In de wereld van informatietechnologie is automatisering voor de meesten van ons niet nieuw. In feite gebruiken de meeste organisaties het voor verschillende doeleinden, afhankelijk van hun werktype en doelstellingen. Gegevensanalisten gebruiken bijvoorbeeld automatisering om rapporten te genereren, systeembeheerders gebruiken automatisering voor hun repetitieve taken, zoals het opschonen van schijfruimte, en ontwikkelaars gebruiken automatisering om hun ontwikkelingsproces te automatiseren.
Tegenwoordig zijn er dankzij het DevOps-tijdperk veel automatiseringstools voor IT beschikbaar en te kiezen. Wat is het beste gereedschap? Het antwoord is een voorspelbaar 'het hangt ervan af', omdat het afhangt van wat we proberen te bereiken en van onze omgeving. Sommige van de automatiseringstools zijn Terraform, Bolt, Chef, SaltStack en een zeer trendy is Ansible. Ansible is een open-source agentloze IT-engine die applicatie-implementatie, configuratiebeheer en IT-orkestratie kan automatiseren. Ansible is opgericht in 2012 en is geschreven in de meest populaire taal, Python. Het gebruikt een playbook om alle automatisering te implementeren, waarbij alle configuraties zijn geschreven in een voor mensen leesbare taal, YAML.
In de post van vandaag gaan we leren hoe we Ansible kunnen gebruiken om Postgresql-database-implementatie uit te voeren.
Wat maakt Ansible speciaal?
De reden waarom ansible voornamelijk wordt gebruikt vanwege zijn functies. Die functies zijn:
-
Alles kan worden geautomatiseerd met behulp van eenvoudige, voor mensen leesbare taal YAML
-
Er wordt geen agent geïnstalleerd op de externe computer (agentloze architectuur)
-
De configuratie wordt van uw lokale machine naar de server gepusht vanaf uw lokale machine (push-model)
-
Ontwikkeld met Python (een van de populaire talen die momenteel worden gebruikt) en er kunnen veel bibliotheken worden gekozen uit
-
Verzameling van Ansible-modules zorgvuldig geselecteerd door het Red Had Engineering Team
De manier waarop Ansible werkt
Voordat Ansible operationele taken naar de externe hosts kan uitvoeren, moeten we het op één host installeren die het controllerknooppunt wordt. In dit controllerknooppunt zullen we alle taken die we zouden willen uitvoeren, orchestreren in de externe hosts, ook wel beheerde knooppunten genoemd.
Het controllerknooppunt moet de inventaris van de beheerde knooppunten en de Ansible-software hebben om het te kunnen beheren. De vereiste gegevens die door Ansible moeten worden gebruikt, zoals de hostnaam of het IP-adres van het beheerde knooppunt, worden in deze inventaris geplaatst. Zonder een goede inventarisatie zou Ansible de automatisering niet correct kunnen uitvoeren. Kijk hier voor meer informatie over voorraad.
Ansible is agentless en gebruikt SSH om de wijzigingen door te voeren, wat betekent dat we Ansible niet in alle nodes hoeven te installeren, maar op alle beheerde nodes moet python en alle noodzakelijke python-bibliotheken zijn geïnstalleerd. Zowel het controllerknooppunt als de beheerde knooppunten moeten worden ingesteld als wachtwoordloos. Het is vermeldenswaard dat de verbinding tussen alle controllerknooppunten en beheerde knooppunten goed is en goed is getest.
Voor deze demo heb ik 4 Centos 8 VM's ingericht met behulp van vagrant. Eén zal fungeren als een controllerknooppunt en de andere 2 VM's zullen fungeren als de databaseknooppunten die moeten worden geïmplementeerd. We gaan in deze blogpost niet in op details over het installeren van Ansible, maar als je de handleiding wilt zien, bezoek dan deze link. Houd er rekening mee dat we 3 knooppunten gebruiken om een streamingreplicatietopologie in te stellen, met één primaire en 2 standby-knooppunten. Tegenwoordig bevinden veel productiedatabases zich in een configuratie met hoge beschikbaarheid en een configuratie met 3 knooppunten is gebruikelijk.
