze noemen een gedeelde database, aangezien een enkel databaseknooppunt uiteraard geen hoge beschikbaarheid biedt. We moeten een goede stapel bouwen:

In ons geval. het zal bestaan uit drie PostgreSQL-knooppunten, één primaire en twee replica's. We zullen HAProxy gebruiken als load balancer en Keepalive gebruiken om Virtual IP te beheren om een enkel eindpunt te bieden waarmee de applicatie verbinding kan maken. ClusterControl handelt fouten af door de replicatietopologie te bewaken en indien nodig vereist herstel uit te voeren, zoals het opnieuw starten van mislukte processen of een failover naar een van de replica's als het primaire knooppunt uitvalt.
Om te beginnen zullen we de databaseknooppunten implementeren. Houd er rekening mee dat ClusterControl SSH-connectiviteit vereist van het ClusterControl-knooppunt naar alle knooppunten die het beheert.

Vervolgens kiezen we een gebruiker die we gebruiken om verbinding te maken met de database, het wachtwoord en de PostgreSQL-versie om te implementeren:

Vervolgens gaan we definiëren welke knooppunten moeten worden gebruikt voor de implementatie van PostgreSQL :
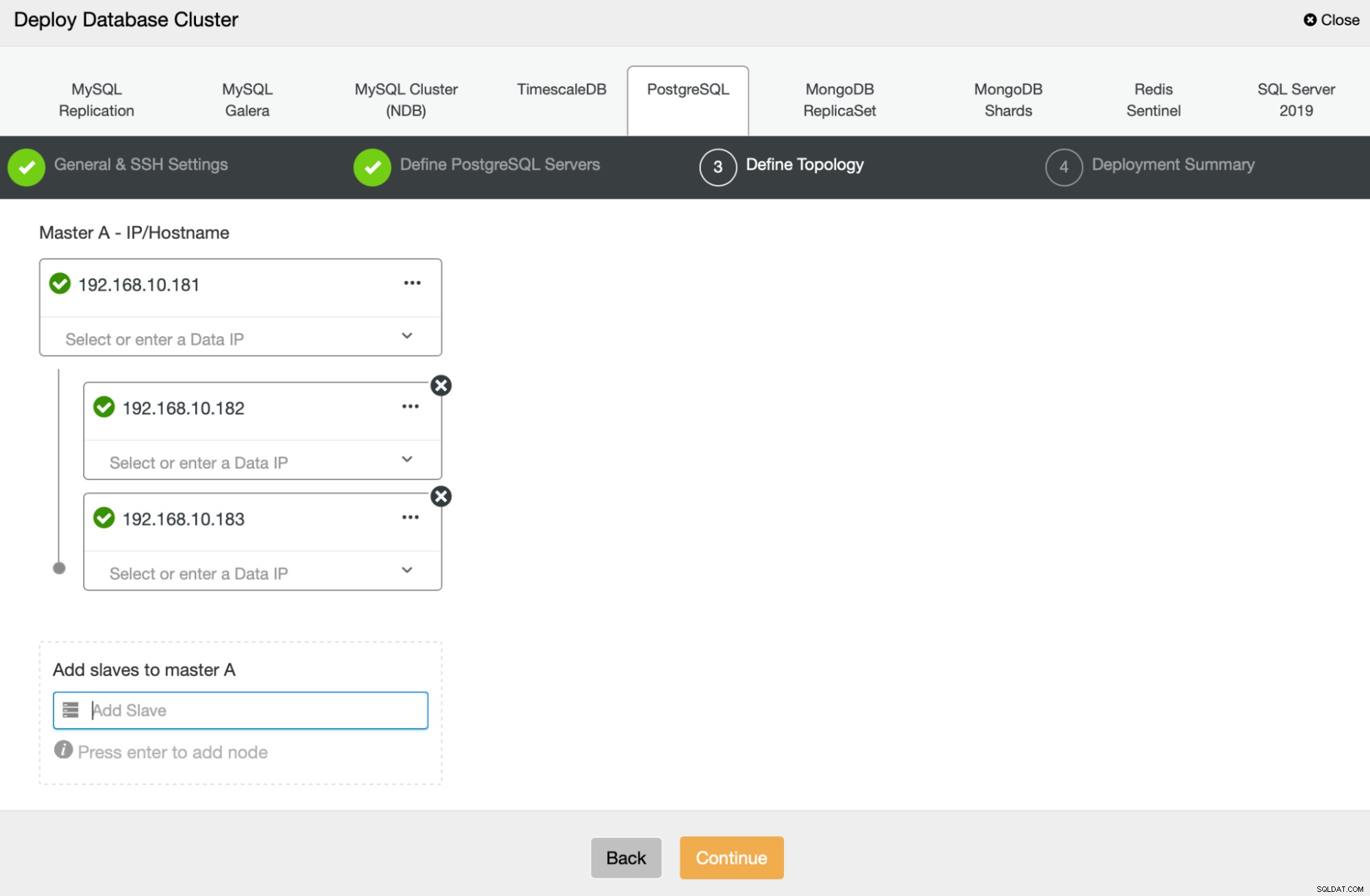
Ten slotte kunnen we bepalen of de knooppunten asynchrone of synchrone replicatie moeten gebruiken. Het belangrijkste verschil tussen deze twee is dat synchrone replicatie ervoor zorgt dat elke transactie die op het primaire knooppunt wordt uitgevoerd, altijd wordt gerepliceerd op de replica's. Synchrone replicatie vertraagt echter ook de vastlegging. We raden aan synchrone replicatie in te schakelen voor de beste duurzaamheid, maar u moet later controleren of de prestaties acceptabel zijn.

