Failover is het vermogen van een systeem om door te blijven werken, zelfs als er een storing optreedt. Het suggereert dat de functies van het systeem worden overgenomen door secundaire componenten als de primaire componenten falen of als dit nodig is. Dus als u het vertaalt naar een PostgreSQL multi-cloudomgeving, betekent dit dat wanneer uw primaire knooppunt faalt (of een andere reden die we in de volgende sectie zullen noemen) in uw primaire cloudprovider, u het stand-byknooppunt moet kunnen promoten in de secundaire om de systemen draaiende te houden.
Over het algemeen bieden alle cloudproviders u een failover-optie in dezelfde cloudprovider, maar het kan zijn dat u een failover naar een andere, andere cloudprovider moet uitvoeren. U kunt dit natuurlijk handmatig doen, maar u kunt ook enkele van de ClusterControl-functies gebruiken, zoals automatische failover of slavenactie promoten om dit op een vriendelijke en gemakkelijke manier te doen.
In deze blog ziet u waarom u een failover nodig heeft, hoe u dit handmatig doet en hoe u ClusterControl voor deze taak gebruikt. We gaan ervan uit dat u een ClusterControl-installatie hebt uitgevoerd en dat uw databasecluster al in twee verschillende cloudproviders is gemaakt.
Waar wordt failover voor gebruikt?
Er zijn verschillende mogelijke toepassingen van failover.
Hoofdfout
Als uw primaire node niet beschikbaar is of zelfs als uw belangrijkste cloudprovider problemen heeft, moet u een failover uitvoeren om de beschikbaarheid van uw systeem te garanderen. In dit geval kan het nodig zijn om dit op een automatische manier te doen om de uitvaltijd te verminderen.
Migratie
Als u uw systemen van de ene Cloud Provider naar de andere wilt migreren door uw downtime te minimaliseren, kunt u failover gebruiken. U kunt een replica maken in de secundaire cloudprovider en zodra deze is gesynchroniseerd, moet u uw systeem stoppen, uw replica en failover promoten voordat u uw systeem naar het nieuwe primaire knooppunt in de secundaire cloudprovider verwijst.
Onderhoud
Als u een onderhoudstaak moet uitvoeren op uw primaire PostgreSQL-knooppunt, kunt u uw replica promoten, de taak uitvoeren en uw oude primaire knooppunt opnieuw opbouwen als een stand-by-knooppunt.
Hierna kunt u de oude primary promoveren en het herbouwproces herhalen op de standby-node, waarbij u terugkeert naar de oorspronkelijke staat.
Op deze manier kunt u op uw server werken, zonder het risico te lopen offline te zijn of informatie te verliezen tijdens het uitvoeren van onderhoudstaken.
Upgrades
Het is mogelijk om uw PostgreSQL-versie te upgraden (sinds PostgreSQL 10) of zelfs uw besturingssysteem te upgraden door middel van logische replicatie zonder downtime, zoals het kan met andere engines.
De stappen zijn hetzelfde als bij het migreren naar een nieuwe Cloud Provider, alleen dat uw replica zich in een nieuwere PostgreSQL- of OS-versie bevindt en dat u logische replicatie moet gebruiken omdat u geen streaming kunt gebruiken replicatie tussen verschillende versies.
Failover gaat niet alleen over de database, maar ook over de applicatie. Hoe weten ze met welke database ze verbinding moeten maken? U wilt waarschijnlijk niet dat u uw toepassing hoeft aan te passen, omdat dit uw downtime alleen maar verlengt, dus u kunt een Load Balancer configureren die wanneer uw primaire node niet beschikbaar is, deze automatisch naar de server verwijst die is gepromoveerd.
Het hebben van één enkele Load Balancer-instantie is niet de beste optie, omdat dit een single point of failure kan worden. Daarom kunt u ook een failover voor de Load Balancer implementeren met behulp van een service als Keepalive. Op deze manier, als je een probleem hebt met je primaire Load Balancer, zal Keepalived het virtuele IP migreren naar je secundaire Load Balancer, en alles blijft transparant werken.
Een andere optie is het gebruik van DNS. Door het stand-byknooppunt in de secundaire cloudprovider te promoten, wijzigt u rechtstreeks het IP-adres van de hostnaam dat naar het primaire knooppunt verwijst. Zo voorkom je dat je je applicatie moet aanpassen, en hoewel het niet automatisch kan, is het een alternatief als je geen Load Balancer wilt implementeren.
Handmatig een failover van PostgreSQL
Voordat u een handmatige failover uitvoert, moet u de replicatiestatus controleren. Het kan zijn dat, wanneer u een failover moet uitvoeren, het standby-knooppunt niet up-to-date is vanwege een netwerkstoring, hoge belasting of een ander probleem, dus u moet ervoor zorgen dat uw standby-knooppunt alle (of bijna alle informatie. Als u meer dan één stand-by-knooppunt heeft, moet u ook controleren welke het meest geavanceerde knooppunt is en deze kiezen voor failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Als u het nieuwe primaire knooppunt kiest, kunt u eerst de opdracht pg_lsclusters uitvoeren om de clusterinformatie op te halen:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logVervolgens hoef je alleen maar de opdracht pg_ctlcluster uit te voeren met de actie promo:
$ pg_ctlcluster 12 main promoteIn plaats van het vorige commando, kun je het pg_ctl commando op deze manier uitvoeren:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedVervolgens wordt uw standby-knooppunt gepromoveerd tot primair knooppunt en kunt u het valideren door de volgende query uit te voeren in uw nieuwe primaire knooppunt:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Als het resultaat "f" is, is dit uw nieuwe primaire node.
Nu moet u het IP-adres van de primaire database in uw toepassing, Load Balancer, DNS of de implementatie die u gebruikt wijzigen. Zoals we al zeiden, zal het handmatig wijzigen hiervan de downtime vergroten. U moet er ook voor zorgen dat uw connectiviteit tussen de providers goed werkt, dat de toepassing toegang heeft tot het nieuwe primaire knooppunt, dat de toepassingsgebruiker toegangsrechten heeft vanaf een andere cloudprovider en dat u de stand-by-knooppunten opnieuw moet opbouwen in de externe of zelfs in de lokale cloudprovider, om te repliceren vanaf de nieuwe primaire, anders heeft u indien nodig geen nieuwe failover-optie.
Failover van PostgreSQL met ClusterControl
ClusterControl heeft een aantal functies met betrekking tot PostgreSQL-replicatie en geautomatiseerde failover. We gaan ervan uit dat u uw ClusterControl-server hebt geïnstalleerd en dat deze uw Multi-Cloud PostgreSQL-omgeving beheert.
Met ClusterControl kunt u zoveel stand-by-knooppunten of Load Balancer-knooppunten toevoegen als u nodig hebt, zonder enige netwerk-IP-beperking. Het betekent dat het niet nodig is dat de standby-node zich in hetzelfde primaire node-netwerk of zelfs in dezelfde cloudprovider bevindt. Wat betreft failover stelt ClusterControl u in staat om dit handmatig of automatisch te doen.
Handmatige failover
Als u een handmatige failover wilt uitvoeren, gaat u naar ClusterControl -> Cluster selecteren -> Knooppunten en selecteert u in de Knooppuntacties van een van uw standby-knooppunten "Slaaf promoten".
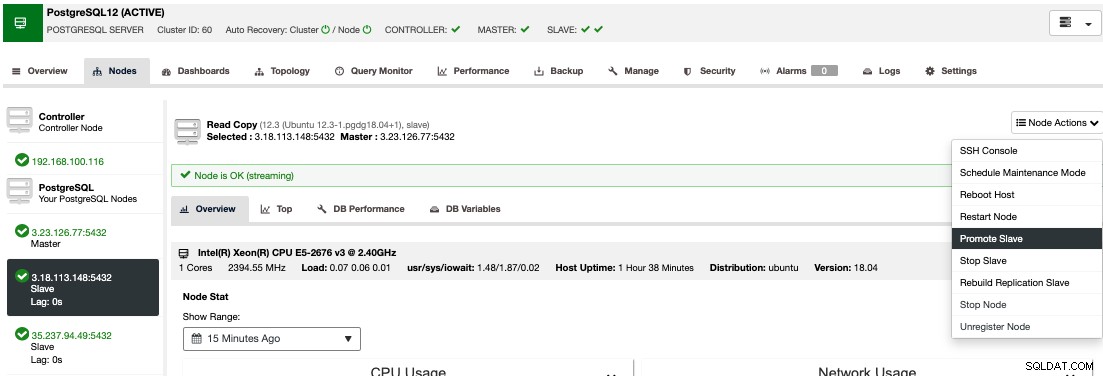
Op deze manier wordt uw standby-knooppunt na een paar seconden primair, en wat voorheen uw primaire was, wordt omgezet in een stand-by. Dus als uw replica zich in een andere cloudprovider bevond, zal uw nieuwe primaire node daar zijn, in gebruik.
Automatische failover
In het geval van automatische failover detecteert ClusterControl fouten in het primaire knooppunt en bevordert het een stand-by-knooppunt met de meest actuele gegevens als het nieuwe primaire knooppunt. Het werkt ook op de rest van de standby-knooppunten om ze te repliceren vanaf deze nieuwe primaire.

