PostgreSQL, ook bekend als 's werelds meest geavanceerde open source-database, heeft een nieuwe releaseversie sinds 24 september 2020, en nu deze volwassen is, kunnen we controleren wat daar nieuw is om te beginnen na te denken over een migratieplan. PostgreSQL 13 is beschikbaar met veel nieuwe functies en verbeteringen. In deze blog zullen we enkele van deze nieuwe functies noemen en zien hoe u uw huidige PostgreSQL-versie kunt implementeren of upgraden.
Nieuwe functies en verbeteringen van PostgreSQL 13
Laten we beginnen met het noemen van enkele van de nieuwe functies en verbeteringen van deze PostgreSQL 13-versie die u kunt zien in de officiële documentatie.
Partitionering
-
Laat in meer gevallen snoeien van partities en partitiegewijze samenvoegingen toe
-
Ondersteuning op rijniveau VOORDAT triggers op gepartitioneerde tabellen
-
Laat gepartitioneerde tabellen logisch repliceren via publicatie
-
Logische replicatie toestaan naar gepartitioneerde tabellen op abonnees
-
Toestaan dat variabelen van hele rijen worden gebruikt bij het partitioneren van expressies
Indexen
-
Duplicaten efficiënter opslaan in B-tree-indexen
-
Sta GiST- en SP-GiST-indexen op boxkolommen toe om ORDER BY box <-> puntquery's te ondersteunen
-
Laat GIN-indexen efficiënter werken! (NOT)-clausules in tsquery-zoekopdrachten
-
Laat indexoperatorklassen parameters gebruiken
Optimizer
-
Verbeter de selectiviteitsschatting van de optimizer voor insluitings-/overeenkomstoperators
-
Instellen van het statistische doel voor uitgebreide statistieken toestaan
-
Gebruik van meerdere uitgebreide statistische objecten in één query toestaan
-
Gebruik van uitgebreide statistische objecten toestaan voor OR-clausules en IN/ANY constantenlijsten
-
Sta toe dat functies in FROM-clausules worden opgetrokken (inline) als ze evalueren naar constanten
Prestaties
-
Incrementeel sorteren implementeren en de prestaties van het sorteren van inet-waarden verbeteren
-
Sta hash-aggregatie toe om schijfopslag te gebruiken voor grote sets met aggregatieresultaten
-
Laat invoegingen, niet alleen updates en verwijderingen, toe om stofzuigactiviteit in autovacuüm te activeren
-
Voeg de parameter maintenance_io_concurrency toe om I/O-concurrency voor onderhoudsbewerkingen te regelen
-
Sta toe dat WAL-schrijfbewerkingen worden overgeslagen tijdens een transactie die een relatie maakt of herschrijft, als wal_level minimaal is
-
Verbeter de prestaties bij het opnieuw afspelen van DROP DATABASE-opdrachten wanneer er veel tabelruimten in gebruik zijn
-
Versnel conversies van gehele getallen naar tekst
-
Verminder geheugengebruik voor queryreeksen en extensiescripts die veel SQL-instructies bevatten
Bewaking
-
Sta EXPLAIN, auto_explain, autovacuum en pg_stat_statements toe om WAL-gebruiksstatistieken bij te houden
-
Toestaan dat een voorbeeld van SQL-instructies in plaats van alle instructies wordt vastgelegd
-
Voeg het backend-type toe aan csvlog en optioneel log_line_prefix log-uitvoer
-
Verbeter de controle over de logboekregistratie van voorbereide instructieparameters
-
Voeg leader_pid toe aan pg_stat_activity om het leidersproces van een parallelle werknemer te rapporteren
-
Voeg systeemweergave pg_stat_progress_basebackup toe om de voortgang van streaming-basisback-ups te rapporteren
-
Voeg systeemweergave pg_stat_progress_analyze toe om voortgang te rapporteren ANALYSEER
-
Voeg systeemweergave pg_shmem_allocations toe om het gebruik van gedeeld geheugen weer te geven
Replicatie en herstel
-
Sta toe dat configuratie-instellingen voor streaming-replicatie worden gewijzigd door opnieuw te laden
-
WAL-ontvangers toestaan een tijdelijke replicatiesleuf te gebruiken als er geen permanente is opgegeven
-
Laat WAL-opslag voor replicatieslots worden beperkt door max_slot_wal_keep_size
-
Stand-by-promotie toestaan om een aangevraagde pauze te annuleren
-
Genereer een fout als het herstel het opgegeven hersteldoel niet bereikt
-
Laat controle over hoeveel geheugen wordt gebruikt door logische decodering voordat het naar schijf wordt gemorst
-
Sta herstel toe om door te gaan, zelfs als er wordt verwezen naar ongeldige pagina's door WAL
Hulpprogramma's
-
Vacature toestaan om de indexen van een tabel parallel te verwerken
-
Buffergebruik tijdens de planning rapporteren in de BUFFER-uitvoer van EXPLAIN
-
Maak CREATE TABLE LIKE de eigenschap NO INHERIT van een CHECK-beperking naar de gemaakte tabel
-
AlTER TABLE toevoegen ... DROP EXPRESSION om de eigenschap GENERATED uit een kolom te verwijderen
-
Voeg ALTER VIEW-syntaxis toe om weergavekolommen te hernoemen
-
Voeg ALTER TYPE-opties toe om de TOAST-eigenschappen en ondersteuningsfuncties van een basistype te wijzigen
-
Optie CREATE DATABASE LOCALE toevoegen
-
Laat DROP DATABASE sessies verbreken met behulp van de doeldatabase, zodat de verwijdering kan slagen
En nog veel meer veranderingen. We hebben er zojuist een paar genoemd om een grotere blogpost te vermijden. Laten we nu eens kijken hoe we deze nieuwe versie kunnen implementeren.
