Tegenwoordig is het vrij gebruikelijk om een database te laten repliceren in een andere server/datacenter, en in sommige gevallen is het ook een must. Er zijn verschillende redenen om uw databases te repliceren naar een totaal aparte omgeving.
- Migreren naar een ander datacenter.
- Vereisten voor upgraden (hardware/software).
- Behoud een volledig gesynchroniseerd operationeel systeem op een Disaster Recovery (DR)-site die het op elk moment kan overnemen
- Houd een slave-database bij als onderdeel van een goedkoper DR-plan.
- Voor vereisten voor geolocatie (gegevens moeten lokaal in een specifiek land zijn).
- Een testomgeving hebben.
- Probleemoplossing.
- Rapportagedatabase.
En er zijn verschillende manieren om deze replicatietaak uit te voeren:
- Back-up/herstel :Een back-up maken van een productiedatabase en deze terugzetten in een nieuwe server/omgeving is de klassieke manier om dit te doen, maar het is ook een ouderwetse manier omdat je je gegevens niet up-to-date houdt en je moet wachten voor elk herstelproces als u recente gegevens nodig hebt. Als je een cluster hebt (master-slave, multi-master), en als je het opnieuw wilt maken, moet je de eerste back-up herstellen en vervolgens de rest van de knooppunten opnieuw maken, wat een tijdrovende taak kan zijn.
- Clonecluster :Het is vergelijkbaar met het vorige, maar het back-up- en herstelproces is voor het hele cluster, niet alleen voor één specifieke databaseserver. Op deze manier kunt u het hele cluster in dezelfde taak klonen en hoeft u de rest van de knooppunten niet handmatig opnieuw te maken. Deze methode heeft nog steeds het probleem om gegevens tussen klonen up-to-date te houden.
- Replicatie :Deze manier omvat de optie voor back-up/herstel, maar na het eerste herstel zorgt het replicatieproces ervoor dat uw gegevens worden gesynchroniseerd met het hoofdknooppunt. Op deze manier moet u, als u een databasecluster heeft, de back-up terugzetten naar één knooppunt en alle knooppunten handmatig opnieuw maken.
In deze blog zullen we een nieuwe ClusterControl 1.7.4-functie zien waarmee je een mix van de eerder genoemde methode kunt gebruiken om deze taak te verbeteren.
Wat is cluster-naar-cluster replicatie?
Replicatie tussen twee clusters is niet hetzelfde als het uitbreiden van een cluster om over twee datacenters te draaien. Bij het opzetten van replicatie tussen twee clusters hebben we eigenlijk 2 aparte systemen die autonoom kunnen opereren. Replicatie wordt gebruikt om ze synchroon te houden, zodat het slave-systeem een bijgewerkte status heeft en het kan overnemen.
Vanuit ClusterControl 1.7.4 is het mogelijk om een nieuw cluster te maken door een actief broncluster direct te klonen, of door een recente back-up van het broncluster te gebruiken.
Na het klonen van de cluster, heb je een Slave Cluster (SC) die gegevens ontvangt en een Master Cluster (MC) die wijzigingen naar de slave verzendt.
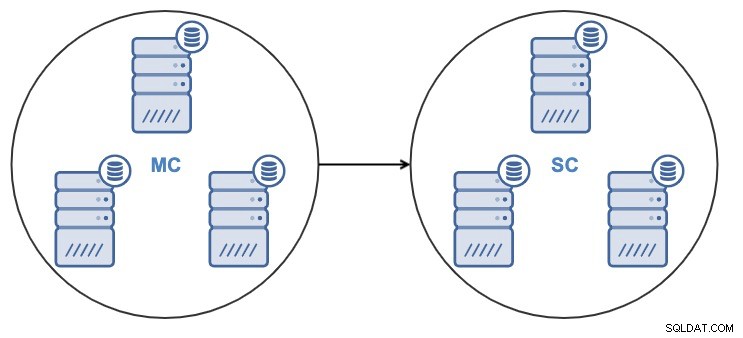
ClusterControl ondersteunt Cluster-naar-Cluster-replicatie voor de volgende clustertypen:
- Percona XtraDB Cluster versie 5.6.x en hoger.
- MariaDB Galera Cluster versie 10.x en hoger.
- PostgreSQL 9.6 en hoger.
Cluster-naar-clusterreplicatie voor Percona XtraDB / MariaDB Galera-cluster
Voor op MySQL gebaseerde engines is GTID vereist om deze functie te gebruiken en wordt asynchrone replicatie tussen het Master- en Slave-cluster gebruikt.
Er zijn een aantal acties die moeten worden uitgevoerd om het huidige cluster voor te bereiden op deze taak. Ten eerste moet op ten minste één knooppunt op het huidige cluster de binaire logboeken zijn ingeschakeld. Vervolgens moet u de back-upgebruiker die is geconfigureerd in het databaseknooppunt toevoegen aan het ClusterControl-configuratiebestand, dat zal worden gebruikt voor beheertaken. Al deze acties kunnen worden uitgevoerd met behulp van de ClusterControl UI of ClusterControl CLI.
Nu bent u klaar om de Percona XtraDB/MariaDB Galera Cluster-naar-Cluster-replicatie te maken. Wanneer de taak is voltooid, beschikt u over:
- Eén knooppunt in het slavecluster wordt gerepliceerd vanaf één knooppunt in het hoofdcluster.
