PostgreSQL is een van de databases die kan worden ingezet via ClusterControl, samen met MySQL, MariaDB en MongoDB. ClusterControl vereenvoudigt niet alleen de implementatie van het databasecluster, maar heeft ook een functie voor schaalbaarheid voor het geval uw applicatie groeit en die functionaliteit vereist.
Door uw database op te schalen, zal uw applicatie veel soepeler en beter werken als de applicatiebelasting of het verkeer toeneemt. In deze blogpost bespreken we de stappen voor het implementeren en opschalen van PostgreSQL v13 met ClusterControl 1.8.2.
Gebruikersinterface (UI)-implementatie
Er zijn twee manieren van implementatie in ClusterControl, de webgebruikersinterface (UI) en de opdrachtregelinterface (CLI). De gebruiker heeft de vrijheid om een van de implementatie-opties te kiezen, afhankelijk van hun voorkeur en behoefte. Beide opties zijn gemakkelijk te volgen en goed gedocumenteerd in onze documentatie. In deze sectie zullen we het implementatieproces doorlopen met behulp van de eerste optie - web-UI.
De eerste stap is om in te loggen op uw ClusterControl en op Deploy te klikken:
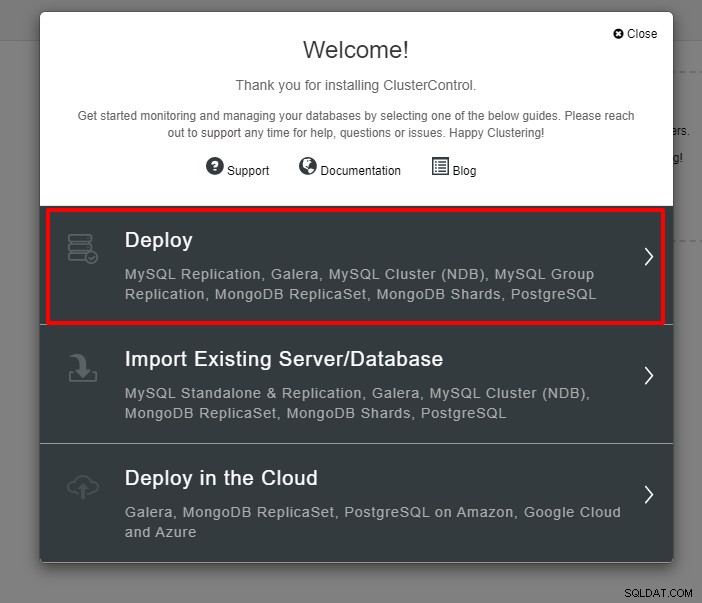
U krijgt de onderstaande schermafbeelding te zien voor de volgende stap van de implementatie , kies het tabblad PostgreSQL om door te gaan:
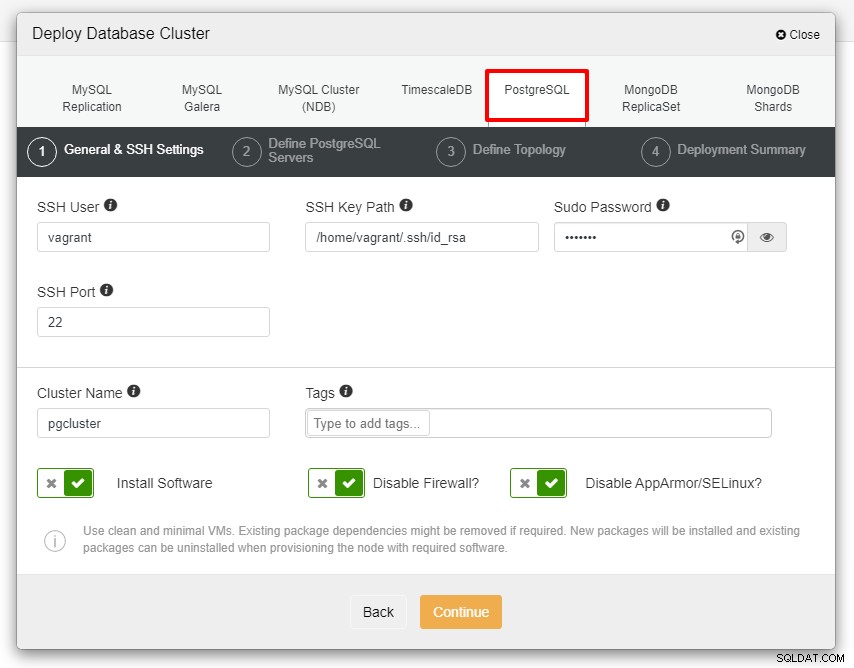
Voordat we verder gaan, wil ik u eraan herinneren dat de verbinding tussen het ClusterControl-knooppunt en de databaseknooppunten moeten wachtwoordloos zijn. Voorafgaand aan de implementatie hoeven we alleen de ssh-keygen van het ClusterControl-knooppunt te genereren en deze vervolgens naar alle knooppunten te kopiëren. Vul de invoer in voor de SSH-gebruiker, het Sudo-wachtwoord en de clusternaam volgens uw vereisten en klik op Doorgaan.
