Kennis van replicatie is een must voor iedereen die databases beheert. Het is een onderwerp dat je vast wel eens vaker hebt gezien, maar dat nooit verveelt. In deze blog zullen we een klein beetje van de geschiedenis van de ingebouwde replicatiefuncties van PostgreSQL bekijken en dieper ingaan op hoe streamingreplicatie werkt.
Als we het over replicatie hebben, hebben we het veel over WAL's. Laten we dus snel een klein beetje over vooruitschrijven logboeken bekijken.
Write-Ahead Log (WAL)
Een vooruitschrijvend logboek is een standaardmethode om de gegevensintegriteit te waarborgen en wordt standaard automatisch ingeschakeld.
De WAL's zijn de REDO-logboeken in PostgreSQL. Maar wat zijn REDO-logboeken precies?
REDO-logboeken bevatten alle wijzigingen die in de database zijn aangebracht en worden gebruikt voor replicatie, herstel, online back-up en point-in-time recovery (PITR). Alle wijzigingen die niet zijn toegepast op de gegevenspagina's kunnen opnieuw worden gedaan vanuit de REDO-logboeken.
Het gebruik van WAL resulteert in een aanzienlijk verminderd aantal schijfschrijfbewerkingen, omdat alleen het logbestand naar schijf hoeft te worden gewist om te garanderen dat een transactie wordt doorgevoerd, in plaats van elk gegevensbestand dat door de transactie wordt gewijzigd.
P>Een WAL-record specificeert de wijzigingen die in de gegevens zijn aangebracht, beetje bij beetje. Elk WAL-record wordt toegevoegd aan een WAL-bestand. De invoegpositie is een Log Sequence Number (LSN), een byte-offset in de logs, die met elke nieuwe record toeneemt.
De WAL's worden opgeslagen in de map pg_wal (of pg_xlog in PostgreSQL-versies <10) onder de gegevensmap. Deze bestanden hebben een standaardgrootte van 16 MB (u kunt de grootte wijzigen door de --with-wal-segsize configure-optie te wijzigen bij het bouwen van de server). Ze hebben een unieke incrementele naam in het volgende formaat:"00000001 00000000 00000000".
Het aantal WAL-bestanden in pg_wal hangt af van de waarde die is toegewezen aan de parameter checkpoint_segments (of min_wal_size en max_wal_size, afhankelijk van de versie) in het postgresql.conf-configuratiebestand.
Eén parameter die u moet instellen bij het configureren van al uw PostgreSQL-installaties is de wal_level. Het wal_level bepaalt hoeveel informatie naar de WAL wordt geschreven. De standaardwaarde is minimaal, die alleen de informatie schrijft die nodig is om te herstellen van een crash of onmiddellijke afsluiting. Archive voegt logboekregistratie toe die vereist is voor WAL-archivering; hot_standby voegt verder informatie toe die nodig is om alleen-lezen query's op een standby-server uit te voeren; logisch voegt informatie toe die nodig is om logische decodering te ondersteunen. Deze parameter vereist een herstart, dus het kan moeilijk zijn om wijzigingen aan te brengen in draaiende productiedatabases als u dat vergeten bent.
Voor meer informatie kunt u hier of hier de officiële documentatie raadplegen. Nu we de WAL hebben behandeld, gaan we de geschiedenis van replicatie in PostgreSQL bekijken.
Geschiedenis van replicatie in PostgreSQL
De eerste replicatiemethode (warm stand-by) die PostgreSQL implementeerde (versie 8.2, in 2006) was gebaseerd op de verzendmethode voor logbestanden.
Dit betekent dat de WAL-records direct van de ene databaseserver naar de andere worden verplaatst om te worden toegepast. We kunnen zeggen dat het een continue PITR is.
PostgreSQL implementeert op bestanden gebaseerde verzending van logbestanden door WAL-records één bestand (WAL-segment) tegelijk over te dragen.
Deze replicatie-implementatie heeft het nadeel:als er een grote storing is op de primaire servers, gaan transacties die nog niet zijn verzonden verloren. Er is dus een venster voor gegevensverlies (u kunt dit afstemmen door de parameter archive_timeout te gebruiken, die kan worden ingesteld op slechts enkele seconden. Een dergelijke lage instelling zal echter de bandbreedte die nodig is voor het verzenden van bestanden aanzienlijk vergroten).
