Geheugenbeheer in PostgreSQL is belangrijk voor het verbeteren van de prestaties van de databaseserver. Het PostgreSQL-configuratiebestand (postgres.conf) beheert de configuratie van de databaseserver. Het gebruikt standaardwaarden van de parameters, maar we kunnen deze waarden wijzigen om de werkbelasting en de besturingsomgeving beter weer te geven.
In deze blog behandelen we deze geheugengerelateerde parameters. Maar laten we, voordat we beginnen, eens kijken naar de geheugenarchitectuur in PostgreSQL.
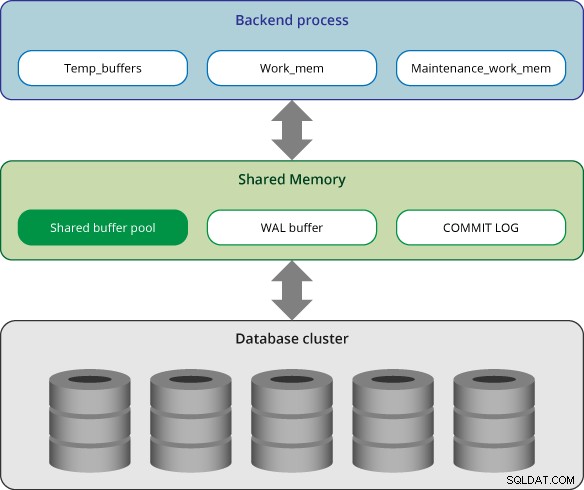
Geheugenarchitectuur
Geheugen in PostgreSQL kan in twee categorieën worden ingedeeld:
- Lokaal geheugengebied:het wordt door elk backend-proces voor eigen gebruik toegewezen.
- Gedeeld geheugengebied:het wordt gebruikt door alle processen van een PostgreSQL-server.
Lokaal geheugengebied
In PostgreSQL wijst elk backend-proces lokaal geheugen toe voor het verwerken van query's; elk gebied is verdeeld in subgebieden waarvan de grootte vast of variabel is.
De subgebieden zijn als volgt.
Work_mem
De uitvoerder gebruikt dit gebied voor het sorteren van tuples op ORDER BY en DISTINCT-bewerkingen. Het gebruikt het ook om tabellen samen te voegen door middel van merge-join en hash-join operaties.
Maintenance_work_mem
Deze parameter wordt gebruikt voor bepaalde soorten onderhoudswerkzaamheden (VACUUM, REINDEX).
Temp_buffers
De uitvoerder gebruikt dit gebied voor het opslaan van tijdelijke tabellen.
Gedeeld geheugengebied
Het gedeelde geheugengebied wordt bij het opstarten toegewezen door de PostgreSQL-server. Deze gebieden zijn onderverdeeld in verschillende subgebieden met een vaste grootte.
Gedeelde bufferpool
PostgreSQL laadt pagina's in tabellen en indexen van permanente opslag naar een gedeelde bufferpool en werkt er vervolgens rechtstreeks op.
WAL-buffer
PostgreSQL ondersteunt het WAL-mechanisme (Write ahead log) om ervoor te zorgen dat er geen gegevens verloren gaan na een serverstoring. WAL-gegevens zijn in feite een transactielogboek in PostgreSQL en WAL-buffer is een buffergebied van de WAL-gegevens voordat deze naar een permanente opslag worden geschreven.
Logboek vastleggen
Het commit log (CLOG) houdt de statussen van alle transacties bij en maakt deel uit van het gelijktijdigheidscontrolemechanisme. Het vastleggingslogboek wordt toegewezen aan het gedeelde geheugen en gebruikt tijdens de transactieverwerking.
PostgreSQL definieert de volgende vier transactiestatussen.
- IN_PROGRESS
- BETROKKEN
- AFGEBRACHT
- SUB-TOEVOEGD
PostgreSQL-geheugenparameters afstemmen
Er zijn enkele belangrijke parameters die worden aanbevolen voor geheugenbeheer in PostgreSQL. U dient rekening te houden met het volgende.
Gedeelde_buffers
Deze parameter geeft de hoeveelheid geheugen aan die wordt gebruikt voor gedeelde geheugenbuffers. De parameter shared_buffers bepaalt hoeveel geheugen aan de server wordt toegewezen voor het cachen van gegevens. De standaardwaarde van shared_buffers is doorgaans 128 megabyte (128 MB).
De standaardwaarde van deze parameter is erg laag omdat op sommige platforms, zoals oudere Solaris-versies en SGI, het hebben van grote waarden ingrijpende acties vereist, zoals het opnieuw compileren van de kernel. Zelfs op de moderne Linux-systemen zal de kernel waarschijnlijk niet toestaan dat shared_buffers worden ingesteld op meer dan 32 MB zonder eerst de kernelinstellingen aan te passen.
Het mechanisme is veranderd in PostgreSQL 9.4 en later, dus de kernelinstellingen hoeven daar niet te worden aangepast.
Als de databaseserver zwaar wordt belast, zal het instellen van een hoge waarde de prestaties verbeteren.
Als u een dedicated DB-server heeft met 1 GB of meer RAM, is een redelijke startwaarde voor de configuratieparameter shared_buffer 25% van het geheugen in uw systeem.
Standaardwaarde van shared_buffers =128 MB. De wijziging vereist herstart van de PostgreSQL-server.
De algemene aanbeveling om de shared_buffers in te stellen is als volgt.
- Stel bij minder dan 2 GB geheugen de waarde van shared_buffers in op 20% van het totale systeemgeheugen.
- Stel bij minder dan 32 GB geheugen de waarde van shared_buffers in op 25% van het totale systeemgeheugen.
