Relationele databases vertegenwoordigen de gegevens van een organisatie in tabellen die kolommen met verschillende gegevenstypen gebruiken, zodat ze geldige waarden kunnen opslaan. Ontwikkelaars en DBA's moeten het juiste gegevenstype voor elke kolom kennen en begrijpen voor betere queryprestaties.
Dit artikel behandelt de populaire gegevenstypen VARCHAR() en NVARCHAR(), hun vergelijking en prestatiebeoordelingen in SQL Server.
VARCHAR [ ( n | max ) ] in SQL
De VARCHAR gegevenstype staat voor de niet-Unicode gegevenstype tekenreeks met variabele lengte. U kunt er letters, cijfers en speciale tekens in opslaan.
- N vertegenwoordigt de tekenreeksgrootte in bytes.
- In de kolom VARCHAR-gegevenstype kunnen maximaal 8000 niet-Unicode-tekens worden opgeslagen.
- Het VARCHAR-gegevenstype neemt 1 byte per teken in beslag. Als u de waarde voor N niet expliciet opgeeft, neemt het 1-byte opslag in beslag.
Opmerking:Verwar N . niet met een waarde die het aantal tekens in een tekenreeks vertegenwoordigt.
De volgende query definieert het VARCHAR-gegevenstype met 100 bytes aan gegevens.
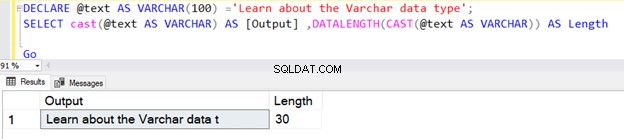
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Het retourneert de lengte als 17 vanwege 1 byte per teken, inclusief een spatie.
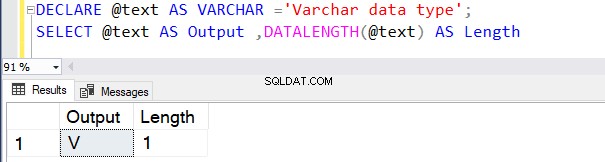
De volgende query definieert het VARCHAR-gegevenstype zonder enige waarde van N . Daarom beschouwt SQL Server de standaardwaarde als 1 byte, zoals hieronder weergegeven.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
We kunnen VARCHAR ook gebruiken met de CAST- of CONVERT-functie. In de onderstaande twee voorbeelden hebben we bijvoorbeeld een variabele met een lengte van 100 bytes gedeclareerd en later de CAST-operator gebruikt.
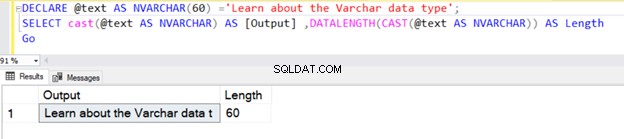
De eerste query retourneert de lengte als 30 omdat we N niet hebben opgegeven in het gegevenstype CAST-operator VARCHAR. De standaardlengte is 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Als de stringlengte echter minder dan 30 is, neemt het de werkelijke grootte van de string aan.

NVARCHAR [ ( n | max ) ] in SQL
De NVARCHAR gegevenstype is voor de Unicode karaktergegevenstype met variabele lengte. Hier verwijst N naar National Language Character Set en wordt gebruikt om de Unicode-string te definiëren. U kunt zowel niet-Unicode- als Unicode-tekens opslaan (Japanse Kanji, Koreaanse Hangul, enz.).
- N vertegenwoordigt de tekenreeksgrootte in bytes.
- Het kan maximaal 4000 Unicode- en niet-Unicode-tekens opslaan.
- Het VARCHAR-gegevenstype neemt 2 bytes per teken in beslag. Er is 2 bytes opslagruimte nodig als u geen waarde opgeeft voor N.
De volgende query definieert het VARCHAR-gegevenstype met 100 bytes aan gegevens.