We kunnen deze bestandsgebaseerde verzendmethode voor logbestanden weergeven met de onderstaande afbeelding:
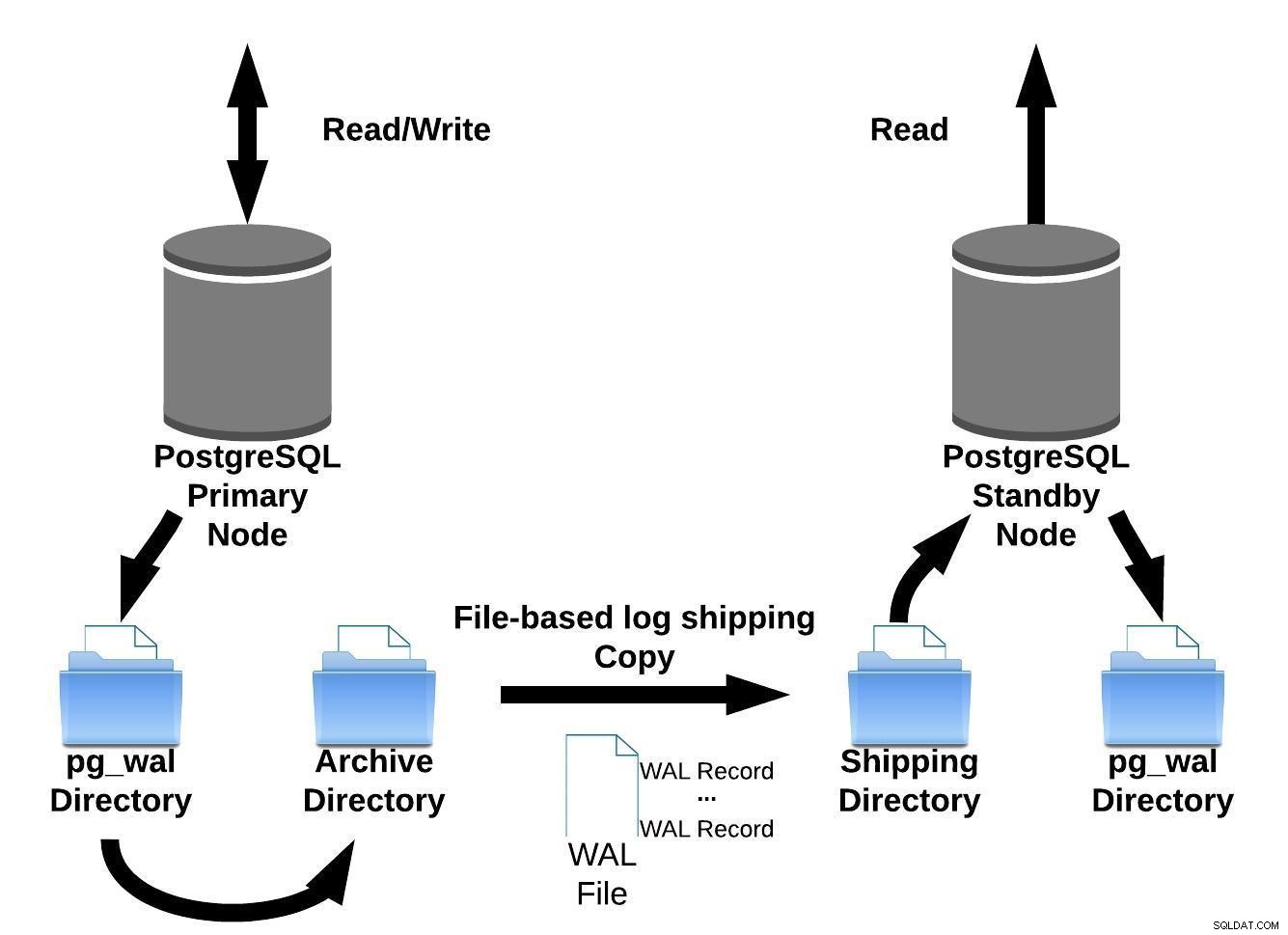 PostgreSQL-bestandsgebaseerde verzending van logbestanden
PostgreSQL-bestandsgebaseerde verzending van logbestandenVervolgens, in versie 9.0 (terug in 2010 ), werd streamingreplicatie geïntroduceerd.
Streaming-replicatie stelt je in staat om meer up-to-date te blijven dan mogelijk is met op bestanden gebaseerde verzending van logbestanden. Dit werkt door WAL-records (een WAL-bestand is samengesteld uit WAL-records) on-the-fly (record-based log shipping) tussen een primaire server en een of meerdere standby-servers over te dragen zonder te wachten tot het WAL-bestand is gevuld.
In de praktijk zal een proces met de naam WAL-ontvanger, dat draait op de standby-server, verbinding maken met de primaire server via een TCP/IP-verbinding. In de primaire server bestaat een ander proces, genaamd WAL-afzender, en is verantwoordelijk voor het verzenden van de WAL-registers naar de standby-server wanneer ze plaatsvinden.