- Stel boven 32 GB geheugen de waarde van shared_buffers in op 8 GB
Work_mem
Deze parameter specificeert de hoeveelheid geheugen die moet worden gebruikt door interne sorteerbewerkingen en hashtabellen voordat naar tijdelijke schijfbestanden wordt geschreven. Als er veel complexe sorteringen plaatsvinden en u voldoende geheugen hebt, kunt u door de parameter work_mem te verhogen, PostgreSQL in staat stellen grotere sorteringen in het geheugen uit te voeren die sneller zijn dan op schijf gebaseerde equivalenten.
Houd er rekening mee dat voor een complexe query veel sorteer- of hash-bewerkingen parallel kunnen worden uitgevoerd. Elke bewerking mag zoveel geheugen gebruiken als deze waarde aangeeft voordat er gegevens naar de tijdelijke bestanden worden geschreven. Er is een mogelijkheid dat meerdere sessies dergelijke bewerkingen tegelijkertijd kunnen uitvoeren. Daarom kan het totale gebruikte geheugen vele malen groter zijn dan de waarde van de parameter work_mem.
Houd daar rekening mee bij het kiezen van de juiste waarde. Sorteerbewerkingen worden gebruikt voor ORDER BY, DISTINCT en merge joins. Hash-tabellen worden gebruikt in hash-joins, hash-gebaseerde verwerking van IN-subquery's en hash-gebaseerde aggregatie.
De parameter log_temp_files kan worden gebruikt om sorteringen, hashes en tijdelijke bestanden te loggen, wat handig kan zijn om uit te zoeken of sorteringen naar de schijf worden gemorst in plaats van in het geheugen te passen. U kunt de sortering controleren die op schijf terechtkomt met behulp van EXPLAIN ANALYZE-plannen. Als u bijvoorbeeld in de uitvoer van EXPLAIN ANALYZE de regel ziet zoals:"Sorteermethode:externe samenvoeging Schijf:7528kB ”, een work_mem van ten minste 8 MB zou de tussenliggende gegevens in het geheugen houden en de reactietijd van de query verbeteren.
De standaardwaarde van work_mem =4 MB.
De algemene aanbeveling om de work_mem in te stellen is als volgt.
- Begin met lage waarde:32-64 MB
- Zoek vervolgens naar regels voor 'tijdelijk bestand' in logbestanden
- Stel in op 2-3 keer het grootste tijdelijke bestand
onderhoud _work_mem
Deze parameter specificeert de maximale hoeveelheid geheugen die wordt gebruikt door onderhoudsbewerkingen zoals VACUUM, CREATE INDEX en ALTER TABLE ADD FOREIGN KEY. Aangezien slechts één van deze bewerkingen tegelijk kan worden uitgevoerd door een databasesessie en een PostgreSQL-installatie er niet veel tegelijk heeft, is het veilig om de waarde van maintenance_work_mem aanzienlijk groter in te stellen dan work_mem.
Het instellen van de grotere waarde kan de prestaties verbeteren voor het opzuigen en herstellen van databasedumps.
Het is noodzakelijk om te onthouden dat wanneer autovacuum wordt uitgevoerd, tot autovacuum_max_workers keer dit geheugen kan worden toegewezen, dus pas op dat u de standaardwaarde niet te hoog instelt.
De standaardwaarde van maintenance_work_mem =64 MB.
De algemene aanbeveling om maintenance_work_mem in te stellen is als volgt.
- Stel de waarde 10% van het systeemgeheugen in, tot 1 GB
- Misschien kun je het nog hoger instellen als je VACUM-problemen hebt
Effective_cache_size
De effectieve_cache_grootte moet worden ingesteld op een schatting van hoeveel geheugen beschikbaar is voor schijfcaching door het besturingssysteem en binnen de database zelf. Dit is een richtlijn voor hoeveel geheugen u verwacht beschikbaar te hebben in het besturingssysteem en de PostgreSQL-buffercaches, geen toewijzing.
PostgreSQL-queryplanner gebruikt deze waarde om erachter te komen of de plannen die het overweegt, naar verwachting in het RAM passen of niet. Als het te laag is ingesteld, worden indexen mogelijk niet gebruikt voor het uitvoeren van query's zoals u zou verwachten. Aangezien de meeste Unix-systemen behoorlijk agressief zijn bij het cachen, zal ten minste 50% van het beschikbare RAM-geheugen op een speciale databaseserver vol gegevens in de cache zitten.
Algemene aanbeveling voor effectieve_cache_size is als volgt.
- Stel de waarde in op de hoeveelheid beschikbare cache van het bestandssysteem
- Als u het niet weet, stelt u de waarde in op 50% van het totale systeemgeheugen
De standaardwaarde van Effective_cache_size =4GB.
Temp_buffers
Deze parameter stelt het maximum aantal tijdelijke buffers in dat door elke databasesessie wordt gebruikt. De lokale sessiebuffers worden alleen gebruikt voor toegang tot tijdelijke tabellen. De instelling van deze parameter kan worden gewijzigd binnen individuele sessies, maar alleen vóór het eerste gebruik van tijdelijke tabellen binnen de sessie.
De PostgreSQL-database gebruikt dit geheugengebied voor het bewaren van de tijdelijke tabellen van elke sessie, deze worden gewist wanneer de verbinding wordt verbroken.
De standaardwaarde van temp_buffer =8 MB.
Conclusie
Het begrijpen van de geheugenarchitectuur en het afstemmen van de juiste parameters is belangrijk om de prestaties te verbeteren. Dit is vooral nodig voor systemen met een hoge werkbelasting. Raadpleeg deze spiekbrief voor prestaties voor PostgreSQL voor meer algemene tips voor het afstemmen van prestaties.