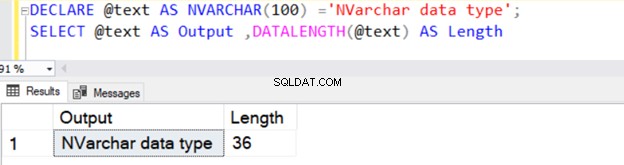
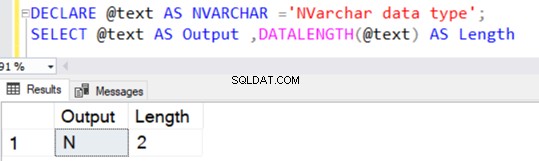
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Het retourneert de tekenreekslengte van 36 omdat NVARCHAR 2 bytes per tekenopslag in beslag neemt.
Net als het VARCHAR-gegevenstype heeft NVARCHAR ook een standaardwaarde van 1 teken (2 bytes) zonder een expliciete waarde voor N op te geven.
Als we de NVARCHAR-conversie toepassen met behulp van de CAST- of CONVERT-functie zonder enige expliciete waarde van N, is de standaardwaarde 30 tekens, d.w.z. 60 bytes.
De Unicode- en niet-Unicode-waarden opslaan in VARCHAR-gegevenstype
Stel dat we een tabel hebben waarin de feedback van klanten van een e-shoppingportal wordt vastgelegd. Voor dit doel hebben we een SQL-tabel met de volgende query.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
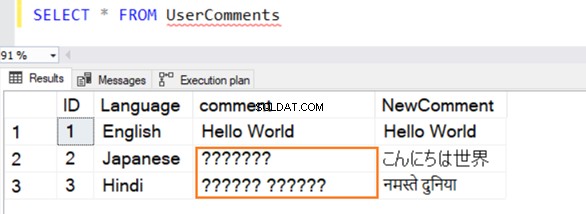
We voegen verschillende voorbeeldrecords in deze tabel in het Engels, Japans en Hindi in. Het gegevenstype voor [Commentaar] is VARCHAR en [NewComment] is NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
De query wordt met succes uitgevoerd en geeft de volgende rijen terwijl er een waarde uit wordt geselecteerd. Voor rij 2 en 3 herkent het geen gegevens als het niet in het Engels is.
VARCHAR- en NVARCHAR-gegevenstypen:prestatievergelijking
We moeten het gebruik van VARCHAR- en NVARCHAR-gegevenstypen in de JOIN- of WHERE-predikaten niet combineren. Het maakt de bestaande indexen ongeldig omdat SQL Server aan beide zijden van JOIN dezelfde gegevenstypen vereist. SQL Server probeert de impliciete conversie uit te voeren met behulp van de functie CONVERT_IMPLICIT() in het geval van een mismatch.
SQL Server gebruikt de prioriteit van het gegevenstype om te bepalen wat het doelgegevenstype is. NVARCHAR heeft een hogere prioriteit dan het gegevenstype VARCHAR. Daarom converteert SQL Server tijdens de conversie van het gegevenstype de bestaande VARCHAR-waarden naar NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Laten we nu twee SELECT-instructies uitvoeren die records ophalen volgens hun gegevenstype.
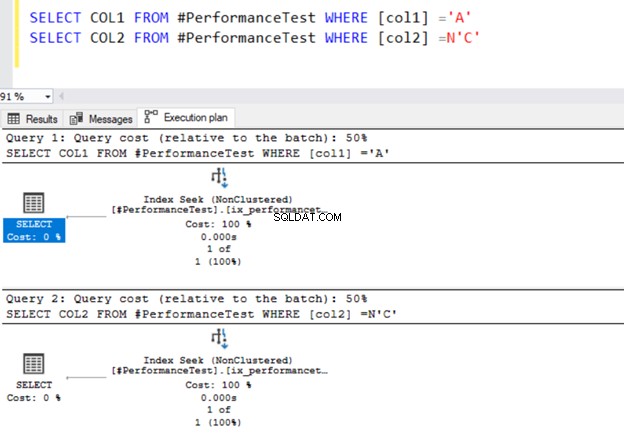
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Beide zoekopdrachten gebruiken de Index-zoekoperator en de indexen die we eerder hebben gedefinieerd.
