Het gebruik van een multicloud- of multidatacenteromgeving is handig voor geo-gedistribueerde topologieën of zelfs voor een rampherstelplan, en eigenlijk wordt het tegenwoordig steeds populairder, daarom is het concept van split-brain wordt ook belangrijker naarmate het risico om het te krijgen in dit soort scenario's toeneemt. U moet een gespleten brein voorkomen om mogelijk gegevensverlies of gegevensinconsistentie te voorkomen, wat een groot probleem voor het bedrijf zou kunnen zijn.
In deze blog zullen we zien wat een split-brain is en hoe ClusterControl je kan helpen dit belangrijke probleem te vermijden.
Wat is Split-Brain?
In de PostgreSQL-wereld vindt split-brain plaats wanneer meer dan één primaire node tegelijkertijd beschikbaar is (zonder een tool van derden om een multi-masteromgeving te hebben) waarmee de applicatie kan schrijven in beide knooppunten. In dit geval heeft u verschillende informatie over elk knooppunt, wat inconsistentie in de gegevens in het cluster genereert. Het oplossen van dit probleem kan moeilijk zijn, omdat u gegevens moet samenvoegen, iets wat soms niet mogelijk is.
PostgreSQL Split-Brain in een multi-cloudtopologie
Stel dat je de volgende multi-cloud-topologie voor PostgreSQL hebt (wat tegenwoordig een vrij veel voorkomende topologie is):
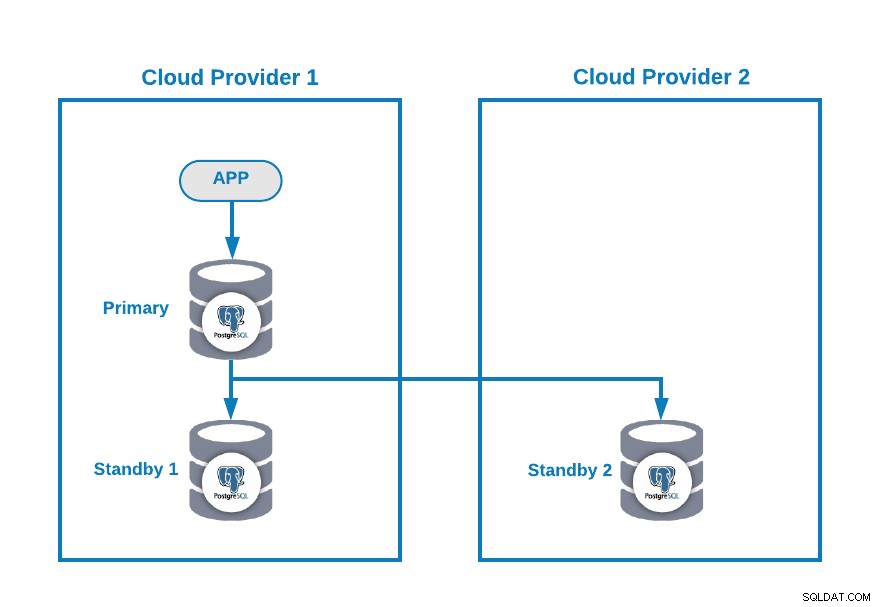
Natuurlijk kunt u deze omgeving verbeteren door bijvoorbeeld een Application Server in de Cloud Provider 2, maar laten we in dit geval deze basisconfiguratie gebruiken.
Als uw primaire knooppunt niet beschikbaar is, moet een van de standby-knooppunten worden gepromoot als een nieuw primair knooppunt en moet u het IP-adres in uw toepassing wijzigen om dit nieuwe primaire knooppunt te gebruiken.
Er zijn verschillende manieren om dit op een automatische manier te doen. U kunt bijvoorbeeld een virtueel IP-adres gebruiken dat is toegewezen aan uw primaire knooppunt en dit bewaken. Als het niet lukt, promoveer dan een van de standby-knooppunten en migreer het virtuele IP-adres naar dit nieuwe primaire knooppunt, zodat u niets hoeft te wijzigen in uw toepassing, en dit kan worden gedaan met uw eigen script of tool.
Op dit moment heb je geen probleem, maar... als je oude primaire node terugkomt, moet je ervoor zorgen dat je niet twee primaire nodes tegelijkertijd in hetzelfde cluster hebt .
De meest gebruikelijke methoden om deze situatie te voorkomen zijn:
- STONITH:Schiet de andere knoop in het hoofd.