PostgreSQL 13 implementeren
Hiervoor gaan we ervan uit dat u ClusterControl hebt geïnstalleerd, anders kunt u de bijbehorende documentatie volgen om het te installeren.
Als u een implementatie wilt uitvoeren vanuit ClusterControl, selecteert u gewoon de optie Deploy en volgt u de instructies die verschijnen.
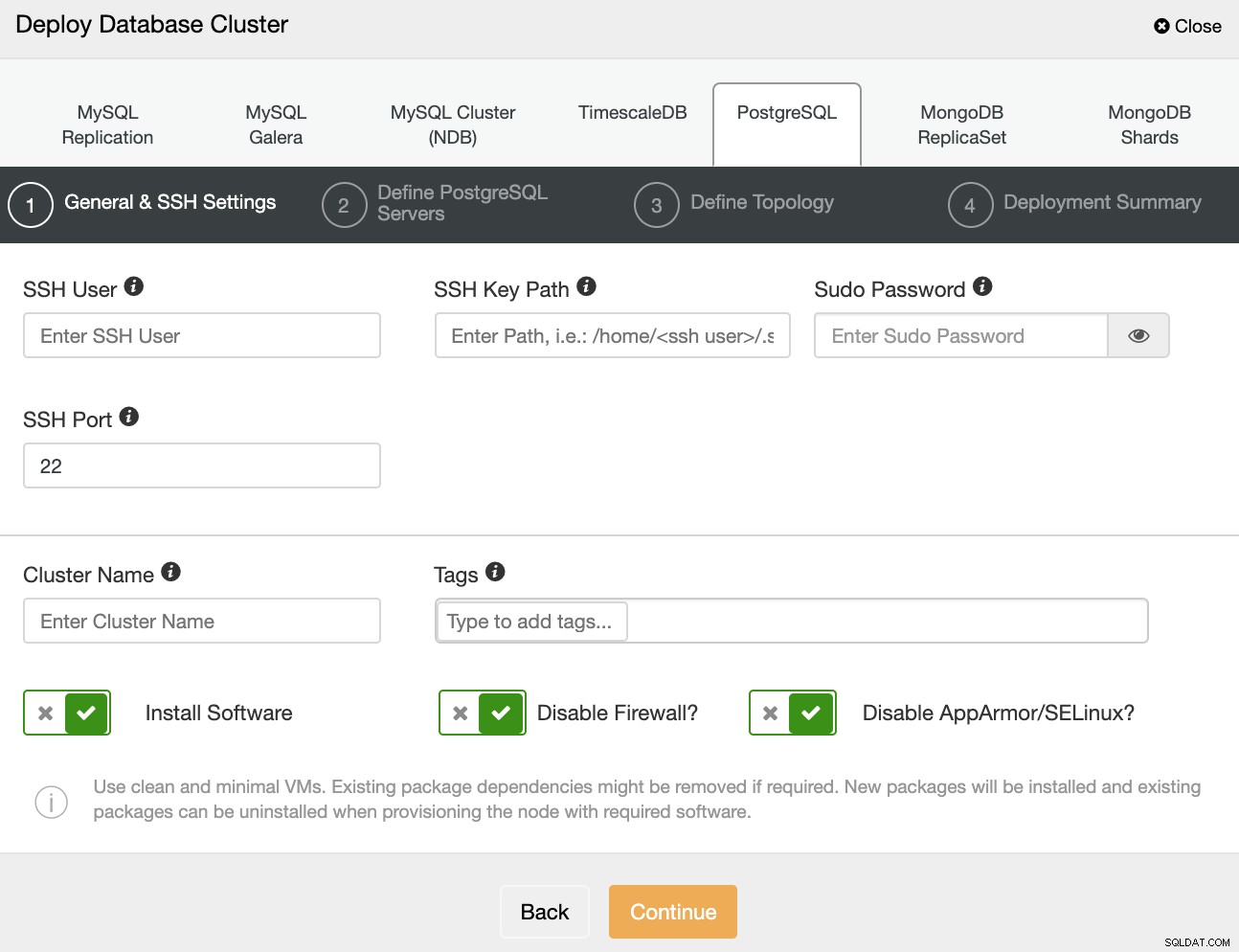
Als u PostgreSQL selecteert, moet u Gebruiker, Sleutel of Wachtwoord en Poort opgeven om via SSH verbinding te maken met uw servers. U kunt ook een naam voor uw nieuwe cluster toevoegen en als u wilt dat ClusterControl de bijbehorende software en configuraties voor u installeert.