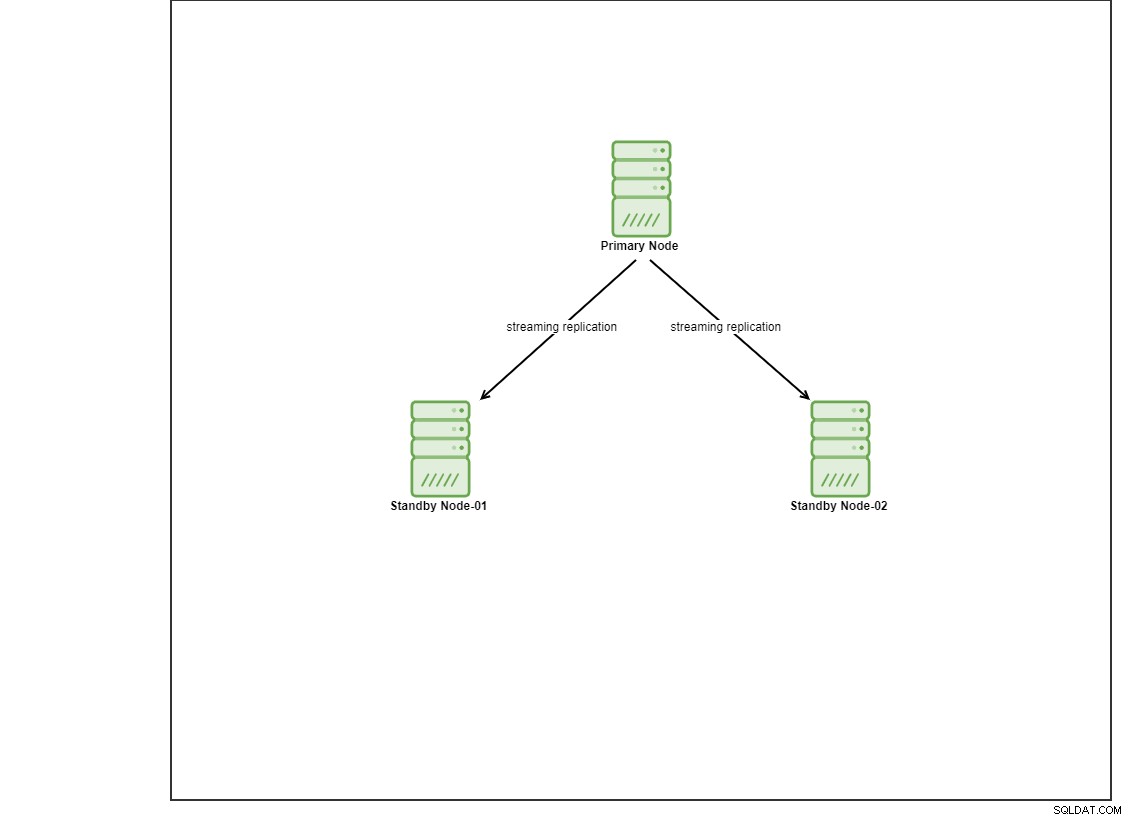
PostgreSQL installeren
Er zijn verschillende manieren om PostgreSQL te installeren met behulp van Ansible. Vandaag zal ik Ansible Rollen gebruiken om dit doel te bereiken. Ansible-rollen in een notendop zijn een reeks taken om een host te configureren om een bepaald doel te dienen, zoals het configureren van een service. Ansible-rollen worden gedefinieerd met behulp van YAML-bestanden met een vooraf gedefinieerde directorystructuur die kan worden gedownload van de Ansible Galaxy-portal.
Ansible Galaxy daarentegen is een opslagplaats voor Ansible-rollen die direct in je Playbooks kunnen worden geplaatst om je automatiseringsprojecten te stroomlijnen.
Voor deze demo heb ik de rollen gekozen die door dudefellah zijn onderhouden. Om deze rol te kunnen gebruiken, moeten we deze downloaden en installeren op het controllerknooppunt. De taak is vrij eenvoudig en kan worden uitgevoerd door de volgende opdracht uit te voeren, op voorwaarde dat Ansible op uw controllerknooppunt is geïnstalleerd:
$ ansible-galaxy install dudefellah.postgresqlJe zou het volgende resultaat moeten zien zodra de rol met succes is geïnstalleerd in je controllerknooppunt:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Om PostgreSQL met deze rol te kunnen installeren, moeten er een paar stappen worden uitgevoerd. Hier komt het Ansible Playbook. In Ansible Playbook kunnen we Ansible-code schrijven of een verzameling van de scripts die we op de beheerde knooppunten willen uitvoeren. Ansible Playbook gebruikt YAML en bestaat uit een of meer toneelstukken die in een bepaalde volgorde worden uitgevoerd. U kunt hosts definiëren, evenals een reeks taken die u op die toegewezen hosts of beheerde knooppunten wilt uitvoeren.