- SMITH:Schiet mezelf in het hoofd.
PostgreSQL biedt geen enkele manier om dit proces te automatiseren. Je moet het zelf maken.
Gesplitste hersenen in PostgreSQL vermijden met ClusterControl
Laten we nu eens kijken hoe ClusterControl u kan helpen met deze taak.
Ten eerste kun je het gebruiken om je PostgreSQL Multi-Cloud-omgeving op een gemakkelijke manier te implementeren of importeren, zoals je kunt zien in deze blogpost.
Vervolgens kunt u uw topologie verbeteren door een Load Balancer (HAProxy) toe te voegen, wat u ook kunt doen met ClusterControl na deze blog. Je krijgt dus zoiets als dit:
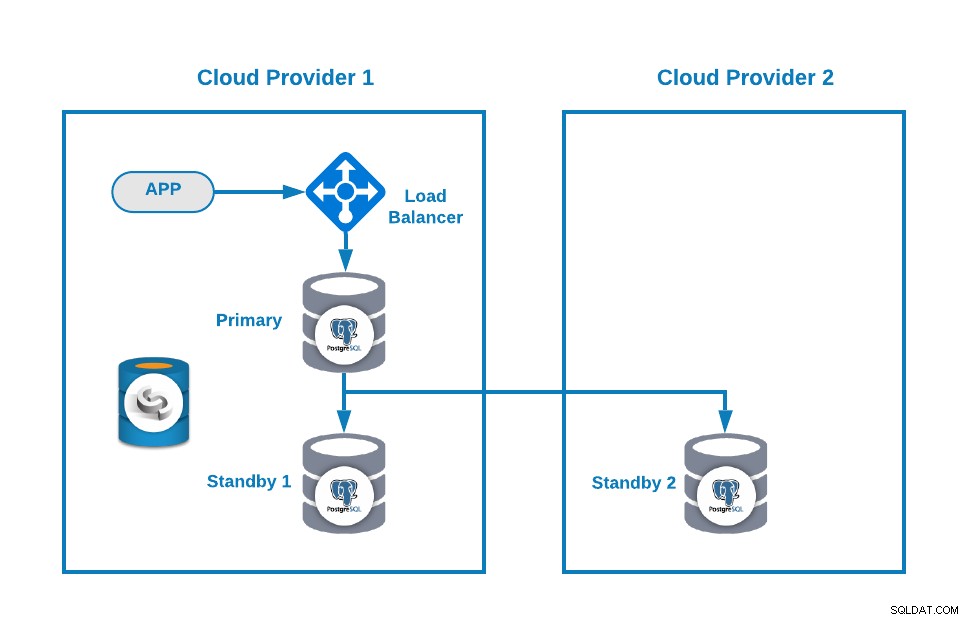
ClusterControl heeft een auto-failover-functie die hoofdfouten detecteert en een stand-by bevordert knooppunt met de meest actuele gegevens als nieuwe primaire. Het faalt ook om de rest van de standby-knooppunten te repliceren vanaf het nieuwe primaire knooppunt.
HAProxy wordt standaard door ClusterControl geconfigureerd met twee verschillende poorten, één lezen-schrijven en één alleen-lezen. In de read-write-poort heb je je primaire node als online en de rest van je nodes als offline, en in de read-only-poort heb je zowel de primaire als de standby-nodes online. Op deze manier kunt u het leesverkeer tussen uw knooppunten balanceren, maar u zorgt ervoor dat op het moment van schrijven de lees-schrijfpoort wordt gebruikt, die schrijft in het primaire knooppunt dat de server is die online is.