Het volgende diagram stelt streaming-replicatie voor:
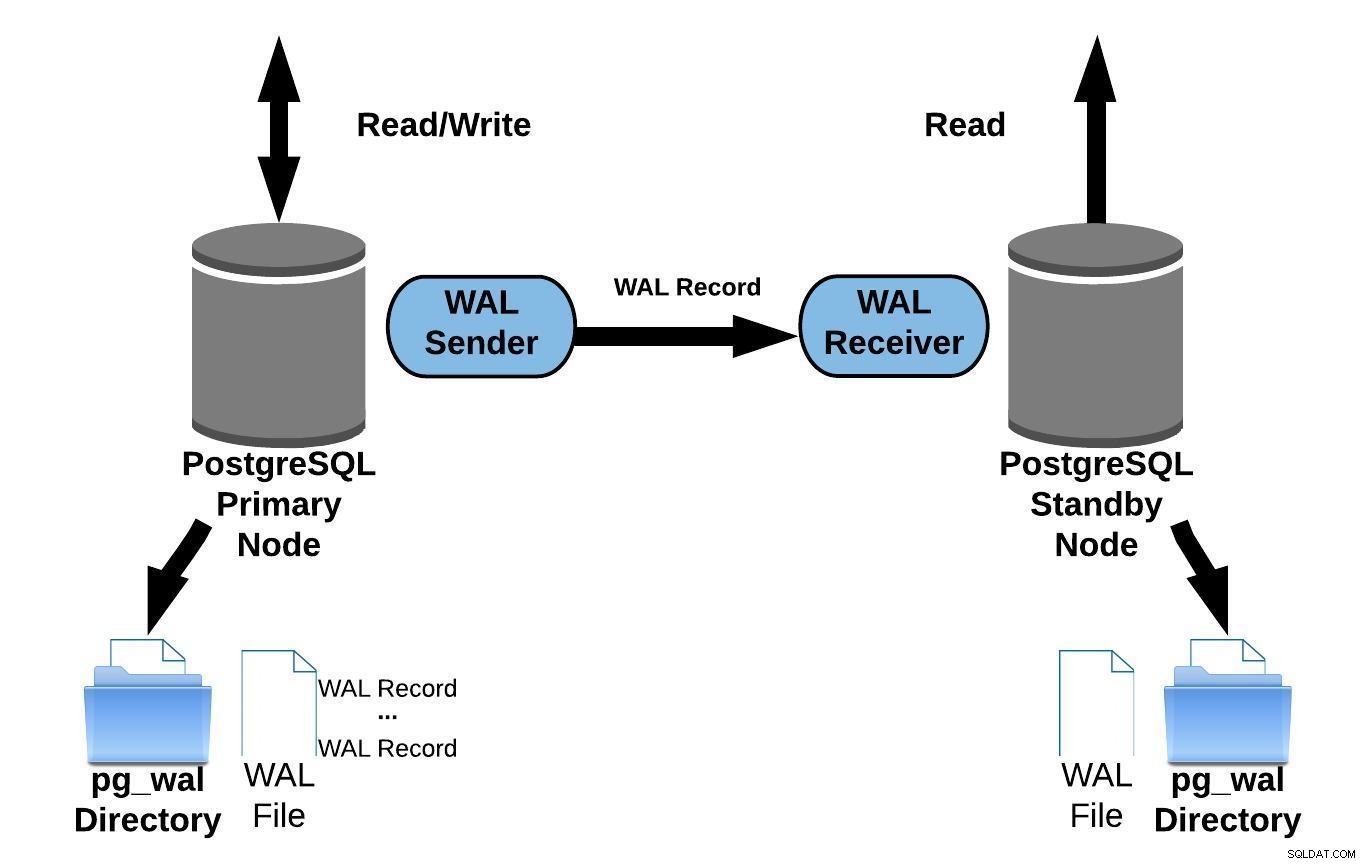 PostgreSQL Streaming-replicatie
PostgreSQL Streaming-replicatieAls je naar het bovenstaande diagram kijkt, vraag je je misschien af wat er gebeurt wanneer de communicatie tussen de WAL-zender en de WAL-ontvanger mislukt?
Bij het configureren van streamingreplicatie heeft u de mogelijkheid om WAL-archivering in te schakelen.
Deze stap is niet verplicht, maar is uiterst belangrijk voor een robuuste replicatie-installatie. Het is noodzakelijk om te voorkomen dat de hoofdserver oude WAL-bestanden recycleert die nog niet zijn toegepast op de standby-server. Als dit gebeurt, moet u de replica helemaal opnieuw maken.
Bij het configureren van replicatie met continue archivering, begint het met een back-up. Om de in-sync-status met de primaire te bereiken, moet deze alle wijzigingen toepassen die zijn gehost in de WAL die na de back-up zijn gebeurd. Tijdens dit proces herstelt de standby eerst alle beschikbare WAL op de archieflocatie (gedaan door restore_command aan te roepen). De restore_command zal mislukken wanneer het het laatst gearchiveerde WAL-record bereikt, dus daarna gaat de standby in de pg_wal-directory kijken om te zien of de wijziging daar bestaat (dit werkt om gegevensverlies te voorkomen wanneer de primaire servers crashen en enkele wijzigingen die zijn al verplaatst en toegepast op de replica, zijn nog niet gearchiveerd).