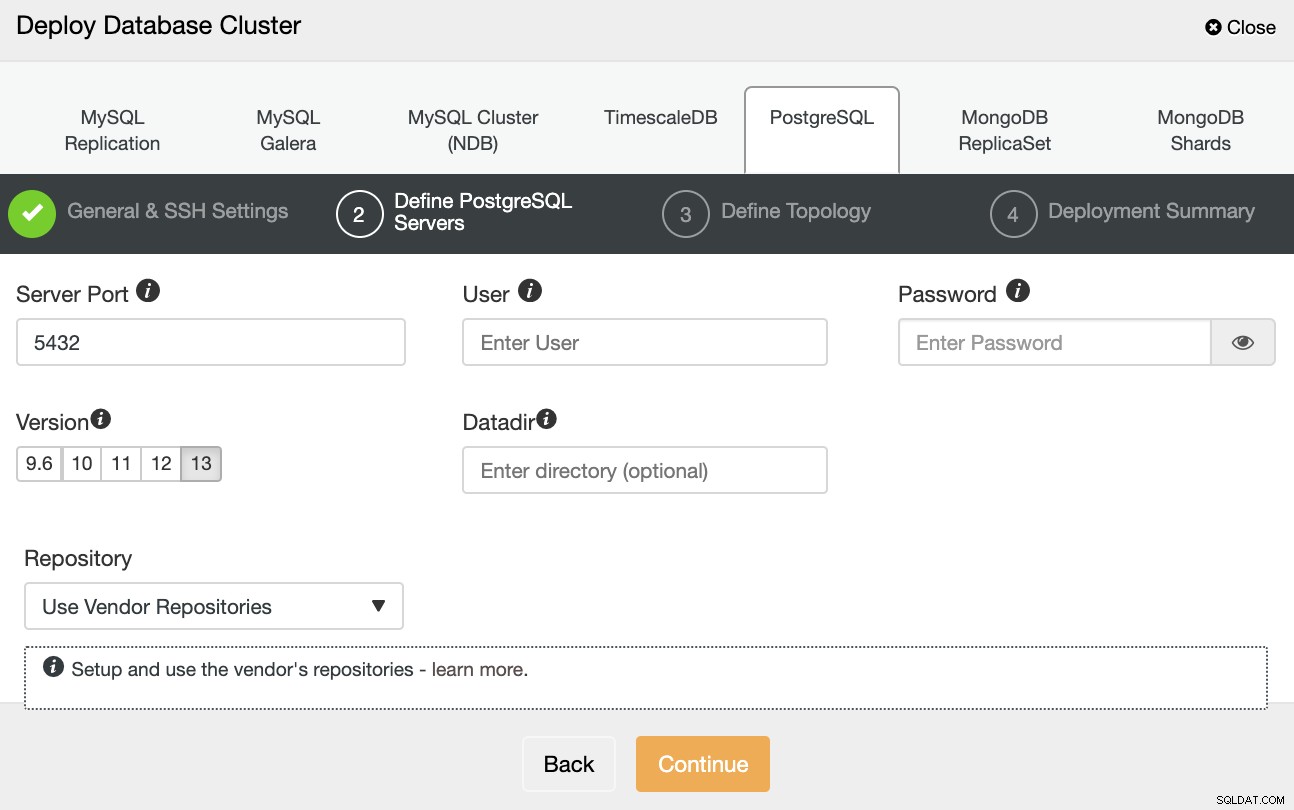
Na het instellen van de SSH-toegangsinformatie, moet u de databasereferenties definiëren , versie en datadir (optioneel). Je kunt ook aangeven welke repository je wilt gebruiken.