- De replicatie zal bidirectioneel zijn tussen de clusters.
- Alle knooppunten in het slavecluster zijn standaard alleen-lezen. Het is mogelijk om de alleen-lezen vlag op de knooppunten één voor één uit te schakelen.
- Active-Active clustering wordt alleen aanbevolen als applicaties alleen disjuncte datasets op beide clusters raken, aangezien de engine geen conflictdetectie of -oplossing biedt.
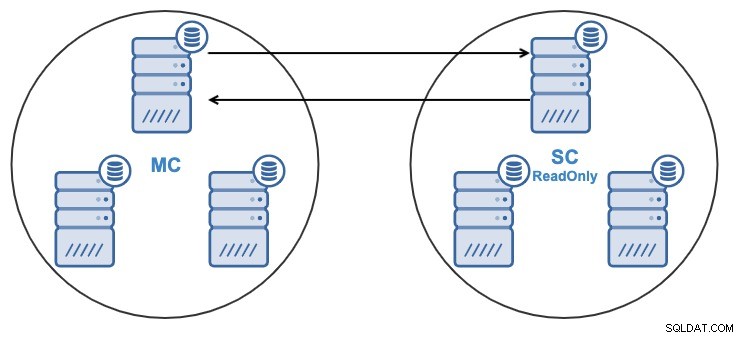
Van zowel de ClusterControl UI als de ClusterControl CLI kunt u:
- Maak dit replicatiecluster.
- Activeer de Active-Active-configuratie.
- Wijzig de clustertopologie.
- Een replicatiecluster opnieuw opbouwen.
- Stop/start een replicatieslave.
- Reset Replication Slave (alleen geïmplementeerd met ClusterControl CLI atm).
Overwegingen
- De back-upgebruiker moet handmatig worden toegevoegd in het ClusterControl-configuratiebestand.
- De inloggegevens van de back-upgebruiker moeten hetzelfde zijn in zowel het huidige als het nieuwe cluster.
- Het MySQL-rootwachtwoord dat is opgegeven bij het maken van het slavecluster, moet hetzelfde zijn als het rootwachtwoord dat voor het mastercluster wordt gebruikt.
Bekende beperkingen
- Automatische failover wordt nog niet ondersteund. Als de master faalt, is het de verantwoordelijkheid van de beheerder om een failover naar een andere master uit te voeren.
- Het is alleen mogelijk om een replicatieslave te "RESET" vanuit de ClusterControl CLI omdat deze nog niet is geïmplementeerd in de ClusterControl UI.
- Het is alleen mogelijk om een cluster opnieuw op te bouwen in de alleen-lezen modus. Alle knooppunten in een cluster moeten alleen-lezen zijn om als alleen-lezen cluster te tellen.
Cluster-naar-clusterreplicatie voor PostgreSQL
ClusterControl Cluster-naar-Cluster-replicatie wordt ondersteund op PostgreSQL met behulp van streaming-replicatie.
Als vereiste moet er een PostgreSQL-server zijn met de ClusterControl-rol 'master', en wanneer u het slavecluster instelt, moeten de beheerdersreferenties identiek zijn aan het mastercluster.
Nu bent u klaar om de PostgreSQL Cluster-naar-Cluster-replicatie te maken. Wanneer de taak is voltooid, beschikt u over:
- Eén knooppunt in het slavecluster wordt gerepliceerd vanaf één knooppunt in het hoofdcluster.
- De replicatie zal unidirectioneel zijn tussen de clusters.
- Het knooppunt in het slavecluster is alleen-lezen.
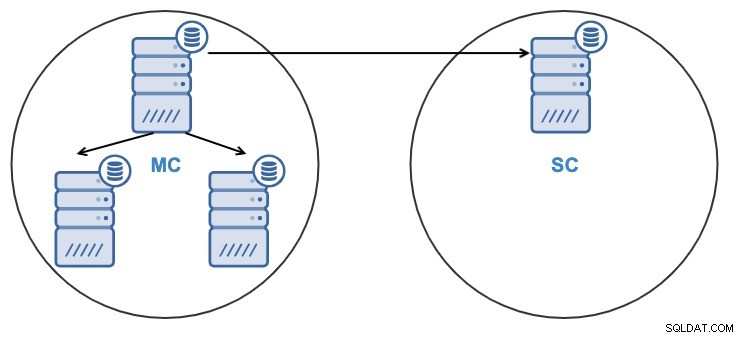
Van zowel de ClusterControl UI als de ClusterControl CLI kunt u:
- Maak dit replicatiecluster.
- Een replicatiecluster opnieuw opbouwen.
- Stop/start een replicatieslave.
Overweging
- De beheerdersreferenties moeten identiek zijn in het master- en slavecluster.
Bekende beperkingen
- De maximale grootte van het slavecluster is één knoop.
- Het Slave-cluster kan niet worden gestaged vanuit een back-up.
- Wijzigingen in de topologie worden niet ondersteund.
- Alleen unidirectionele replicatie wordt ondersteund.
Conclusie
Met deze nieuwe ClusterControl-functie hoeft u niet elke stap afzonderlijk of handmatig uit te voeren om een Clusterreplicatie te maken, en als resultaat van het gebruik ervan bespaart u tijd en moeite. Probeer het eens!