Als dat niet lukt en het gevraagde record daar niet bestaat, zal het gaan communiceren met de primaire server via streaming-replicatie.
Als streaming-replicatie mislukt, gaat het terug naar stap 1 en worden de records uit het archief opnieuw hersteld. Deze lus van nieuwe pogingen vanuit het archief, pg_wal, en via streaming-replicatie gaat door totdat de server stopt of een failover wordt geactiveerd door een triggerbestand.
Het volgende diagram geeft een configuratie voor streaming-replicatie met continue archivering weer:
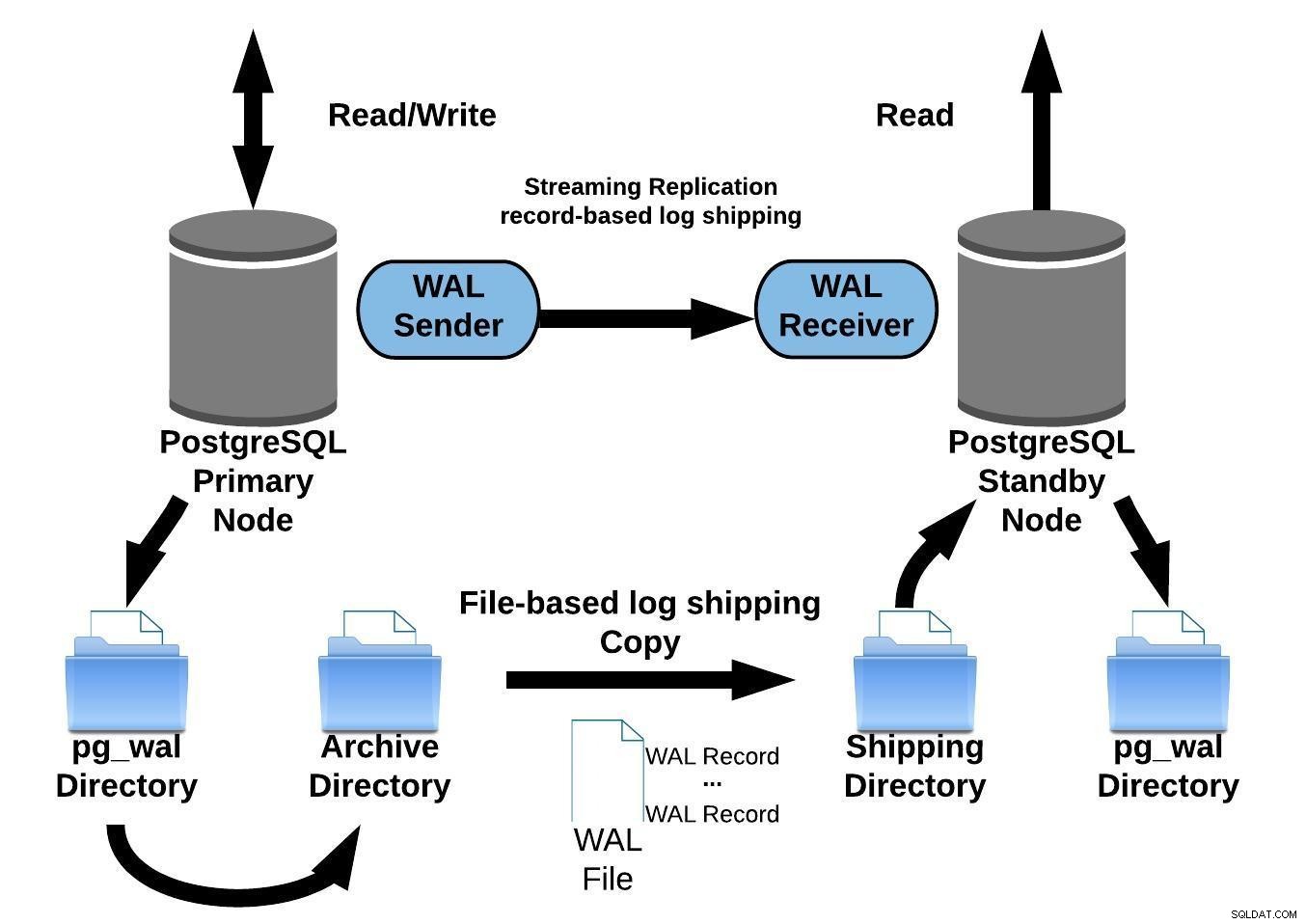 PostgreSQL-streamingreplicatie met continue archivering
PostgreSQL-streamingreplicatie met continue archiveringStreamingreplicatie is standaard asynchroon, dus op op elk willekeurig moment kunt u transacties hebben die kunnen worden vastgelegd op de primaire server en die nog niet zijn gerepliceerd naar de standby-server. Dit impliceert mogelijk gegevensverlies.