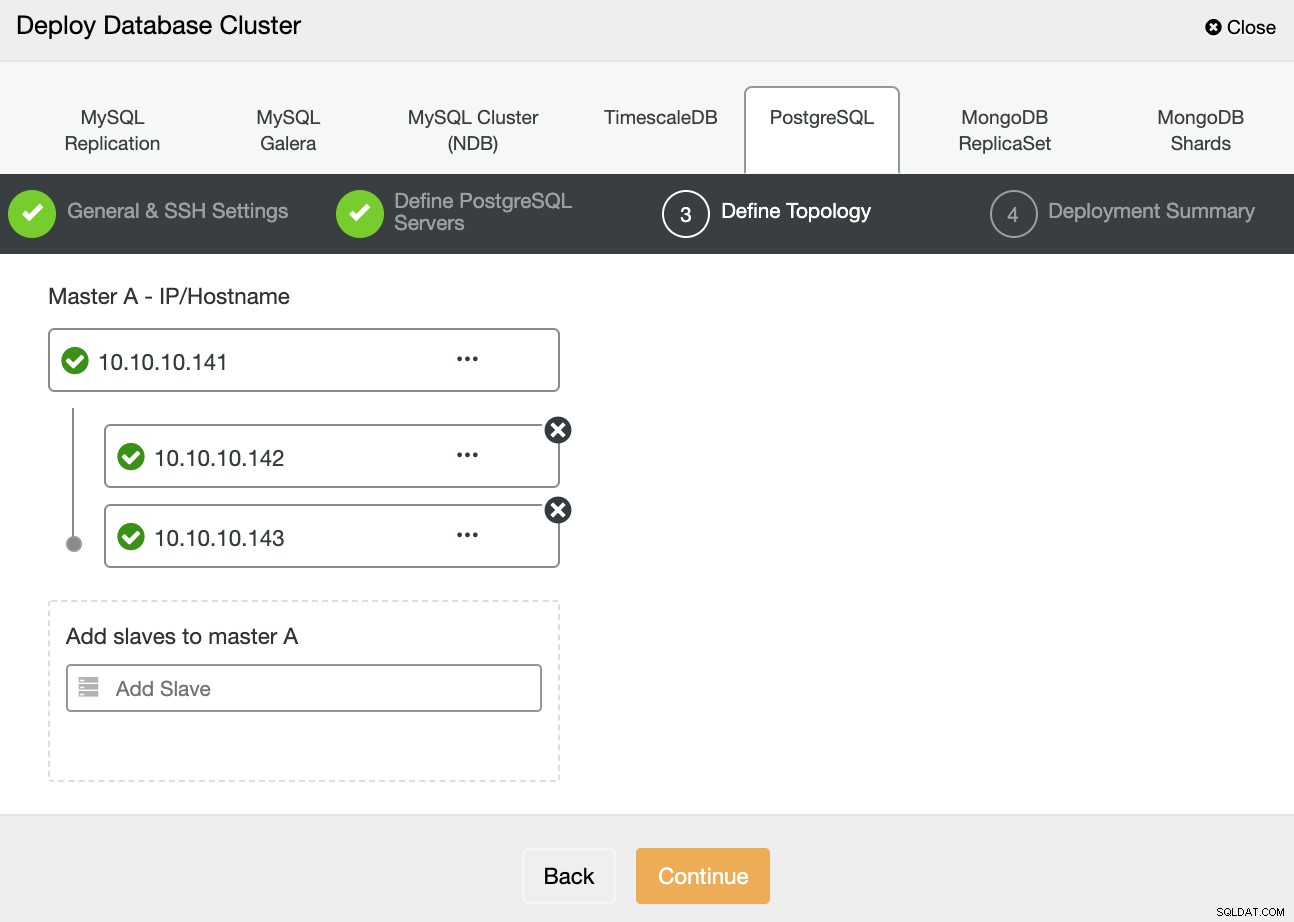
In de volgende stap moet u uw servers toevoegen aan het cluster dat u gaat maken met behulp van het IP-adres of de hostnaam.