Alle taken worden uitgevoerd als de ansible-gebruiker die zich heeft aangemeld. Om de taken met een andere gebruiker, inclusief 'root', uit te voeren, kunnen we gebruik maken van word. Laten we eens kijken naar pg-play.yml hieronder:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Zoals je kunt zien, heb ik de hosts gedefinieerd als pgcluster en gebruik ik word zodat Ansible de taken uitvoert met het sudo-privilege. Gebruiker zwerver is al in de sudoer-groep. Ik heb ook de rol gedefinieerd die ik dudefellah.postgresql heb geïnstalleerd. pgcluster is gedefinieerd in het hosts-bestand dat ik heb gemaakt. Als je je afvraagt hoe het eruit ziet, kun je hieronder een kijkje nemen:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleDaarnaast heb ik nog een aangepast bestand (custom_var.yml) gemaakt waarin ik alle configuratie en instellingen voor PostgreSQL heb opgenomen die ik zou willen implementeren. De details voor het aangepaste bestand zijn als volgt:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Om de installatie uit te voeren, hoeven we alleen het volgende commando uit te voeren. U kunt de opdracht ansible-playbook niet uitvoeren zonder het gemaakte playbook-bestand (in mijn geval is dit pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostNadat ik dit commando heb uitgevoerd, zal het een paar taken uitvoeren die door de rol zijn gedefinieerd en dit bericht weergeven als het commando succesvol is uitgevoerd:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Zodra de ansible de taken had voltooid, logde ik in op de slave (n2), stopte de PostgreSQL-service, verwijderde de inhoud van de gegevensmap (/var/lib/pgsql/13/data/) en voer de volgende opdracht uit om de back-uptaak te starten:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |We kunnen ook de status van de replicatie in stand-by controleren met de volgende opdracht nadat we de PostgreSQL-service opnieuw hebben gestart:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyZoals je kunt zien, moet er nog veel gebeuren voordat we de replicatie voor PostgreSQL kunnen instellen, ook al hebben we sommige taken geautomatiseerd. Laten we eens kijken hoe dit kan worden bereikt met ClusterControl.
PostgreSQL-implementatie met ClusterControl GUI
Nu we weten hoe we PostgreSQL moeten implementeren met Ansible, gaan we kijken hoe we kunnen implementeren met ClusterControl. ClusterControl is beheer- en automatiseringssoftware voor databaseclusters, waaronder MySQL, MariaDB, MongoDB en TimescaleDB. Het helpt bij het implementeren, bewaken, beheren en schalen van uw databasecluster. Er zijn twee manieren om de database te implementeren. In deze blogpost laten we u zien hoe u deze implementeert met behulp van de grafische gebruikersinterface (GUI) ervan uitgaande dat u ClusterControl al op uw omgeving hebt geïnstalleerd.
De eerste stap is om in te loggen op uw ClusterControl en op Deploy te klikken:
U krijgt de onderstaande schermafbeelding te zien voor de volgende stap van de implementatie , kies het tabblad PostgreSQL om door te gaan:
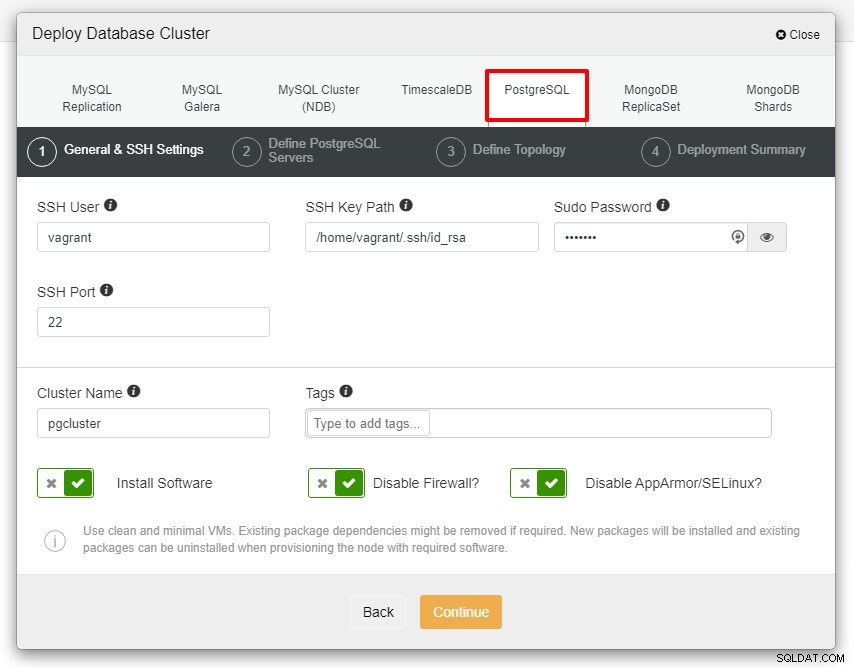
Voordat we verder gaan, wil ik u eraan herinneren dat de verbinding tussen het ClusterControl-knooppunt en de databaseknooppunten wachtwoordloos moet zijn. Voorafgaand aan de implementatie hoeven we alleen de ssh-keygen van het ClusterControl-knooppunt te genereren en deze vervolgens naar alle knooppunten te kopiëren. Vul de invoer in voor de SSH-gebruiker, het Sudo-wachtwoord en de clusternaam volgens uw vereisten en klik op Doorgaan.