Deze vertraging tussen de vastlegging en de impact van de wijzigingen in de replica wordt echter verondersteld erg klein te zijn (enkele milliseconden), uiteraard in de veronderstelling dat de replicaserver krachtig genoeg is om gelijke tred te houden met de lading.
Voor gevallen waarin zelfs het risico van een klein gegevensverlies niet acceptabel is, heeft versie 9.1 de functie voor synchrone replicatie geïntroduceerd.
Bij synchrone replicatie wacht elke vastlegging van een schrijftransactie totdat de bevestiging is ontvangen dat de vastlegging is geschreven naar het write-ahead-logboek op schijf van zowel de primaire als de standby-server.
Deze methode minimaliseert de kans op gegevensverlies; om dat te laten gebeuren, moet je zowel de primaire als de stand-by tegelijkertijd laten uitvallen.
Het voor de hand liggende nadeel van deze configuratie is dat de responstijd voor elke schrijftransactie toeneemt, omdat er moet worden gewacht totdat alle partijen hebben gereageerd. Dus de tijd voor een commit is minimaal de heen- en terugreis tussen de primaire en de replica. Alleen-lezen transacties worden hierdoor niet beïnvloed.
Als u synchrone replicatie wilt instellen, moet u een toepassingsnaam opgeven in de primary_conninfo van het herstel voor elk stand-by server.conf-bestand:primary_conninfo ='...aplication_name=standbyX' .
U moet ook de lijst specificeren van de standby-servers die zullen deelnemen aan de synchrone replicatie:synchronous_standby_name ='standbyX,standbyY'.
U kunt een of meerdere synchrone servers instellen, en deze parameter specificeert ook welke methode (EERSTE en WELKE) synchrone standbys moet kiezen uit de vermelde. Bekijk deze blog voor meer informatie over het instellen van de synchrone replicatiemodus. Het is ook mogelijk om synchrone replicatie in te stellen bij implementatie via ClusterControl.
Nadat u uw replicatie hebt geconfigureerd en deze actief is, moet u monitoring implementeren
PostgreSQL-replicatie bewaken
De weergave pg_stat_replication op de masterserver bevat veel relevante informatie:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Laten we dit in detail bekijken:
-
pid:Proces-ID van walsender-proces.
-
usesysid:OID van gebruiker die wordt gebruikt voor streaming-replicatie.
-
usename:naam van de gebruiker die wordt gebruikt voor streaming-replicatie.
-
application_name:applicatienaam verbonden met master.
-
client_addr:Adres van stand-by/streaming-replicatie.
-
client_hostname:Hostnaam van stand-by.
-
client_port:TCP-poortnummer waarop stand-by communiceert met WAL-afzender.
-
backend_start:begintijd wanneer SR verbinding maakte met Primair.
-
status:huidige WAL-afzenderstatus, d.w.z. streaming.
-
sent_lsn:Laatste transactielocatie naar stand-by gestuurd.
-
write_lsn:Laatste transactie geschreven op schijf in stand-by.
-
flush_lsn:Laatste transactiespoeling op schijf in stand-by.
-
replay_lsn:Laatste transactiespoeling op schijf in stand-by.
-
sync_priority:prioriteit van de standby-server gekozen als de synchrone standby.
-
sync_state:synchronisatiestatus van stand-by (is het asynchroon of synchroon).
Je kunt ook de WAL verzend-/ontvangerprocessen op de servers zien.
Afzender (primair knooppunt):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Ontvanger (Standby Node):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Een manier om te controleren hoe up-to-date uw replicatie is, is door het aantal WAL-records te controleren dat is gegenereerd op de primaire server, maar nog niet is toegepast op de standby-server.
Primair:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Stand-by:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)U kunt de volgende query in het standby-knooppunt gebruiken om de vertraging in seconden te krijgen:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)En je kunt ook het laatst ontvangen bericht zien:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)PostgreSQL-replicatie bewaken met ClusterControl
Als u uw PostgreSQL-cluster wilt bewaken, kunt u ClusterControl gebruiken, waarmee u verschillende aanvullende beheertaken kunt bewaken en uitvoeren, zoals implementatie, back-ups, uitschalen en meer.