Als de optie "Autoherstel" is ingeschakeld, voert ClusterControl een automatische failover uit als en u op de hoogte stellen van het probleem. Op deze manier kunnen uw systemen binnen enkele seconden en zonder uw tussenkomst herstellen.
ClusterControl biedt u de mogelijkheid om een whitelist/blacklist te configureren om te bepalen hoe u wilt dat uw servers al dan niet in aanmerking worden genomen bij het kiezen van een primaire kandidaat.
ClusterControl voert ook verschillende controles uit op het failover-proces, bijvoorbeeld, als het u lukt om uw oude defecte primaire node te herstellen, wordt deze niet automatisch opnieuw in het cluster geïntroduceerd, noch als primaire noch als primaire node. als stand-by moet u dit handmatig doen. Dit voorkomt de mogelijkheid van gegevensverlies of inconsistentie in het geval dat uw stand-by (die u heeft gepromoot) werd vertraagd op het moment van de storing. Misschien wilt u het probleem ook in detail analyseren, maar als u het aan uw cluster toevoegt, verliest u mogelijk diagnostische informatie.
Loadbalancers
Zoals we eerder vermeldden, is de Load Balancer een belangrijk hulpmiddel voor uw failover, vooral als u automatische failover in uw databasetopologie wilt gebruiken.
Om de failover transparant te maken voor zowel de gebruiker als de applicatie, heb je een component ertussen nodig, aangezien het niet voldoende is om een nieuwe primaire node te promoten. Hiervoor kunt u HAProxy + Keepalived gebruiken.
Als u deze oplossing met ClusterControl wilt implementeren, gaat u naar Clusteracties -> Load Balancer toevoegen -> HAProxy op uw PostgreSQL-cluster. In het geval dat u failover voor uw Load Balancer wilt implementeren, moet u ten minste twee HAProxy-instanties configureren en vervolgens kunt u Keepalive configureren (Clusteracties -> Load Balancer toevoegen -> Keepalive). Meer informatie over deze implementatie vind je in deze blogpost.
Hierna heeft u de volgende topologie:

HAProxy is standaard geconfigureerd met twee verschillende poorten, één lezen-schrijven en één alleen-lezen.
In de read-write-poort heb je je primaire node als online en de rest van de nodes als offline. In de alleen-lezen-poort hebt u zowel de primaire als de standby-knooppunten online. Op deze manier kunt u het leesverkeer tussen de knooppunten balanceren. Bij het schrijven wordt de lees-schrijfpoort gebruikt, die naar het huidige primaire knooppunt verwijst.

Als HAProxy detecteert dat een van de nodes, primair of stand-by, niet toegankelijk is, wordt het automatisch gemarkeerd als offline. HAProxy zal er geen verkeer naartoe sturen. Deze controle wordt uitgevoerd door scripts voor gezondheidscontrole die zijn geconfigureerd door ClusterControl op het moment van implementatie. Deze controleren of de instanties actief zijn, of ze worden hersteld of alleen-lezen zijn.
Als ClusterControl een nieuw primair knooppunt promoot, markeert HAProxy het oude als offline (voor beide poorten) en plaatst het het gepromote knooppunt online in de lees-schrijfpoort. Op deze manier blijven uw systemen normaal werken.
Als de actieve HAProxy (die een virtueel IP-adres heeft toegewezen waarmee uw systemen verbinding maken) faalt, migreert Keepalive deze virtuele IP automatisch naar de passieve HAProxy. Dit betekent dat uw systemen dan normaal kunnen blijven functioneren.
Cluster-naar-clusterreplicatie in de cloud
Als u een Multi-Cloud-omgeving wilt hebben, kunt u de actie ClusterControl Slave toevoegen over uw PostgreSQL-cluster gebruiken, maar ook de functie Cluster-naar-clusterreplicatie. Op dit moment heeft deze functie een beperking voor PostgreSQL, waardoor u slechts één extern knooppunt kunt hebben, maar we werken eraan om die beperking binnenkort in een toekomstige release te verwijderen.
Als u het wilt implementeren, kunt u het gedeelte 'Cluster-naar-clusterreplicatie in de cloud' in deze blogpost bekijken.

Als het aanwezig is, kunt u het externe cluster promoten dat zal een onafhankelijk PostgreSQL-cluster met een primaire node die draait op de secundaire cloudprovider.

Dus, voor het geval je het nodig hebt, heb je hetzelfde cluster actief binnen enkele seconden in een nieuwe cloudprovider.
Conclusie
Het hebben van een automatisch failover-proces is verplicht als je zo min mogelijk downtime wilt hebben, en ook het gebruik van verschillende technologieën zoals HAProxy en Keepalived zal deze failover verbeteren.
Met de ClusterControl-functies die we hierboven noemden, kunt u snel een failover tussen verschillende cloudproviders uitvoeren en de installatie op een gemakkelijke en vriendelijke manier beheren.
Het belangrijkste om rekening mee te houden voordat een failover-proces tussen verschillende cloudproviders wordt uitgevoerd, is de connectiviteit. U moet ervoor zorgen dat uw applicatie of uw databaseverbindingen zoals gewoonlijk werken met behulp van de hoofd- maar ook de secundaire cloudprovider in geval van failover, en om veiligheidsredenen moet u het verkeer alleen van bekende bronnen beperken, dus alleen tussen de Cloud Providers en laat het niet toe vanaf een externe bron.