Nadat we op 'Implementeren' hebben geklikt, wordt er een implementatietaak gestart. We kunnen de voortgang volgen op het tabblad Activiteit in de gebruikersinterface van ClusterControl. We zouden uiteindelijk moeten zien dat de taak is voltooid en dat het cluster met succes is geïmplementeerd.

Implementeer HAProxy-instanties door naar Beheren -> Load balancers te gaan. Selecteer HAProxy als load balancer en vul het formulier in. De belangrijkste keuze is waar je HAProxy wilt inzetten. In dit geval hebben we een databaseknooppunt gebruikt, maar in een productieomgeving wilt u waarschijnlijk load balancers scheiden van database-instanties. Selecteer vervolgens welke PostgreSQL-knooppunten u wilt opnemen in HAProxy. We willen ze allemaal.

Nu zal de HAProxy-implementatie starten. We willen dit nog minstens één keer herhalen om twee HAProxy-instanties voor redundantie te maken. In deze implementatie hebben we besloten om te gaan met drie HAProxy-load balancers. Hieronder is een screenshot van het instellingenscherm tijdens het configureren van de implementatie van een tweede HAProxy:
Als al onze HAProxy-instanties actief zijn, kunnen we Keepalive inzetten . Het idee hier is dat Keepalive samen met HAProxy wordt geplaatst en het proces van HAProxy bewaakt. Aan een van de instanties met werkende HAProxy wordt een virtueel IP-adres toegewezen. Deze VIP moet door de toepassing worden gebruikt om verbinding te maken met de database. Keepalive zal detecteren of die HAProxy niet meer beschikbaar is en naar een andere beschikbare HAProxy-instantie gaan.
De implementatiewizard vereist dat we HAProxy-instanties doorgeven waarvan we willen dat Keepalived deze controleert. We moeten ook het IP-adres en de netwerkinterface doorgeven voor VIP.

De laatste en laatste stap is het maken van een database voor TeamCity:

Hiermee hebben we de implementatie van het zeer beschikbare PostgreSQL-cluster afgerond.
TeamCity implementeren als multi-node
De volgende stap is om TeamCity te implementeren in een omgeving met meerdere knooppunten. We gebruiken drie TeamCity-knooppunten. Eerst moeten we Java JRE en JDK installeren die voldoen aan de vereisten van TeamCity.
apt install default-jre default-jdkNu moeten we op alle nodes TeamCity downloaden. We zullen installeren in een lokale, niet gedeelde map.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzDan kunnen we TeamCity starten op een van de knooppunten:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logZodra TeamCity is gestart, hebben we toegang tot de gebruikersinterface en kunnen we beginnen met de implementatie. In eerste instantie moeten we de locatie van de gegevensmap doorgeven. Dit is het gedeelde volume dat we op GlusterFS hebben gemaakt.