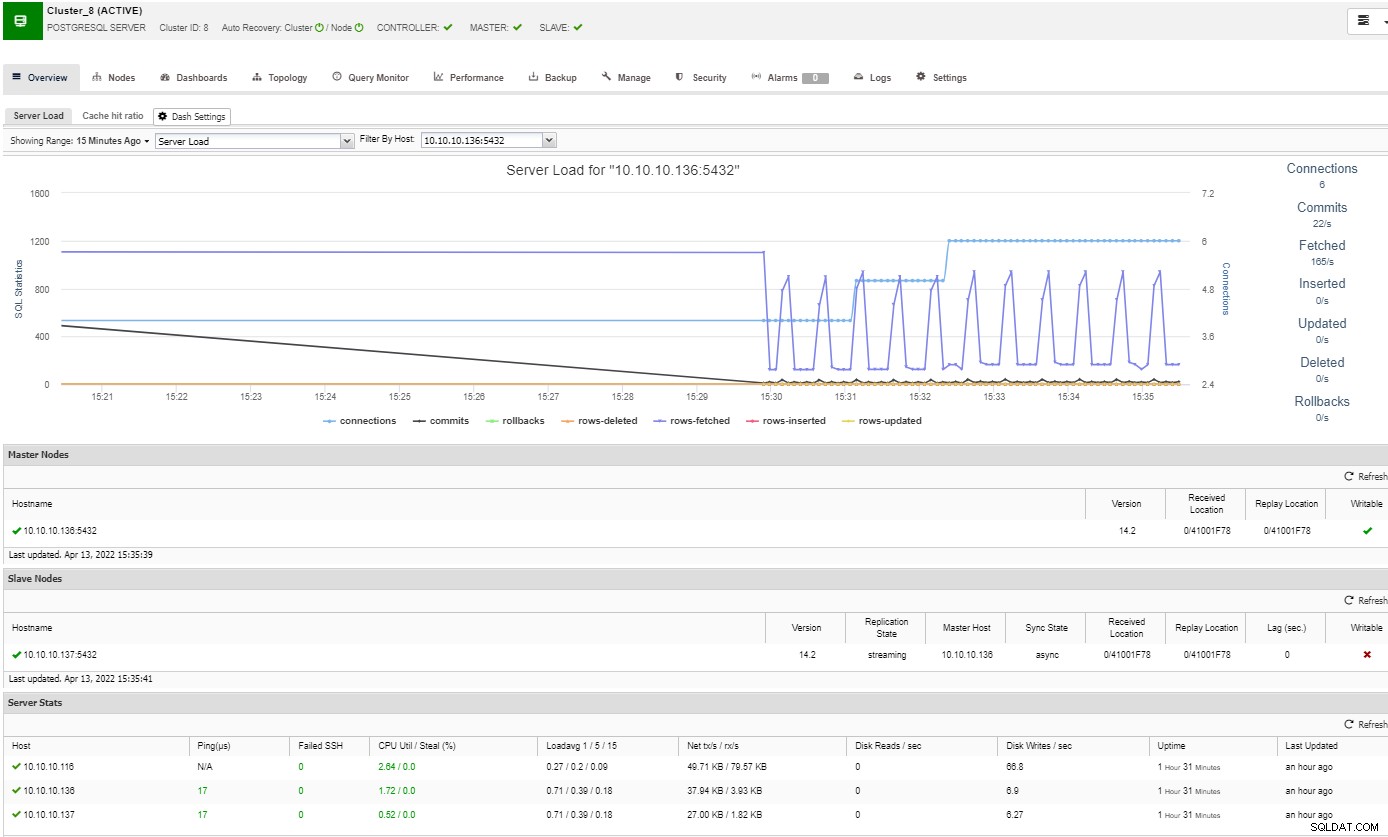
In het overzichtsgedeelte heeft u een volledig beeld van uw databasecluster huidige status. Voor meer details gaat u naar het dashboardgedeelte, waar u veel nuttige informatie ziet, opgedeeld in verschillende grafieken.