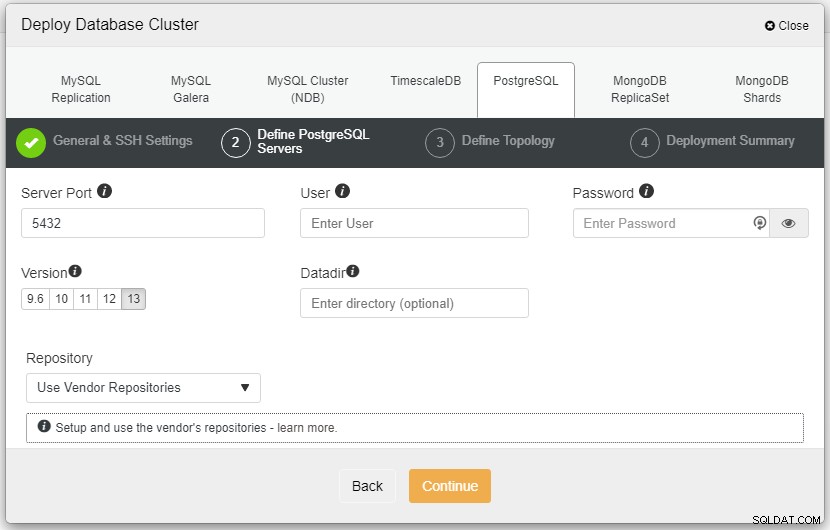
In de bovenstaande schermafbeelding moet u de serverpoort definiëren (in als u anderen wilt gebruiken), de gebruiker die u wilt gebruiken en het wachtwoord en zorg ervoor dat u versie 13 kiest die u wilt installeren.
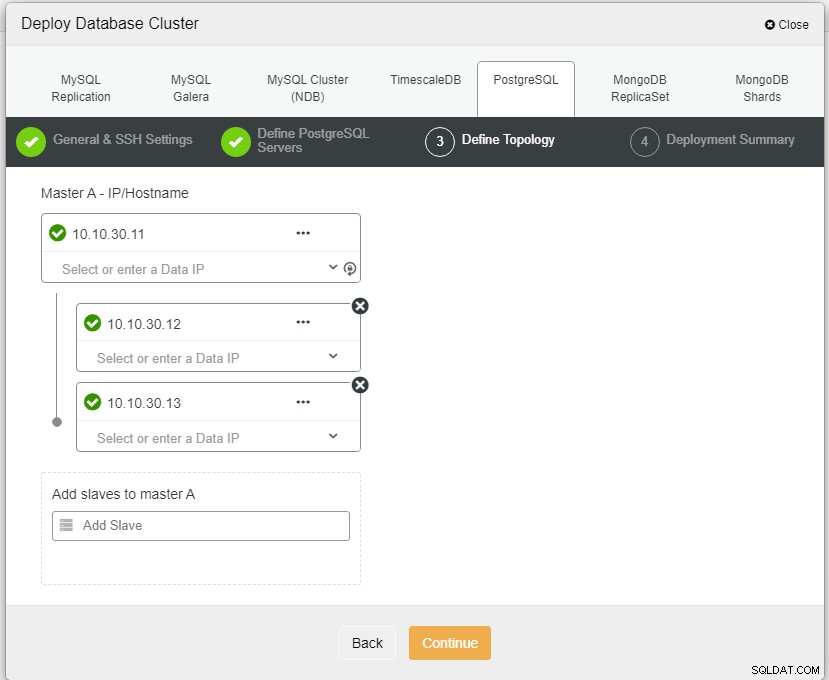 Foto auteurFotobeschrijving
Foto auteurFotobeschrijvingHier moeten we de servers definiëren met behulp van de hostnaam of het IP-adres, zoals in dit geval 1 master en 2 slaves. De laatste stap is het kiezen van de replicatiemodus voor ons cluster.
