In een vorige blog hadden we besproken hoe je een standalone Moodle-setup migreert naar een schaalbare setup op basis van een geclusterde database. De volgende stap waar u aan moet denken, is het failover-mechanisme - wat doet u als en wanneer uw databaseservice uitvalt.
Een defecte databaseserver is niet ongebruikelijk als u MySQL-replicatie als uw backend Moodle-database heeft, en als dit gebeurt, moet u een manier vinden om uw topologie te herstellen door bijvoorbeeld een standby-server te promoten om een nieuwe primaire server worden. Automatische failover voor je Moodle MySQL-database helpt de uptime van apps. We zullen uitleggen hoe failover-mechanismen werken en hoe u automatische failover in uw installatie kunt inbouwen.
Architectuur met hoge beschikbaarheid voor MySQL-database
Een architectuur met hoge beschikbaarheid kan worden bereikt door uw MySQL-database op verschillende manieren te clusteren. U kunt MySQL-replicatie gebruiken, meerdere replica's instellen die uw primaire database nauw volgen. Bovendien kunt u een database-load balancer plaatsen om het lees-/schrijfverkeer te splitsen en het verkeer te verdelen over lees-schrijf- en alleen-lezen knooppunten. Database-architectuur met hoge beschikbaarheid die MySQL-replicatie gebruikt, kan als volgt worden beschreven:
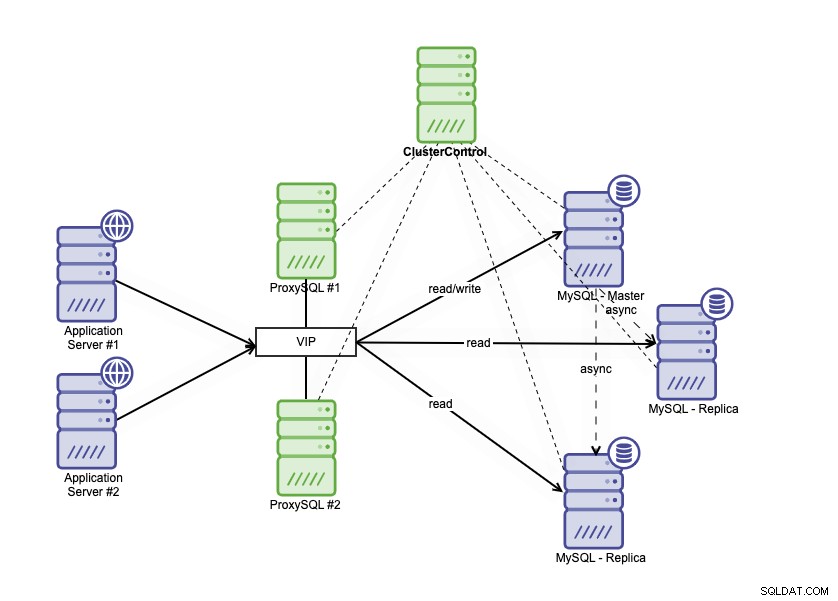
Het bestaat uit één primaire database, twee database-replica's en database-load balancers (in deze blog gebruiken we ProxySQL als database load balancers) en keepalive als een service om de ProxySQL-processen te monitoren. We gebruiken het virtuele IP-adres als een enkele verbinding vanuit de applicatie. Het verkeer wordt gedistribueerd naar de actieve load balancer op basis van de rolvlag in keepalive.
ProxySQL kan het verkeer analyseren en begrijpen of een verzoek gelezen of geschreven is. Het zal het verzoek dan doorsturen naar de juiste host(s).
Failover op MySQL-replicatie
MySQL-replicatie gebruikt binaire logboekregistratie om gegevens van de primaire naar de replica's te repliceren. De replica's maken verbinding met het primaire knooppunt en elke wijziging wordt gerepliceerd en geschreven naar de relaislogboeken van de replicaknooppunten via IO_THREAD. Nadat de wijzigingen zijn opgeslagen in het relaislogboek, gaat het SQL_THREAD-proces verder met het toepassen van gegevens in de replicadatabase.
De standaardinstelling voor parameter read_only in een replica is AAN. Het wordt gebruikt om de replica zelf te beschermen tegen direct schrijven, dus de wijzigingen komen altijd van de primaire database. Dit is belangrijk omdat we niet willen dat de replica afwijkt van de primaire server. Failover-scenario in MySQL-replicatie vindt plaats wanneer de primaire niet bereikbaar is. Hier kunnen veel redenen voor zijn; bijvoorbeeld servercrashes of netwerkproblemen.