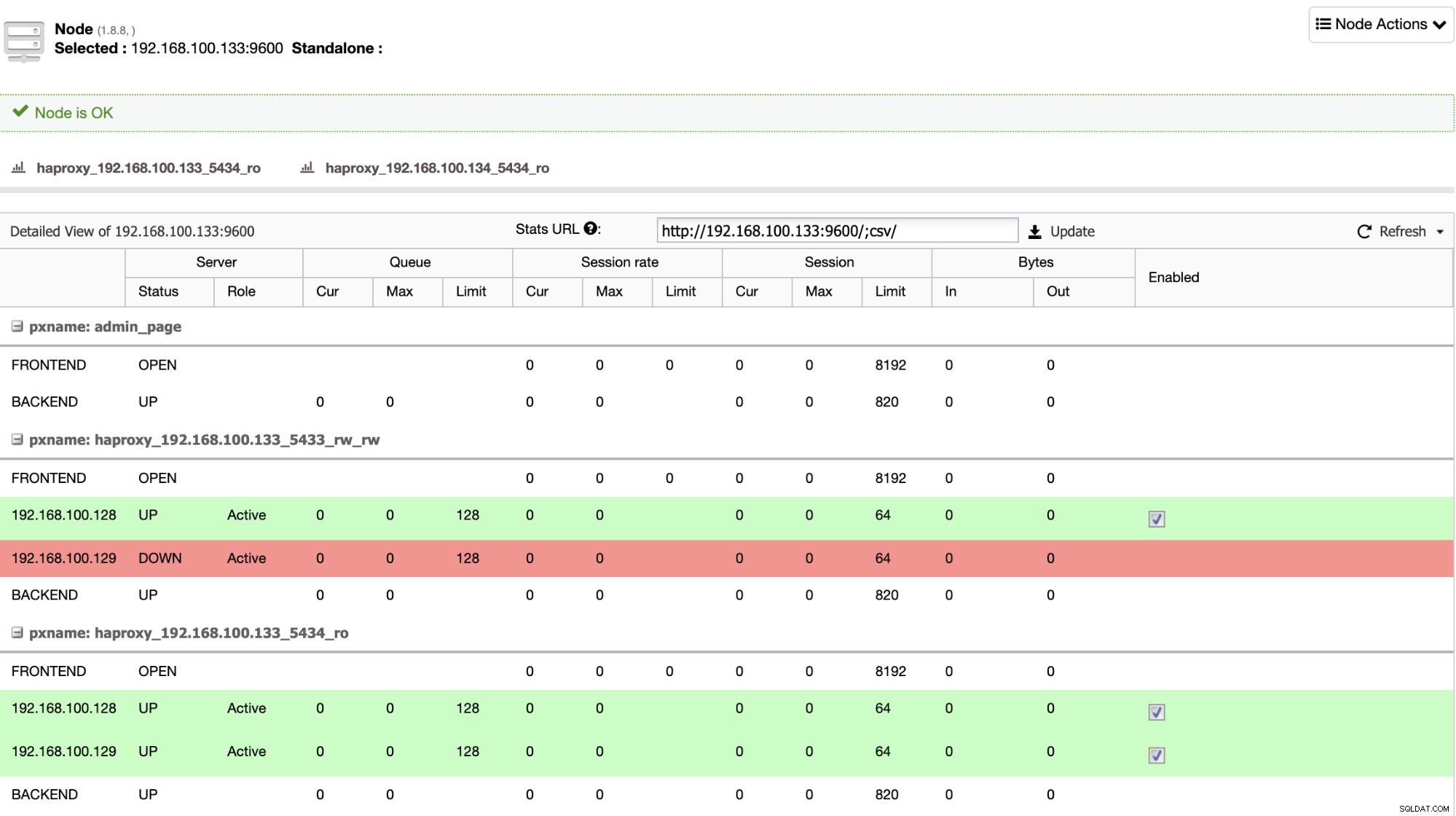
Wanneer HAProxy detecteert dat een van uw nodes, primair of stand-by, niet toegankelijk is, markeert het het automatisch als offline en houdt het geen rekening met het verzenden van verkeer ernaar. Deze controle wordt uitgevoerd door scripts voor gezondheidscontrole die zijn geconfigureerd door ClusterControl op het moment van implementatie. Deze controleren of de instances actief zijn, of ze worden hersteld of alleen-lezen zijn.
Als uw oude primaire knooppunt terugkomt, zal ClusterControl ook vermijden om het te starten, om een mogelijke split-brain te voorkomen in het geval u een directe verbinding heeft die de Load Balancer niet gebruikt, maar u kunt deze toevoegen automatisch of handmatig naar het cluster als een stand-by-knooppunt met behulp van de ClusterControl UI of CLI, dan kunt u het promoten zodat het dezelfde topologie heeft die u had voor het probleem.
Conclusie
Als de optie "Autorecovery" AAN staat, zal ClusterControl deze automatische failover uitvoeren en u op de hoogte stellen van het probleem. Op deze manier kunnen uw systemen binnen enkele seconden herstellen zonder uw tussenkomst en voorkomt u een split-brain in een PostgreSQL Multi-Cloud-omgeving.
U kunt uw High Availability-omgeving ook verbeteren door meer ClusterControl-nodes toe te voegen met behulp van de CMON HA-functie die in deze blog wordt beschreven.