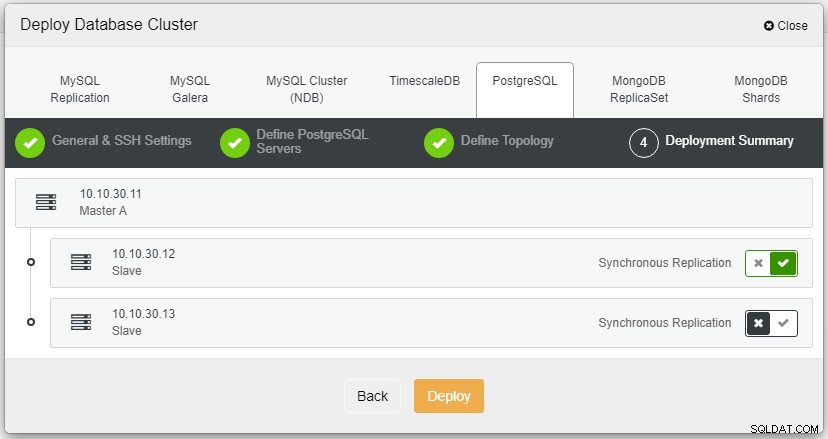
Nadat u op Implementeren hebt geklikt, wordt het implementatieproces gestart en kunnen we de voortgang op het tabblad Activiteit.
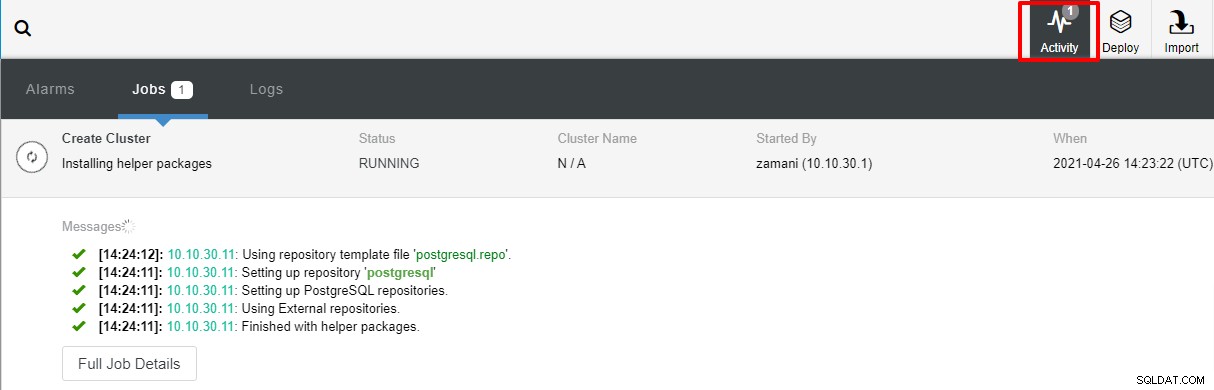
De implementatie duurt normaal gesproken een paar minuten, de prestaties hangen grotendeels af van de netwerk en de specificaties van de server.