Kies vervolgens de database. We gaan een PostgreSQL-cluster gebruiken die we al hebben gemaakt.

Download en installeer het JDBC-stuurprogramma:

Vul vervolgens de toegangsgegevens in. We gebruiken het virtuele IP-adres van Keepalive. Houd er rekening mee dat we poort 5433 gebruiken. Dit is de poort die wordt gebruikt voor de lees/schrijf-backend van HAProxy; het zal altijd naar het actieve primaire knooppunt wijzen. Kies vervolgens een gebruiker en de database om met TeamCity te gebruiken.

Zodra dit is gebeurd, begint TeamCity met het initialiseren van de databasestructuur.

Akkoord met de licentieovereenkomst:

Maak ten slotte een gebruiker voor TeamCity:

Dat is het! We zouden nu de TeamCity GUI moeten kunnen zien:

Nu moeten we TeamCity instellen in multi-node-modus. Eerst moeten we de opstartscripts op alle knooppunten bewerken:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shWe moeten ervoor zorgen dat de volgende twee variabelen worden geëxporteerd. Controleer of u de juiste hostnaam, IP en de juiste mappen gebruikt voor lokale en gedeelde opslag:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Zodra dit is gebeurd, kunt u de resterende knooppunten starten:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startU zou de volgende uitvoer moeten zien in Beheer -> Configuratie van knooppunten:één hoofdknooppunt en twee stand-byknooppunten.

Houd er rekening mee dat failover in TeamCity niet geautomatiseerd is. Als het hoofdknooppunt niet meer werkt, moet u verbinding maken met een van de secundaire knooppunten. Ga hiervoor naar 'Knooppuntconfiguratie' en promoot het naar het 'Hoofdknooppunt'. Op het inlogscherm ziet u een duidelijke indicatie dat dit een secundair knooppunt is:

In de "Nodes Configuration" ziet u dat de ene node verwijderd uit het cluster:

U ontvangt een bericht waarin staat dat u niet naar dit knooppunt kunt schrijven. Maak je geen zorgen; het schrijven dat nodig is om dit knooppunt naar de "hoofd"-status te promoveren, werkt prima:

Klik op "Inschakelen" en we hebben een secundair TimeCity-knooppunt gepromoot:

Als node1 beschikbaar komt en TeamCity opnieuw wordt gestart op dat knooppunt, zullen we zie hoe het zich weer bij het cluster voegt:

Als u de prestaties verder wilt verbeteren, kunt u HAProxy + Keepalive inzetten voor de TeamCity-gebruikersinterface om een enkel toegangspunt tot de GUI te bieden. Details over het configureren van HAProxy voor TeamCity vindt u in de documentatie.
Afronden
Zoals u kunt zien, is het implementeren van TeamCity voor hoge beschikbaarheid niet zo moeilijk - het meeste is grondig behandeld in de documentatie. Als u op zoek bent naar manieren om een deel hiervan te automatiseren en een database-backend met hoge beschikbaarheid toe te voegen, overweeg dan om ClusterControl 30 dagen gratis te evalueren. ClusterControl kan de backend snel implementeren en bewaken, en biedt geautomatiseerde failover, herstel, monitoring, back-upbeheer en meer.
Bekijk voor meer tips over tools voor softwareontwikkeling en best practices hoe u uw DevOps-team kunt ondersteunen bij hun databasebehoeften.
Voor het laatste nieuws en best practices voor het beheer van uw op open source gebaseerde database-infrastructuur, vergeet niet ons te volgen op Twitter of LinkedIn en u te abonneren op onze nieuwsbrief. Tot snel!