U moet een van de replica's promoveren naar primair, de alleen-lezen-parameter op de gepromote replica uitschakelen, zodat deze beschrijfbaar kan zijn. U moet ook de andere replica wijzigen om verbinding te maken met de nieuwe primaire. In de GTID-modus hoeft u de binaire lognaam en de positie van waaruit u de replicatie hervat, niet te noteren. Bij traditionele op binlog gebaseerde replicatie moet u echter zeker de laatste binaire lognaam en positie weten om verder te gaan. Failover in op binlog gebaseerde replicatie is een behoorlijk complex proces, maar zelfs failover in op GTID gebaseerde replicatie is ook niet triviaal, omdat je moet letten op zaken als foutieve transacties. Een storing detecteren is één ding, en vervolgens binnen korte tijd reageren op de storing is waarschijnlijk niet mogelijk zonder automatisering.
Hoe ClusterControl automatische failover mogelijk maakt
ClusterControl heeft de mogelijkheid om automatische failover uit te voeren voor uw Moodle MySQL-database. Er is een functie voor automatisch herstel voor cluster en knooppunt die het failoverproces activeert wanneer de primaire database crasht.
We zullen simuleren hoe automatische failover plaatsvindt in ClusterControl. We zullen de primaire database laten crashen en kijken op het ClusterControl-dashboard. Hieronder vindt u de huidige topologie van het cluster:
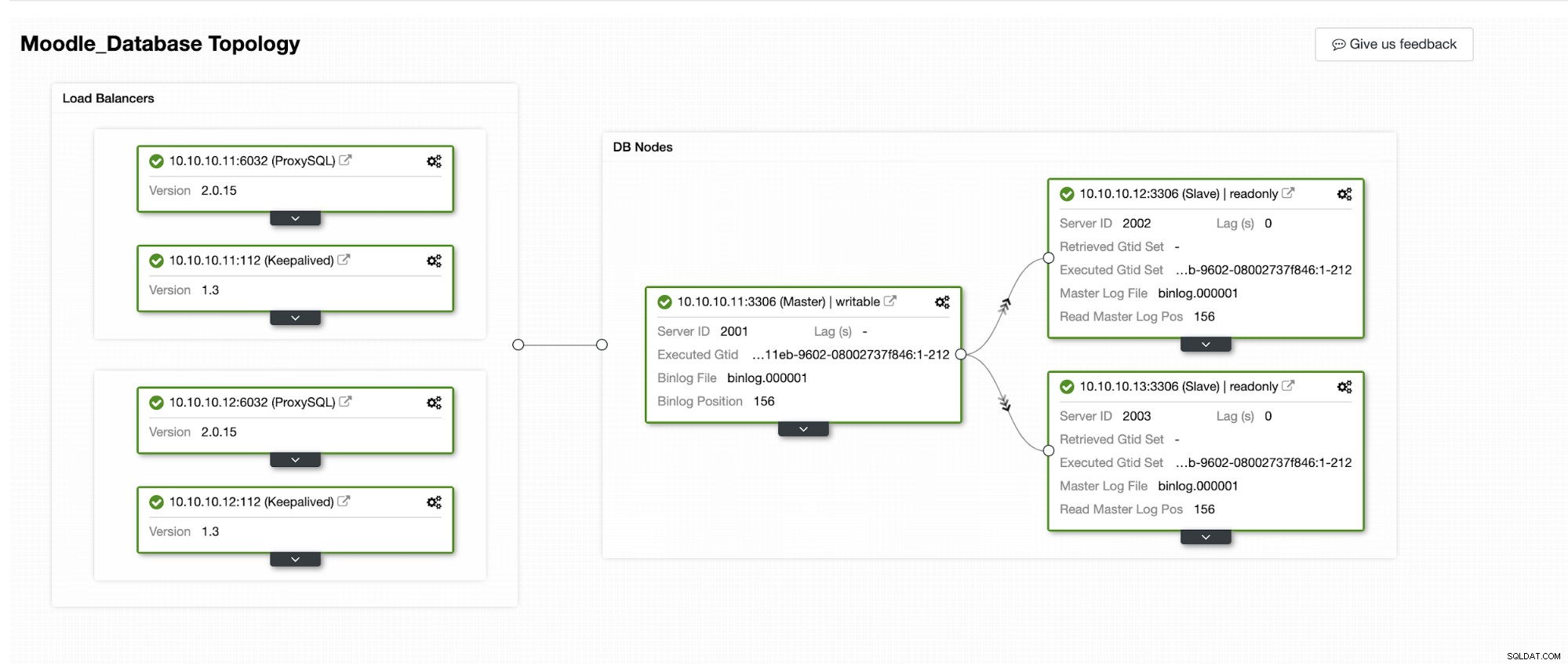
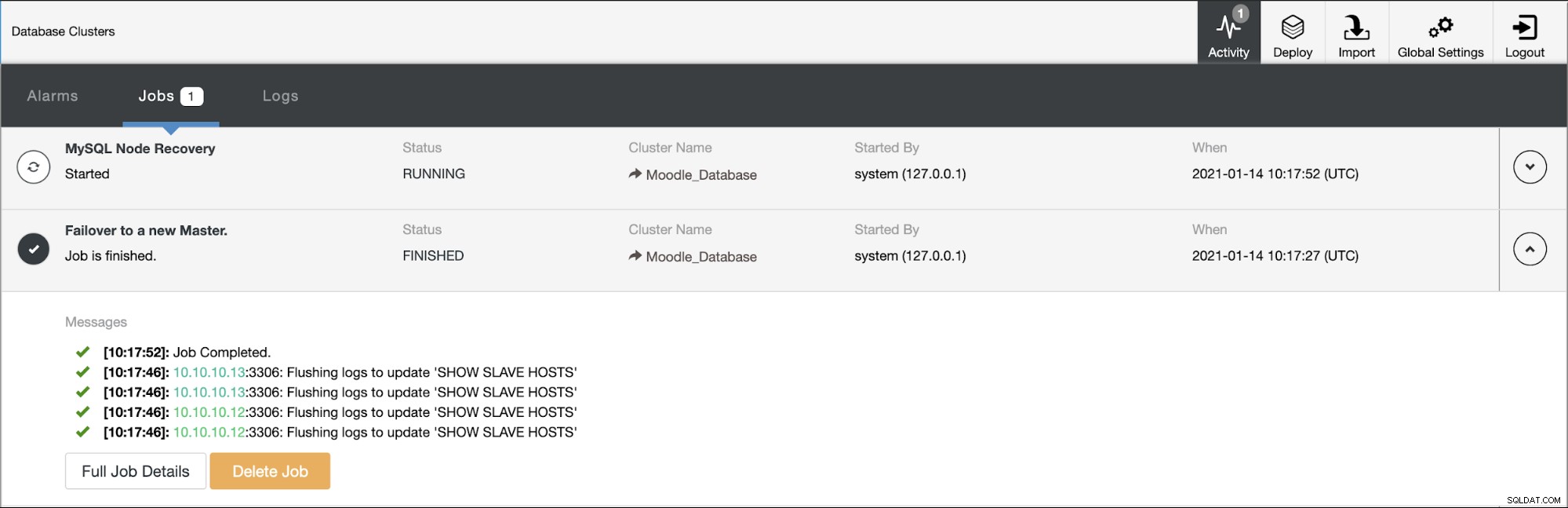
De primaire database gebruikt IP-adres 10.10.10.11 en de replica's zijn:10.10.10.12 en 10.10.10.13. Wanneer de crash plaatsvindt op de primaire, activeert ClusterControl een waarschuwing en start een failover zoals weergegeven in de onderstaande afbeelding:
Een van de replica's wordt gepromoveerd tot primair, wat resulteert in de topologie als in de onderstaande afbeelding:
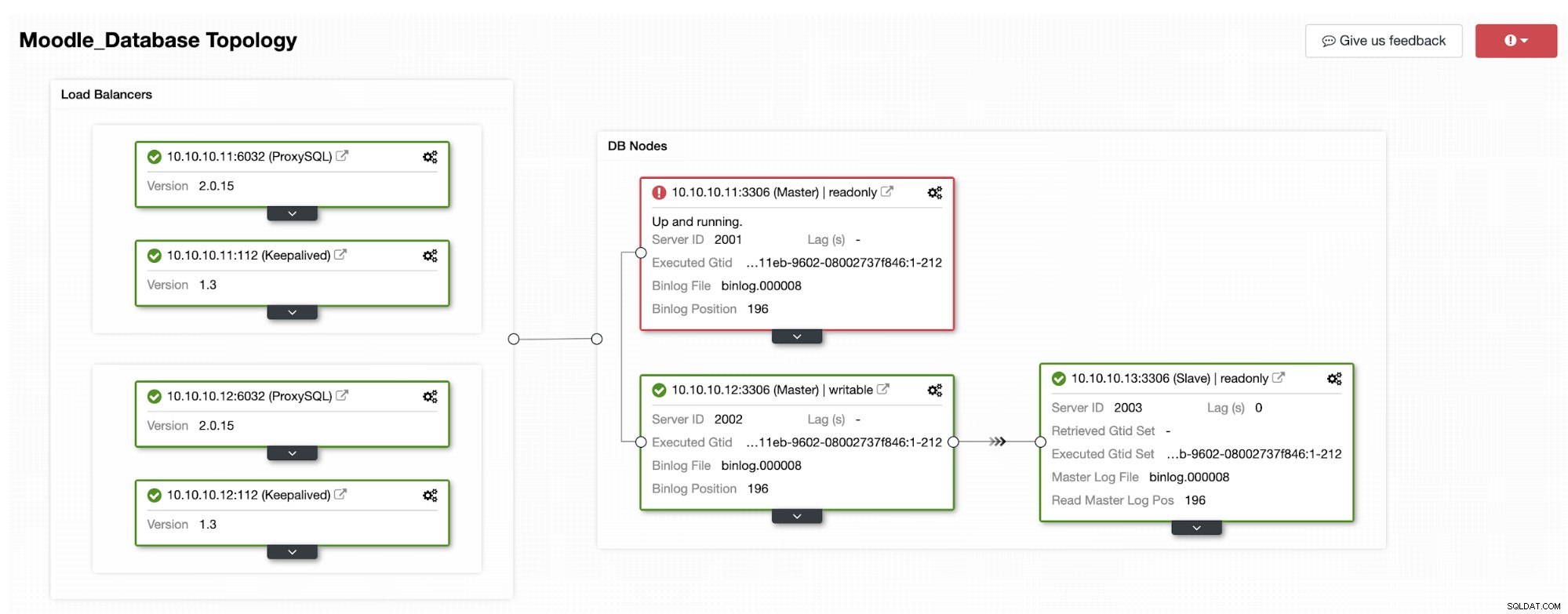