Nu we PostgreSQL v13 hebben geïnstalleerd met behulp van ClusterControl GUI, wat vrij eenvoudig is .
Command Line Interface (CLI) PostgreSQL-implementatie
Uit het bovenstaande kunnen we zien dat de implementatie vrij eenvoudig is met behulp van de web-UI. De belangrijke opmerking is dat alle knooppunten voorafgaand aan de implementatie wachtwoordloze SSH-verbindingen moeten hebben. In deze sectie gaan we zien hoe u kunt implementeren met behulp van de opdrachtregel ClusterControl CLI of "s9s".
We gingen ervan uit dat ClusterControl eerder was geïnstalleerd, laten we beginnen met het genereren van de ssh-keygen. Voer in het ClusterControl-knooppunt de volgende opdrachten uit:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Zodra alle bovenstaande opdrachten met succes zijn uitgevoerd, kunnen we de wachtwoordloze verbinding verifiëren met behulp van de volgende opdracht:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordAls de bovenstaande opdracht met succes wordt uitgevoerd, kan de clusterimplementatie worden gestart vanaf de ClusterControl-server met behulp van de volgende opdrachtregel:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logDirect nadat je de bovenstaande opdracht hebt uitgevoerd, zie je zoiets als dit, wat betekent dat de taak is gestart:
Cluster wordt gemaakt op 3 gegevensknooppunt(en).
Taakparameters verifiëren.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Je kunt het ook verifiëren door in te loggen op de webconsole met de gebruikersnaam die je hebt aangemaakt. Nu hebben we een PostgreSQL-cluster geïmplementeerd met behulp van 3 knooppunten. Als u meer wilt weten over de bovenstaande implementatieopdracht, is dit de beste referentie voor u.
PostgreSQL opschalen met ClusterControl UI
PostgreSQL is een relationele database en we weten dat het uitschalen van dit type database niet eenvoudig is in vergelijking met een niet-relationele database. Tegenwoordig hebben de meeste applicaties schaalbaarheid nodig om betere prestaties en snelheid te kunnen bieden. Er zijn veel manieren om dit te implementeren, afhankelijk van uw infrastructuur en omgeving.