Nu schakelen we de gegevenstypewaarden voor vergelijking om naar het WHERE-predikaat. Kolom 1 heeft een VARCHAR-gegevenstype, maar we specificeren N'A' om het als NVARCHAR-gegevenstype te plaatsen.
Evenzo is col2 het NVARCHAR-gegevenstype en specificeren we de waarde 'C' die verwijst naar het VARCHAR-gegevenstype.
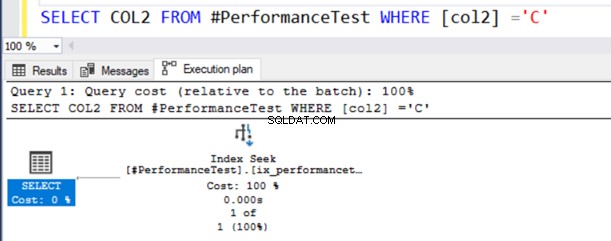
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'In het daadwerkelijke uitvoeringsplan van de query krijgt u een Index-scan en de SELECT-instructie heeft een waarschuwingssymbool.
Deze query werkt prima omdat het gegevenstype NVARCHAR() zowel Unicode- als niet-Unicode-waarden kan hebben.
De tweede query gebruikt nu een Index-scan en geeft een waarschuwingssymbool op de SELECT-operator.
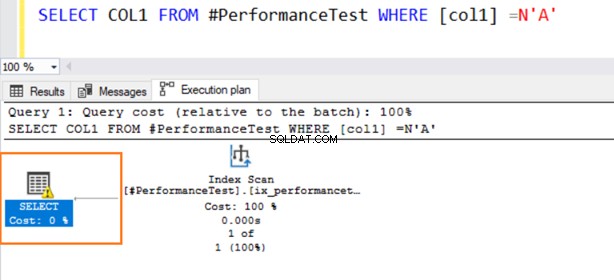
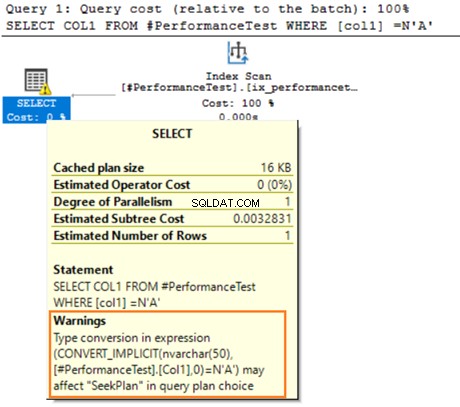
Beweeg de muis over de SELECT-instructie die een waarschuwing geeft over de impliciete conversie. SQL Server kan de bestaande index niet goed gebruiken. Dit komt door de verschillende algoritmen voor het sorteren van gegevens voor zowel VARCHAR- als NVARCHAR-gegevenstypen.
Als de tabel miljoenen rijen heeft, moet SQL Server extra werk doen en gegevens impliciet converteren met behulp van gegevensconversie. Het kan de prestaties van uw zoekopdracht negatief beïnvloeden. Vermijd daarom het mengen en matchen van deze gegevenstypen bij het optimaliseren van de zoekopdrachten.
Conclusie
U dient uw gegevensvereisten te herzien terwijl u databasetabellen en hun kolommengegevenstype op de juiste manier ontwerpt. Gewoonlijk is het VARCHAR-gegevenstype de server voor de meeste van uw gegevensvereisten. Als u echter zowel Unicode- als niet-Unicode-gegevenstypen in een kolom moet opslaan, kunt u overwegen de NVARCHAR te gebruiken. U moet echter de implicaties voor de prestaties en de opslaggrootte bekijken voordat u de definitieve beslissing neemt.