Het IP-adres 10.10.10.12 dient nu het schrijfverkeer als primair, en we hebben ook nog maar één replica met IP-adres 10.10.10.13. Aan de ProxySQL-kant zal de proxy de nieuwe primaire automatisch detecteren. Hostgroep (HG10) bedient nog steeds het schrijfverkeer met lid 10.10.10.12 zoals hieronder weergegeven:

Hostgroup (HG20) kan nog steeds leesverkeer bedienen, maar zoals u kunt zien het knooppunt 10.10.10.11 is offline vanwege de crash :
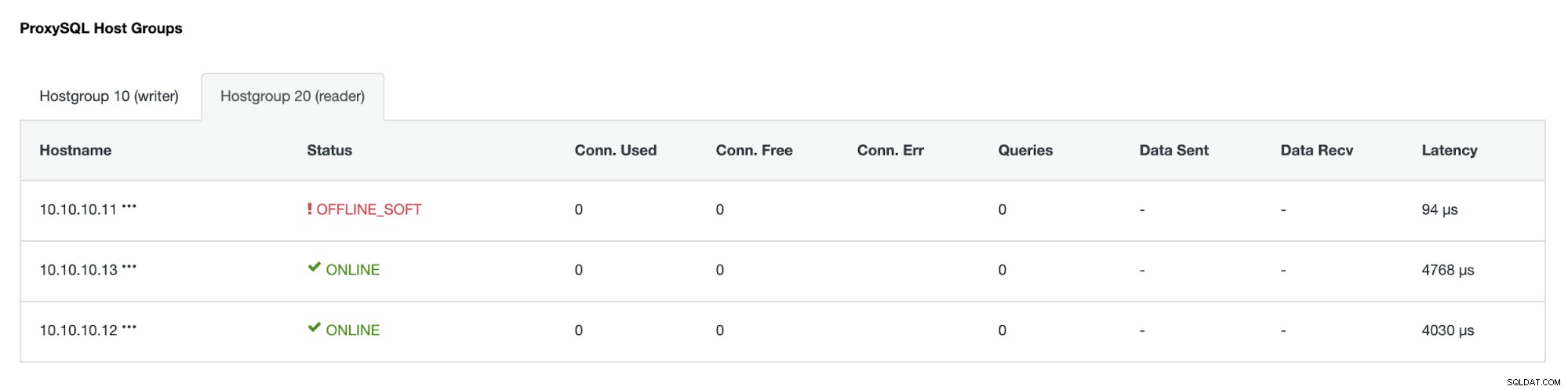
Zodra de primaire defecte server weer online is, wordt deze niet automatisch opnieuw -geïntroduceerd in de database-topologie. Dit is om te voorkomen dat informatie over het oplossen van problemen verloren gaat, aangezien het opnieuw introduceren van het knooppunt als replica mogelijk het overschrijven van sommige logboeken of andere informatie vereist. Maar het is mogelijk om automatisch opnieuw deelnemen aan het mislukte knooppunt te configureren.