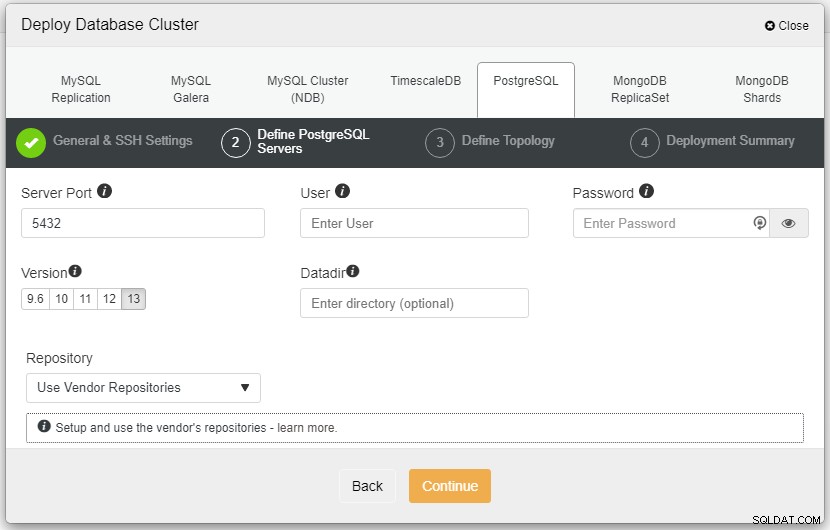
In de bovenstaande schermafbeelding moet u de serverpoort definiëren (voor het geval u anderen wilt gebruiken), de gebruiker die u wilt gebruiken, evenals het wachtwoord en de versie die u wilt te installeren.
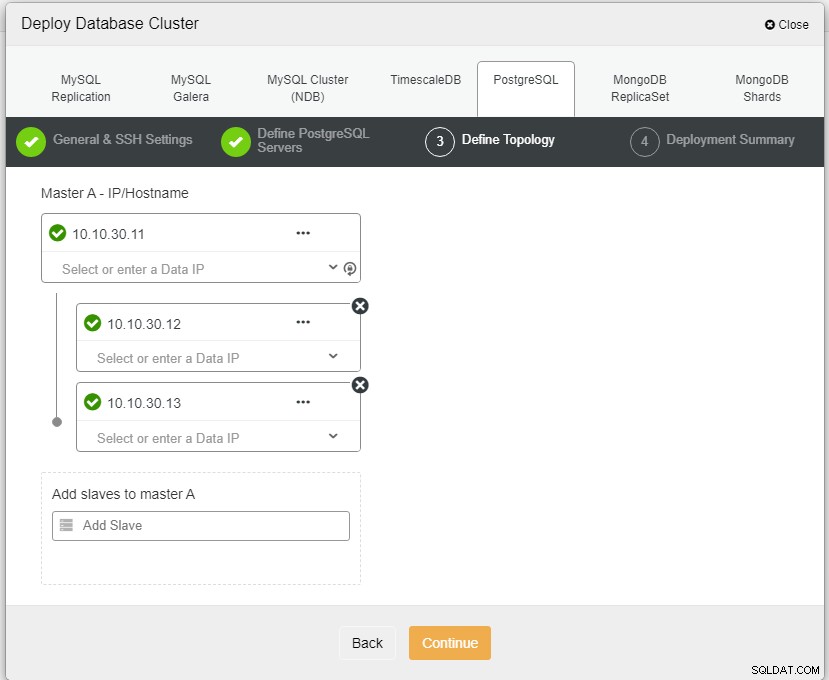
Hier moeten we de servers definiëren met behulp van de hostnaam of het IP-adres, zoals in dit geval 1 master en 2 slaves. De laatste stap is het kiezen van de replicatiemodus voor ons cluster.