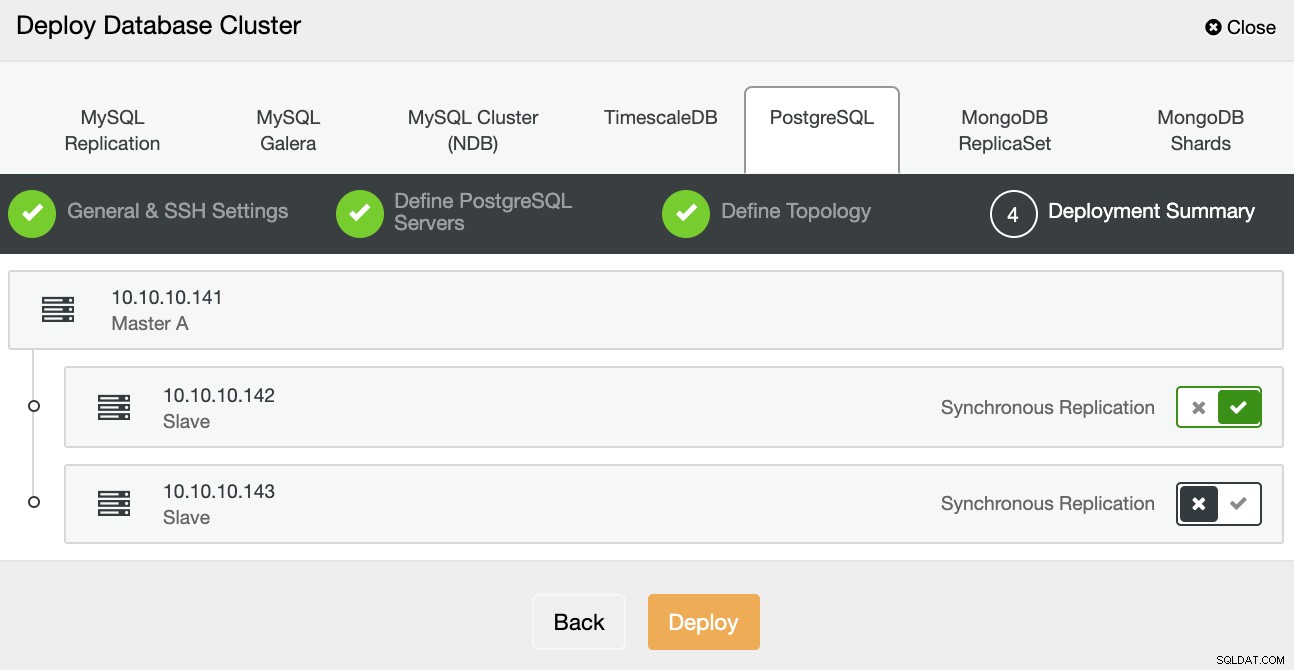
In de laatste stap kunt u kiezen of uw replicatie Synchroon of Asynchroon, en druk dan gewoon op Deploy.
Zodra de taak is voltooid, ziet u uw nieuwe PostgreSQL-cluster in de hoofdscherm van ClusterControl.

Nu je je cluster hebt gemaakt, kun je er verschillende taken op uitvoeren, zoals het toevoegen van load balancers (HAProxy), verbindingspoolers (PgBouncer) of nieuwe replicatieslaves van dezelfde ClusterControl-gebruikersinterface.
Upgraden naar PostgreSQL 13
Als u uw huidige PostgreSQL-versie naar deze nieuwe wilt upgraden, heeft u drie hoofdopties waarmee u deze taak kunt uitvoeren.
-
Pg_dump:het is een logische back-uptool waarmee u uw gegevens kunt dumpen en terugzetten in de nieuwe PostgreSQL versie. Hier heeft u een periode van uitvaltijd die zal variëren afhankelijk van uw gegevensomvang. U moet het systeem stoppen of nieuwe gegevens in het primaire knooppunt vermijden, de pg_dump uitvoeren, de gegenereerde dump naar het nieuwe databaseknooppunt verplaatsen en deze herstellen. Gedurende deze tijd kunt u niet in uw primaire PostgreSQL-database schrijven om inconsistentie van gegevens te voorkomen.
-
Pg_upgrade:het is een PostgreSQL-tool om je PostgreSQL-versie ter plekke te upgraden. In een productieomgeving kan het gevaarlijk zijn en in dat geval raden we deze methode niet aan. Als je deze methode gebruikt, heb je ook downtime, maar waarschijnlijk zal dit aanzienlijk minder zijn dan met de vorige pg_dump-methode.
-
Logische replicatie:sinds PostgreSQL 10 kunt u deze replicatiemethode gebruiken waarmee u belangrijke versie-upgrades kunt uitvoeren met nul (of bijna nul) uitvaltijd. Op deze manier kunt u een standby-knooppunt toevoegen in de laatste PostgreSQL-versie, en wanneer de replicatie up-to-date is, kunt u een failoverproces uitvoeren om het nieuwe PostgreSQL-knooppunt te promoten.
Raadpleeg de officiële documentatie voor meer gedetailleerde informatie over de nieuwe PostgreSQL 13-functies.