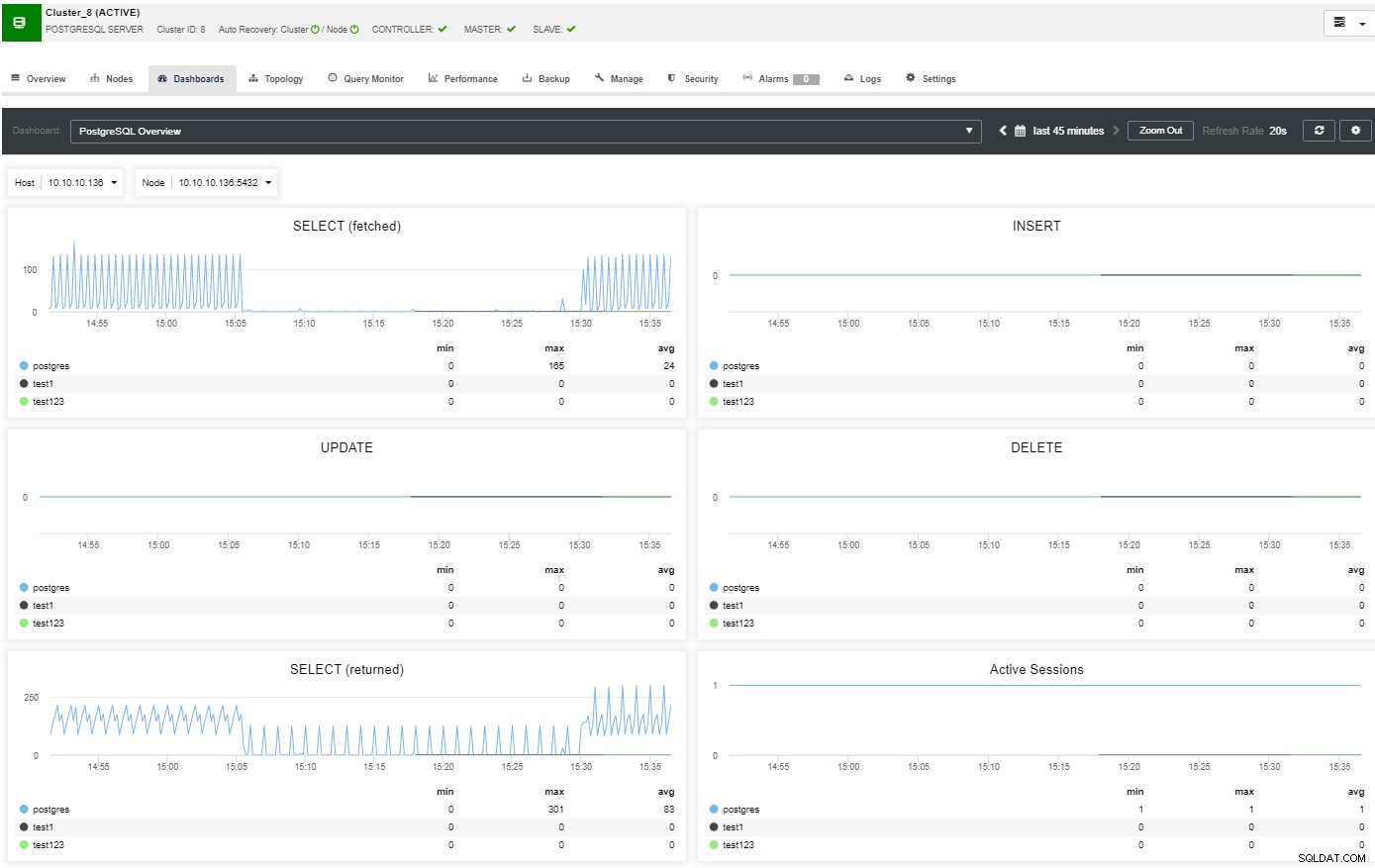
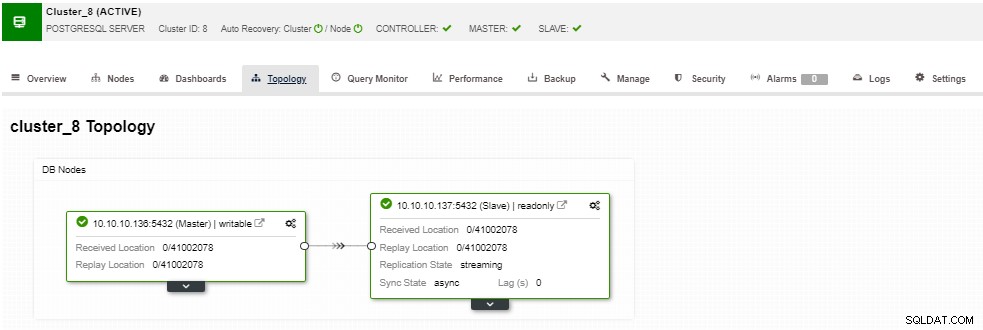
In de topologiesectie kunt u uw huidige topologie in een gebruikers- vriendelijke manier, en u kunt ook verschillende taken over de knooppunten uitvoeren door de knop Knooppuntactie te gebruiken.
Streaming-replicatie is gebaseerd op het verzenden van de WAL-records en het toepassen ervan op de stand-by server, dicteert het welke bytes in welk bestand moeten worden toegevoegd of gewijzigd. Als gevolg hiervan is de standby-server eigenlijk een bit-voor-bit kopie van de primaire server. Er zijn hier echter enkele bekende beperkingen:
-
Je kunt niet repliceren naar een andere versie of architectuur.
-
Je kunt niets wijzigen op de standby-server.
-
Je hebt niet veel details over wat je repliceert.
Dus, om deze beperkingen te overwinnen, heeft PostgreSQL 10 ondersteuning voor logische replicatie toegevoegd
Logische replicatie
Logische replicatie gebruikt ook de informatie in het WAL-bestand, maar decodeert deze in logische wijzigingen. In plaats van te weten welke byte is gewijzigd, weet het precies welke gegevens in welke tabel zijn ingevoegd.