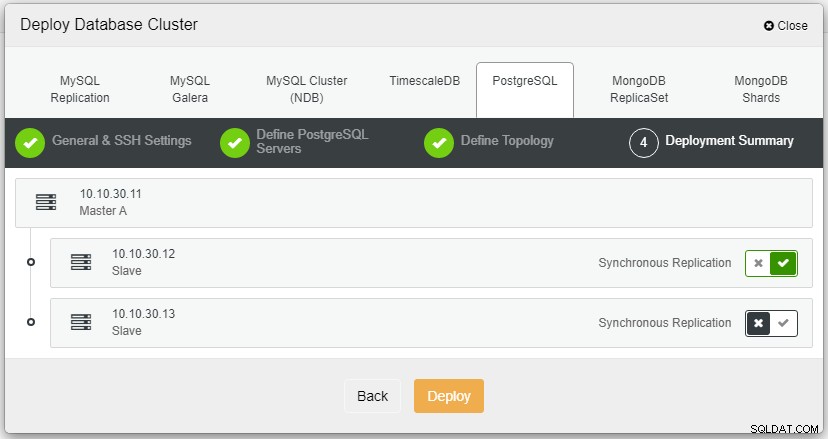
Nadat u op Implementeren heeft geklikt, wordt het implementatieproces gestart en kunnen we de voortgang volgen op het tabblad Activiteit.
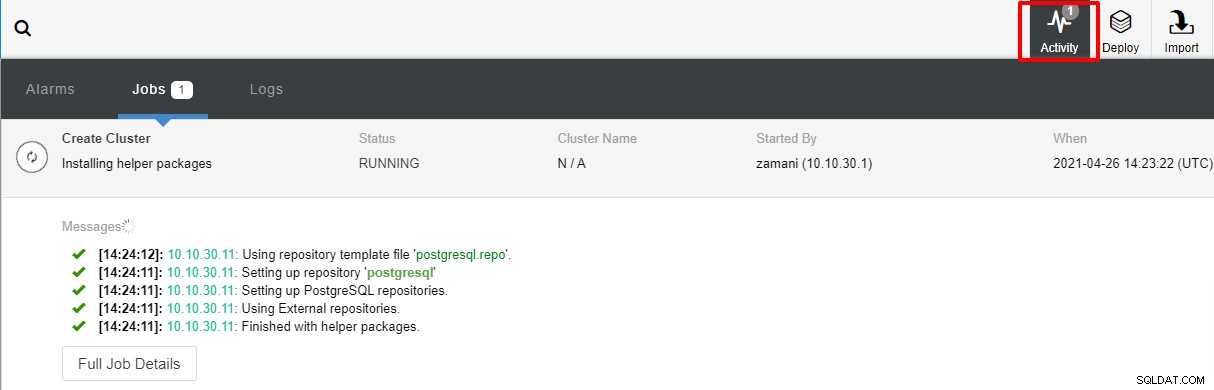
De implementatie duurt normaal gesproken een paar minuten, de prestaties hangen grotendeels af van het netwerk en de specificaties van de server.

Nu we PostgreSQL hebben geïnstalleerd met ClusterControl.
PostgreSQL-implementatie met ClusterControl CLI
De andere alternatieve manier om PostgreSQL te implementeren is door de CLI te gebruiken. op voorwaarde dat we de wachtwoordloze verbinding al hebben geconfigureerd, kunnen we gewoon de volgende opdracht uitvoeren en het laten eindigen.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logU zou het onderstaande bericht moeten zien zodra het proces met succes is voltooid en u kunt inloggen op de ClusterControl-web om te verifiëren:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Conclusie
Zoals je kunt zien zijn er een paar manieren om PostgreSQL te implementeren. In deze blogpost hebben we geleerd hoe we het kunnen implementeren met behulp van Ansible en met onze ClusterControl. Beide manieren zijn gemakkelijk te volgen en kunnen worden bereikt met een minimale leercurve. Met ClusterControl kan de streaming-replicatie-setup worden aangevuld met HAProxy, VIP en PGBouncer om verbindingsfailover, virtuele IP en pooling van verbindingen aan de setup toe te voegen.
Houd er rekening mee dat implementatie slechts één aspect is van een productiedatabaseomgeving. Het draaiende houden, failovers automatiseren, kapotte nodes herstellen en andere aspecten zoals monitoring, waarschuwingen en back-ups zijn essentieel.
Hopelijk zal deze blogpost sommigen van jullie ten goede komen en een idee geven over hoe PostgreSQL-implementaties te automatiseren.