Schaalbaarheid is een van de functies die door ClusterControl kan worden gefaciliteerd en kan worden bereikt met zowel gebruikersinterface als CLI. In deze sectie gaan we kijken hoe we PostgreSQL kunnen uitschalen met behulp van de gebruikersinterface van ClusterControl. De eerste stap is om in te loggen op uw gebruikersinterface en het cluster te kiezen. Zodra het cluster is gekozen, kunt u op de optie klikken zoals in de onderstaande schermafbeelding:
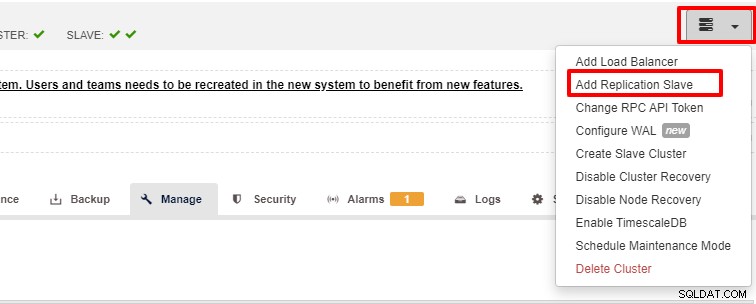
Zodra op "Add Replication Slave" is geklikt, ziet u de volgende pagina . U kunt "Nieuwe toevoegen..." of "Importeren..." kiezen, afhankelijk van uw situatie. In dit voorbeeld zullen we de eerste optie kiezen:
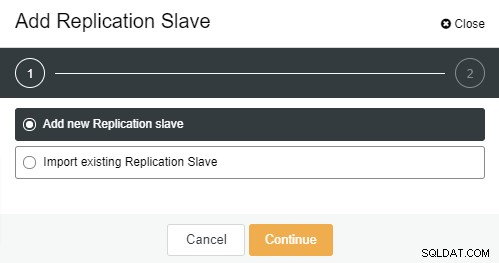
Het volgende scherm wordt weergegeven zodra u erop klikt:
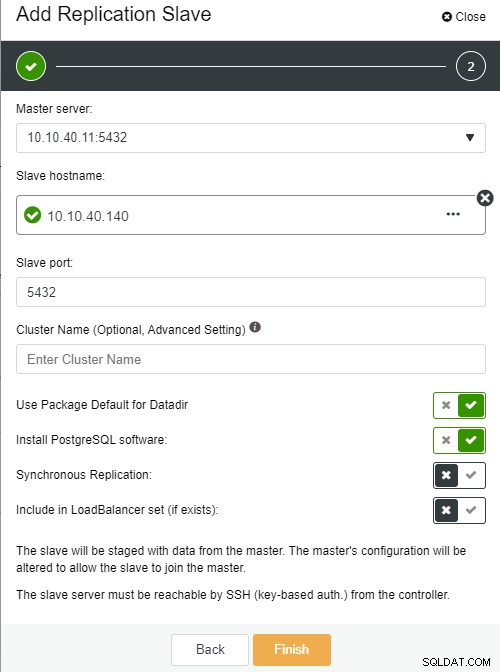 Foto auteurFotobeschrijving
Foto auteurFotobeschrijving-
Slave Hostname:de hostnaam/IP-adres van de nieuwe slave of node
-
Slave-poort:de PostgreSQL-poort van de slave, standaard is 5432
-
Clusternaam:de naam van het cluster, u kunt deze toevoegen of leeg laten
-
Gebruik pakketstandaard voor Datadir:u kunt deze optie aangevinkt hebben als u een andere locatie wilt hebben voor Datadir
-
Installeer PostgreSQL-software:u kunt deze optie aangevinkt laten
-
Synchrone replicatie:je kunt kiezen welk type replicatie je in deze wilt hebben
-
Opnemen in LoadBalancer-set (indien aanwezig):deze optie moet worden aangevinkt als u LoadBalancer hebt geconfigureerd voor het cluster
De belangrijkste belangrijke opmerking hier is dat je de nieuwe slave-host moet configureren om wachtwoordloos te zijn voordat je deze setup kunt uitvoeren. Zodra alles is bevestigd, kunnen we op de knop "Voltooien" klikken om de installatie te voltooien. In dit voorbeeld heb ik IP “10.10.40.140” toegevoegd.
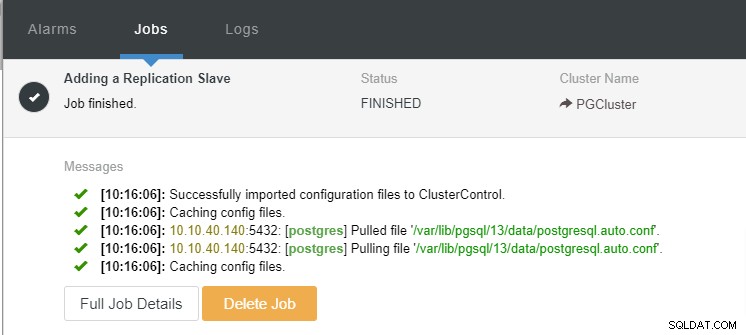
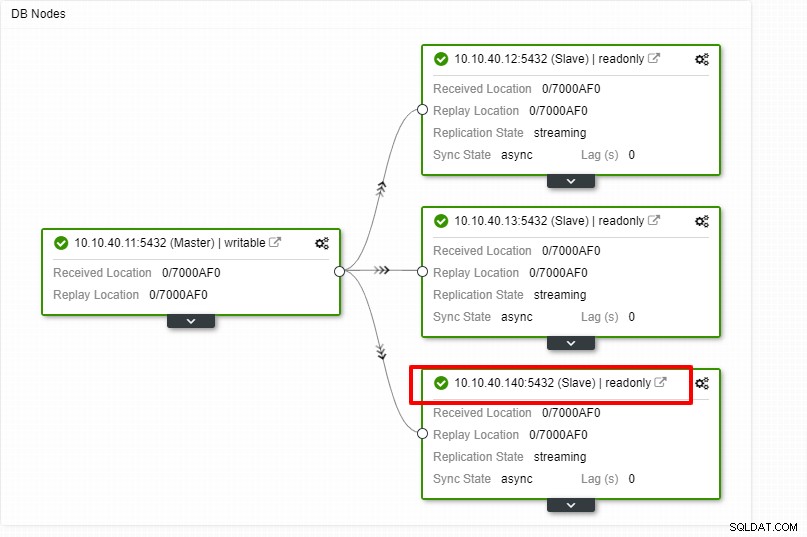
We kunnen nu de taakactiviteit volgen en de installatie laten voltooien. Om de installatie te bevestigen, kunnen we naar het tabblad "Topologie" gaan om de nieuwe slave te zien:
PostgreSQL uitschalen met ClusterControl CLI
Het toevoegen van de nieuwe nodes aan het bestaande cluster is heel eenvoudig met behulp van de CLI. Vanaf het controllerknooppunt voert u de volgende opdracht uit. De eerste opdracht is om het cluster te identificeren waaraan we het nieuwe knooppunt willen toevoegen:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.In dit voorbeeld kunnen we zien dat de node-ID "1" is voor de clusternaam "PGCluster". Laten we eens kijken naar de eerste opdrachtoptie voor het toevoegen van een nieuw knooppunt aan het bestaande PostgreSQL-cluster:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logDe afkorting "--log" aan het einde van de regel laat ons zien wat de huidige taak is die wordt uitgevoerd nadat de opdracht is uitgevoerd zoals hieronder:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Het volgende beschikbare commando dat je kunt gebruiken is als volgt:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitKnooppunt toevoegen aan cluster
\ Job 9 RUNNING [▋ ] 5% Installing packagesMerk op dat er een afkorting "--wait" in de regel staat en dat de uitvoer die u ziet, wordt weergegeven zoals hierboven. Zodra het proces is voltooid, kunnen we de nieuwe knooppunten bevestigen op het tabblad 'Overzicht' van het cluster vanuit de gebruikersinterface:
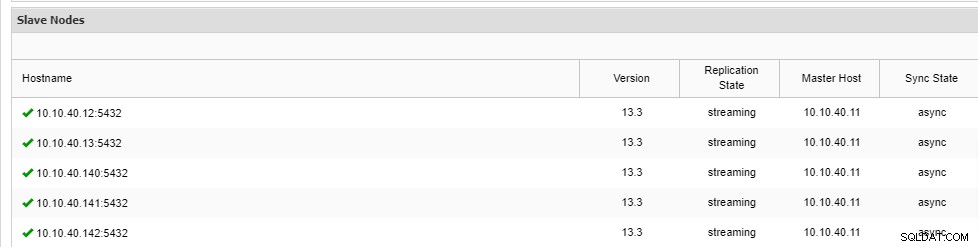
Conclusie
In deze blogpost hebben we twee opties besproken voor het uitschalen van PostgreSQL in ClusterControl. Zoals u wellicht opmerkt, is het uitschalen van PostgreSQL eenvoudig met ClusterControl. ClusterControl kan niet alleen de schaalbaarheid doen, maar u kunt ook een hoge beschikbaarheid instellen voor uw databasecluster. Functies zoals HAProxy, PgBouncer en Keepalive zijn beschikbaar en klaar om te worden geïmplementeerd voor uw cluster wanneer u daar behoefte aan heeft. Met ClusterControl is uw databasecluster eenvoudig te beheren en tegelijkertijd te bewaken.
We hopen dat deze blogpost je zal helpen bij het uitbreiden van je PostgreSQL-configuratie.