Het is gebaseerd op een "publish" en "subscribe"-model waarbij een of meer abonnees zich abonneren op een of meer publicaties op een uitgeversknooppunt dat er als volgt uitziet:
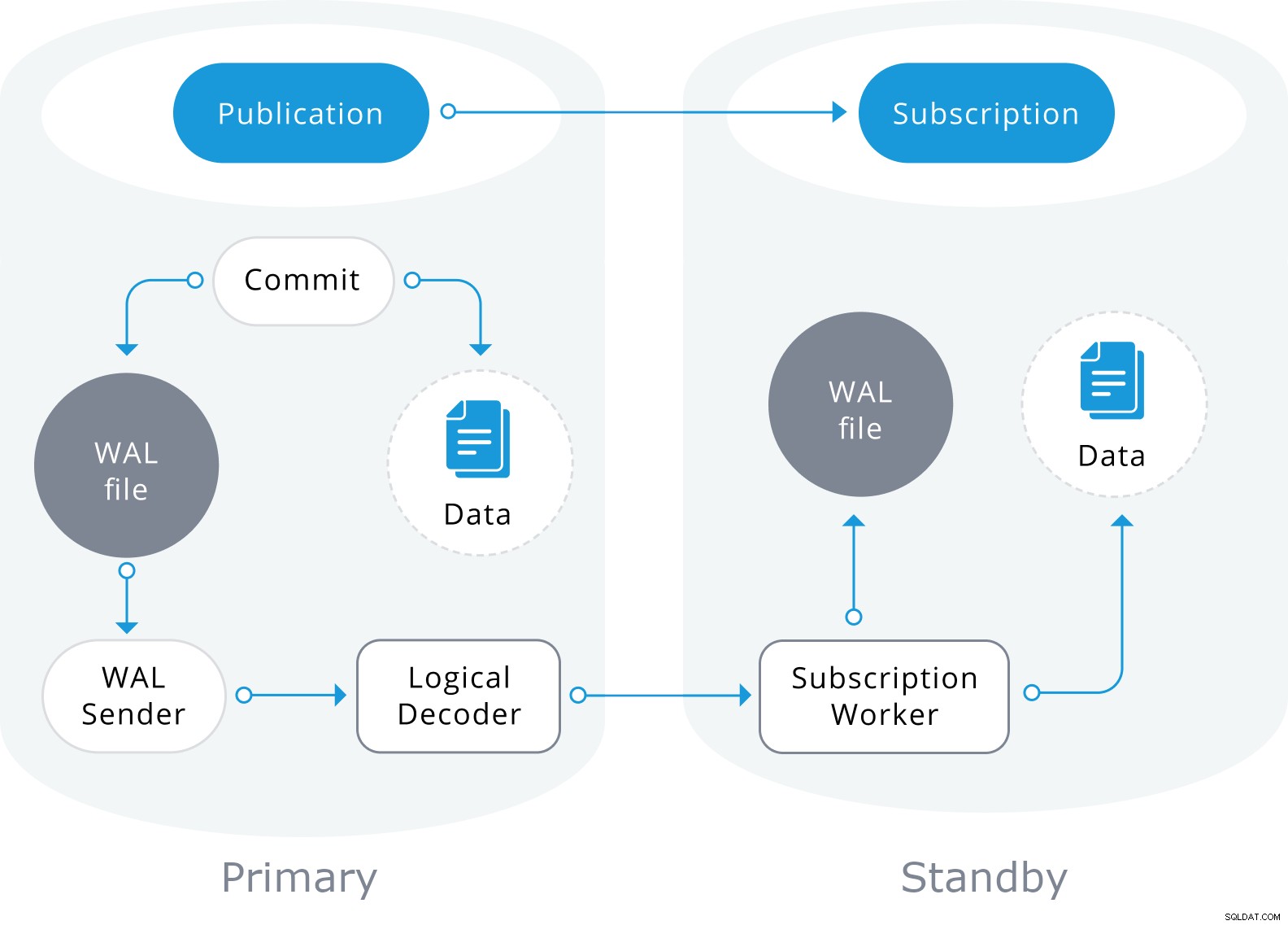
Afronden
Met streaming-replicatie kunt u continu WAL-records verzenden en toepassen op uw stand-by-servers, zodat de bijgewerkte informatie op de primaire server in realtime wordt overgedragen naar de stand-by-server, zodat beide synchroon blijven .
ClusterControl maakt het instellen van streaming-replicatie eenvoudig en u kunt het 30 dagen gratis evalueren.
Als je meer wilt weten over logische replicatie in PostgreSQL, bekijk dan zeker dit overzicht van logische replicatie en dit bericht over best practices voor PostgreSQL-replicatie.
Voor meer tips en best practices voor het beheren van uw op open source gebaseerde database, volg ons op Twitter en LinkedIn, en abonneer u op onze nieuwsbrief voor regelmatige updates.